はじめに
この記事はInfocom Advent Calendar 2022の21日目の記事です。
最近、ChatGPTなどの大規模言語モデルを利用した自然言語生成 (NLG) が話題ですね。私もChatGPT によく人生相談をしています。
今日はこのNLGにおけるHallucinationについての論文を少し読んだので簡単に論文紹介をしたいと思います。
目次
- Survey of Hallucination in Natural Language Generation
- そもそもHallucinationとは何か?
- なぜHallucinationが起きるのか?
- 緩和策について
- さいごに
Survey of Hallucination in Natural Language Generation
Survey of Hallucination in Natural Language Generation
こちらはNLGの各タスクにおけるHallucinationについて調査した論文です。
今回はこの論文を参考になぜHallucinationが起きるのかや、その緩和方法について紹介します。
そもそもHallucinationとは何か?
言語生成モデルにおけるHallucinationとは、言語生成モデルが入力に対し、理解できるが忠実でない生成を行う現象のことを指します。
例えば、以下のような入力から抽象的要約をするタスクがあったとします。(以下は論文の英文をDeepL翻訳したものです。)
ソース(入力):エボラ出血熱の最初のワクチンは、2014年の最初の発生から5年後の2019年、米国でFDAに承認されました。ワクチンを製造するために、科学者たちはエボラのDNAの配列を決定し、次に可能性のあるワクチンを特定し、最後に臨床試験の成功を示さなければならなかった。科学者たちは、臨床試験はすでに始まっているものの、COVID-19のワクチンが今年中に準備できる可能性は低いと言っています。
このソースに対し、言語生成モデルが以下の出力をします。
言語生成モデル(出力):2021年に最初のエボラワクチンが承認されました。
ですがソースに書かれているのは「5年後の2019年、米国でFDAに承認されました。」であり、明らかにソースとは異なった出力結果になっています。
もう一つの出力例だと
言語生成モデル(出力):中国はすでにCOVID-19ワクチンの臨床試験を開始しています。
こちらはソースに中国に関連する情報がない為、事実なのかそうでないのか判断できません。
このように、ソースに対して明らかに異なっていたり、事実なのか判断できない出力結果のことをHallucinated textと言います。また、本論文では前者は「Intrinsic Hallucinations」、後者を「Extrinsic Hallucinations」と呼んでいます。
言語生成モデルに触ったことがある人ならもしかしたら感じたことがある話だったかもしれません。
なぜHallucinationが起きるのか?
論文では大きく2つの要因があると書いています。
1. データからのHallucination
当たり前ですが、言語モデルを学習させるデータ自体に事実と異なる内容が入っていれば、モデルが学習した内容に沿って生成する際に、事実と異なる結果を出します。
また、大規模なデータセットを作成する際にヒューリスティック(直感的)にソースとターゲットを選択する方法で収集すると、ソースには含まれていない情報がターゲットに入ってしまう可能性があります。この「ソースとターゲットの不一致性」によってHallucinationが起きている可能性があると書かれていました。
2. 訓練と推論からのHallucination
本論文では、ニューラルモデルの学習とモデリングの選択によってもHallucinationが起こると書かれています。例えば、テキストをベクトル化するエンコーダ(もっといえば表現学習)の時点で、学習データの意図しない部分の相関関係を学習した場合に、入力から乖離した生成に繋がります。また、同様にエンコーダの結果から、意図しない部分に注目するデコーダであれば、Hallucinationが起こるとされています。
また、学習時と推論時のでデコーディングの不一致がHallucinationの原因であるとも書かれていました。学習する際は答えが明確にあるテキストから次のテキストを予測しますが、推論時では、以前に生成された履歴に基づき次のテキストを生成するため、生成物(テキスト)が長くなると段々と辻褄が合わなくなっていき、Hallucinationに繋がる可能性があるとされています。
言われてみると確かに言語生成モデルに連続で生成させると、前に生成した文とは矛盾し始めたり…と思い当たる節が合ったりします。またデータの質については以前から話題になっていたり、将来データが不足する話も聞いたりしますね。
Hallucination緩和方法について
Hallucinationが起きる要因に対応して緩和策が書かれていました。
全く解消される訳ではなくあくまでも「Mitication(緩和)」と書かれていることに問題の根深さを感じます…
1. データに関する方法
「アノテータを利用しソースから綺麗で忠実なターゲットをゼロから生成すること」と書かれていました。一番の理想的だ…とも思ったのですが、一方で「多様性に欠ける可能性がある」とも書かれていて、Hallucinationと多様性はトレードオフなのかも?と思い始めました。また、何をHallucinationとするのかの定義や指標がしっかり定まっていて、元データ内のノイズが中程度であれば、自動でフィルタリングする方法も提案されていました。
2. モデリングと推論方法
本論文で書かれていた三つの手法について紹介します。
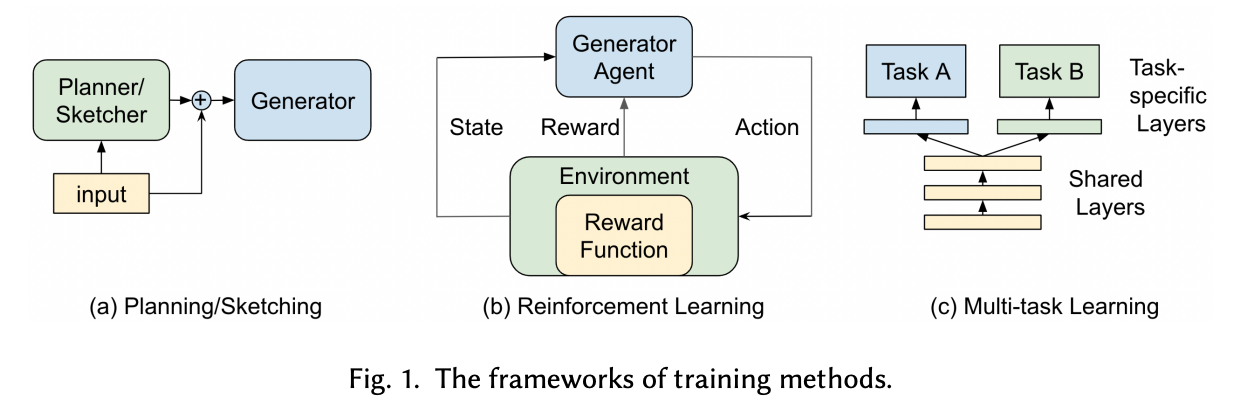
(Survey of Hallucination in Natural Language Generationより引用)
-
Planning/Sketching
モデルの学習の際にどの単語をどのタイミングで使うかなどの情報をinputに加えることで、どの単語を意識してテキストを生成すれば良いかをモデルに学ばせることができます。ただ、制御性を高める一方で多様性が減少する可能性があり、このバランスを取る必要があると書かれていました。 -
Reinforcement Learning (RL)
適切なReward関数を使ってモデルを学習させれば、Hallucinationを減らすのに役に立つと書かれていました。
本論文の話とは逸れますが、OpenAIのブログに「Aligning Language Models to Follow Instructions(指示に従うための言語モデルを揃える)」という記事があります。ChatGPTの前身であるInstructGPTは、強化学習を使ったことによってHallucinationが軽減されたようです。
結果を見る限りだと確かに効果がありそうですが、じゃあ「適切なReward関数って…?」となっています…まだ調べてきれていません。 -
Multi-task Learning
複数のタスクを用いて同時に学習させる方法。本論文では、単一のデータセットに依存した学習プロセスのためにモデルが実際のタスクの特徴を学習出来ないことがHallucinationの起因だと書かれています。そのためにメインタスクで学習するのと同時に、そのメインタスクに合ったタスクで学習させることで、Hallucinationを低減する可能性があります。
本論文の例だと「抽象的要約」と「含意関係認識」を組み合わせより原文に忠実な要約を生成するようになるようです。
個人的にはタスク特化言語生成ならマルチタスク学習で良いと思いますが、汎用性や話題性を考えると強化学習を使ってみたい…という気持ちです。
さいごに
個人的にはHallucinationというNLGにおける課題があり、それに取り組んでいる研究があることを紹介できたらと思い、この記事を書きました。
言語モデルは生成されるテキストは自然で、思わず鵜呑みにしてしまいますが、「もしかしたらこれHallucinationかも?」と意識して頂けたら幸いです。