音声認識を使ったアプリを作りたかったので、公開されている技術でどこまで正確に音声認識ができるか調べてみた。
結論
現在公開されている技術で、長文の音声入力をテキスト化するのは難しそう。
制限を設けて、決まったフレーズの認識はできそうなので、「テレビをつける」「テレビを消す」などの音声を入力とし、
テレビのON/OFFなどの制御はできそう。
調査方法
「坊ちゃん」の冒頭部分の音声データを入力とし、認識結果を確認する。
使用する技術(API)によって、マイクからの入力 or 録音データファイルを入力とする。
青空文庫のサイトより引用:http://www.aozora.gr.jp/cards/000148/files/752_14964.html
親譲りの無鉄砲で小供の時から損ばかりしている。小学校に居る時分学校の二階から飛び降りて一週間ほど腰を抜かした事がある
Google Speech API
精度は高いが、利用制限が厳しすぎる
Google Speech APIは、Chromium Dev groupに参加した開発者のみしか利用できない。
また、1日50リクエスト/1リクエストは10〜15秒程度の音声データしか利用できないなどの厳しい使用条件がある。
Google Speech API
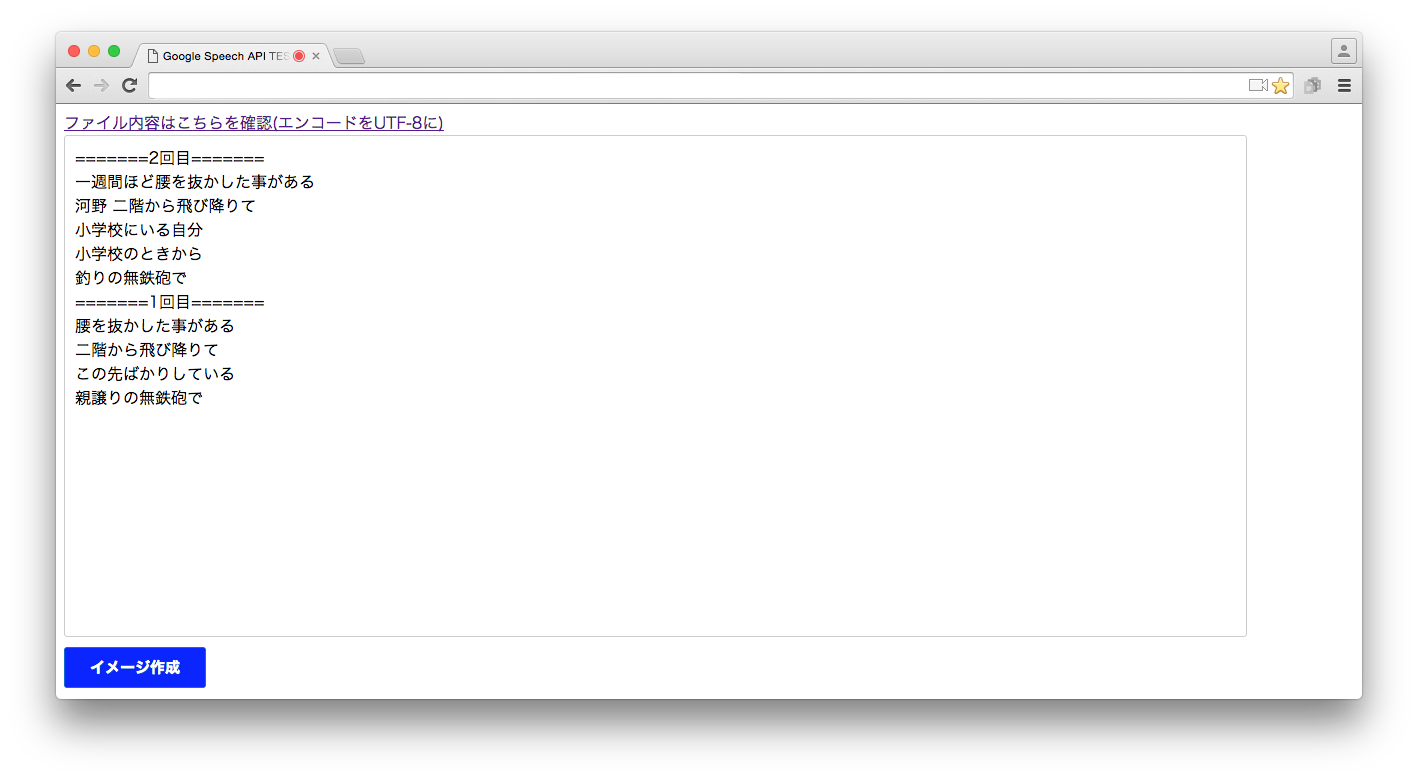
1回目
アプリの無鉄砲で 子供の時から損ばかりしている小学校にいる気分 学校の二階から飛び降りて一週間ほど腰を抜かした事がある
2回目
釣りの無鉄砲で 子供の時から損ばかりしている 小学校にいる気分 学校の二階から飛び降りて一週間ほど腰を抜かした事がある
実行メモ
// soxインストール
$ brew install sox
// 音声録音
$ rec --encoding signed-integer --bits 16 --channels 1 --rate 16000 <出力ファイル名(test.wav)>
// flac形式に変換(flac形式のファイルが作られる(test.flac))
$ flac -V <変換するファイル(test.wav)>
// google speech APIで音声認識
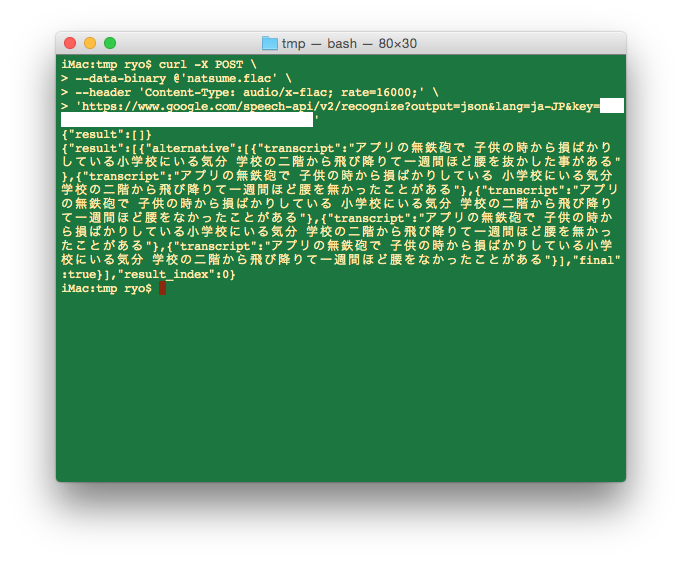
$ curl -X POST \
--data-binary @'<ファイル名>' \
--header 'Content-Type: audio/x-flac; rate=16000;' \
'https://www.google.com/speech-api/v2/recognize?output=json&lang=ja-JP&key=<API Key>'
// 結果
{"result":[{"alternative":[{"transcript":"アプリの無鉄砲で 子供の時から損ばかりしている小学校にいる気分 学校の二階から飛び降りて一週間ほど腰を抜かした事がある"},{"transcript":"アプリの無鉄砲で 子供の時から損ばかりしている 小学校にいる気分 学校の二階から飛び降りて一週間ほど腰を無かったことがある"},{"transcript":"アプリの無鉄砲で 子供の時から損ばかりしている 小学校にいる気分 学校の二階から飛び降りて一週間ほど腰をなかったことがある"},{"transcript":"アプリの無鉄砲で 子供の時から損ばかりしている小学校にいる気分 学校の二階から飛び降りて一週間ほど腰を無かったことがある"},{"transcript":"アプリの無鉄砲で 子供の時から損ばかりしている小学校にいる気分 学校の二階から飛び降りて一週間ほど腰をなかったことがある"}],"final":true}],"result_index":0}
Web Speech API
ChromeのwebkitSpeechRecognition APIを使用しての音声認識。
(確認にはwebspeechapiのラッパー的なannyangというなJSライブラリを使用)
あまり認識率はよくない、特に発話の最初の部分の認識率の精度は悪い。
入力する音声データもwebkitSpeechRecognitionに任せているため、入力データを加工することもできない。
docomo 音声認識API
音声認識API【Powered by NTTアイティ】
APIを利用して開発したアプリケーションは個人利用に限定。
Android,iOS,Browser用にそれぞれSDKが用意されている。
iPhoneにデモアプリを入れて試してみたが、まあまあの認識率。
音声認識API【Powered by アドバンスト・メディア】
音声データをREST形式で送信するだけで音声認識をすることができる。
APIを利用して開発したアプリケーションを商用利用する際には、無償提供などの提供形態を問わず有償契約が別途必要
10秒を超える音声データは途中で打ち切られる。
入力の音声データはGoogle Speech APIと同じものを使用しているが、Google Speech APIに比べて精度が低い。
1回目
ブルースリーのも手を、今時から損ばかりしている。小学校、1分ある。学校に耐えたとき、
2回目
何をするのも手を子供の時から損ばかりしている。小学校にいる気分。
実行メモ
$ ./post.py <入力ファイル>
# ! /usr/bin/python
# coding:utf-8
import urllib
import urllib2
import sys
import requests
if len(sys.argv) != 2:
print "error:argv is not 1"
exit(1)
url = 'https://api.apigw.smt.docomo.ne.jp/amiVoice/v1/recognize?APIKEY=<API Key>'
f = open(sys.argv[1], 'rb')
data = f.read()
f.close()
files = {"a": open(sys.argv[1], 'rb'), "v":"on"}
r = requests.post(url, files=files)
print r.json()['text']
Julius
Julius を動かしてみるために必要なキットであるJuliusディクテーション実行キットを動かしてみたが、ほとんど認識しなかった。
坊ちゃんの冒頭を読んだが。。。
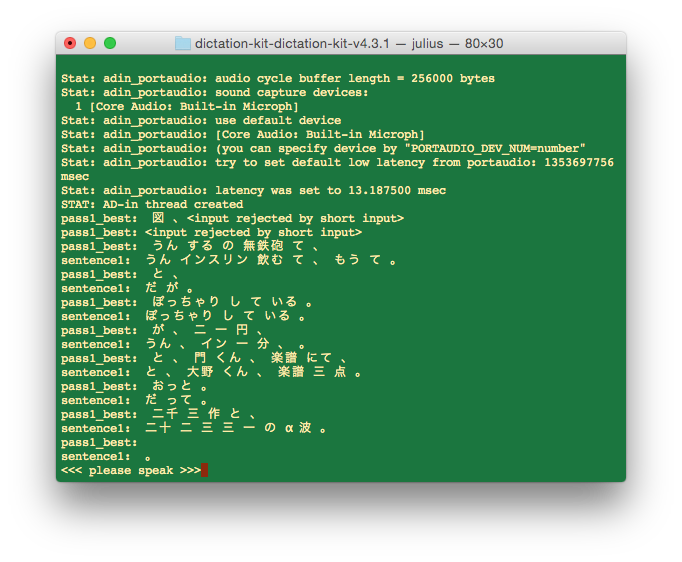
キットの説明文に以下の記述があるので、辞書に色々な言葉と登録する必要があるよう。
なお,このシステムで認識できる発話には以下のような限界があります.
・辞書にない未知語は全く認識できない
(ユーザ辞書登録も無し)
・ユーザのくせを学習する,いわゆる話者適応に未対応
他の人のサイトでは、精度は低いながらも、もう少しまともな結果が返ってきているので、なにかインストール手順などに問題がるのかも。。
また、カスタマイズすれば、実用的なものになる等の記事もあるため、時間があればまた調べる。
ただ、以下のよう記述もあるので、事前準備は大変そう。
Juliusの最大の特徴は、汎用性・可搬性である。
すなわち、音響モデルや言語モデルなどのインタフェースが公開されており、それらを置き換えたり、修正したりするのが容易なことである。
これにより、様々な使用環境や目的に応じたシステムの構築が簡単にできる。
さらに、ソースコードも公開されているので、システム自体の修正・拡張も可能である。
逆に事前登録学習(エンロールメント)や自動適応学習などの機能は現在実装されておらず、単語登録をするGUIもないので、音響モデルや単語辞書・文法ファイルなどを直接操作する必要がある。
http://www.ar.media.kyoto-u.ac.jp/lab/bib/review/KAW-JSAI05.pdf より
音声認識を使ったもの
iOSなどの音声認識を使った入力についても調べてみた。
AppleやGoogleの音声認識はかなりの精度が高い。
iOS
iOS標準の音声認識機能のAPIは現在非公開であり、アプリに組み込むことはできない。

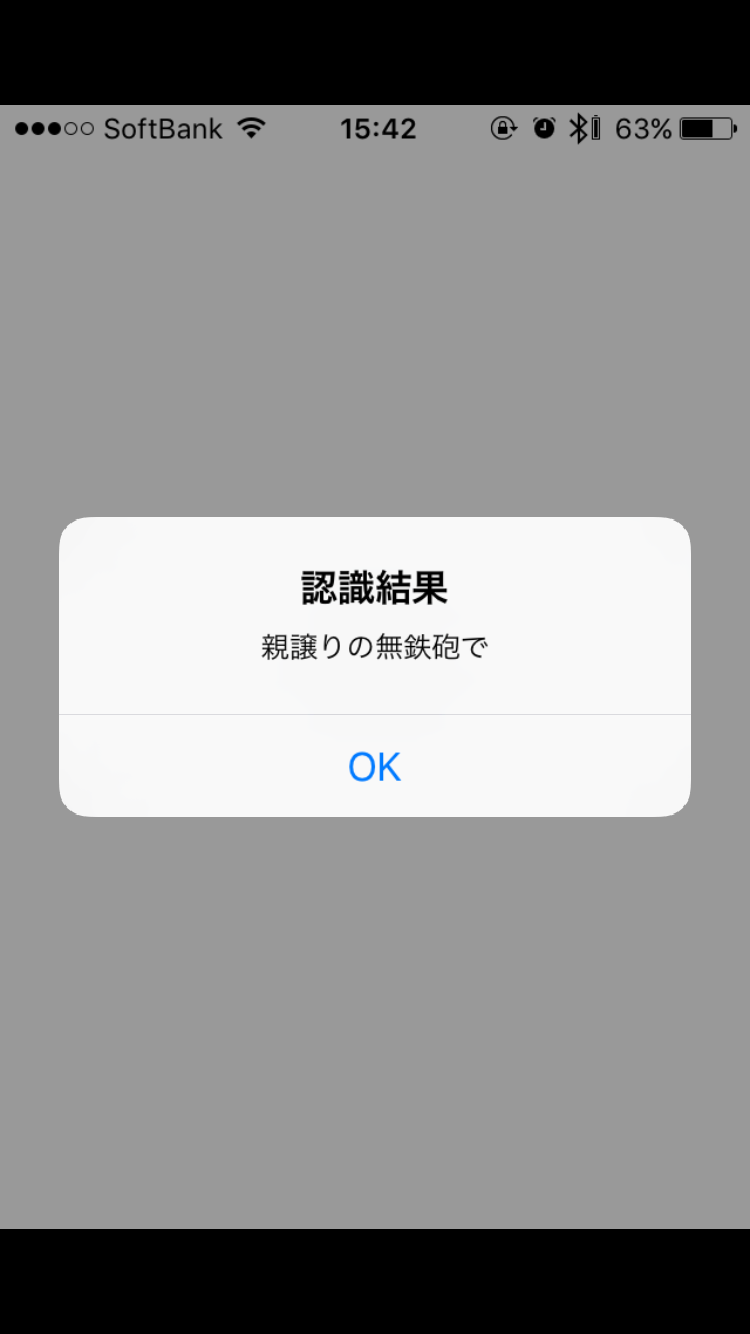
1回目
親譲りの無鉄砲で子供の時から損ばかりしている小学校に入る自分学校の2階から飛び降りて1週間ほど故障中したことがある
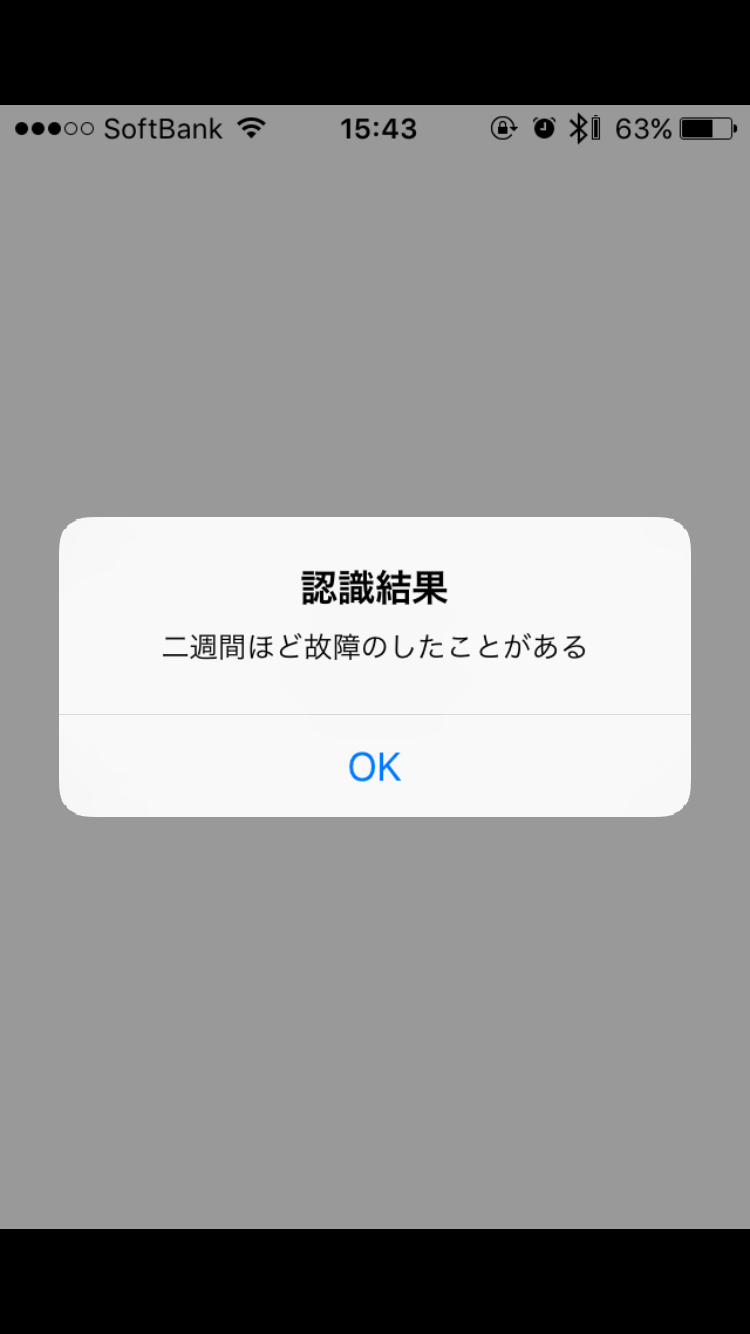
2回目
親譲りの無鉄砲で子供の時から損ばかりしている小学校に入る自分学校の2階から飛び降りて1週間ほど故障中したことがある
Googleドキュメント
[ツール]→[音声入力]を選択し、音声入力を行う。
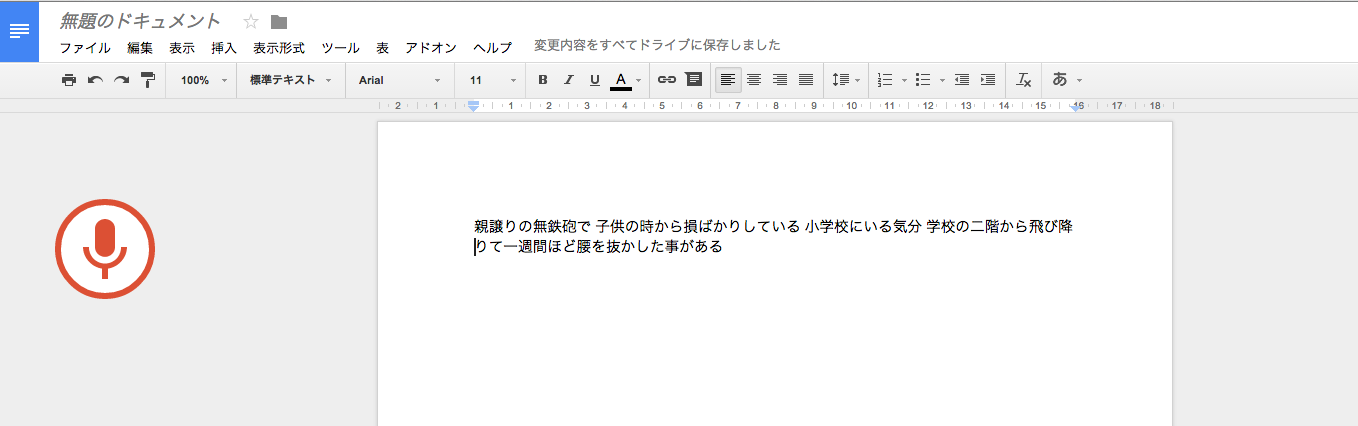
1回目
親譲りの無鉄砲で 子供の時から損ばかりしている 小学校にいる気分 学校の二階から飛び降りて一週間ほど腰を抜かした事がある
2回目
親譲りの無鉄砲で 子供の時から損ばかりしている その学校にいる気分 学校 何階から飛び降りて 一週間ほど腰を抜かした事がある