YOLOv3のアノテーション方法についてまとめます。
アノテーションの手順
私が物体検出したい対象はwebカメラから収集可能です。
その場合は以下のようになります。
- 物体検出したい画像データ群を収集
- 画像データ群を1つの動画にまとめる
- 動画から元サイズと(416,416)サイズの二つ画像データ群を作成
- 元画像サイズデータ群に対してアノテーションを実行
なぞの手間がかかっていると思いますが、
データをごちゃごちゃしたくないのでこのように細分化しました。
画像は3チャンネル(RGB)であることに注意。
1. 物体検出したい画像データ群を収集
参考コードとかは特にありません。
こればかりは自分の努力に成果は比例します(泣)。
2. 画像データ群を1つの動画にまとめる
連番画像から動画を作成するコード。
1から1000枚まで読み込み、動画用オブジェクトに書き込む。
しかし連番の末端まで行くとスキップし、動画作成を終了させるする。
できれば、連番の画像ファイルの枚数を取得できると楽になる。
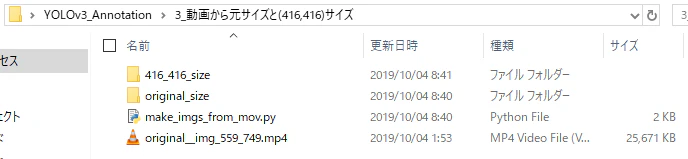
フォルダの中身

参考コード
import cv2
# フレーム番号
f_num =1
# 画像パス
img_path = "movie_img/pic_{}_.png"
# 画像の読み込み
img = cv2.imread(img_path.format(f_num))
# 画像のサイズを取得
img_h, img_w, img_channels = img.shape[:3]
# 画像のサイズを表示
print(img_h, img_w, img_channels)
# 動画用fourcc
fourcc = cv2.VideoWriter_fourcc('m','p','4','v')
# 動画パス
mov_path = "oiginal__img_{}_{}.mp4".format(img_h, img_w)
# 動画作成関数
video = cv2.VideoWriter(mov_path. format(img_w, img_h), fourcc, 20.0, (img_w, img_h))
# for文で動画作成
for i in range(1, 1001):#1-1000まで
#画像の読み込み
img = cv2.imread(img_path.format(i))
#画像があるとき
if not img is None:
#動画に書き込み
video.write(img)
# 終了
video.release()
3. 動画から元サイズと(416,416)サイズの二つ画像データ群を作成
動画から2つのデータ群を作成する。
このときに、画像の拡張子はjpgを推奨します。
理由は後でわかると思います。
-
元画像サイズの使用目的
- アノテーション用に作成。
-
(416,416)の画像サイズの使用目的
- YOLOv3の学習用に保持。
フォルダの中身
参考コード
import cv2
# 動画パス
filepath = "original__img_559_749.mp4"
# 動画の読み込み
cap = cv2.VideoCapture(filepath)
# オリジナルか(416, 416)かを問う
check_img_size = int(input("""オリジナルサイズは1, (416,416)サイズは0 を入力してください
"""))
if int(check_img_size) == 1:
# 動画のサイズ
mov_h = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
mov_w = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
#画像保存用パス
img_path = "original_size/pic_({})_.jpg"
else :
# 動画のサイズ
mov_h = 416
mov_w = 416
#画像保存用パス
img_path = "416_416_size/pic_({})_.jpg"
# フレーム番号
f_num = 0
# 動画終了まで繰り返し
while(cap.isOpened()):
#フレーム番号
f_num = 1 + f_num
# フレームを取得
ret, frame = cap.read()
# 動画再生内のcapがない場合
if ret != True :
break
if int(check_img_size) != 1:
#リサイズ
frame = cv2.resize(frame, (mov_h, mov_w))
# フレームを保存
cv2.imwrite(img_path.format(f_num), frame)
# フレームを表示
cv2.imshow("Frame", frame)
# qキーが押されたら途中終了
if cv2.waitKey(1) & 0xFF == ord('q'):
break
4. 元画像サイズデータ群に対してアノテーションを実行
これから元画像に対してアノテーションをしようと思います。
なぜ(416, 416)サイズにアノテーションをしないかというと、
元画像(559, 749)のほうが画像サイズとしては大きいので
アノテーションしたときの信頼度が多少高くなるのではないかと考えています。
結局、(416, 416)サイズに圧縮したアノテーションデータを作成するので、各自にお任せします。
アノテーションツールとして、AnnotationTool.exeを使わせていただきました。
AnnotationTool.exeはEeePCの軌跡様が独自で開発したアプリです。
AnnotationTool.exeのダウンロードリンクはこちらです。
非常にお世話になっております。
AnnotationTool.exeの使い方
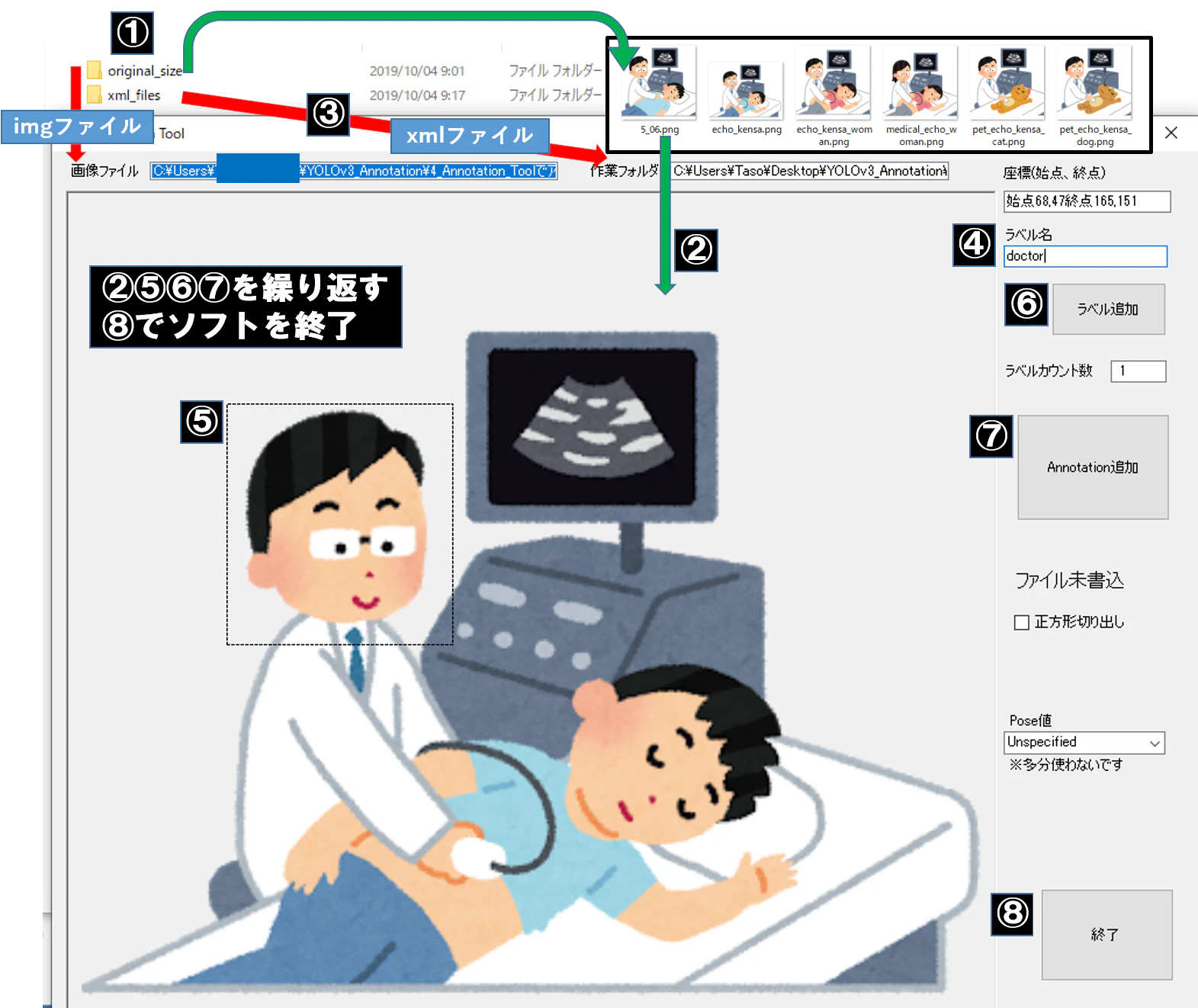
①画像データ群フォルダ(original_size)とアノテーションフォルダ(xml_files)を作成
②画像データ群フォルダから画像を一枚選択し、中に入れる
③ソフト内の作業フォルダにアノテーションフォルダを入れる
④ソフト内のラベル名にクラス名を記述
⑤検出したい物体をマウスで囲む
⑥ソフト内のラベル追加をクリック
⑦ソフト内のAnnotation追加をクリック
②⑤⑥⑦を繰り返し、データをたくさん作ります。
アノテーションが全て終わったら、
⑧ソフト内の終了をクリック
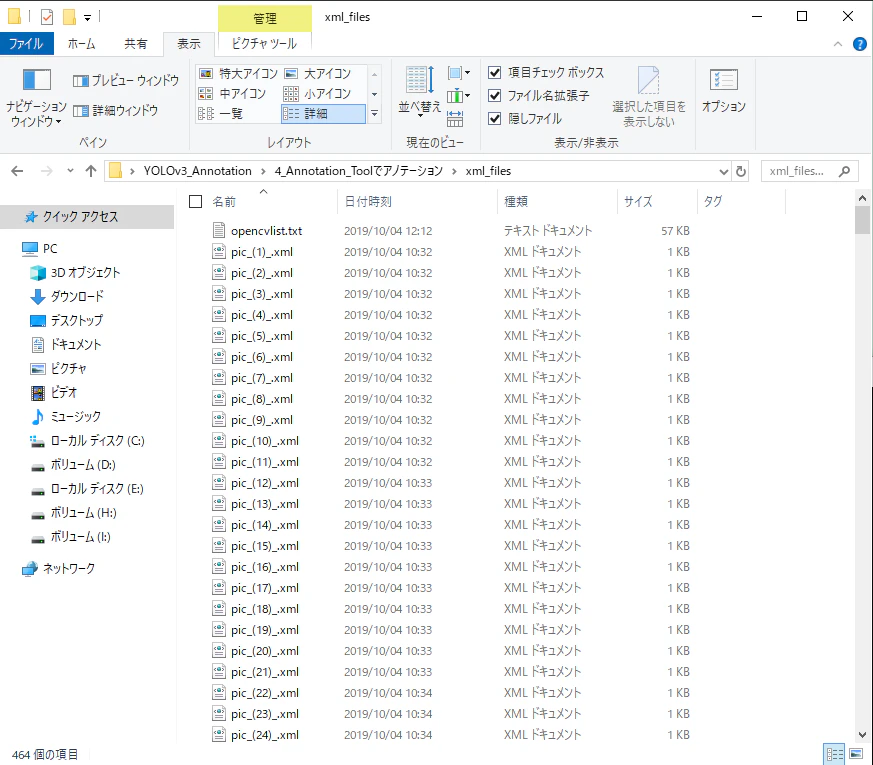
YOLOv3で学習するときにアノテーション情報にミスがあると、学習ができません。
その理由の一つとして、1つのアノテーションに対してラベリング追加を二回クリックして、余分に情報を追加してしまった可能性があります。
確認方法として、アノテーションフォルダ内にopencvlist.txtを確認すると誤りのあるデータを見つけられます。
アノテーションできることを、心からお祈り申し上げます。
次はアノテーションデータ(Pascal VOC形式のxmlファイル)の独自に加工してみたいと思います。
アノテーションデータの作成結果
参考文献
最新の物体検出YOLO v3 (Keras2.2.0+TensorFlow 1.8.0)を独自データで学習できるようにしてみた
KerasのYOLO-v3を動かしたった
物体検出でパトライトの監視(YOLOv3)
Pascal VOC形式のxmlファイルをPythonで読む