はじめに
Apache Iceberg は、オープンなテーブルフォーマットとして注目されており、データレイク上でのテーブル管理や履歴管理、タイムトラベルといった機能を実現できます。
こうした Iceberg の機能は、OCI 上でも OCI Data Flow(サーバーレスで使えるSpark実行基盤)やObject Storage を用いて実行できます。
今回は、OCI Object Storage を保存先として Iceberg テーブル を作成し、データの追加・更新や履歴参照の動作を確認します。
まずは Compute 上で動作を確かめたうえで、OCI Data Flow でも同じスクリプトを実行し、マネージド環境でも同様に扱えることを確認していきます。
本記事は以下のQiita記事を参考にさせていただいたトレース記事になります。手順をなぞりながら、OCI環境上で Apache Iceberg を動かしてみた内容を、確認ポイントも交えて整理しています。
「OCI Object Storage を保存先にした Iceberg テーブルをまず一通り触ってみたい」「PySpark や SQL ベースで Iceberg の基本操作を確認したい」という方の参考になれば幸いです。
この記事で分かること
- Object Storage を保存先にした Iceberg テーブルの作り方
- PySpark / SQL での基本操作(作成・追加・更新)
- スナップショット履歴とタイムトラベルの確認方法
- 同じスクリプトを OCI Data Flow でも実行する流れ
手順
以下の流れで進めていきます。
Step 1. 事前準備
- Object Storageのバケットを作る
- Compute から Object Storageを使うためのIAM設定を行う
Step 2. Computeで実行
- Computeの作成・Compute上に Spark + OCI HDFS Connector をインストール
-
iceberg-test.pyを作成 - Compute上で
spark-submitして出力を確認する - SQLベースのスクリプト
iceberg-test-sql.pyも実行し結果を確認
Step 3. OCI Data Flowで実行
- Compute 上で確認したスクリプトを使い、Data Flowでも同様に実行する
Step 1. 事前準備
今回の検証用のコンパートメントsparkに対して、バケットとポリシーの設定などの事前準備をします。
1-1. バケットの作成
Icebergのデータ(Parquetファイル)とメタデータを保存するバケットを作成します。
今回は、Iceberg の保存先(warehouse)として、Object Storage のバケットを使います。
たとえば oci://spark@mytenancyns/iceberg/ のように指定すると、spark バケットの iceberg 配下にテーブル関連のファイルが作られていきます。
Object Storage 上に Iceberg テーブルを作成し、data と metadata 配下にファイルが格納される構成です。
sparkという名前でバケットを作成しておきます。
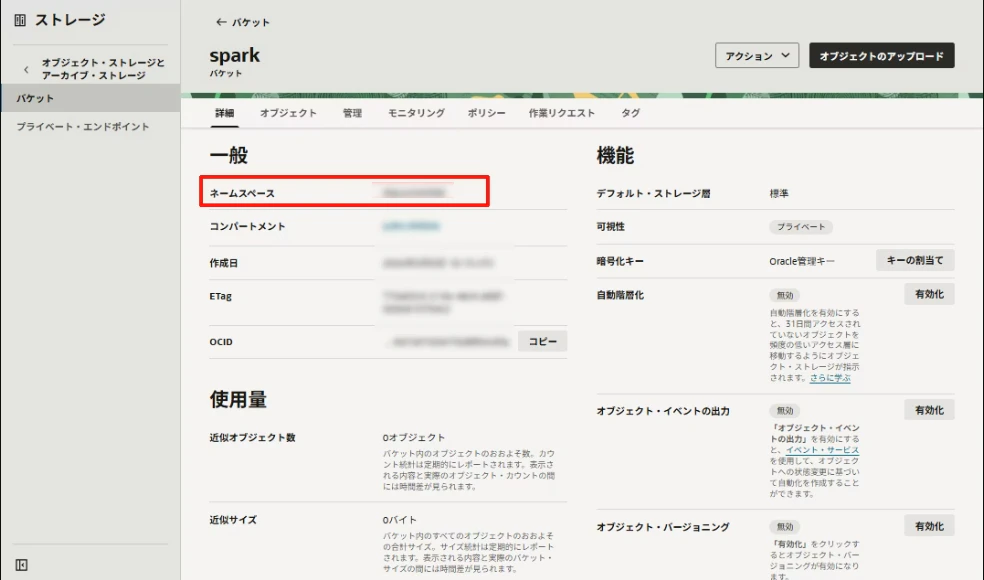
合わせて、この後Object Storageのネームスペースを使用するので、確認しておきます。
1-2. ポリシーの設定
ComputeからInstance PrincipalでObject Storageにアクセスするために、Dynamic Groupを作成します。
今回のセットアップスクリプトは Instance Principal を使う前提で、動的グループに対して Object Storage 権限を付ける構成です。
アイデンティティとセキュリティ>ドメインを選択し、詳細画面から動的グループをクリックします。
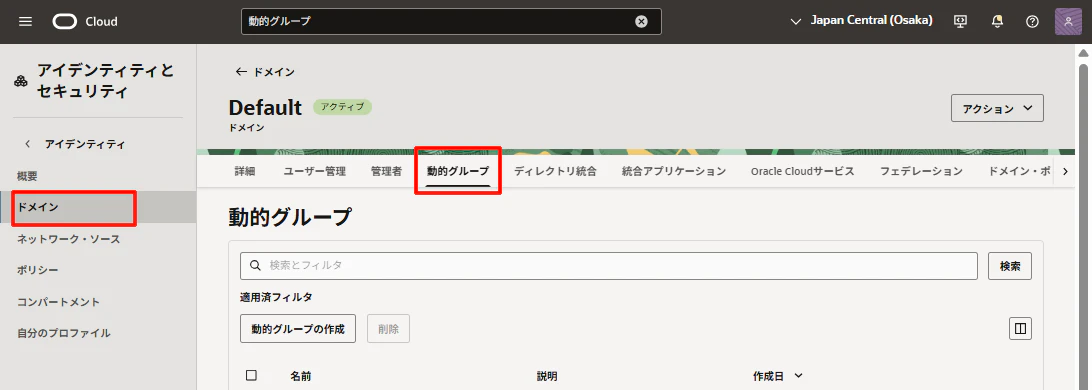
動的グループを作成します。
例:
- 名前:
dg-spark-iceberg - 一致ルール:
ANY {instance.compartment.id = 'ocid1.compartment.xxx...'}- ※Computeを作成するCompartmentのOCIDを入力します。これによりそのコンパートメントに作成する全てのインスタンスがこのグループに含まれます。

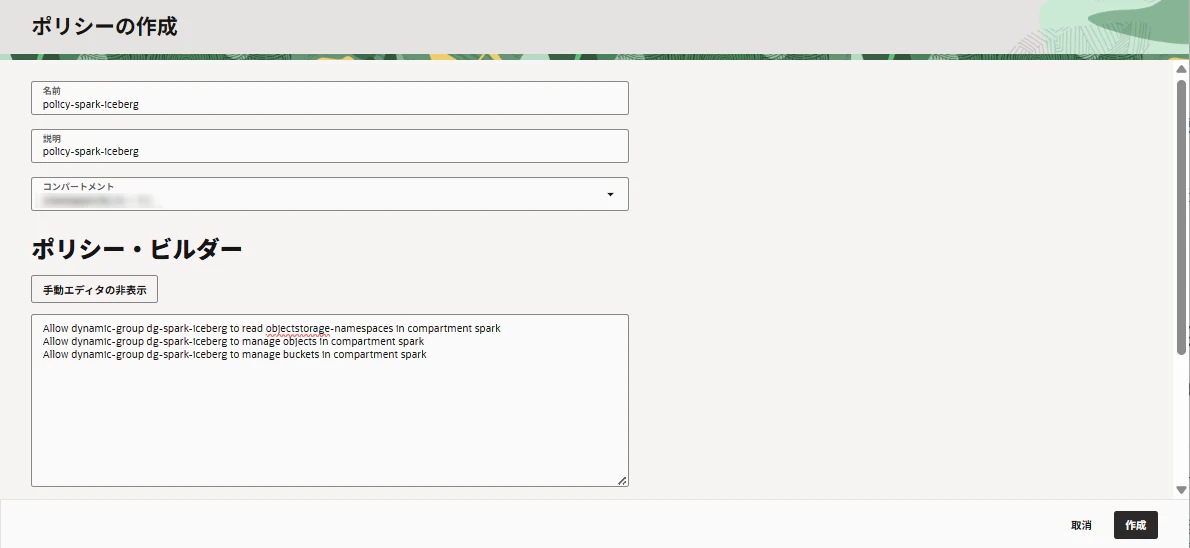
次にIAM Policyを作成します。
Computeが、Object Storageのnamespace参照・バケット参照・オブジェクト作成/更新をできるようにします。
- 名前:
policy-spark-iceberg - コンパートメント:
Allow dynamic-group dg-spark-iceberg to read objectstorage-namespaces in compartment spark
Allow dynamic-group dg-spark-iceberg to manage objects in compartment spark
Allow dynamic-group dg-spark-iceberg to manage buckets in compartment spark
Step 2. Computeで実行
2-1. Computeの作成
まずはComputeでSparkを動かして、正しく動くか確認してきます。そのために利用するComputeインスタンスを作成します。
- 名前:
spark-iceberg-vm - コンパートメント:
spark - OS:Oracle Linux 9
- シェイプ:
VM.Standard.E5.Flex

2-2. Computeのセットアップ
Spark実行前の前提準備です。
Java 17または21をインストールします。
ssh opc@<ComputeのPublic IP>
sudo dnf install -y java-17-openjdk-devel
mkdir -p /home/opc/work
cd /home/opc/work
java -version

次に、参考記事で用意されているスクリプトを使用して、Spark環境とHDFS Connectorの構築・設定を行っていきます。
Iceberg テーブルは Object Storage 上に作られるので、Spark から Object Storage を扱えるようにするために OCI HDFS Connector が必要です。
こちらのスクリプトで構築できる環境は次のとおりです。
Spark 3.5.6 / Scala 2.12 / Hadoop 3.3 + OCI HDFS Connector 3.3.4.1.5.1
また、以下のスクリプトでは東京リージョンのObject Storageのエンドポイントになっています。利用するリージョンに合わせて、スクリプト後半にある以下のURLを利用するリージョンに書き換えます。
例:https://objectstorage.ap-osaka-1.oraclecloud.com (大阪リージョンの場合)
bashスクリプト:setup-spark.shはこちら
#!/bin/bash
set -ex
SPARK_BASE=spark-3.5.6-bin-hadoop3
SPARK_HOME=$(pwd)/$SPARK_BASE
spark_dl_url=https://archive.apache.org/dist/spark/spark-3.5.6/spark-3.5.6-bin-hadoop3.tgz
hdfs_connector_dl_url=https://github.com/oracle/oci-hdfs-connector/releases/download/v3.3.4.1.5.1/oci-hdfs.zip
# download spark
wget -q --no-check-certificate ${spark_dl_url}
mkdir $SPARK_HOME
tar xzvf *.tgz -C $SPARK_HOME --strip-components 1
rm $SPARK_BASE.tgz
# download oci hdfs connector
wget -q --no-check-certificate ${hdfs_connector_dl_url}
unzip *.zip -d oci-hdfs
cp oci-hdfs/lib/*.jar $SPARK_HOME/jars
cp oci-hdfs/third-party/lib/*.jar $SPARK_HOME/jars
rm $SPARK_HOME/jars/jsr305-3.0.0.jar # HDFS connector includes 3.0.2
# clean-up hdfs connector
rm oci-hdfs.zip
rm -rf oci-hdfs
# generate log4j2.properties
cat $SPARK_HOME/conf/log4j2.properties.template \
| sed -e 's/rootLogger.level = info/rootLogger.level = warn/' \
| sed -e '$a\\nlogger.oci.name = com.oracle.bmc' \
| sed -e '$a\logger.oci.level = error' \
| sed -e '$a\\nlogger.nativecodeloader.name = org.apache.hadoop.util.NativeCodeLoader' \
| sed -e '$a\logger.nativecodeloader.level = error' \
| sed -e '$a\\nlogger.metrics.name = org.apache.spark.metrics' \
| sed -e '$a\logger.metrics.level = error' \
> $SPARK_HOME/conf/log4j2.properties
# generate spark-defaults.conf - change object storage endpoint as needed
cat $SPARK_HOME/conf/spark-defaults.conf.template \
| sed -e '$a\\nspark.sql.hive.metastore.sharedPrefixes=shaded.oracle,com.oracle.bmc' \
| sed -e '$a\spark.hadoop.fs.oci.client.hostname=https://objectstorage.ap-tokyo-1.oraclecloud.com' \
| sed -e '$a\#spark.hadoop.fs.oci.client.hostname.BUCKET.NAMESPACE=https://objectstorage.REGION.oraclecloud.com' \
| sed -e '$a\spark.hadoop.fs.oci.client.custom.authenticator=com.oracle.bmc.hdfs.auth.InstancePrincipalsCustomAuthenticator' \
> $SPARK_HOME/conf/spark-defaults.conf
vi setup-spark.sh
chmod +x setup-spark.sh
./setup-spark.sh
export SPARK_HOME=/home/opc/work/spark-3.5.6-bin-hadoop3
echo 'export SPARK_HOME=/home/opc/work/spark-3.5.6-bin-hadoop3' >> ~/.bashrc
source ~/.bashrc
2-3. Icebergを操作するPySparkスクリプトを作る
ここからPySparkを使って、Iceberg テーブルを実際に作り操作していきます。
エディタでiceberg-test.py を作ります。
vi iceberg-test.py
以下のコードを貼り付けます。コードの中身はこの後解説します。
流れとしては、テーブル作成 → 追加 → 更新 → 履歴確認 → 過去スナップショット確認です。
そして、以下の行を修正します。
.config("spark.sql.catalog.dev.warehouse", "oci://spark@NAMESPACE/iceberg/")
- バケット名:
spark - ネームスペース:冒頭確認したご自身のネームスペース
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit, when
spark = (SparkSession.builder
.appName("MyIcebergApp")
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.config("spark.sql.catalog.dev", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.dev.type", "hadoop")
.config("spark.sql.catalog.dev.warehouse", "oci://spark@NAMESPACE/iceberg/")
.getOrCreate())
table_name = "dev.db.test"
if spark.catalog.tableExists(table_name):
spark.sql(f"DROP TABLE {table_name}")
# テスト用データをコード内で作成
df1 = spark.range(5).withColumn("data", lit("df1"))
df2 = spark.range(5, 10).withColumn("data", lit("df2"))
# 1回目: テーブル作成
df1.writeTo(f"{table_name}").create()
# 2回目: データ追加
df2.writeTo(f"{table_name}").append()
# 3回目: 一部データ更新
updated_df = spark.read.table(f"{table_name}").withColumn(
"data",
when(col("id") % 3 == 0, "mod3").otherwise(col("data"))
)
updated_df.writeTo(f"{table_name}").overwritePartitions()
# 現在のテーブル表示
print(f"{table_name}")
spark.read.table(f"{table_name}").show()
# 履歴表示
history = spark.read.table(f"{table_name}.history")
print(f"{table_name}.history")
history.show()
# 最初のスナップショットID
snapshot_id = history.where(col("parent_id").isNull()).head()["snapshot_id"]
print(f"snapshot_id: {snapshot_id}")
# 最初のスナップショットを表示
spark.read.option("snapshot-id", snapshot_id).table(table_name).show()
# 2番目に古い状態を timestamp 指定で表示
ts = history.select(col("made_current_at").alias("ts")).where(col("parent_id") == snapshot_id).head()["ts"]
print(f"timestamp: {ts}")
spark.read.option("as-of-timestamp", int(ts.timestamp() * 1000)).table(table_name).show()
spark.stop()
◆ 全体の流れ
dev.db.test という Iceberg テーブルを作って、
最初に df1 を入れ、次に df2 を追加し、その後一部の行を更新しています。
そのあと、Iceberg の特徴である 履歴管理(スナップショット) を使って、
- 最初に作った時点の状態
- その次の更新時点の状態
を読み直しています。
つまり、Icebergの「追加・更新・履歴参照・タイムトラベル」を一通り確認していきます。
◆ 扱うデータ
今回のサンプルでは、外部ファイルは使いません。
CSV や JSON を読み込むのではなく、コード内でテスト用データを作ります。
使うのは、次の2つの DataFrame です。
df1 = spark.range(5).withColumn("data", lit("df1"))
df2 = spark.range(5, 10).withColumn("data", lit("df2"))
これは、それぞれ次のような内容です。
df1 は id が 0〜4、data が "df1" のデータ。
df2 は id が 5〜9、data が "df2" のデータ。
◆ Icebergのカタログタイプ
スクリプト冒頭のSpark セッションの作成時に Iceberg 拡張機能の設定を行なっています。そこで今回は spark.sql.catalog.dev.type に hadoop を指定しています。
Iceberg のカタログのタイプにはオプションがあり、OCI Data Flow で扱う場合は、hadoop タイプを使います。
これにより、メタデータも含めて Object Storage 上で管理されます。
つまり、Hive Metastore など別の管理先を使わず、Object Storage をそのまま Iceberg の保存・管理先にする構成です。
1. SparkをIceberg対応で起動
・dev というIcebergカタログを設定
・保存先は OCI Object Storage(oci://.../iceberg/)
2. テーブルを作り直す
・dev.db.test というテーブルを使う
・すでにあれば削除して作り直す
3. データを入れる
・df1(id 0〜4, data="df1")を書き込み
・df2(id 5〜9, data="df2")を追加
4. 一部データを更新する
・id が3の倍数(0,3,6,9)の行だけ data を "mod3" に変更(id = 0, 3, 6, 9 → data = "mod3"
・それ以外 → 元の df1 / df2 のまま
5. Icebergの履歴を見る
・.history テーブルを読んで、変更履歴(スナップショット)を確認
6. 過去の状態を読み直す
・最初のスナップショット時点のデータを表示
・次の時点のデータも timestamp 指定で表示
2-4. 実行
以下のコマンドを使用して、先程作成したコードを実行していきます。
$SPARK_HOME/bin/spark-submit \
--master local[*] \
--packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.9.2 \
iceberg-test.py
ポイントは、Iceberg の runtime パッケージを --packages で追加することです。Spark 標準だけでは Iceberg 拡張機能は使えず、このパッケージを追加して実行することで、Iceberg拡張機能が使えるようになります。
Spark と Scala のバージョンに合ったパッケージを指定する必要があります。今回は org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.9.2 を使っています。
これがないと、Iceberg のテーブル操作やスナップショット関連の機能が使えません。
2-5. 実行結果の確認
出力結果を見てみましょう!
[opc@spark-iceberg-vm work]$ $SPARK_HOME/bin/spark-submit \
--master local[*] \
--packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.9.2 \
iceberg-test.py
:: loading settings :: url = jar:file:/home/opc/work/spark-3.5.6-bin-hadoop3/jars/ivy-2.5.1.jar!/org/apache/ivy/core/settings/ivysettings.xml
Ivy Default Cache set to: /home/opc/.ivy2/cache
The jars for the packages stored in: /home/opc/.ivy2/jars
org.apache.iceberg#iceberg-spark-runtime-3.5_2.12 added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-9ad46276-a0fb-43bf-bff9-ed93f4ec6b46;1.0
confs: [default]
found org.apache.iceberg#iceberg-spark-runtime-3.5_2.12;1.9.2 in central
downloading https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/1.9.2/iceberg-spark-runtime-3.5_2.12-1.9.2.jar ...
[SUCCESSFUL ] org.apache.iceberg#iceberg-spark-runtime-3.5_2.12;1.9.2!iceberg-spark-runtime-3.5_2.12.jar (1232ms)
:: resolution report :: resolve 520ms :: artifacts dl 1238ms
:: modules in use:
org.apache.iceberg#iceberg-spark-runtime-3.5_2.12;1.9.2 from central in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 1 | 1 | 1 | 0 || 1 | 1 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent-9ad46276-a0fb-43bf-bff9-ed93f4ec6b46
confs: [default]
1 artifacts copied, 0 already retrieved (44317kB/21ms)
dev.db.test
+---+----+
| id|data|
+---+----+
| 5| df2|
| 6|mod3|
| 7| df2|
| 8| df2|
| 9|mod3|
| 0|mod3|
| 1| df1|
| 2| df1|
| 3|mod3|
| 4| df1|
+---+----+
dev.db.test.history
+--------------------+-------------------+-------------------+-------------------+
| made_current_at| snapshot_id| parent_id|is_current_ancestor|
+--------------------+-------------------+-------------------+-------------------+
|2026-03-03 12:39:...| 993876873677258359| NULL| true|
|2026-03-03 12:39:...|6398785414383798966| 993876873677258359| true|
|2026-03-03 12:39:...| 537931430566713130|6398785414383798966| true|
+--------------------+-------------------+-------------------+-------------------+
snapshot_id: 993876873677258359
+---+----+
| id|data|
+---+----+
| 0| df1|
| 1| df1|
| 2| df1|
| 3| df1|
| 4| df1|
+---+----+
timestamp: 2026-03-03 12:39:43.773000
+---+----+
| id|data|
+---+----+
| 0| df1|
| 1| df1|
| 2| df1|
| 3| df1|
| 4| df1|
| 5| df2|
| 6| df2|
| 7| df2|
| 8| df2|
| 9| df2|
+---+----+
[opc@spark-iceberg-vm work]$
上から順番に見ていきます。
dev.db.test:現在の中身
dev.db.test
+---+----+
| id|data|
+---+----+
| 5| df2|
| 6|mod3|
| 7| df2|
| 8| df2|
| 9|mod3|
| 0|mod3|
| 1| df1|
| 2| df1|
| 3|mod3|
| 4| df1|
+---+----+
これは Iceberg テーブル dev.db.test の“今の状態” です。
列は2つ:
- id
- data
id が3の倍数の行(`id = 0, 3, 6, 9) だけ data が"mod3" に変更されていることが確認できます。
dev.db.test.history:スナップショット履歴
dev.db.test.history
+--------------------+-------------------+-------------------+-------------------+
| made_current_at| snapshot_id| parent_id|is_current_ancestor|
+--------------------+-------------------+-------------------+-------------------+
|2026-03-03 12:39:...| 993876873677258359| NULL| true|
|2026-03-03 12:39:...|6398785414383798966| 993876873677258359| true|
|2026-03-03 12:39:...| 537931430566713130|6398785414383798966| true|
+--------------------+-------------------+-------------------+-------------------+
これは Iceberg の履歴管理機能 です。
Iceberg はテーブル変更のたびに snapshot(スナップショット) を作ります。
各列の意味
-
made_current_at
そのスナップショットが「現在版」になった時刻 -
snapshot_id
スナップショットの一意ID -
parent_id
ひとつ前のスナップショットID
(どの版から派生したか) -
is_current_ancestor
今の最新状態につながる履歴かどうか
3行あるため、3回テーブル状態が確定 したことを示しています。
①初回データ投入(df1)→ ②追加投入(df2)→ ③更新(mod3)
snapshot_id: 993876873677258359 最初の状態
snapshot_id: 993876873677258359
+---+----+
| id|data|
+---+----+
| 0| df1|
| 1| df1|
| 2| df1|
| 3| df1|
| 4| df1|
+---+----+
これは、最初のスナップショット時点のテーブル内容 を表示しています。
最初は
- id=0~4
- data=df1
の5件だけだった、ということが確認できます。
さらに、timestamp: 2026-03-03 12:39:43.773000として、この指定された時間についてもアクセスしています。
いわゆるタイムトラベル機能により、Iceberg では最新のテーブルだけでなく、過去の特定時点の状態も参照できます。
そのため、変更前の内容を確認したい場面や、監査対応、過去時点を基準にした検証、レポートの再現などに役立ちます。
2-6. Object Storage上の結果の確認
Icebergテーブルが作成されているはずの、Object Storageを確認してみます。
指定したsparkバケットを確認してみましょう。
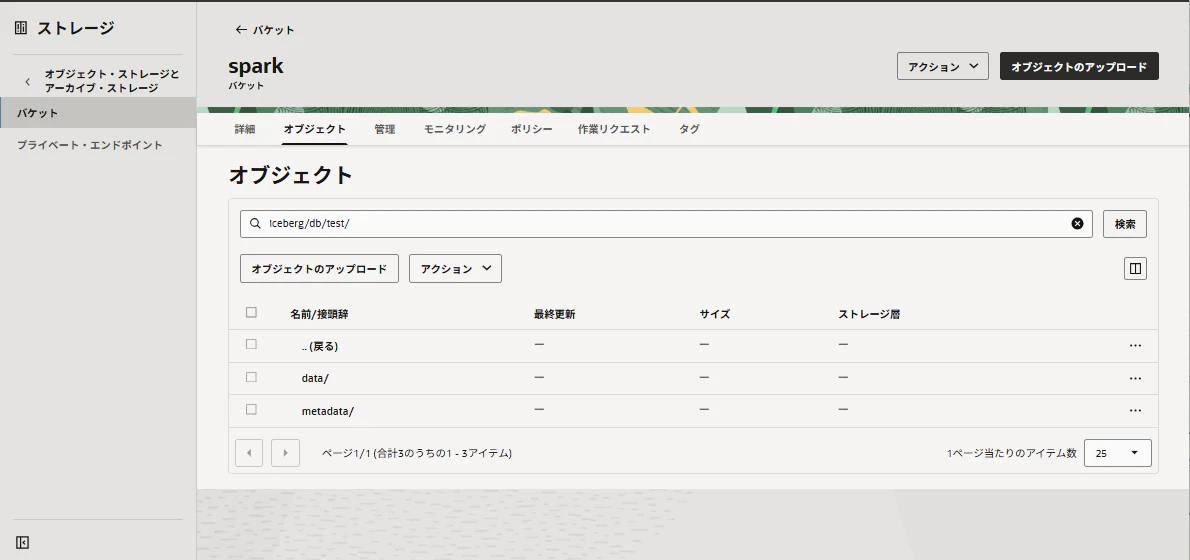
このような構成が作成されています。
iceberg/
└── db/
└── test/
├── data/
└── metadata
spark バケットの /iceberg フォルダ配下に、/db/test というサブフォルダが作られ、そこに data と metadata というフォルダが作成されています。ここに実データやメタデータが保存されます。
iceberg/db/test/data/
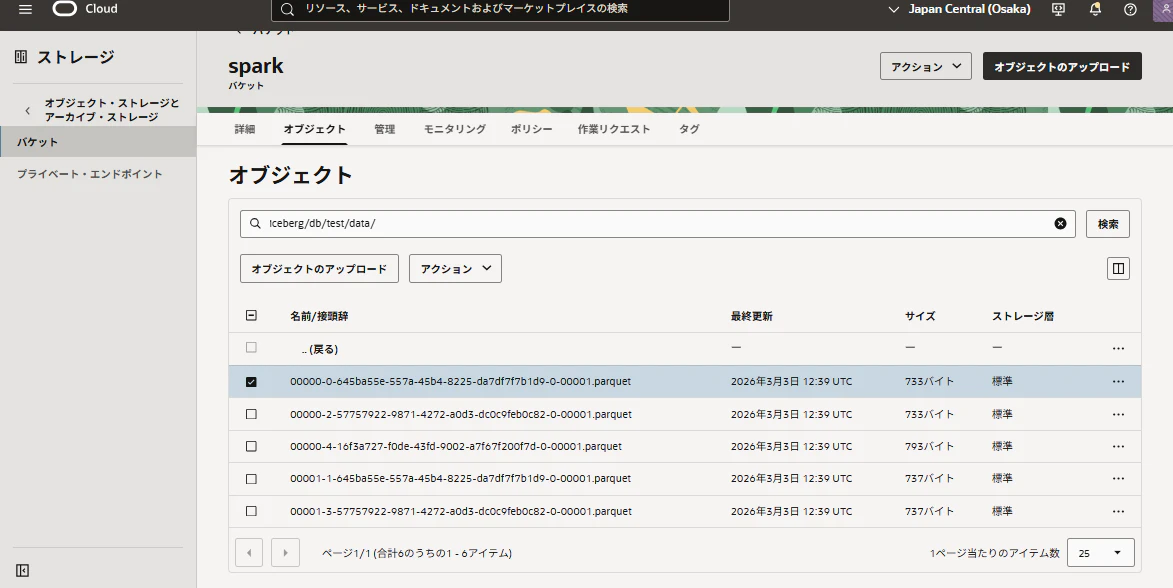
iceberg/db/test/metadata/
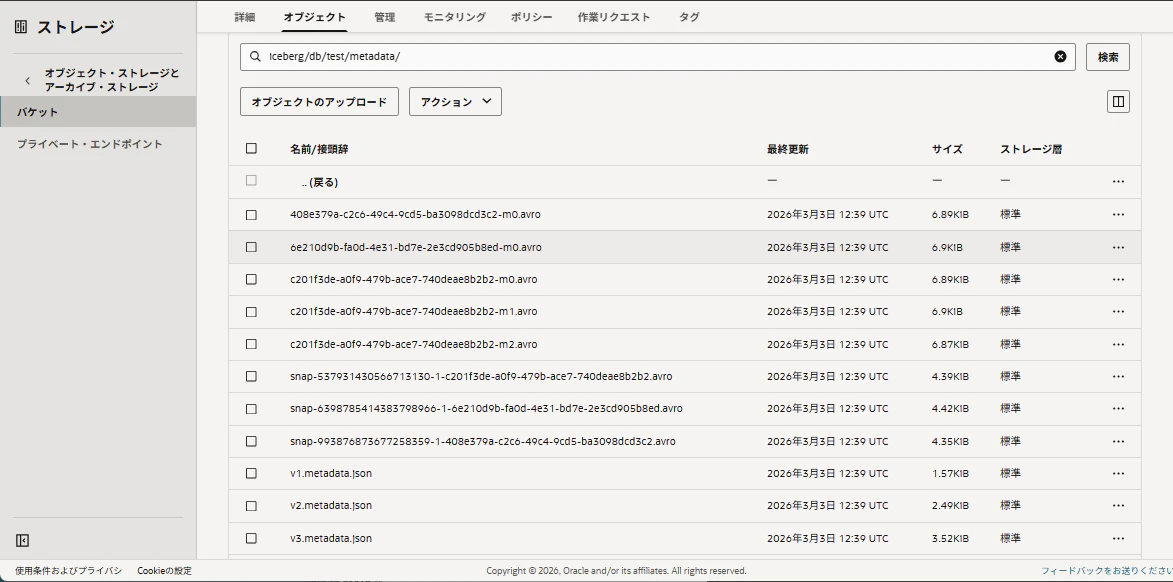
2-7. SQLベースで実行してみる
以下のSQLベースでも同様の内容で確かめてみます。
スクリプトを作成します。
vi iceberg-test-sql.py
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("MyIcebergApp")
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.config("spark.sql.catalog.dev", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.dev.type", "hadoop")
.config("spark.sql.catalog.dev.warehouse", "oci://spark@NAMESPACE/iceberg/")
.getOrCreate())
# 既存の dev.db.test とは別名のテーブルを使う
table_name = "dev.db.test_v2"
# テーブルが既に存在する場合は削除
spark.sql(f"DROP TABLE IF EXISTS {table_name};")
# 2種類のデータを作成
data1 = []
for n in range(5):
data1.append(f"({n}, 'df1')")
values1 = ",".join(data1)
print(f"values1: {values1}")
data2 = []
for n in range(5, 10):
data2.append(f"({n}, 'df2')")
values2 = ",".join(data2)
print(f"values2: {values2}")
# テーブルを新規作成
spark.sql(f"CREATE TABLE {table_name} (id int, data string) USING iceberg")
# values1 を追加
spark.sql(f"INSERT INTO {table_name} VALUES {values1}")
# values2 を追加
spark.sql(f"INSERT INTO {table_name} VALUES {values2}")
# id が 3 の倍数の行のデータを更新
spark.sql(f"UPDATE {table_name} SET data = 'mod3' WHERE id % 3 = 0")
# 現在のテーブルの内容を表示
print(f"{table_name}")
spark.sql(f"SELECT * FROM {table_name} ORDER BY id").show()
# 履歴テーブル(Icebergのメタデータ)を読み込む
history = spark.sql(f"SELECT * FROM {table_name}.history")
history.printSchema()
# 一番最初のスナップショットのIDを取得して表示(parent_id が NULL のレコード)
snapshot_id = spark.sql(
f"SELECT * FROM {table_name}.history WHERE parent_id IS NULL"
).head()["snapshot_id"]
print(f"snapshot_id: {snapshot_id}")
# 一番最初のスナップショットの内容を表示
spark.sql(f"SELECT * FROM {table_name} VERSION AS OF {snapshot_id} ORDER BY id").show()
# 二番目に古いスナップショット(parent_id = 最初の snapshot_id)を timestamp 指定で取得
ts = spark.sql(
f"SELECT made_current_at as ts FROM {table_name}.history WHERE parent_id = {snapshot_id}"
).head()["ts"]
print(f"timestamp: {ts}")
spark.sql(f"SELECT * FROM {table_name} TIMESTAMP AS OF '{ts}' ORDER BY id").show()
spark.stop()
2-8. 実行結果の確認
以下のコマンドを実行します。
$SPARK_HOME/bin/spark-submit \
--master local[*] \
--packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.9.2 \
iceberg-test-sql.py
出力結果は以下のとおりです。
:: loading settings :: url = jar:file:/home/opc/work/spark-3.5.6-bin-hadoop3/jars/ivy-2.5.1.jar!/org/apache/ivy/core/settings/ivysettings.xml
Ivy Default Cache set to: /home/opc/.ivy2/cache
The jars for the packages stored in: /home/opc/.ivy2/jars
org.apache.iceberg#iceberg-spark-runtime-3.5_2.12 added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-4770d050-9f76-41fb-b91e-e32dccbf2f3b;1.0
confs: [default]
found org.apache.iceberg#iceberg-spark-runtime-3.5_2.12;1.9.2 in central
:: resolution report :: resolve 112ms :: artifacts dl 7ms
:: modules in use:
org.apache.iceberg#iceberg-spark-runtime-3.5_2.12;1.9.2 from central in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 1 | 0 | 0 | 0 || 1 | 0 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent-4770d050-9f76-41fb-b91e-e32dccbf2f3b
confs: [default]
0 artifacts copied, 1 already retrieved (0kB/5ms)
values1: (0, 'df1'),(1, 'df1'),(2, 'df1'),(3, 'df1'),(4, 'df1')
values2: (5, 'df2'),(6, 'df2'),(7, 'df2'),(8, 'df2'),(9, 'df2')
dev.db.test_v2
+---+----+
| id|data|
+---+----+
| 0|mod3|
| 1| df1|
| 2| df1|
| 3|mod3|
| 4| df1|
| 5| df2|
| 6|mod3|
| 7| df2|
| 8| df2|
| 9|mod3|
+---+----+
root
|-- made_current_at: timestamp (nullable = false)
|-- snapshot_id: long (nullable = false)
|-- parent_id: long (nullable = true)
|-- is_current_ancestor: boolean (nullable = false)
snapshot_id: 2494107284522669852
+---+----+
| id|data|
+---+----+
| 0| df1|
| 1| df1|
| 2| df1|
| 3| df1|
| 4| df1|
+---+----+
timestamp: 2026-03-03 13:50:46.935000
+---+----+
| id|data|
+---+----+
| 0| df1|
| 1| df1|
| 2| df1|
| 3| df1|
| 4| df1|
| 5| df2|
| 6| df2|
| 7| df2|
| 8| df2|
| 9| df2|
+---+----+
◆ ポイント
SQL版では CREATE TABLE / INSERT / UPDATE / SELECT 等を使って、より直感的なSQLで表現できます。
過去データの参照も、PySparkの1つ目のスクリプトで実施する際の option("snapshot-id", ...) や option("as-of-timestamp", ...) に対して、SQL版では VERSION AS OF や TIMESTAMP AS OF を使ってそのまま記述できるため、Icebergのタイムトラベル機能をSQLとして理解しやすい構成になっています。
Object Storage内にも同様に、iceberg/db/test_v2/ディレクトリが作成され、実データやメタデータが作成されたことが確認できます。

Step 3. OCI Data Flowで実行
Compute 上で動作確認できたら、同じスクリプトを OCI Data Flow で実行します。
これにより、手元に近い検証環境で確認した Iceberg の処理を、サーバーレスなマネージド Spark 実行基盤にも載せ替えられることを確認できます。
3-1. ポリシーの設定
Data Flow が Object Storage にアクセスするためには、Resource Principal を使ったポリシーの設定が必要になります。
こちらを参照し設定を行ってください。
3-2. .pyファイルをObject Storageへアップロード
Data Flow は、実行時に Python スクリプトへアクセスする必要があります。
そのため、作成した iceberg-test.py を Object Storage にアップロードしておきます。
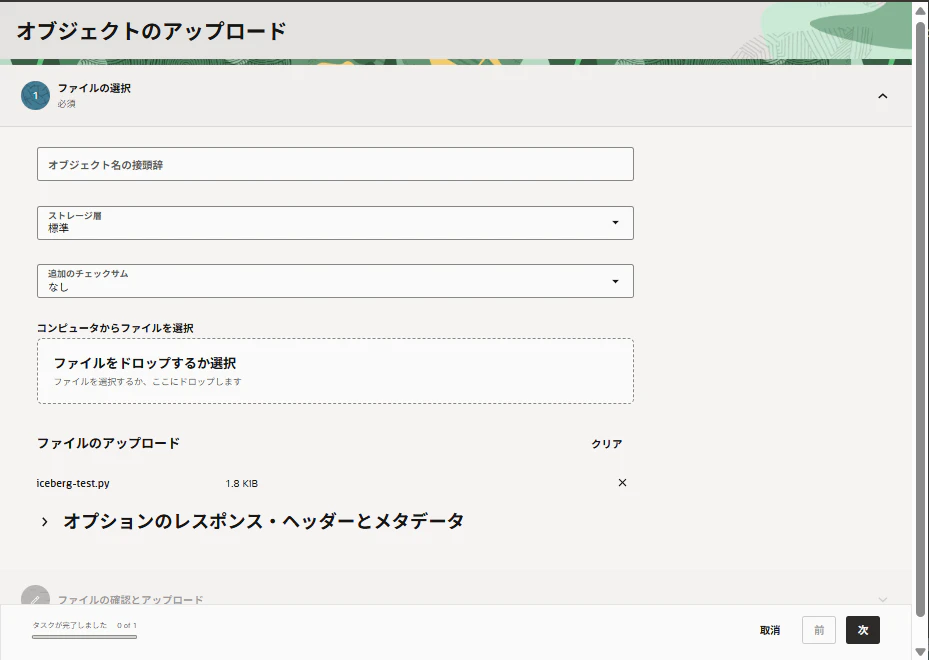
3-3. Data Flow アプリケーションの作成
「アナリティクスとAI」から「データ・フロー」を選択します。

「アプリケーションの作成」をクリックします。
ウィザードに従って入力していきます。


-
アプリケーション構成
- Spark-Submitオプションの使用:有効
Spark-Submitオプションに以下を入力します。
--packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.9.2
oci://spark@NAMESPACE/iceberg-test.py


入力出来たら、「作成」をクリックします。
Spark-Submit機能について
Spark-SubmitはApache Spark のアプリケーションをクラスタに送って実行するためのツール・コマンドです。どのアプリを実行するかに加えて、必要なライブラリや設定値も一緒に渡せます。
今回の構成では、iceberg-test.pyを実行する際に、Iceberg を使うために追加ライブラリが必要です。そのため、Data Flow 側でも --packages を使って、たとえば次のように Iceberg の依存関係を読み込ませます。
詳細は以下をご覧ください。
■ドキュメント:データ・フローでのSpark-Submit機能
アプリケーションが作成できました。
3-4. Data Flow アプリケーションの実行
作成したアプリケーション icebergを開き、「実行」をクリックします。
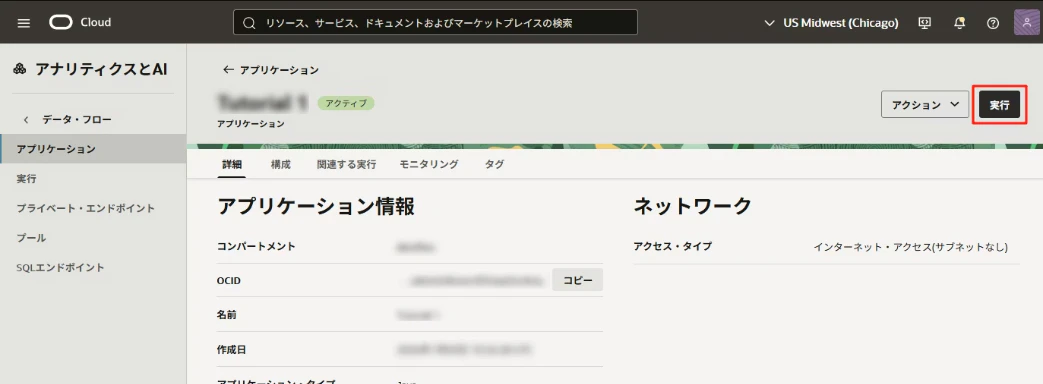
「Pythonアプリケーションの実行」画面から「実行」をクリックします。

実行すると、ステータスが「受け入れ済」であることを確認できます。
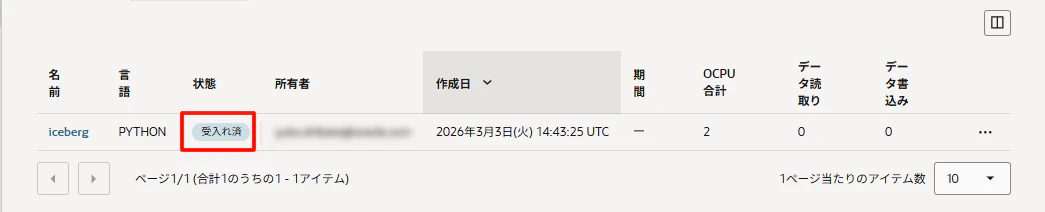
数分後に、ステータスが「進行中」になりました。

「成功」しました!

3-5. 実行結果の確認
ログを確認します。
icebergの実行詳細画面から「モニタリング」から、出力されたログを確認できます。
spark_application_stdout.log.gzを開きます。

Computeから実施した時と同様の出力が確認できました!
dev.db.test
+---+----+
| id|data|
+---+----+
| 5| df2|
| 6|mod3|
| 7| df2|
| 8| df2|
| 9|mod3|
| 0|mod3|
| 1| df1|
| 2| df1|
| 3|mod3|
| 4| df1|
+---+----+
dev.db.test.history
+--------------------+-------------------+-------------------+-------------------+
| made_current_at| snapshot_id| parent_id|is_current_ancestor|
+--------------------+-------------------+-------------------+-------------------+
|2026-03-03 14:51:...|3989594690871572783| NULL| true|
|2026-03-03 14:51:...|6248650874181736062|3989594690871572783| true|
|2026-03-03 14:52:...|6819555488153502892|6248650874181736062| true|
+--------------------+-------------------+-------------------+-------------------+
snapshot_id: 3989594690871572783
+---+----+
| id|data|
+---+----+
| 0| df1|
| 1| df1|
| 2| df1|
| 3| df1|
| 4| df1|
+---+----+
timestamp: 2026-03-03 14:51:59.670000
+---+----+
| id|data|
+---+----+
| 5| df2|
| 6| df2|
| 7| df2|
| 8| df2|
| 9| df2|
| 0| df1|
| 1| df1|
| 2| df1|
| 3| df1|
| 4| df1|
+---+----+
おわりに
今回は、OCI Object Storage を保存先として Apache Iceberg テーブルを作成し、Compute 上の Spark 環境と OCI Data Flow の両方で動作を確認しました。
実際に試してみることで、Iceberg の基本的なテーブル操作だけでなく、スナップショットによる履歴管理や、過去時点のデータを参照できるタイムトラベル機能まで、一連の流れを具体的に確認できました。
また、Compute でまず動作確認してから Data Flow に載せ替えることで、ローカルに近い検証からマネージド実行環境への展開までのイメージを掴むことができました。
Iceberg は、単にデータを保存するだけでなく、変更履歴を前提とした扱いやすいテーブル形式として活用できるのが大きな特徴です。
今後、より実践的なデータパイプラインや分析基盤を考えるうえでも、こうした基本動作を一度手を動かして確認しておくと理解しやすいと感じました。