初期値が気になった
深層学習だとよくハイパーパラメータが大切なんて聞きますが、重みとかの初期値ってどうなんでしょう。相当重要な気がしますが・・・。
調べてみて軽く比較してみました。考察とかはしないので各自で解釈していただければ。(そして教えていただければ・・・)
比較対象
- 活性化関数
- ReLU
- Sigmoid
- 重み
- He
- Xavier
- バイアス
- np.zeros
- np.rand
- np.randn
使用するデータ
ゼロから作るDeep Learning2に載ってたやつ
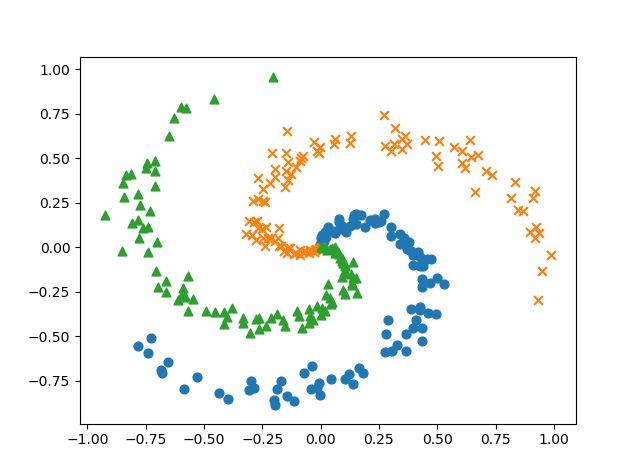
比較結果
he, zeros
relu
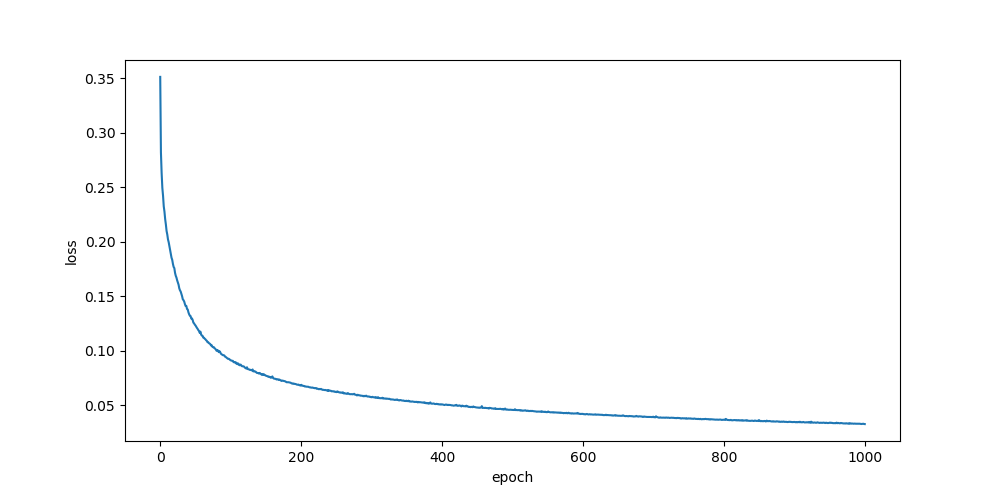

sigmoid
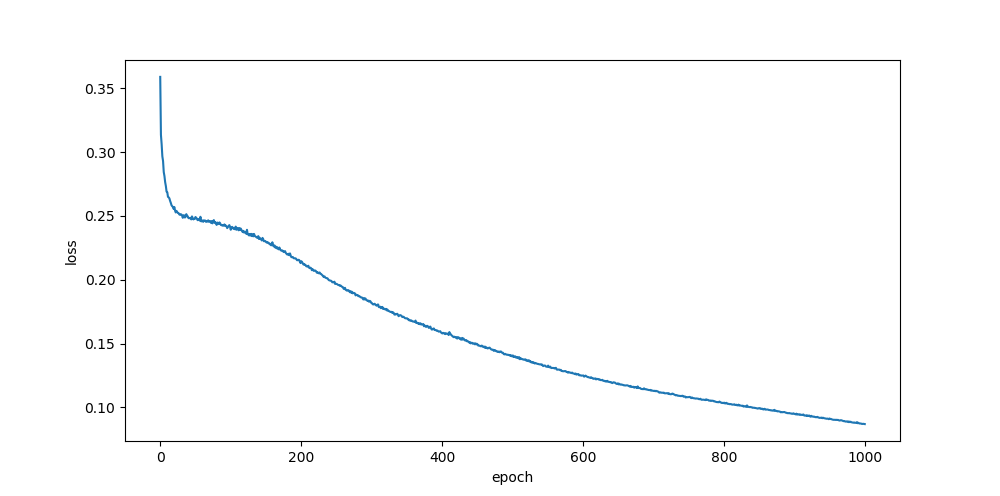

xavier, zeros
relu

sigmoid
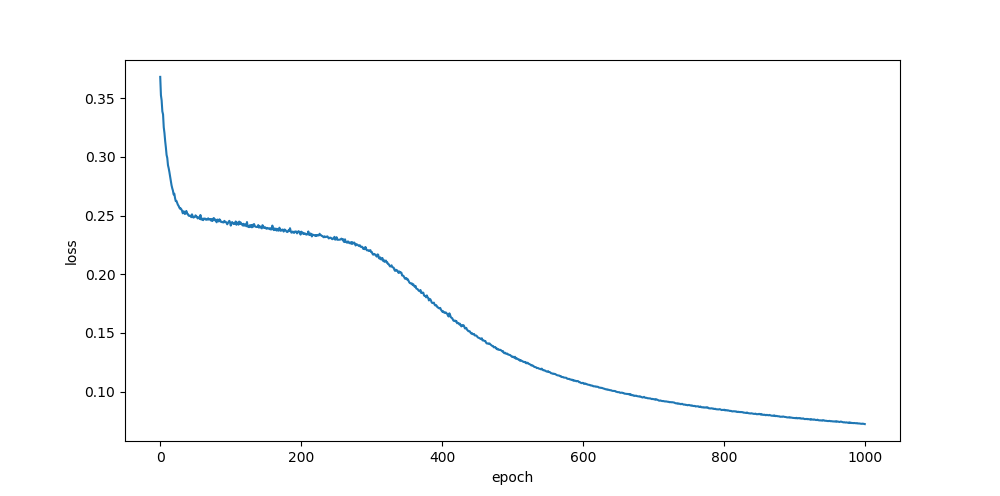

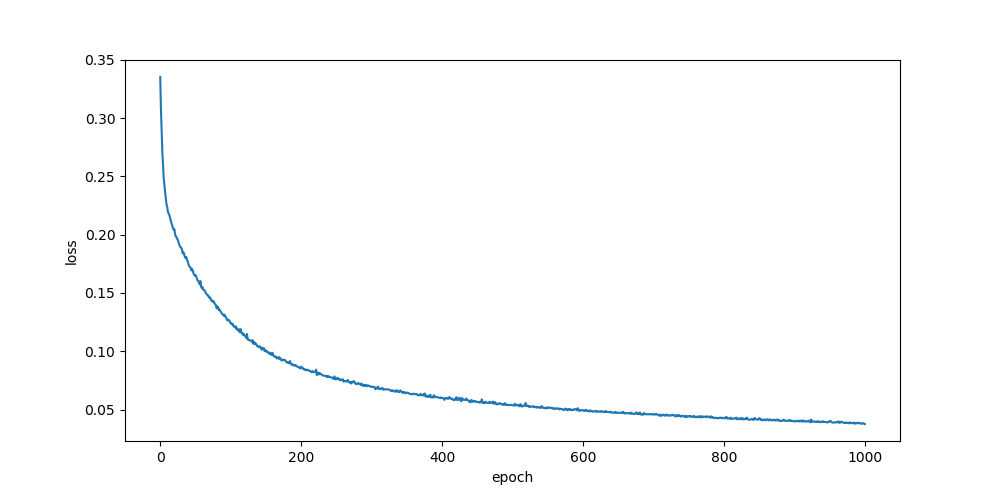
he, uni
relu
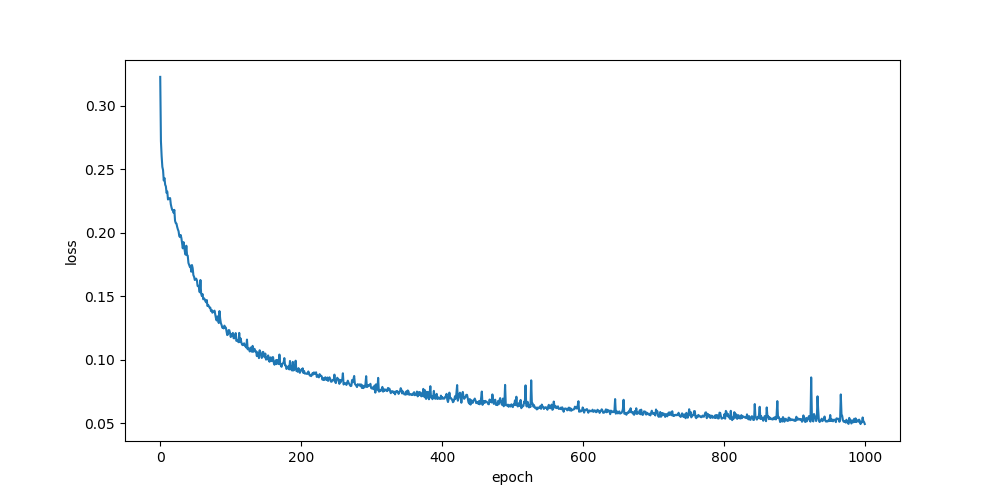

sigmoid
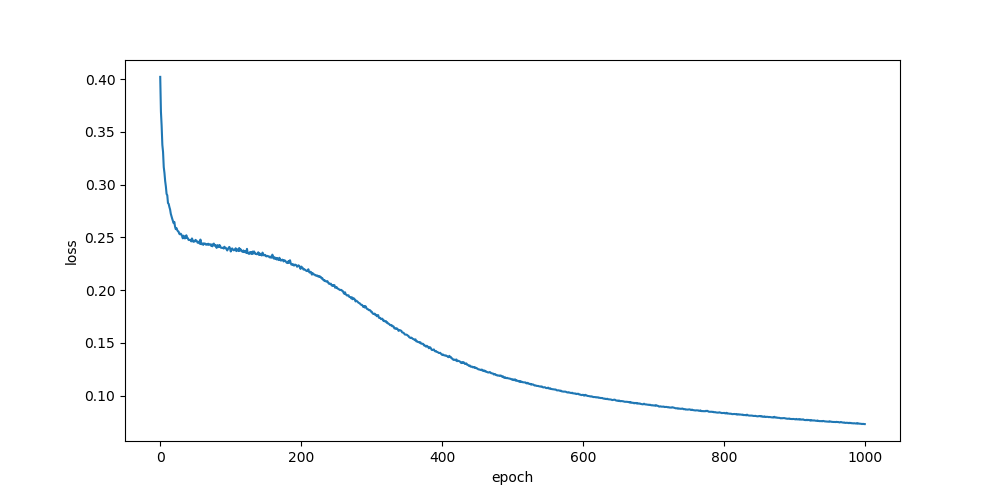

he, randn
relu
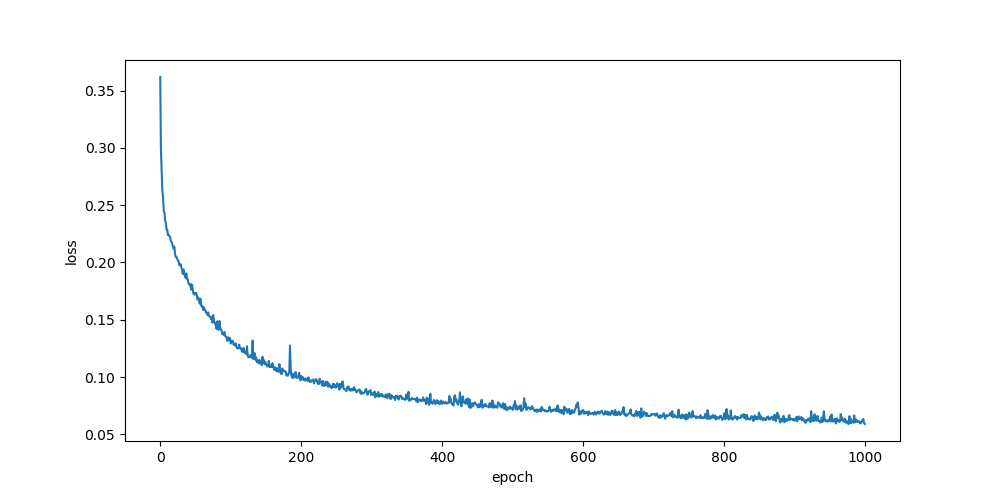

sigmoid
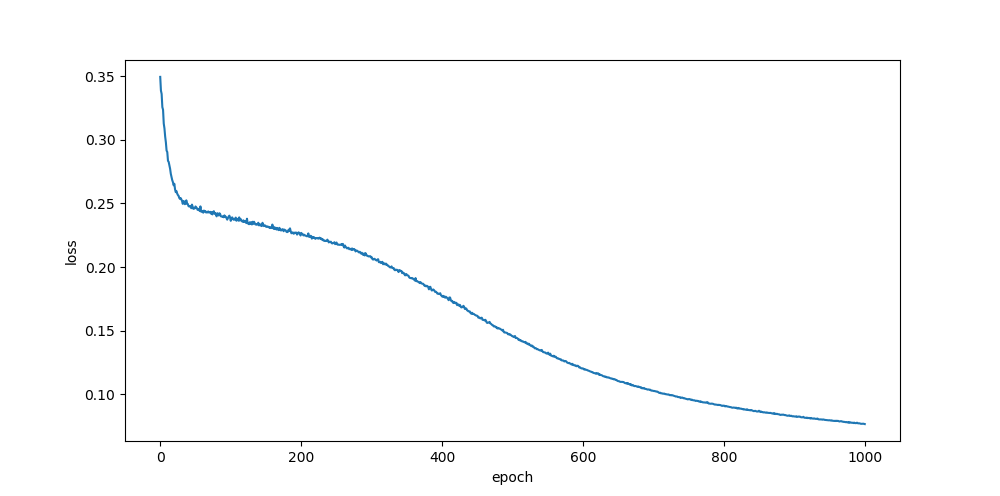

he, rand
relu
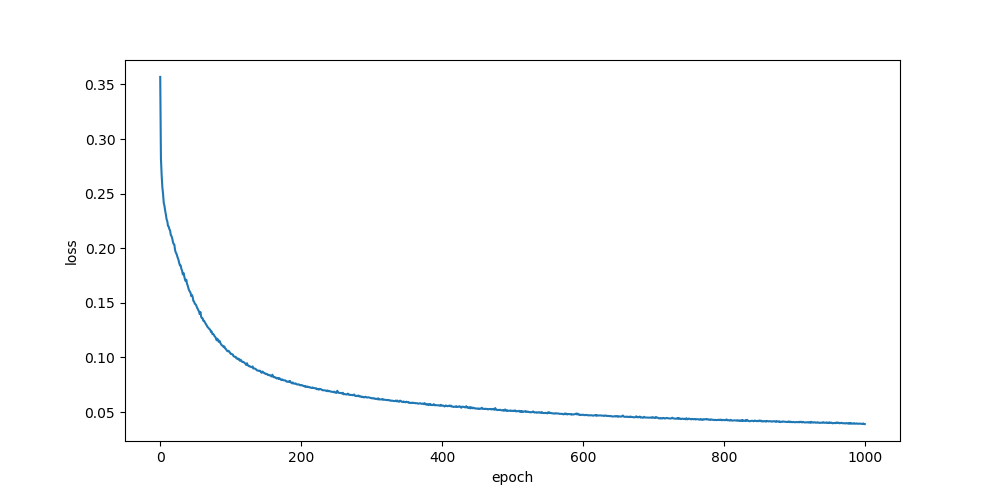

sigmoid
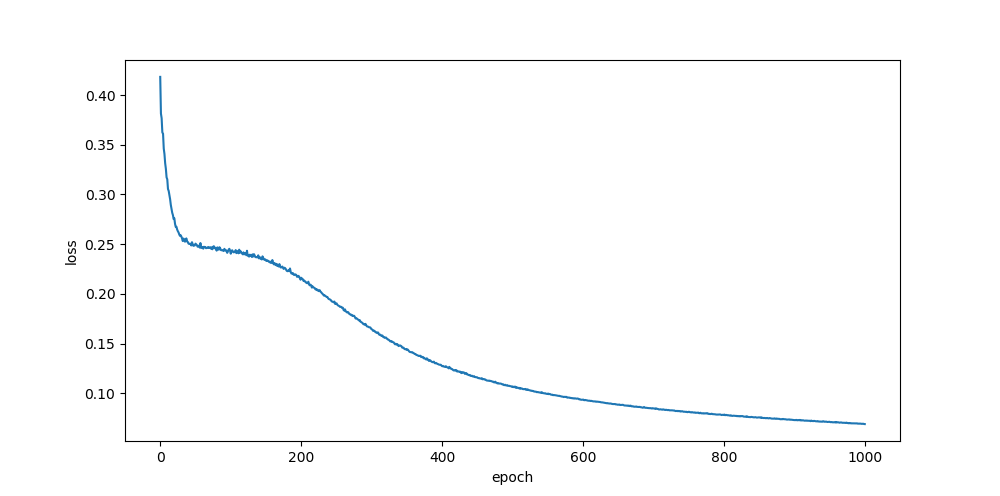

xavier, randn
relu
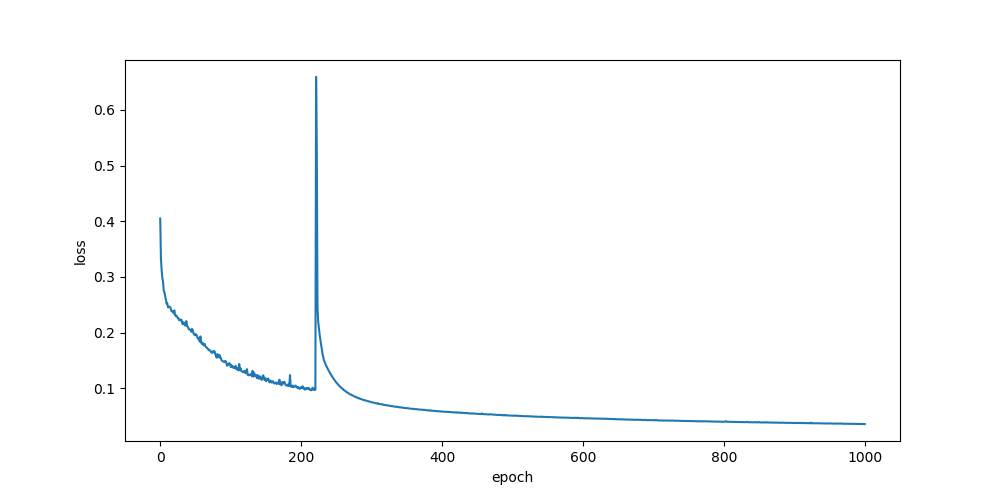

sigmoid
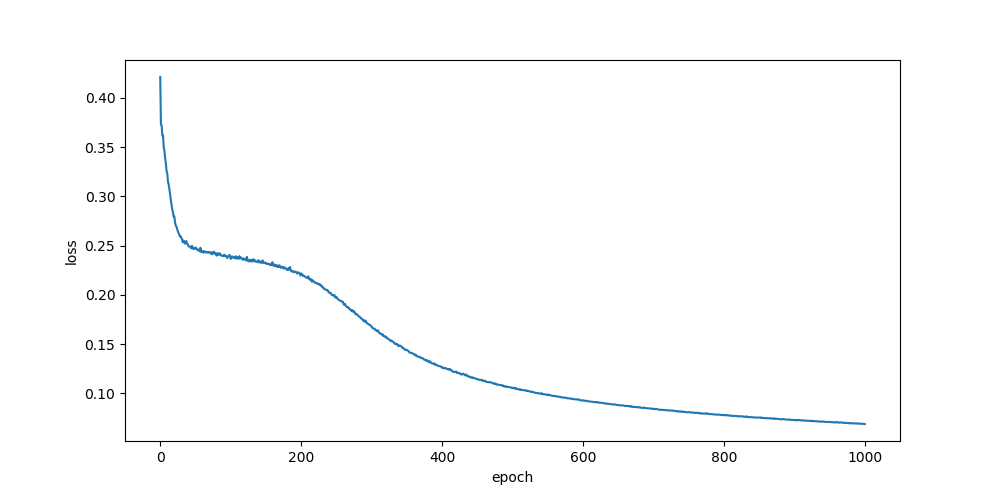

xavier, rand
relu
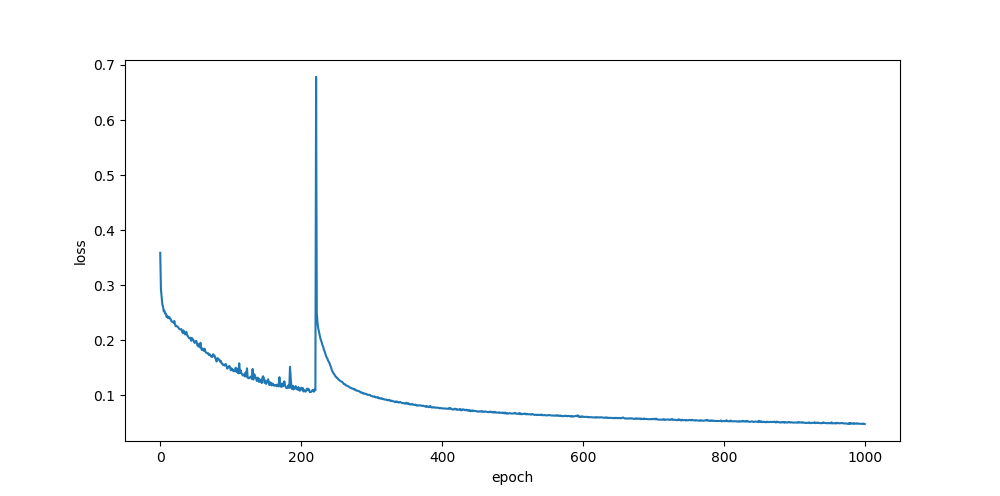

sigmoid

感想
とりあえずhe, zerosにしとけばいい感じですかね。
それにしてもバイアスで結構変わるものですね、正直舐めてました。