はじめに
以前、マイナンバーのチェックデジットを計算したことがあります。
このときはTwitterのTLで謎の盛り上がりが発生してSIMD化されてしまうのでした。
さて、今回のお題は法人番号です。なにかとネタを提供し続けてくれる @AinoMegumi 氏が次のようなコードを見せてきました。
#include <string>
#include <vector>
#include <unordered_map>
#include <regex>
#include <utility>
#include <algorithm>
namespace CalculationImpl {
namespace {
void ReplaceString(std::string& src, const std::string& oldStr, const std::string& newStr) noexcept {
std::string::size_type Pos(src.find(oldStr));
while( Pos != std::string::npos ) {
src.replace(Pos, oldStr.length(), newStr);
Pos = src.find(oldStr, Pos + newStr.length());
}
}
}
inline bool CheckArg(const std::string& val) {
static const std::regex r(R"([0-90-9]{12,36})");
return std::regex_match(val, r);
}
inline void ConvertNumTextToHalfSizeString(std::string& str) {
ReplaceString(str, "0", "0");
ReplaceString(str, "1", "1");
ReplaceString(str, "2", "2");
ReplaceString(str, "3", "3");
ReplaceString(str, "4", "4");
ReplaceString(str, "5", "5");
ReplaceString(str, "6", "6");
ReplaceString(str, "7", "7");
ReplaceString(str, "8", "8");
ReplaceString(str, "9", "9");
}
inline std::vector<unsigned long> SplitAll(const std::string& str) {
static const std::regex r(R"([0-9]{12})");
if (!std::regex_match(str, r)) return {};
std::vector<unsigned long> Ret{};
for (const auto& i : str) Ret.emplace_back(static_cast<unsigned long>(i - '0'));
return Ret;
}
inline unsigned long CalcCheckDigit(const std::vector<unsigned long>& arr) {
if (arr.size() != 12 || std::any_of(arr.begin(), arr.end(), [](const unsigned long& v) { return v > 9; })) return 0;
bool b = false;
unsigned long TotalBuf[2] = { 0, 0 };
for (const unsigned long& i : arr) TotalBuf[std::exchange(b, !b)] += i;
return 9 - ((TotalBuf[0] * 2 + TotalBuf[1]) % 9);
}
}
ただしこれには下のようにいくつか個人的に好きではない点があるので書き直した意欲が湧きてきたのです。
- 文字列置換がある
- いわく
0-90-9が入り乱れても対応できるようにとのことだけど文字列置換は本当に必要なのか
- いわく
- SplitAllして
std::vector<unsigned long>に持ち込む意味とは- 本人も手元ではそれをやめたと言っていた
- 正規表現で入力の検査をするのをやめたい
-
TotalBuf[std::exchange(b, !b)]がなんかいやだ
というわけで書き換えていきましょう。
法人番号のチェックデジット
その前に計算方法の確認です。国税庁直々にわかりやすい計算方法解説をしてくれているのでそれを見ましょう。

元のコードはこれに忠実に従っていることがわかります。
入力の検査
UTF-8での0-9と0-9の共通性
まずUnicodeにおいていずれでも数値は連続したコードポイントになります。
つぎにUTF-8にエンコードしたときの様子を見ていきます。
-
0:30 -
0:EF BC 90
ここで最後のbyteを抜き出してよく見てみます
| 16進数 | 2進数 |
|---|---|
| 30 | 0011 0000 |
| 90 | 1001 0000 |
つまり上位4bitが0011ないし1001になっていれば入力は正しい可能性があると言えそうです(検証1段階目)。
下位4bitについて考えます。0x0-0xFの範囲のうち、有効なのは0x0-0x9の範囲です。つまり上位4bitをマスクしてみたときに9以下であればいいわけです。とってもシンプルですね(検証2段階目)。
入力文字列から必要な部分を抜き出して__m128iに格納する
これは腕力で書きます。配列外参照だけしないように気をつけて。なお、UTF-8において何byteにエンコードされるときの先頭byteが何になるかはきちんと定義があるのですが、どうせその後の検証で落ちて問題なくなるのでサボっています。
static inline const auto zero = _mm_set1_epi8(0);
/**
* 入力文字列から必要な部分を抜き出して`__m128i`に格納する
*
* 0-9の場合、`EF BC 9x`となるので3byte目の`9x`の部分を格納する
* 0-9の場合、`3x`となるので1byte目の`3x`の部分を格納する
* @param s 入力文字列
*/
inline __m128i gather_target_bytes(std::string_view s) noexcept
{
if (s.length() > 12 * 3) return zero;
alignas(16) char ret[16]{};
std::size_t i, j;
for (i = 0, j = 0; i < 12 && j < s.length(); ++i, ++j) {
constexpr std::byte expected[] = { std::byte(0xEF), std::byte(0xBC) };
const bool b = (j + 2 >= s.length() || std::memcmp(s.data() + j, expected, 2) != 0);
ret[i] = b ? s[j] : s[j += 2];
}
return (j != s.length()) ? zero : _mm_load_si128(reinterpret_cast<__m128i*>(ret));
}
検証1段階目
namespace bits_for_validate {
static inline const auto mask_extract_significant_bit = _mm_set1_epi8(0b1111'0000);
static inline const auto valid_pattern_alphabetic = _mm_set1_epi8(0b0011'0000);
static inline const auto valid_pattern_full_width = _mm_set1_epi8(0b1001'0000);
}
//16要素詰め込めるところを12要素しか詰め込んでいないので残りの部分は判定からはずすためのmask
static inline const auto mask_valid_bits = _mm_setr_epi32(-1, -1, -1, 0);
/**
* 各byteの上位bitが0-9もしくは0-9のものであることを検証する
* @param x 8bit整数が格納された`__m128i`
*/
inline bool validate_phase1(const __m128i& x) noexcept
{
using namespace bits_for_validate;
// 下位桁(0x0-0xF)はvalidate_phase2で見るので一旦mask
const auto masked = _mm_and_si128(x, mask_extract_significant_bit);
// 0-9が格納されたbyteでは0になる
const auto distance_alphabetic = _mm_sub_epi8(masked, valid_pattern_alphabetic);
// 0-9が格納されたbyteでは0になる
const auto distance_full_width = _mm_sub_epi8(masked, valid_pattern_full_width);
// AND演算すれば0-9もしくは0-9が格納されたbyteでは0になる
const auto distance = _mm_and_si128(distance_alphabetic, distance_full_width);
// 12要素分全部0なら正しい
return _mm_test_all_zeros(distance, mask_valid_bits) == 1;
}
上位4bitが0011ないし1001になっているというのは言い換えると、
下位4bitをマスクした後に00110000ないし10010000を引き算したとき(_mm_sub_epi8)、いずれかが0になるということを意味します。
どちらかの結果が0になってることを調べるにはAND演算すればいいのでそうします(_mm_and_si128)。
あとは12byte分についてどのbitも立っていなければ検証1段階目は完了です(_mm_test_all_zeros)。
検証2段階目
static inline const auto mask_get_value = _mm_set1_epi8(0b0000'1111);
inline int calc(std::string_view s) noexcept
{
const auto gathered = gather_target_bytes(s);
if (!validate_phase1(gathered)) return 0xFF;
// 下位桁(0x0-0xF)をとってくる
const auto value = _mm_and_si128(gathered, mask_get_value);
というわけで以降上位4bitはいらないのでmaskしておきます。
9以下であることを調べる方法はまあいろいろあると思いますが、ここで以前 @mtfmk さんに
// 11文字に'0'から'9'以外が含まれていればfalseを返す
static inline bool validate(const __m128i& x)
{
__m128i t = _mm_sub_epi8(x, _mm_min_epu8(x, _mm_set1_epi8(9)));
return _mm_test_all_zeros(t, _mm_setr_epi32(-1, -1, 0x00FFFFFF, 0)) == 1;
}
こんなコードをもらっていたことを思い出します。
するとこんなふうに書き換えれば良さそうです
//16要素詰め込めるところを12要素しか詰め込んでいないので残りの部分は判定からはずすためのmask
static inline const auto mask_valid_bits = _mm_setr_epi32(-1, -1, -1, 0);
/**
* 各byteで9以下であることを検証する
* @param x 8bit整数が格納された`__m128i`
*/
inline bool validate_phase2(const __m128i& x) noexcept
{
const __m128i t = _mm_sub_epi8(x, _mm_min_epu8(x, _mm_set1_epi8(9)));
return _mm_test_all_zeros(t, mask_valid_bits) == 1;
}
奇数byteの2倍の総和と偶数byteの総和の和を求めるには
愚直にforを回してもあんまり変わらない気もしますがせっかくなのでSIMDで遊んで見ることにします。
static inline const auto mask_for_pack = _mm_set1_epi16(0xFF);
/**
* 奇数byte * 2 + 偶数byte
* 最終的な計算結果を得るには8byte目までを合計する必要がある
* @param x input
*/
inline __m128i accumlate_pre(const __m128i& x) noexcept
{
// x: o e o e | o e o e | o e o e | o e o e
// AND
// mask: FF 00 FF 00 | FF 00 FF 00 | FF 00 FF 00 | FF 00 FF 00
// ----> o 00 o 00 | o 00 o 00 | o 00 o 00 | o 00 o 00
const auto odd = _mm_and_si128(x, mask_for_pack);
// x: o e o e | o e o e | o e o e | o e o e
// RSHIFT
// ----> e o e o | e o e o | e o e o | e o e 00
// AND
// mask: FF 00 FF 00 | FF 00 FF 00 | FF 00 FF 00 | FF 00 FF 00
// ----> e 00 e 00 | e 00 e 00 | e 00 e 00 | e 00 e 00
const auto even = _mm_and_si128(_mm_srli_si128(x, 1), mask_for_pack);
// odd * 2 + even
// sum: s 00 s 00 | s 00 s 00 | s 00 s 00 | s 00 s 00
return _mm_add_epi8(_mm_add_epi8(odd, odd), even);
}
inline int calc(std::string_view s) noexcept
{
const auto gathered = gather_target_bytes(s);
if (!validate_phase1(gathered)) return 0xFF;
// 下位桁(0x0-0xF)をとってくる
const auto value = _mm_and_si128(gathered, mask_get_value);
if (!validate_phase2(value)) return 0xFE;
const auto sum_pre = accumlate_pre(value);
まず奇数/偶数 byteのみ残して残りを0にmaskすることを考えます。このmaskは_mm_set1_epi16(0xFF)とすると、FF 00 FF 00 FF 00 FF 00 FF 00 FF 00 FF 00 FF 00というなんかいい感じのものが手に入れられます。
maskしたあと奇数 byteの2倍と偶数byteを足し合わせる都合上、偶数byteはbyte shiftしておきます(_mm_srli_si128)
byte単位の掛け算をできるSIMD命令は存在しませんが、2倍するだけなので足し算に置き換えられます。
さて、最後に気になるのは、byte単位でアクセスするには飛び飛びに0のbyteがいることです。最初は下のように_mm_packus_epi16を用いて前詰めすることを考えたのですが、よくよく考えればstd::uint16_t単位でアクセスすればいいだけでした。
const auto sum_pre = _mm_add_epi8(_mm_add_epi8(odd, odd), even);
// sum: s 00 s 00 | s 00 s 00 | s 00 s 00 | s 00 s 00
// even: 00 00 00 00 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00
// PACKUSWB
// ----> s s s s | s s s s | 00 00 00 00 | 00 00 00 00
return _mm_packus_epi16(sum_pre, zero);
std::accumlateしなくても総和は出せる、そう、SIMDならねっ
さて、あとは普通にstd::accumlateを呼びましょうか
const auto sum_pre = accumlate_pre(value);
alignas(16) std::uint16_t sum_pre_raw[8];
_mm_store_si128(reinterpret_cast<__m128i*>(sum_pre_raw), sum_pre);
const auto sum = std::accumulate(std::begin(sum_pre_raw), std::begin(sum_pre_raw) + 6, 0);
・・・本当にそれでいいのでしょうか?ここでまたまた以前 @mtfmk 氏にもらったコードを思い出します。 @YSRKEN 氏のその部分の解説を読みましょう。
後は掛け算した結果の各要素を合計すればいい……のですが、_mm_store_si128命令などで変数に書き出してから足し算するのは効率が悪いです。
そこで、ここでもSIMD演算をフル活用することになります(Chikuzenさんからの情報提供)。
検査用数字の算出は……前述のテーブル引きで十分でしょう。2つを表すコードはこんな感じ。
// 総和を計算する __m128i temp = _mm_sad_epu8(mul_pq, _mm_setzero_si128()); temp = _mm_add_epi16(temp, _mm_srli_si128(temp, 8)); return g_table[_mm_cvtsi128_si32(temp)];
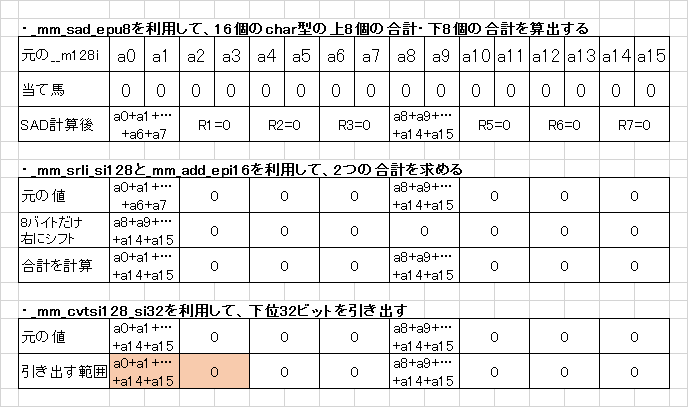
そうでした、_mm_sad_epu8がいましたね。早速呼びましょう。今回は12byte分有効であることを示すためにmaskを念のためしておきましょう。
/**
* 奇数byte * 2 + 偶数byte
* @param x input
*/
inline int accumlate(const __m128i& x) noexcept
{
// x: o e o e | o e o e | o e o e | o e o e
// AND
// mask: FF 00 FF 00 | FF 00 FF 00 | FF 00 FF 00 | FF 00 FF 00
// ----> o 00 o 00 | o 00 o 00 | o 00 o 00 | o 00 o 00
const auto odd = _mm_and_si128(x, mask_for_pack);
// x: o e o e | o e o e | o e o e | o e o e
// RSHIFT
// ----> e o e o | e o e o | e o e o | e o e 00
// AND
// mask: FF 00 FF 00 | FF 00 FF 00 | FF 00 FF 00 | FF 00 FF 00
// ----> e 00 e 00 | e 00 e 00 | e 00 e 00 | e 00 e 00
const auto even = _mm_and_si128(_mm_srli_si128(x, 1), mask_for_pack);
// odd * 2 + even
// sum_pre: s 00 s 00 | s 00 s 00 | s 00 s 00 | s 00 s 00
const auto sum_pre = _mm_add_epi8(_mm_add_epi8(odd, odd), even);
//ref: https://qiita.com/YSRKEN/items/17097b26ddf0754c5d34#%E5%90%88%E8%A8%88%E5%87%A6%E7%90%86%E3%81%A8%E6%A4%9C%E6%9F%BB%E7%94%A8%E6%95%B0%E5%AD%97%E3%81%AE%E8%A8%88%E7%AE%97%E5%87%A6%E7%90%86
//zeroは当て馬、_mm_sad_epu8はa-bの総和を求めるため0を引く
const auto sum_tmp = _mm_sad_epu8(_mm_and_si128(sum_pre, mask_valid_bits), zero);
//_mm_sad_epu8が8byteずつ足し算の結果をまとめるのでbyte shiftして足す
const auto sum = _mm_add_epi16(sum_tmp, _mm_srli_si128(sum_tmp, 8));
//先頭
return _mm_cvtsi128_si32(sum);
}
結論
/*=============================================================================
Copyright (C) 2022 yumetodo <yume-wikijp@live.jp>
Distributed under the Boost Software License, Version 1.0.
(See https://www.boost.org/LICENSE_1_0.txt)
=============================================================================*/
#include <iostream>
#include <string>
#include <string_view>
#include <cstdint>
#include <cstring>
#include <immintrin.h>
#include <smmintrin.h>
namespace check_digit_calc {
namespace {
static inline const auto zero = _mm_setzero_si128();
static inline const auto mask_get_value = _mm_set1_epi8(0b0000'1111);
namespace bits_for_validate {
static inline const auto mask_extract_significant_bit = _mm_set1_epi8(0b1111'0000);
static inline const auto valid_pattern_alphabetic = _mm_set1_epi8(0b0011'0000);
static inline const auto valid_pattern_full_width = _mm_set1_epi8(0b1001'0000);
}
static inline const auto mask_for_pack = _mm_set1_epi16(0xFF);
//16要素詰め込めるところを12要素しか詰め込んでいないので残りの部分は判定からはずすためのmask
static inline const auto mask_valid_bits = _mm_setr_epi32(-1, -1, -1, 0);
/**
* 入力文字列から必要な部分を抜き出して`__m128i`に格納する
*
* 0-9の場合、`EF BC 9x`となるので3byte目の`9x`の部分を格納する
* 0-9の場合、`3x`となるので1byte目の`3x`の部分を格納する
* @param s 入力文字列
*/
inline __m128i gather_target_bytes(std::string_view s) noexcept
{
if (s.length() > 12 * 3) return zero;
alignas(16) char ret[16]{};
std::size_t i, j;
for (i = 0, j = 0; i < 12 && j < s.length(); ++i, ++j) {
constexpr std::byte expected[] = { std::byte(0xEF), std::byte(0xBC) };
const bool b = (j + 2 >= s.length() || std::memcmp(s.data() + j, expected, 2) != 0);
ret[i] = b ? s[j] : s[j += 2];
}
return (j != s.length()) ? zero : _mm_load_si128(reinterpret_cast<__m128i*>(ret));
}
/**
* 各byteの上位bitが0-9もしくは0-9のものであることを検証する
* @param x 8bit整数が格納された`__m128i`
*/
inline bool validate_phase1(const __m128i& x) noexcept
{
using namespace bits_for_validate;
// 下位桁(0x0-0xF)はvalidate_phase2で見るので一旦mask
const auto masked = _mm_and_si128(x, mask_extract_significant_bit);
// 0-9が格納されたbyteでは0になる
const auto distance_alphabetic = _mm_sub_epi8(masked, valid_pattern_alphabetic);
// 0-9が格納されたbyteでは0になる
const auto distance_full_width = _mm_sub_epi8(masked, valid_pattern_full_width);
// AND演算すれば0-9もしくは0-9が格納されたbyteでは0になる
const auto distance = _mm_and_si128(distance_alphabetic, distance_full_width);
// 12要素分全部0なら正しい
return _mm_test_all_zeros(distance, mask_valid_bits) == 1;
}
/**
* 各byteで9以下であることを検証する
* @param x 8bit整数が格納された`__m128i`
*/
inline bool validate_phase2(const __m128i& x) noexcept
{
const __m128i t = _mm_sub_epi8(x, _mm_min_epu8(x, _mm_set1_epi8(9)));
return _mm_test_all_zeros(t, mask_valid_bits) == 1;
}
/**
* 奇数byte * 2 + 偶数byte
* @param x input
*/
inline int accumlate(const __m128i& x) noexcept
{
// x: o e o e | o e o e | o e o e | o e o e
// AND
// mask: FF 00 FF 00 | FF 00 FF 00 | FF 00 FF 00 | FF 00 FF 00
// ----> o 00 o 00 | o 00 o 00 | o 00 o 00 | o 00 o 00
const auto odd = _mm_and_si128(x, mask_for_pack);
// x: o e o e | o e o e | o e o e | o e o e
// RSHIFT
// ----> e o e o | e o e o | e o e o | e o e 00
// AND
// mask: FF 00 FF 00 | FF 00 FF 00 | FF 00 FF 00 | FF 00 FF 00
// ----> e 00 e 00 | e 00 e 00 | e 00 e 00 | e 00 e 00
const auto even = _mm_and_si128(_mm_srli_si128(x, 1), mask_for_pack);
// odd * 2 + even
// sum_pre: s 00 s 00 | s 00 s 00 | s 00 s 00 | s 00 s 00
const auto sum_pre = _mm_add_epi8(_mm_add_epi8(odd, odd), even);
//ref: https://qiita.com/YSRKEN/items/17097b26ddf0754c5d34#%E5%90%88%E8%A8%88%E5%87%A6%E7%90%86%E3%81%A8%E6%A4%9C%E6%9F%BB%E7%94%A8%E6%95%B0%E5%AD%97%E3%81%AE%E8%A8%88%E7%AE%97%E5%87%A6%E7%90%86
//zeroは当て馬、_mm_sad_epu8はa-bの総和を求めるため0を引く
const auto sum_tmp = _mm_sad_epu8(_mm_and_si128(sum_pre, mask_valid_bits), zero);
//_mm_sad_epu8が8byteずつ足し算の結果をまとめるのでbyte shiftして足す
const auto sum = _mm_add_epi16(sum_tmp, _mm_srli_si128(sum_tmp, 8));
//先頭
return _mm_cvtsi128_si32(sum);
}
}
inline int calc(std::string_view s) noexcept
{
const auto gathered = gather_target_bytes(s);
if (!validate_phase1(gathered)) return 0xFF;
// 下位桁(0x0-0xF)をとってくる
const auto value = _mm_and_si128(gathered, mask_get_value);
if (!validate_phase2(value)) return 0xFE;
const auto sum = accumlate(value);
return 9 - (sum % 9);
}
};
int main()
{
//std::string s = "70011000590:";
//std::string s = "700110005901";
std::string s = "700110005901";
std::cout << s << ':' << s.length() << std::endl;
const auto result = check_digit_calc::calc(s);
std::cout << "result: " << result << std::endl;
}
参考記事
- C++でマイナンバーのチェックデジットを計算する - Qiita
- SIMD intrinsicでチェックディジットを計算してみる その2 - Qiita
- Intel® Intrinsics Guide
- 組み込み関数(intrinsic)によるSIMD入門
- x86/x64 SIMD命令一覧表 (SSE~AVX2)
- SSEやAVXの水平加算処理について - Qiita
- c - print a __m128i variable - Stack Overflow
- Intrinsicsを使ってもっと早く演算やってみよう! - Qiita
追記: accumlateの命令数削減
よくよく考えれば_mm_sad_epu8に偶数と奇数の足し算を任せてしまえばいいことに気が付きました。
@@ -6,15 +6,10 @@
// ----> o 00 o 00 | o 00 o 00 | o 00 o 00 | o 00 o 00
const auto odd = _mm_and_si128(x, mask_for_pack);
// x: o e o e | o e o e | o e o e | o e o e
- // RSHIFT
- // ----> e o e o | e o e o | e o e o | e o e 00
- // AND
- // mask: FF 00 FF 00 | FF 00 FF 00 | FF 00 FF 00 | FF 00 FF 00
- // ----> e 00 e 00 | e 00 e 00 | e 00 e 00 | e 00 e 00
- const auto even = _mm_and_si128(_mm_srli_si128(x, 1), mask_for_pack);
- // odd * 2 + even
- // sum_pre: s 00 s 00 | s 00 s 00 | s 00 s 00 | s 00 s 00
- const auto sum_pre = _mm_add_epi8(_mm_add_epi8(odd, odd), even);
+ // ADD
+ // odd: o 00 o 00 | o 00 o 00 | o 00 o 00 | o 00 o 00
+ // ----> 2o e 2o e | 2o e 2o e | 2o e 2o e | 2o e 2o e
+ const auto sum_pre = _mm_add_epi8(x, odd);
//ref: https://qiita.com/YSRKEN/items/17097b26ddf0754c5d34#%E5%90%88%E8%A8%88%E5%87%A6%E7%90%86%E3%81%A8%E6%A4%9C%E6%9F%BB%E7%94%A8%E6%95%B0%E5%AD%97%E3%81%AE%E8%A8%88%E7%AE%97%E5%87%A6%E7%90%86
//zeroは当て馬、_mm_sad_epu8はa-bの総和を求めるため0を引く
const auto sum_tmp = _mm_sad_epu8(_mm_and_si128(sum_pre, mask_valid_bits), zero);