はじめに
- 総務省eStatで公開されている政府統計データを取得する方法は、下記の通りです。
- ① e-Stat HPにアクセスする(and/or スクレイピング)
- ② e-Stat APIを利用する
- この記事では、主に2つ目の方法(e-Stat APIを利用)について説明します。
- 具体的には、PythonでWeb APIを扱う他のケースと同じように、
requestやurllibを用いてRESTな呼び出し関数群の作成を考えます。 - eStat API (version 3.0) の詳しい仕様については、API仕様書 (ver 3.0) を参照してください。
- 実装したコード(Github repo):https://github.com/yumaloop/estat-api
- 具体的には、PythonでWeb APIを扱う他のケースと同じように、
0. 政府統計とは
- 政府統計とは、日本の行政機関(中央省庁+地方自治体)が実施している統計調査の総称である。現在実施されている政府統計の一覧はここで確認できる。
- それぞれの統計調査は実施主体(〇〇省,〇〇庁,〇〇県など)ごとに管理していたようだが、最近では、ほぼすべての政府統計が総務省統計局によって集計されデータベースとして管理されている。
- eStatは、総務省統計局が主管する政府統計データベースを一般向けに公開しているサービスである。eStatのうち、主に開発者向けに公開されているWebAPIがe-Stat APIである。
- 2021年6月現在、eStatには672件の政府統計(テーブル)が登録されており、調査時期(年・月単位)や集計地域(国・都道府県・市区町村)ごとに分割された179,188件のデータセット(ファイル)がダウンロード可能である。
たくさんある政府統計をどう分類するか
eStatでは、672件ある政府統計を「統計分野」「組織」「統計の種類」「提供周期」で分けている。またデータを取得する場合、それぞれの政府統計に対して、さらに調査時期(年・月単位)や集計地域(国・都道府県・市区町村)によって絞る)
例えば、672件ある政府統計は「統計分野 (17)」と「組織 (14)」でまとめると次表のように整理される。
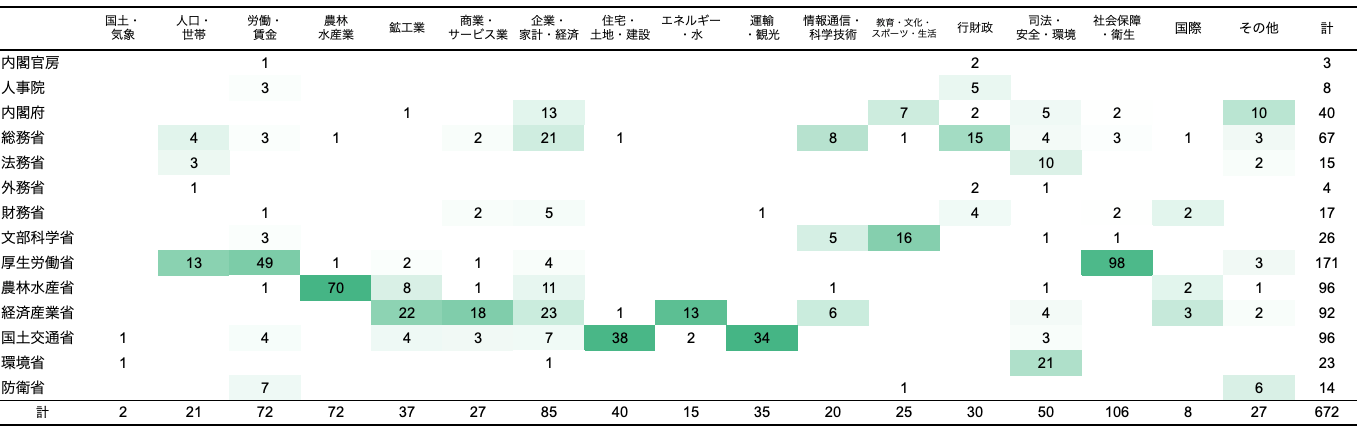
データを取得する前に、eStatの検索機能を使い、どのような政府統計があるかを把握すると良い。
政府統計コードと統計表ID
eStatで公開されているデータは、政府統計コードや統計表IDで識別される。
- 「政府統計コード」: 政府統計に割り当てられたユニークID.
- 「統計表ID」: 政府統計に含まれる統計表に割り当てられたユニークID.
たとえば、国勢調査の政府統計コードは00200521、家計調査の政府統計コードは00200561.
e-Statからデータを取得するときは、まず「政府統計コード」を指定し、指定された政府統計に含まれる統計表を条件検索する。他にも都道府県コードや市区町村コードなど、総務省が定めるコードがある。条件検索する際にも参照するコードを以下に記しておく。
- 政府統計コード一覧(例:「国勢調査2015」= "00200521")
- 統計表の作成機関コード(例:「総務省」= "00200")
- 都道府県コード、市区町村コード(例:「北海道」="01"「札幌市」= "1002 ")
- 全国地方公共団体コード(例:「北海道札幌市」= "011002")
- 政府機関が保有するコード一覧
1. e-Stat HPにアクセス + スクレイピング
e-Statのホームページでは、構造的なURLでDBからデータを提供するため、Webスクレイピングが可能である。例として、「家計調査 / 家計収支編 二人以上の世帯 詳細結果表」にアクセスする際のURL
https://www.e-stat.go.jp/stat-search/files
?page=1&layout=datalist&toukei=00200561&tstat=000000330001
&cycle=1&year=20200&month=12040606&tclass1=000000330001
&tclass2=000000330004&tclass3=000000330005&stat_infid=000031969452&result_back=1
は、それぞれの分類項目に関するHTTP GETのパラメータ指定("&<param>=<value>")によって次のような対応関係をもつ。
| 項目 (param) | 値 (value) | URL |
|---|---|---|
| 政府統計名 | 家計調査 | &toukei=00200561 |
| 提供統計名 | 家計調査 | &tstat=000000330001 |
| 提供分類1 | 家計収支編 | tclass1=000000330001 |
| 提供分類2 | 二人以上の世帯(農林漁家世帯を除く結果) | tclass2=000000330002 |
| 提供分類3 | 詳細結果表 | tclass3=000000330003 |
| 提供周期 | 月次 | &cycle=1 |
| 調査年月 | 2000年1月 | &year=20000 &month=11010301 |
2. e-Stat APIを利用する
2.1 データ取得手順
Step 1: eStat API のアプリケーションIDを取得する。
eStats APIのトップページにアクセスして、「ユーザ登録・ログイン」から手続きを行う。氏名・メールアドレス・パスワードを登録すると、メールにてアプリケーションIDが送付される。アプリケーションIDがないとAPIコールできない(アカウント認証が必要)。
Step 2: HTTP GETをコールして、APIからレスポンス(データ)を受け取る。
APIの細かい使い方は、API仕様書 (ver 3.0) を参照。基本、以下2つのコールができればほとんど困ることはない。
- 統計情報取得(getStatsList)
- 統計データ取得(getStatsData)
2.2 Pythonモジュールの実装
e-Stat API (version 3.0.0)の仕様書を参考にして、指定したパラメータに対して適当なURLを生成するモジュールを作った。コード(Github repo):https://github.com/yumaloop/estat-api
Web-API Client (URL Parser)
APIに対して実行するRESTメソッドに対応したURLを生成するクラス(Python)
API仕様書 (ver 3.0) を参照。
import urllib
import requests
class EstatRestApiClient:
"""
This is a simple python module class for e-Stat API (ver.3.0).
See more details at https://www.e-stat.go.jp/api/api-info/e-stat-manual3-0
"""
def __init__(self, api_version=None, app_id=None):
# base url
self.base_url = "https://api.e-stat.go.jp/rest"
# e-Stat REST API Version
if api_version is None:
self.api_version = "3.0"
else:
self.api_version = api_version
# Application ID
if app_id is None:
self.app_id = "****************" # ここにアプリケーションIDをいれる
else:
self.app_id = app_id
def getStatsList(self, params_dict, format="csv"):
"""
2.1 統計表情報取得 (HTTP GET)
"""
params_str = urllib.parse.urlencode(params_dict)
if format == "xml":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/getStatsList?{params_str}"
)
elif format == "json":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/json/getStatsList?{params_str}"
)
elif format == "jsonp":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/jsonp/getStatsList?{params_str}"
)
elif format == "csv":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/getSimpleStatsList?{params_str}"
)
return url
def getMetaInfoURL(self, params_dict, format="csv"):
"""
2.2 メタ情報取得 (HTTP GET)
"""
params_str = urllib.parse.urlencode(params_dict)
if format == "xml":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/getMetaInfo?{params_str}"
)
elif format == "json":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/json/getMetaInfo?{params_str}"
)
elif format == "jsonp":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/jsonp/getMetaInfo?{params_str}"
)
elif format == "csv":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/getSimpleMetaInfo?{params_str}"
)
return url
def getStatsDataURL(self, params_dict, format="csv"):
"""
2.3 統計データ取得 (HTTP GET)
"""
params_str = urllib.parse.urlencode(params_dict)
if format == "xml":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/getStatsData?{params_str}"
)
elif format == "json":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/json/getStatsData?{params_str}"
)
elif format == "jsonp":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/jsonp/getStatsData?{params_str}"
)
elif format == "csv":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/getSimpleStatsData?{params_str}"
)
return url
def postDatasetURL(self):
"""
2.4 データセット登録 (HTTP POST)
"""
url = (
f"{self.base_url}/{self.api_version}"
"/app/postDataset"
)
return url
def refDataset(self, params_dict, format="xml"):
"""
2.5 データセット参照 (HTTP GET)
"""
params_str = urllib.parse.urlencode(params_dict)
if format == "xml":
url = (
f"{self.base_url}/{self.api_version}"
+ f"/app/refDataset?{params_str}"
)
elif format == "json":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/json/refDataset?{params_str}"
)
elif format == "jsonp":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/jsonp/refDataset?{params_str}"
)
return url
def getDataCatalogURL(self, params_dict, format="xml"):
"""
2.6 データカタログ情報取得 (HTTP GET)
"""
params_str = urllib.parse.urlencode(params_dict)
if format == "xml":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/getDataCatalog?{params_str}"
)
elif format == "json":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/json/getDataCatalog?{params_str}"
)
elif format == "jsonp":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/jsonp/getDataCatalog?{params_str}"
)
return url
def getStatsDatasURL(self, params_dict, format="xml"):
"""
2.7 統計データ一括取得 (HTTP GET)
"""
params_str = urllib.parse.urlencode(params_dict)
if format == "xml":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/getStatsDatas?{params_str}"
)
elif format == "json":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/json/getStatsDatas?{params_str}"
)
elif format == "csv":
url = (
f"{self.base_url}/{self.api_version}"
f"/app/getSimpleStatsDatas?{params_str}"
)
return url
Download functions
import文(Python)
import csv
import json
import xlrd
import zipfile
import requests
import functools
import pandas as pd
from concurrent.futures import ThreadPoolExecutor
from tqdm import tqdm
APIにHTTP Requestを送り、受け取ったJSONデータを辞書として返す(Python)
def get_json(url):
"""
Request a HTTP GET method to the given url (for REST API)
and return its response as the dict object.
Args:
====
url: string
valid url for REST API
"""
try:
print("HTTP GET", url)
r = requests.get(url)
json_dict = r.json()
return json_dict
except requests.exceptions.RequestException as error:
print(error)
APIにHTTP Requestを送り、JSONファイルをダウンロード(Python)
def download_json(url, filepath):
"""
Request a HTTP GET method to the given url (for REST API)
and save its response as the json file.
url: string
valid url for REST API
filepath: string
valid path to the destination file
"""
try:
print("HTTP GET", url)
r = requests.get(url)
json_dict = r.json()
json_str = json.dumps(json_dict, indent=2, ensure_ascii=False)
with open(filepath, "w") as f:
f.write(json_str)
except requests.exceptions.RequestException as error:
print(error)
APIにHTTP Requestを送り、CSVファイルをダウンロード(Python)
def download_csv(url, filepath, enc="utf-8", dec="utf-8", logging=False):
"""
Request a HTTP GET method to the given url (for REST API)
and save its response as the csv file.
url: string
valid url for REST API
filepathe: string
valid path to the destination file
enc: string
encoding type for a content in a given url
dec: string
decoding type for a content in a downloaded file
dec = 'utf-8' for general env
dec = 'sjis' for Excel on Win
dec = 'cp932' for Excel with extended JP str on Win
logging: True/False
flag whether putting process log
"""
try:
if logging:
print("HTTP GET", url)
r = requests.get(url, stream=True)
with open(filepath, 'w', encoding=enc) as f:
f.write(r.content.decode(dec))
except requests.exceptions.RequestException as error:
print(error)
def download_all_csv(
urls,
filepathes,
max_workers=10,
enc="utf-8",
dec="utf-8"):
"""
Request some HTTP GET methods to the given urls (for REST API)
and save each response as the csv file.
(!! This method uses multi threading when calling HTTP GET requests
and downloading files in order to improve the processing speed.)
urls: list of strings
valid urls for REST API
filepathes: list of strings
valid pathes to the destination file
max_workers: int
max number of working threads of CPUs within executing this method.
enc: string
encoding type for a content in a given url
dec: string
decoding type for a content in a downloaded file
dec = 'utf-8' for general env
dec = 'sjis' for Excel on Win
dec = 'cp932' for Excel with extended JP str on Win
logging: True/False
"""
func = functools.partial(download_csv, enc=enc, dec=dec)
with ThreadPoolExecutor(max_workers=max_workers) as executor:
results = list(
tqdm(executor.map(func, urls, filepathes), total=len(urls))
)
del results
2.3 APIの使用例
サンプルコード
ケース1: 国勢調査(2015) 「人口等基本集計」のダウンロード
国勢調査(2015) の「人口等基本集計」にある統計表のリストをJSONファイルで取得
ファイル構成
.
├ main.ipynb
├ estat_api.py
└ __init__.py
スクリプト
import json
from pprint import pprint
from estat_api import EstatRestApiClient
# 国勢調査(2015) > 人口等基本集計にある統計表リストをJSONファイルで取得
estat_api_client = EstatRestApiClient(app_id= "****************")
json_dict = estat_api_client.getStatsList(lang="J", surveyYears="2015", statsCode="00200521", searchWord="人口等基本集計", limit=10, format="json")
pprint(json_dict)
# 統計表リストをJSONファイルに保存
filepath = "./example1.json"
json_str = json.dumps(json_dict, indent=2, ensure_ascii=False)
with open(filepath, "w") as f:
f.write(json_str)
ケース2: 総務省 「社会・人口統計体系」のダウンロード
総務省が毎年提供している社会・人口統計体系(統計でみる市区町村のすがた)から、市区町村を地域単位として各項目をeStat API経由で集計し、ローカルファイル(CSV)として保存する。
ファイル構成
.
├ main.ipynb
├ estat_api.py
├ io_utils.py
└ __init__.py
スクリプト
import os
from pprint import pprint
from estat_api import EstatRestApiClient
from io_utils import download_all_csv
appId = "****************" # ここにアプリケーションIDをいれる
estatapi_url_parser = EstatRestApiClient() # URL Parser
def search_tables():
"""
Prams (dictionary) to search eStat tables.
For more details, see also
https://www.e-stat.go.jp/api/api-info/e-stat-manual3-0#api_3_2
- appId: Application ID (*required)
- lang: 言語(J:日本語, E:英語)
- surveyYears: 調査年月 (YYYYY or YYYYMM or YYYYMM-YYYYMM)
- openYears: 調査年月と同様
- statsField: 統計分野 (2桁:統計大分類, 4桁:統計小分類)
- statsCode: 政府統計コード (8桁)
- searchWord: 検索キーワード
- searchKind: データの種別 (1:統計情報, 2:小地域・地域メッシュ)
- collectArea: 集計地域区分 (1:全国, 2:都道府県, 3:市区町村)
- explanationGetFlg: 解説情報有無(Y or N)
- ...
"""
params_dict = {
"appId": appId,
"lang": "J",
"statsCode": "00200502",
"searchWord": "社会・人口統計体系", # "統計でみる市区町村のすがた",
"searchKind": 1,
"collectArea": 3,
"explanationGetFlg": "N"
}
url = estatapi_url_parser.getStatsList(params_dict, format="json")
json_dict = get_json(url)
# pprint(json_dict)
if json_dict['GET_STATS_LIST']['DATALIST_INF']['NUMBER'] != 0:
tables = json_dict["GET_STATS_LIST"]["DATALIST_INF"]["TABLE_INF"]
else:
tables = []
return tables
def parse_table_id(table):
return table["@id"]
def parse_table_raw_size(table):
return table["OVERALL_TOTAL_NUMBER"]
def parse_table_urls(table_id, table_raw_size, csv_raw_size=100000):
urls = []
for j in range(0, int(table_raw_size / csv_raw_size) + 1):
start_pos = j * csv_raw_size + 1
params_dict = {
"appId": appId, # Application ID
"lang": "J", # 言語 (J: 日本語, E: 英語)
"statsDataId": str(table_id), # 統計表ID
"startPosition": start_pos, # 開始行
"limit": csv_raw_size, # データ取得件数
"explanationGetFlg": "N", # 解説情報有無(Y or N)
"annotationGetFlg": "N", # 注釈情報有無(Y or N)
"metaGetFlg": "N", # メタ情報有無(Y or N)
"sectionHeaderFlg": "2", # CSVのヘッダフラグ(1:取得, 2:取得無)
}
url = estatapi_url_parser.getStatsDataURL(params_dict, format="csv")
urls.append(url)
return urls
if __name__ == '__main__':
CSV_RAW_SIZE = 100000
# list of tables
tables = search_tables()
# extract all table ids
if len(tables) == 0:
print("No tables were found.")
elif len(tables) == 1:
table_ids = [parse_table_id(tables[0])]
else:
table_ids = list(map(parse_table_id, tables))
# list of urls
table_urls = []
table_raw_size = list(map(parse_table_raw_size, tables))
for i, table_id in enumerate(table_ids):
table_urls = table_urls + parse_table_urls(table_id, table_raw_size[i])
# list of filepathes
filepathes = []
for i, table_id in enumerate(table_ids):
table_name = tables[i]["TITLE_SPEC"]["TABLE_NAME"]
table_dir = f"./downloads/tmp/{table_name}_{table_id}"
os.makedirs(table_dir, exist_ok=True)
for j in range(0, int(table_raw_size[i] / CSV_RAW_SIZE) + 1):
filepath = f"{table_dir}/{table_name}_{table_id}_{j}.csv"
filepathes.append(filepath)
# CSVファイルに保存
download_all_csv(table_urls, filepathes, max_workers=30)
2.4 拡張: Cloud/DWH/ETLへの組込
モダンな分析基盤構築には,データのETL処理(Extract/Transformation/Load)が不可欠であり,また外部データのETL処理には,API利用が欠かせません.その意味で,eStat APIは政府統計データを扱うETLパイプライン実装に有効なツールと言えます.
Layer 1 分析基盤 (DWH)
↓
Layer 2 パイプライン (ETL)
↓
Layer 3 インターフェース (API)
↓
Layer 4 各種スクリプト (notebook/application/chart/BI)
たとえば,
参照したい政府統計に対して、一連の処理をすべてPythonスクリプトとして作成して、1つのパイプラインジョブにまとめれば、あとはスケジューラ(Airflow)を使って実行タイミングや実行結果のモニタリングを適切に設定すれば、APIからDWHへとデータを連携するためのバッチ処理が完成します.
- eStat APIから元データを取得(Python)
- 取得したデータ(csv, json, html, xlsx)を加工・前処理(Python)
- 自社サーバやクラウド上のDBにファイルを保存・追加・更新(SQL)
もし、GCP等のクラウドサービスを利用する場合は、BigQueryやCloudStorageといったDWH系のサービスと相性の良いバッチスケジューラが用意されているので、各サービスの公式リファレンスを参照して、すばやく実装・運用できます。
クラウドストレージ(DWH)
- Google GCP - BigQuery, CloudStorage
- Amazon AWS - RDS, S3, Redshift
最後まで読んでいただき、ありがとうございます。