はじめに
昨年RaspberryPiを購入したが多忙な日々ですっかり放置してたので、何かしたいなと思っていたのでPythonで音声認識の実装にチャレンジしました。
プログラムは普段全く触ることがなく(今まで使った事があるのはVBAくらい)、Pythonは1ヶ月ほど前に初めて触ったという超初心者なのでお見苦しいとは思いますがご容赦ください。(備忘録を兼ねて投稿)
ちなみになぜPythonかと言うと、音声認識に興味を持つ→ググったらPythonでAPIを利用するというコードがいくつも出てきたので、よし、じゃあやってみよう!というなんとも単純な考えからです(笑)
他のプログラムはよく知りませんが、Pythonは文法がシンプルで覚えやすい、可読性が良いから初心者向けということらしいので、私みたいな人間にはありがたい限りです。
参考サイト
RaspberryPiのマイクで録音した音声をテキスト化する【ヒミツのクマちゃん その3】
音声認識
簡単にできる!音声認識と音声合成を使ってRaspberrypiと会話
Pythonで音を監視して一定以上の音量を録音する
PyAudio公式HP
bufferをndarrayに高速変換するnumpy.frombuffer関数の使い方
マイクとスピーカーの接続と録音の確認
とりあえずラズパイにUSBマイクとスピーカーを繋げて接続チェック
マイクはSONY ECM-PCV80Uを繋げました。スピーカーはBuffalo BSSP29Uです。
$ lsusb
Bus 001 Device 006: ID 054c:0686 Sony Corp.
Bus 001 Device 007: ID 0424:7800 Standard Microsystems Corp.
Bus 001 Device 003: ID 0424:2514 Standard Microsystems Corp. USB 2.0 Hub
Bus 001 Device 002: ID 0424:2514 Standard Microsystems Corp. USB 2.0 Hub
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 001に繋がっていることを確認。
次にカード番号とデバイス番号を調べる。
$ arecord -l
**** ハードウェアデバイス CAPTURE のリスト ****
カード 1: UAB80 [UAB-80], デバイス 0: USB Audio [USB Audio]
サブデバイス: 1/1
サブデバイス #0: subdevice #0
カード1のデバイス0で認識されているので録音して再生してみる。
$ arecord -D plughw:1,0 test.wav
録音中 WAVE 'test.wav' : Unsigned 8 bit, レート 8000 Hz, モノラル
$ aplay -D plughw:1,0 test.wav
再生中 WAVE 'test.wav' : Unsigned 8 bit, レート 8000 Hz, モノラル
録音はCtrl+Cで停止。
スピーカーはUSBマイクのUSB Audio Boxに繋げたので-D plughw:1,0を付けて再生したが、ラズパイのオーディオジャックに直接挿した場合は不要(だと思う)
音が聞こえない時は
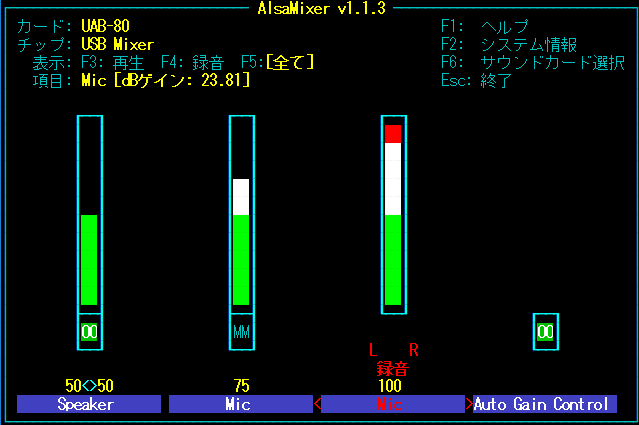
$ alsamixer
で音量調節。デフォルトだとbcm2835のサウンドカードが選択されているのでF6でカード変更。F5で録音デバイスが表示されるのでSpeacerとMicの音量を調節。ミュートMMになっている場合はmで解除。
スピーカーで再生できているかチェックしたい時は
$ aplay -D plughw:1,0 /usr/share/sounds/alsa/Front_Center.wav
で確認できる。
Pyaudioのインストール
Raspberry Piには最初からPython3がインストールされていたのでPyaudioのみをインストールしました。
$ sudo apt-get update
$ sudo apt-get install python3-pyaudio
インストールは特に躓くこと無く完了。apt-get最高。
Pyaudioで録音してみる
とりあえずPyaudio公式のサンプルコードをそのままコピペ。変更点はマイクがモノラルなのでCHANNELS = 1にしたのと、デフォルトのCHUNKだとOSError: [Errno -9981] Input overflowedが出て動かなかったので4倍にした。
import pyaudio
import wave
CHUNK = 1024 * 4 # 4倍
FORMAT = pyaudio.paInt16
CHANNELS = 1 # モノラル入力
RATE = 44100
RECORD_SECONDS = 5
WAVE_OUTPUT_FILENAME = "output.wav"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("* recording")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
このソースコードをラズパイ上で実行。
$ python3 record.py
実行後にoutput.wavが生成されているので再生すると問題なく録音できていることが確認できた。
次に、docomo音声認識APIでは16kHz/16bitのPCM音源が必要ということなので、RATE = 16000としたところ
OSError: [Errno -9997] Invalid sample rate
というエラーが出てハマる・・・。
色々調べたところ、マイクが44.1kHzと48kHzしか対応してないらしい。
どうすれば良いか分からず途方に暮れてたところ、ある時「48kHzで録音したデータを1/3に間引けば16kHzになるのでは?」と思いついたのでやってみる。
import pyaudio
import wave
import numpy as np
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 48000 # 録音は48kHz
RECORD_SECONDS = 5
WAVE_OUTPUT_FILENAME = "output.wav"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("* recording")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
buf = np.frombuffer(data, dtype="int16") # 読み込んだストリームデータを2byteのInt型のリストに分離
frames.append(b''.join(buf[::3])) # 記録するデータを1/3に間引いてリストを結合してフレームに追加
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE / 3) # ヘッダのサンプリングレートを16kHzにする
wf.writeframes(b''.join(frames))
wf.close()
実行した結果、16kHz/16bitの音源で録音された。プログラムは問題が解決してうまく動いたときが一番嬉しいですね(笑)
ちなみに48kHzで録音したところCHUNK = 1024でも動いた。謎。
docomo音声認識APIキー取得
ようやくメインの音声認識です。
まずはAPIキーを取得する必要がありますが、APIキー自体はだいぶ前に取得したので方法を忘れました・・・。
たぶんここのやり方で取得したのだと思う。
docomo音声認識APIを使ってみる
ということで、ここを参考にソースを書いてみました。というか丸パクリでprintだけをPython3仕様に変えただけ。
# !/usr/bin/env python
# coding: utf-8
import requests
import json
path = 'output.wav'
APIKEY = '[取得したAPIキー]'
url = "https://api.apigw.smt.docomo.ne.jp/amiVoice/v1/recognize?APIKEY={}".format(APIKEY)
files = {"a": open(path, 'rb'), "v":"on"}
r = requests.post(url, files=files)
json_data = r.json()
print(json_data['text'])
これでpyファイルを実行するとこんな感じになりました。
$ python3 docomo_voice_to_text.py
こんにちは。今日は暑いですね。
音声検出時に録音&テキスト変換
以上で録音とテキスト変換ができるようになったので、繋げて一連の処理を連続してできるようにしました。また、毎回プログラムを起動するのもあれなので、音声入力待ちの状態にして音を検知したら音声認識をするようにしてみました。
あとはCtrl+Cを押さないと終了しないので「終了」と言ったらプログラムを終わらせるようにもしました。
音声検知はここを参考にしました。
それとNumpyは標準では入ってなかったかも。インストールされてなければ下記コマンドを実行
$ pip3 install numpy
# !/usr/bin/env python
# coding: utf-8
# 音声入力待ちをして音声をテキストに変換
import pyaudio
import wave
import numpy as np
import requests
import json
import sys
CHUNK = 1024
FORMAT = pyaudio.paInt16 # 16bits
CHANNELS = 1 # モノラル
RATE = 48000 # サンプリングレート
MAX_RECORD_SECONDS = 10 # 最大録音時間
SILENCE_SECONDS = 1 # 無音検知時間
threshold_start = 0.01 # 録音開始の閾値
threshold_stop = 0.01 # 録音終了の閾値
WAVE_FILE = "output.wav" # 音声データファイル
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
while True:
# 音声入力部
# -----
frames = []
buf_old = ""
stream.start_stream()
while True:
# 音声入力待ち
data = stream.read(CHUNK)
buf = np.frombuffer(data, dtype="int16")
if buf.max() / 32768 > threshold_start:
# 音声入力判定されたら録音開始
print("録音開始")
frames.append(b''.join(buf_old[::3]))
frames.append(b''.join(buf[::3]))
cnt = 0
for i in range(1, int(RATE / CHUNK * MAX_RECORD_SECONDS)):
data = stream.read(CHUNK)
buf = np.frombuffer(data, dtype="int16")
frames.append(b''.join(buf[::3]))
# 一定時間音声入力が無ければ終了
if buf.max() / 32768 < threshold_stop : cnt = cnt + 1
else: cnt = 0
if cnt > (RATE / CHUNK * SILENCE_SECONDS) : break
print("録音終了")
stream.stop_stream()
# 録音データをファイルに保存
wf = wave.open(WAVE_FILE, "wb")
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE / 3)
wf.writeframes(b''.join(frames))
wf.close()
break
# 音声を一時保存
# 音声入力検知後に録音開始すると最初の声が切れてしまうのでその対策
buf_old = buf
# 音声入力が無ければ繰り返し
# テキスト変換&表示部
# -----
APIKEY = '[取得したAPIキー]'
url = "https://api.apigw.smt.docomo.ne.jp/amiVoice/v1/recognize?APIKEY={}".format(APIKEY)
files = {"a": open(WAVE_FILE, 'rb'), "v":"on"}
r = requests.post(url, files=files)
json_data = r.json()
text = json_data['text']
print(text)
# 終了と言ったらプログラムを終了する
if text == "終了。":
stream.close()
p.terminate()
sys.exit()
print("繰り返し")
# 音声入力部に戻る
これで音声入力からテキスト化ができるようになりました!
おしまい
おまけ
上のコードだと音声データを一度ファイルに保存して読み直すという処理をしているのが気になったので、ファイルに保存しないでデータをdocomoAPIに送ってみることに。
上のコードのframesが音声のRAWデータになるので、リストを結合してそのまま送れば良いだろうと思い試してみたらうまくいかず・・・。
docomoAPIのホームページをよくよく見てみるとこんな記述が。
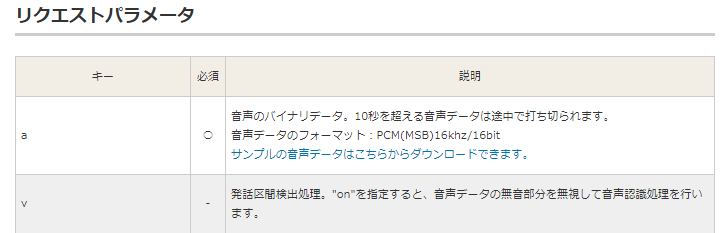
16kHz/16bitのPCM(MSB)とありました。
はて、MSB?ということでググってみたら、ビットまたはバイトの並びの順序のことらしい。またの名をビッグエンディアンと呼ぶとか。そしてMSBの反対はLSB(リトルエンディアン)とのこと。
調べたところ、録音したwaveファイルのRAWデータはLSB形式でした。
なのでLSB形式のデータをそのまま送るとデータの順番が違ってdocomoAPI側で処理できなかったんですね。
でも、waveをOPENしてリクエストすると正常に処理してくれるのはどうしてでしょう?
愚痴っても始まりません。対処法を考えることに・・・。
どうやらwaveファイルのエンディアンはバイト単位らしく、録音データはInt16型(2バイト)なので上位1バイトと下位1バイトを入れ替えれば良さそう。
ということで、最終的にこんなコードになりました。
# !/usr/bin/env python
# coding: utf-8
# 音声入力待ちをして音声をテキストに変換
# waveファイル保存しないバージョン
import pyaudio
import numpy as np
import requests
import json
import sys
CHUNK = 1024 * 2
FORMAT = pyaudio.paInt16 # 16bits
CHANNELS = 1 # モノラル
RATE = 48000 # サンプリングレート
MAX_RECORD_SECONDS = 10 # 最大録音時間
SILENCE_SECONDS = 1 # 無音検知時間
threshold_start = 0.01 # 録音開始の閾値
threshold_stop = 0.01 # 録音終了の閾値
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
# メイン
# -----
def main():
while True:
mic_input = input_audio()
text = voice_to_text(mic_input)
if text == "終了。":
stream.close()
p.terminate()
sys.exit()
# 音声入力部
# -----
def input_audio():
frames = []
buf_old = []
stream.start_stream()
while True:
# 音声入力待ち
buf = read_stream()
if buf.max() / 32768 > threshold_start:
# 音声入力判定されたら録音処理
print("録音開始")
frames = recording(buf)
print("録音終了")
stream.stop_stream()
# 一時保存データがあれば先頭に追加
if len(buf_old) != 0:
frames.insert(0, b''.join(replacebyte(buf_old)))
return b''.join(frames)
# 音声を一時保存
buf_old = buf
# 繰り返し
# テキスト変換部
# docomo音声認識APIを利用
# -----
def voice_to_text(audio):
APIKEY = '[取得したAPIキー]'
url = "https://api.apigw.smt.docomo.ne.jp/amiVoice/v1/recognize?APIKEY={}".format(APIKEY)
files = {"a": audio, "v": "on"}
r = requests.post(url, files=files)
json_data = r.json()
text = json_data['text']
print(text)
return text
# 録音
# -----
def recording(buf):
frames = []
frames.append(b''.join(replacebyte(buf)))
cnt = 0
for i in range(1, int(RATE / CHUNK * MAX_RECORD_SECONDS)):
buf = read_stream()
frames.append(b''.join(replacebyte(buf)))
# 一定時間音声入力が無ければ終了
cnt = count_silent_frame(cnt, buf)
if cnt > (RATE / CHUNK * SILENCE_SECONDS): return frames
return frames
# ストリーム読み込み
# -----
def read_stream():
data = stream.read(CHUNK)
buf = downsampling(data)
return buf
# ダウンサンプリング
# -----
def downsampling(data):
x = np.frombuffer(data, dtype="int16")
return x[::3]
# エンディアン変換(上位8bitと下位8bit入れ替え)
# -----
def replacebyte(data):
z = []
for i in range(0, int(len(data))):
x = np.frombuffer(data[i], dtype="int8")
y = (x[1], x[0])
z.append(b''.join(y))
return z
# 無音時間の連続フレーム数カウント
# -----
def count_silent_frame(cnt, buf):
if buf.max() / 32768 < threshold_stop:
cnt = cnt + 1
else:
cnt = 0
return cnt
if __name__ == "__main__":
main()
録音後にまとめて入れ替えれば簡単だったのですが、録音終了→データ送信の間の時間を減らそうと思ってストリームを読み込む度に入れ替えてみたのですが、やってみると思った以上に面倒くさかった・・・。
あとはコードが長くなったのでファンクション毎に分離してみました。(分けすぎ?)
でもおかげで色々と勉強になりました。
最後まで見てくださった方はありがとうございました。
(10/27追記)
見返して気づいたのですが、最後コードでwaveをimportしていたのは完全に無駄でしたね。。。。消しておきました。