1.Airflowとは?
Apache Airflowは、データパイプラインのオーケストレーション(スケジュール、監視、ワークフローの管理)を行うためのオープンソースのプラットフォームです。Airflowは、タスクの依存関係を定義し、スケジューリング、監視、エラー処理、リトライなどのワークフロー管理機能を提供します。
2.実際にAirflowを使ってみよう
今回は、入門として
Airflowの構築をおこなっていきます。
2.構築環境
2.1 使用OS:
os:macOS M2
ここでは
Airflowを簡単にローカル上で動かせるAstro CLIを活用していきます。
2.2Astro CLIとは?
Aifflowをローカルで簡単にセットアップして実行するための最も簡単かつ最速の方法
2.3 事前準備
まずは、DockerとHomebrewをインストールしておいてください。
ローカル上でAirflowを動かす際は、コンテナで動かします。
まずは astroCLIのインストール
macの場合はbrewでインストール
brew install astro
特定のバージョン等を指定してインストールしたい場合は、ドキュメントをご覧ください
https://docs.astronomer.io/astro/cli/install-cli
次にターミナルに移動して、任意のフォルダに移動し、astroの環境を構築します。
ディレクトリ作成等をまとめて行なっております。
cd ./Desktop && mkdir airflow_tutorial && cd airflow_tutorial && astro dev init
ファイルを見てみましょう

airflowの設定用yamlファイルや
依存関係を解消させるrequirements.txtなどがあります
setting
以下はVimコマンド等を使って、構築してください
requirements.txtに記述
airflowで2つのサービスを扱うおまじないと思ってください
astro-sdk-python[amazon,snowflake] >=0.11
.envに設定を記述
Vimコマンド等を使って、.envファイルに以下の記述を入力してください。
AIRFLOW__CORE__ALLOWED_DESERIALIZATION_CLASSES = airflow\.* astro\.*
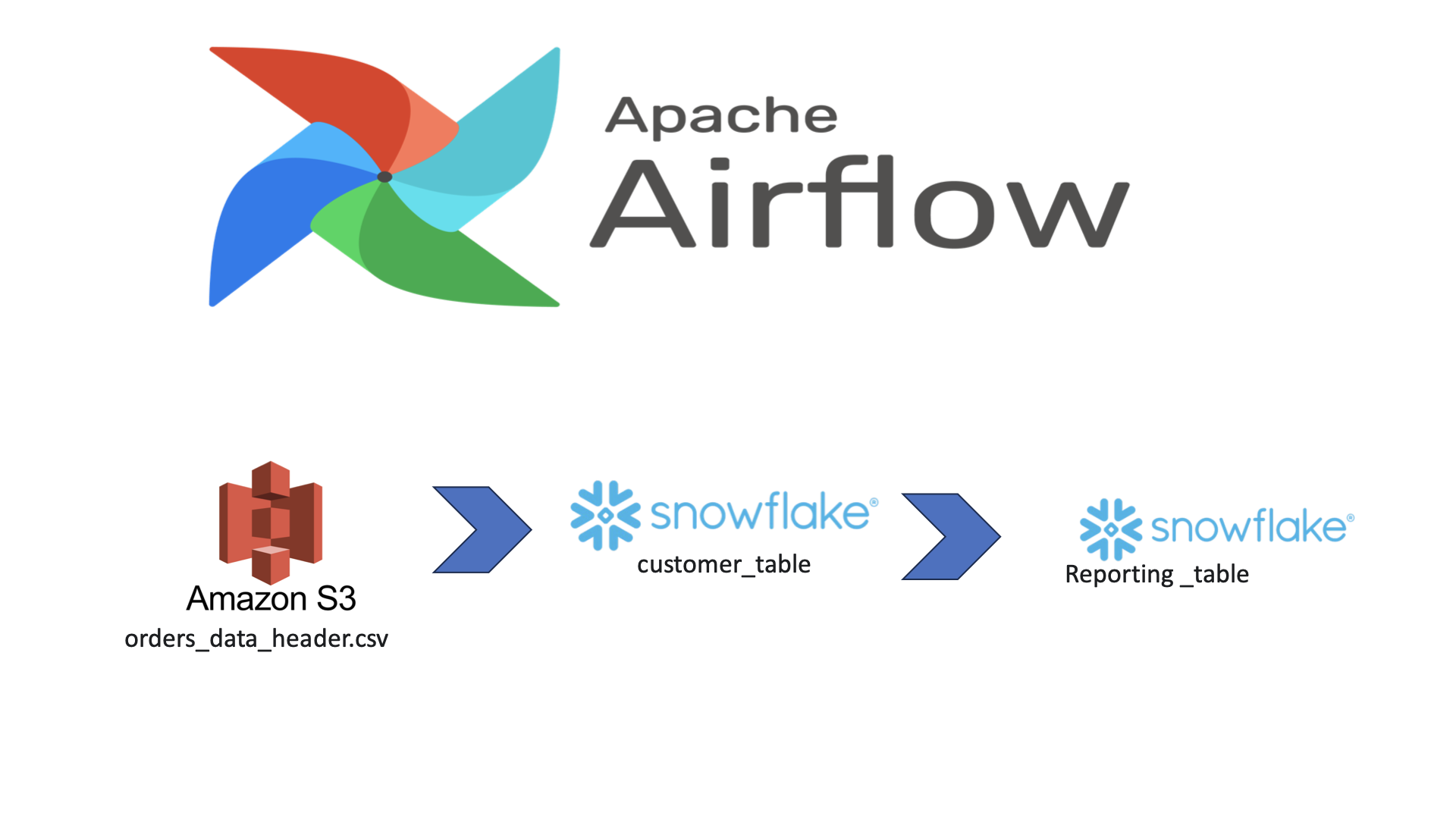
3.ゴールを見てみよう
最終的には、snowflakeにあるテーブルを更新する作業になります。
この一連の作業をAirflowで管理していきます。
今回のゴールとして、以下の表をreporting tableに作成します。
完成したReporting table
| CUSTOMER_ID | CUSTOMER_NAME | ORDER_ID | PURCHASE_DATE | AMOUNT | TYPE |
|---|---|---|---|---|---|
| CUST2 | NAME2 | ORDER2 | 2022-02-02 | 200 | TYPE1 |
| CUST3 | NAME3 | ORDER3 | 2023-03-03 | 300 | TYPE2 |
| CUST4 | NAME4 | ORDER4 | 2022-04-04 | 400 | TYPE2 |
4.構築手順の概要
手順①:orders tableをある値で抽出する
AMOUNTには200以上の値があります。
ただし、oiders tableには200未満のデータがあります。それをまずはreportingテーブルの対象外とします。
orders table
| ORDER_ID | CUSTOMER_ID | PURCHASE_DATE | AMOUNT |
|---|---|---|---|
| ORDER1 | CUST1 | 2022-02-02 | 100 |
| ORDER2 | CUST2 | 2023-03-03 | 200 |
| ORDER3 | CUST3 | 2022-04-04 | 300 |
手順②:orders tableとcustomer tableをmergeする
customer_IDをキーにして結合します。
その後、reporting tableに入れます
customer table
| CUSTOMER_ID | CUSTOMER_NAME | TYPE |
|---|---|---|
| CUST1 | NAME1 | TYPE1 |
| CUST2 | NAME2 | TYPE1 |
| CUST3 | NAME3 | TYPE2 |
手順③:
ここで、Reportingテーブルのスキーマなどは事前に設定されているものとします。
また、先に作られているReporting tableを見ると、エラーと記載されている箇所があります。
これをorders tableとcustomer tableを結合したものを使って更新します
| CUSTOMER_ID | CUSTOMER_NAME | ORDER_ID | PURCHASE_DATE | AMOUNT | TYPE |
|---|---|---|---|---|---|
| error | error | ORDER2 | 2022-02-02 | 200 | TYPE1 |
| CUST3 | NAME3 | ORDER3 | 2023-03-03 | 300 | TYPE2 |
| CUST4 | NAME4 | ORDER4 | 2022-04-04 | 400 | TYPE2 |
5.構築の詳細
5.1 orders_data_header.csvを作成
ローカル上でcsvファイルを作成し、任意のS3バケットを作成し、アップロードしてください。
これをcsvファイルに入力します
order_id,customer_id,purchase_date,amount ORDER1,CUST1,1/1/2021,100 ORDER2,CUST2,2/2/2022,200 ORDER3,CUST3,3/3/2023,300
5.2 Snow flakeのワークシートでcustomer tableとreporting tableを作成
まずは、使用するデータウェアハウスとデータベース等の設定を行います。
CREATE DATABASE ASTRO_SDK_DB;
CREATE WAREHOUSE ASTRO_SDK_DW;
CREATE SCHEMA ASTRO_SDK_DB.ASTRO_SDK_SCHEMA;
その後、作ったスキーマの内にテーブルを作成していきます
CREATE OR REPLACE TABLE REPORTING_TABLE( CUSTOMER_ID VARCHAR(100),CUSTOMER_NAME VARCHAR(100),ORDER_ID CHAR(10),PURCHASE_DATE DATE,AMOUNT FLOAT ,TYPE CHAR(10) );
INSERT INTO REPORTING_TABLE( CUSTOMER_ID,CUSTOMER_NAME,ORDER_ID,PURCHASE_DATE,AMOUNT,TYPE)
VALUES ('error','eroor','ORDER2','2/2/2022',200,'TYPE1'), ('CUST3','NAME3','ORDER3','3/3/2023',300,'TYPE2'), ('CUST4','NAME4','ORDER4','4/4/2022',400,'TYPE2');
CREATE OR replace table customers_table (customer_id CHAR(10),customer_name VARCHAR(100),type VARCHAR(10) );
INSERT INTO customers_table (CUSTOMER_ID , CUSTOMER_NAME,TYPE) VALUES ('CUST1','NAME1','TYPE1'), ('CUST2','NAME2','TYPE1'), ('CUST3','NAME3','TYPE2');
これで、snowflakeとS3の準備は完了です
5.3 Airflowを立ち上げる
次にAirflowを立ち上げます
astro env start
これを入力することで、Dockerが動き、ローカルホストからAirflowを動かすことができます。
ブラウザ上で
localhost:8080
と入力してください
そうすると以下のようなWebが立ち上がるかと思います
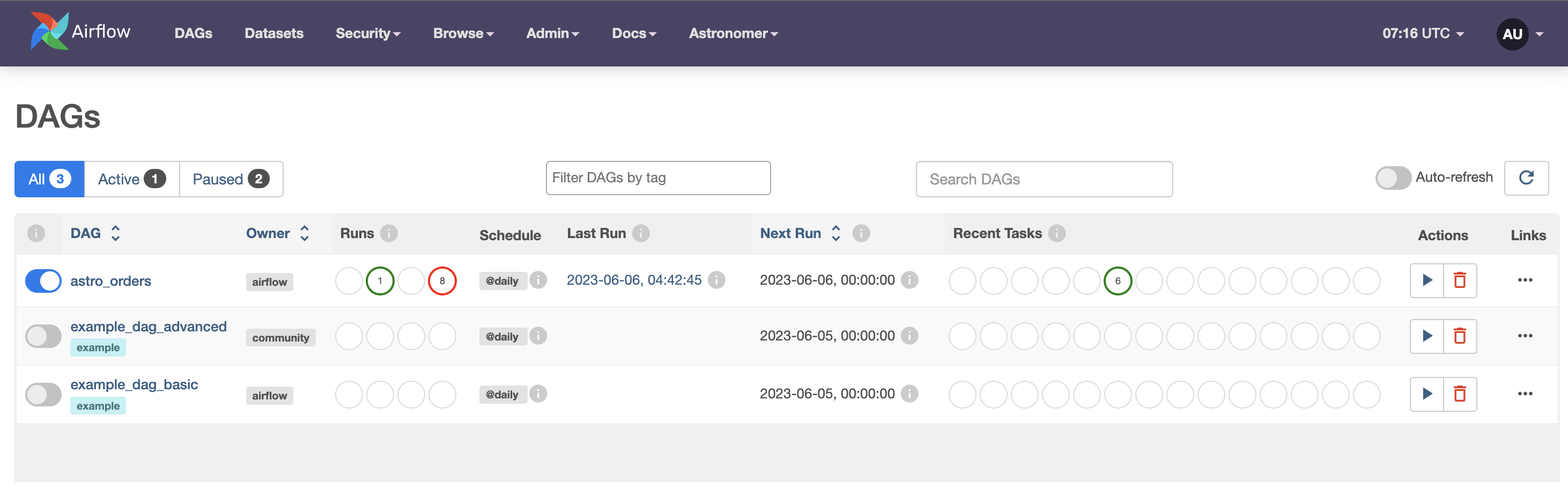
astro_ordersはまだみなさん構築されていないので表示されていないと思います
5.4 AirflowとS3・snowflakeの接続を行う
次にS3とsnowflakesnowflakeの接続を行います。
まずは、AWSのIAMから今回用のユーザーを作成してください
ポリシーは申し訳ありませんが、administoraccessでお願いします
ベストプラクティスなポリシーがわかり次第更新したいと思います。
そこで、作成されたアクセスキーなどはローカル上で大切に保存してください
絶対に外部には漏らさないように。。
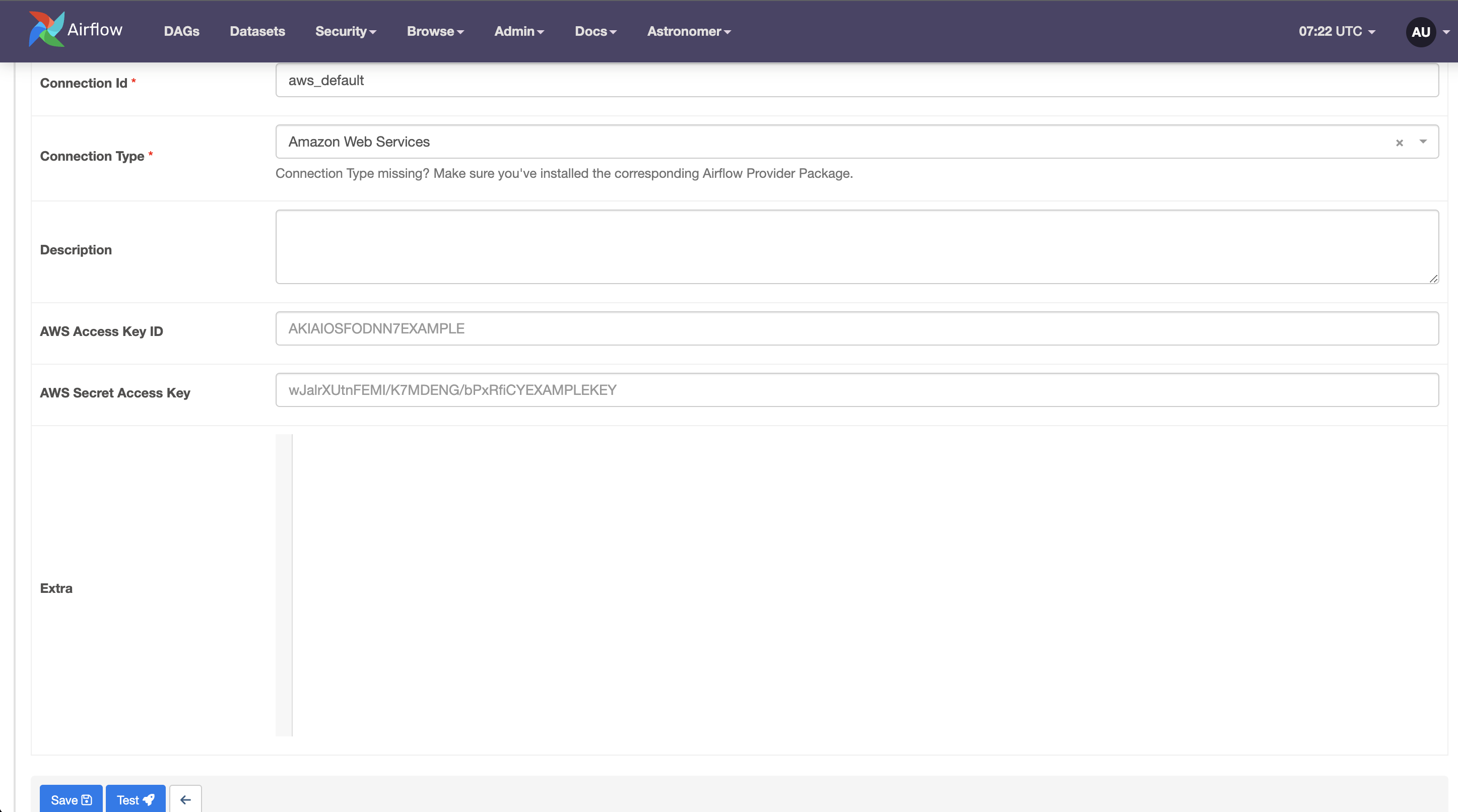
ここで、上のadminからconnectionsに入って、+ボタンを押してください。そうすると以下のような接続が出てくると思います。
connection idはaws_defaultで
connection typeはAmazon Web Serviceとしてください。
ここで、作成したユーザーのアクセスキーを入力してください
その後、Testを入力すると、上のバーが緑で何か記載されると思います。それで設定は完了です。
次にsnowflakeの接続設定をおこなっていきますが、先ほどとあまり変わりません。
作成したウェアハウスやスキーマを設定してください。
ただし、idについては一応snowflake_defaultで統一してください
5.5 DAGの作成
ここまでで、S3とsnowflake、airflowの接続が完了したかと思います。
ここからが、メインになります。
Airflowで動かすコードをpythonスクリプトで記載していきます。
まずは、astro initで作成されたdogsフォルダの中に
astro_orders.pyを作成してください
その作成したastro_orders.pyに以下を記載してください。
from datetime import datetime
from airflow.models import DAG
from pandas import DataFrame
from astro import sql as aql
from astro.files import File
from astro.sql.table import Table
S3_FILE_PATH = "s3://<your_backet>"
S3_CONN_ID = "aws_default"
SNOWFLAKE_CONN_ID = "snowflake_default"
SNOWFLAKE_ORDERS = "orders_table"
SNOWFLAKE_FILTERED_ORDERS = "filtered_table"
SNOWFLAKE_JOINED = "joined_table"
SNOWFLAKE_CUSTOMERS = "customers_table"
SNOWFLAKE_REPORTING = "reporting_table"
@aql.transform
def filter_orders(input_table:Table):
return "SELECT * FROM {{input_table}} WHERE amount >150"
@aql.transform
def join_orders_customers(filtered_orders_table: Table, customers_table: Table):
return """SELECT c.customer_id , customer_name , order_id, purchase_date, amount, type
FROM {{ filtered_orders_table }} f JOIN {{ customers_table }} c
ON f.customer_id = c.customer_id"""
with DAG(dag_id='astro_orders',start_date=datetime(2022,1,1),schedule='@daily',catchup=False):
orders_data = aql.load_file(
input_file = File(
path=S3_FILE_PATH + '/orders_data_header.csv',conn_id=S3_CONN_ID
),
output_table = Table(conn_id = SNOWFLAKE_CONN_ID)
)
customer_table = Table(
name=SNOWFLAKE_CUSTOMERS,
conn_id=SNOWFLAKE_CONN_ID,
)
joined_data = join_orders_customers(filter_orders(orders_data),
customer_table)
reporting_table = aql.merge(
target_table=Table(
name=SNOWFLAKE_REPORTING,
conn_id=SNOWFLAKE_CONN_ID,
),
source_table=joined_data,
target_conflict_columns=["order_id"],
if_conflicts="update",
columns=["customer_id", "customer_name"],
)
これがAirflowを動かすコードになります。
with句のDAGメソッドで全て定義します
-
dag_id='astro_orders': DAGの識別子として "astro_orders" が指定されています。 -
start_date=datetime(2022,1,1): DAGの開始日時が2022年1月1日に設定されています。この日時以前のジョブはスケジュールされません。 -
schedule='@daily': DAGのスケジュールが毎日実行されるように設定されています。**@daily**は、タイムゾーンに基づいて毎日の同じ時間に実行されることを意味します。 -
catchup=False: DAGの実行が開始日からの過去の日時に対してキャッチアップ(遡及)しないように設定されています。つまり、DAGの実行は開始日からの未来の日時にのみ制限されます。
次に、インプットされるデータを指定しています。
conn_idはairflowで設定したidになります。これを統一させたかったので、私の方から指定をしました。
snowflakeのテーブルなどは一旦、astroのTableメソッドで定義します。
astroモジュールのsqlメソッドは非常に便利です。
テーブルをデータフレームとして扱うこともできるようになったり、
デコレータを用いることで、SQL構文で処理を書くことが可能になります。
1つ1つの処理はSQLで記述されているのでみやすいかと思います。
強いて言えば、最後のmergeメソッドでしょうか。
target_conflict_columns
これは、ターゲットテーブルとジョインテーブルがコンフリクトが発生する場所を指定しています。
もし、このカラムがコンフリクトが起きたら、各種カラムをupdateするようになっています。
私たちがやりたいのは、eroorとなっている場所をupdateさせたいんですよね。
そのために、columns
でどこをアップデートさせるのかを指定しているのです。
実際には、どこをアップデートさせるかはわからないので、記述しないことがほとんどなのかもしれませんね。。
てなわけで、指定したフォルダにこれを記述してください。
5.6 Dockerの再起動
内容を変更したので、一度、dockerをstopさせて再度起動させましょう。
docker stop $(docker ps -aq)
asrto dev start
5.7 DAGを実装させる
再度起動させたら、astro_ordersというDAGが追加されていると思います。
名前をクリックし、
Graphをクリックすると以下のようなものが表示されると思います。
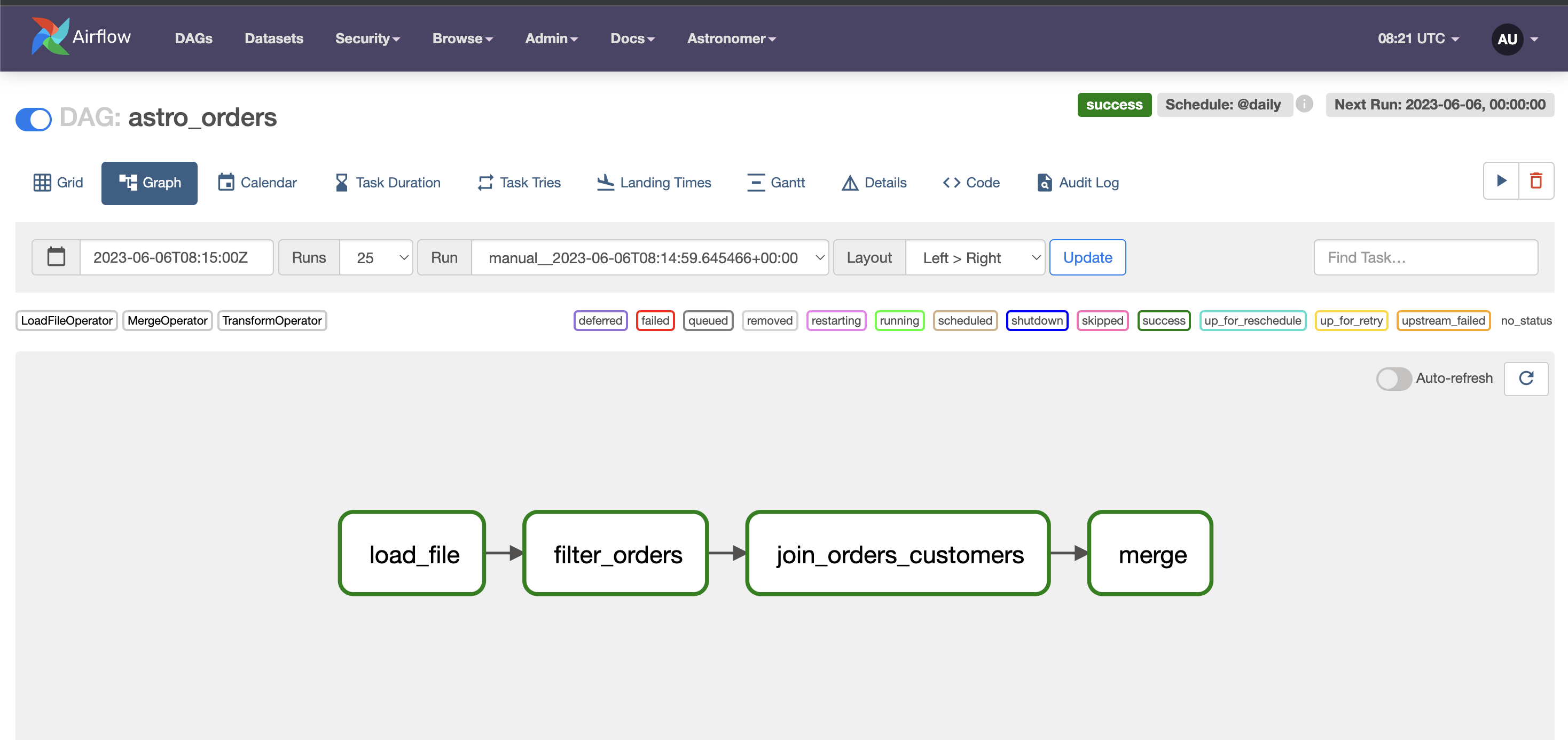
右上のスタート矢印からこのDAGをスケジュール通りではなくそのまますぐ実行できます。
実行させると、どんどん各要素が緑になってくると思います。
すべて緑になれば無事フローが全て完了しました。
snowflakeのワークブックで確認してみると、eroorが上書きされていることがわかります。
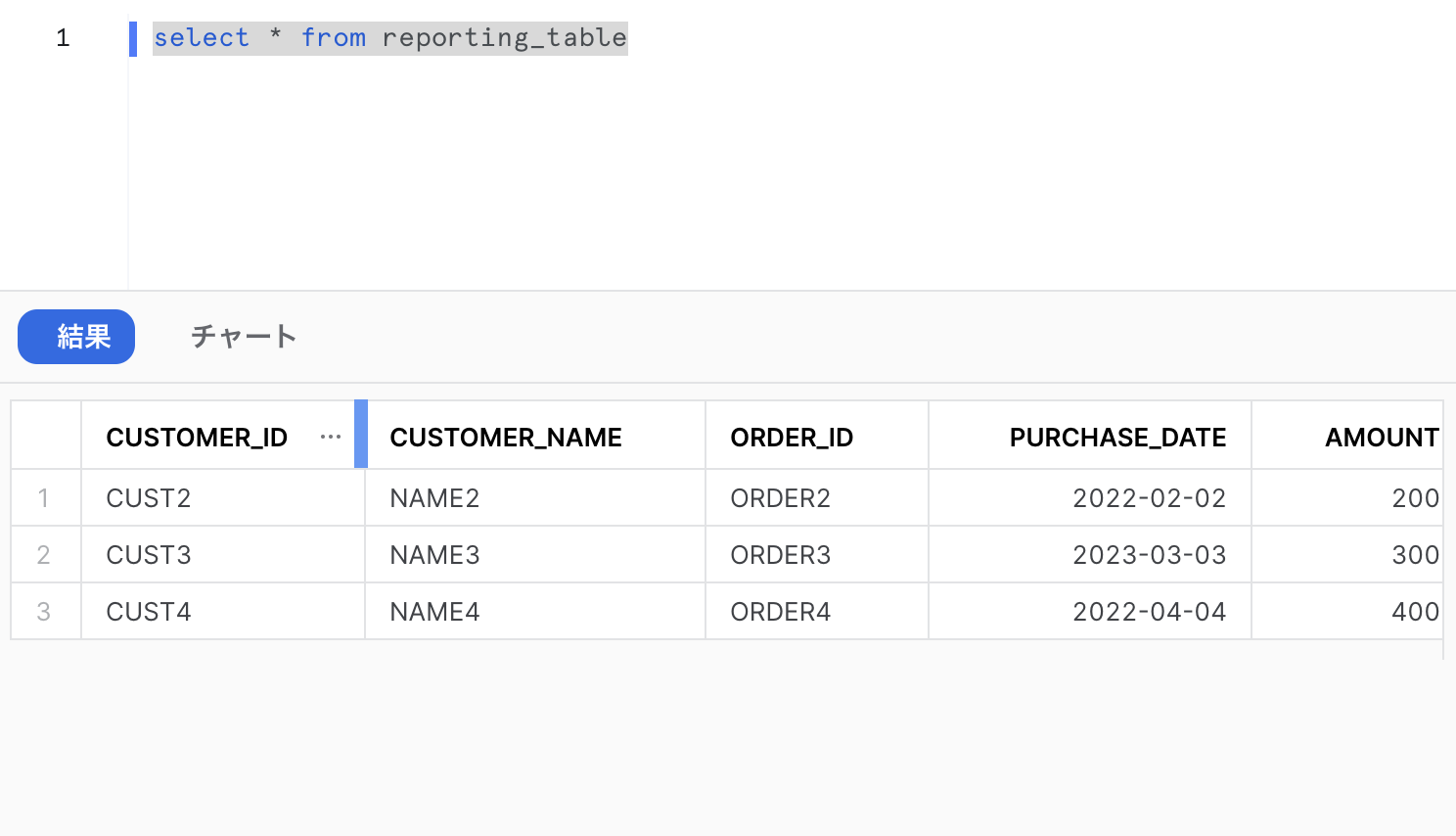
これでゴールになります。
6.総評
いかがだったでしょうか
今回は入門編として、データの読み込みからmergeなど簡単な処理なので、
別にこれ管理しなくても良くない?
となりますが、実務ではそんな簡単な処理だけではなく、この中にさらに機械学習のワークフローや様々なリソースからのデータのマージなどおこなってくると思います。
これを一括で管理するとなるととてもじゃないですが大変です。
これさえあれば、どこでエラーが起きて処理が止まっているのかが一眼でわかります。
これからさらに複雑な処理を書いて、もっと実務レベルの構築をいち早くやってみたいものです。
それでは!!