データにある改行コードを置換する際、Advanced options内の2つのオプションそれぞれの意味について、認識と違う部分があったので整理します。
この記事で指している改行コードは何か?
Excelで「Alt+Enter」を押した際に挿入される改行コードのラインフィード(LF)です。Excelでは「検索と置換」から検索する文字列に「Ctrl+j」を挿入することで検索または置換ができます。
文字列の置換に関する2つのオプション
Power BIではGUIからも簡単に文字列を置換できます。その際にAdvanced optionsを開くと、2つのチェックボックスがあります。1つ目は"Match entire cell contents"、2つ目は"Replace using special characters"です。
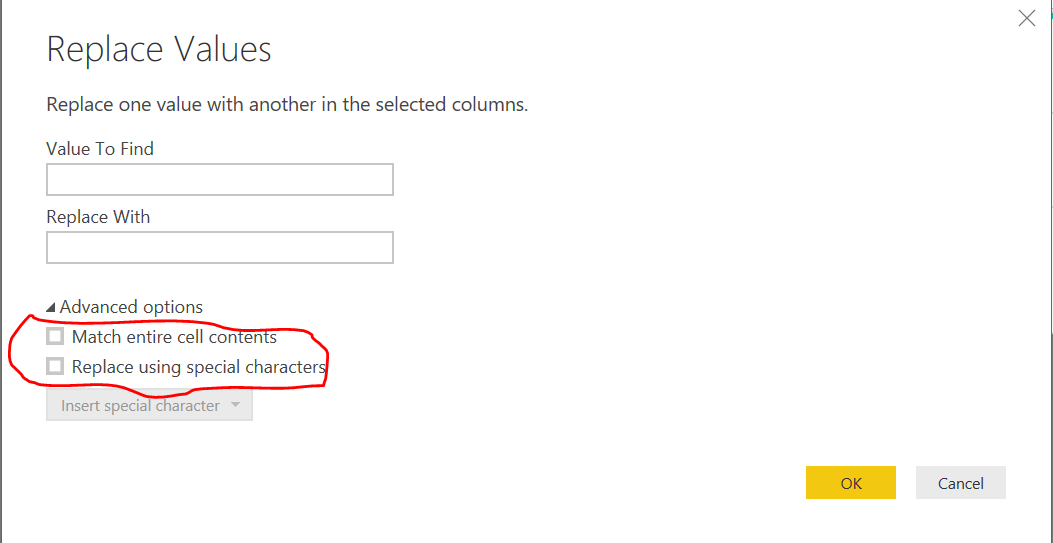
この表示上の右下にあるOKを押した後にPower Queryとして挿入されるのはTable.ReplaceValue関数です。
なにが認識と違ったのか
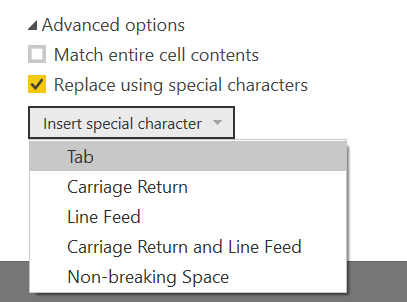
2つ目のチェックボックス"Replace using special characters"は改行コードなど特殊文字を置換するオプションです。単に#(lf)を置換する場合は、2つ目のチェックを入れた状態で"Insert special character"を押し、開かれたドロップダウンメニューの中から"Line Feed"を選択すれば#(lf)が置換対象として設定されます。
私の認識が違っていたのは1つ目のチェックボックスでした。
1つ目のオプションの意味
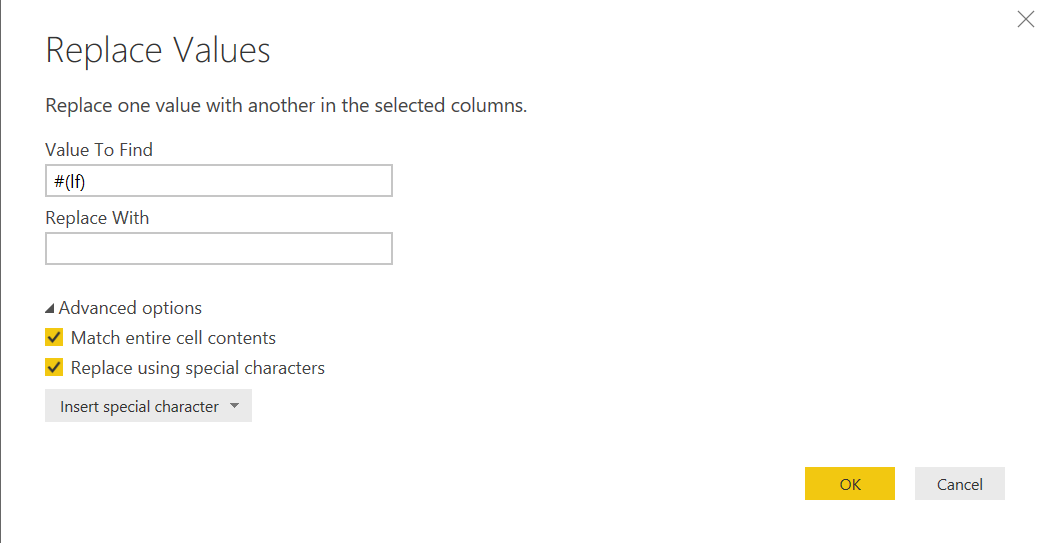
誤:繰り返しを全て置換する
正:完全一致のみを置換する
なので両方にチェックを入れても、改行のみが存在するフィールド以外置換されません(当たり前ですが)。またオプションをつけない場合、繰り返し登場する改行コードは基本的に全て置換されます。
私はこの勘違いで2ヶ月間も溶かしてしまい、反省を込めて記事にしました。
全ての改行を置換したく無い場合はどうしたらいいのか?
基本的に繰り返しは全て置換されるので、部分的に置換したい時のパターンを考えたいと思います。Table.ReplaceValue関数には登場する順番を考慮して置換するオプションは無いため、Text関数をいくつか使って追加カラムを作成する方法を考えました。
1つ目の改行だけを置換したい場合は?(追加カラムとして)
Text.Start(
[元データ],
Text.PositionOf([元データ], "#(lf)")
)
& Text.End(
[元データ],
Text.Length([元データ]) - Text.PositionOf([元データ], "#(lf)") - 1
)
最後の改行だけを置換したい場合は?(追加カラムとして)
Text.Start(
[元データ],
Text.PositionOf([元データ], "#(lf)", Occurrence.Last)
)
& Text.End(
[元データ],
Text.Length([元データ]) - Text.PositionOf([元データ], "#(lf)", Occurrence.Last) - 1
)
※任意の位置で置換する方法についても考えています。
※本記事が初投稿なので、書き方のアドバイスなど頂けましたら幸いです。
※追記(2019/07/17)
コメントでいただいた@tanuki_phoenixさんのアイデアです。
任意の位置で改行を除去したい場合は?
(Source as text,cnt as number)=>
let
分割後 = Splitter.SplitTextByDelimiter("#(lf)")(Source),
文字列生成=List.Accumulate(List.Positions(分割後),
"",
(x,y)=> x & (if y=cnt or y=0 then "" else "#(lf)" ) & 分割後{y}
)
in
文字列生成
New SourceからBlank Queryを選択し、
このpower queryをコピペするとカスタム関数を作成できます。
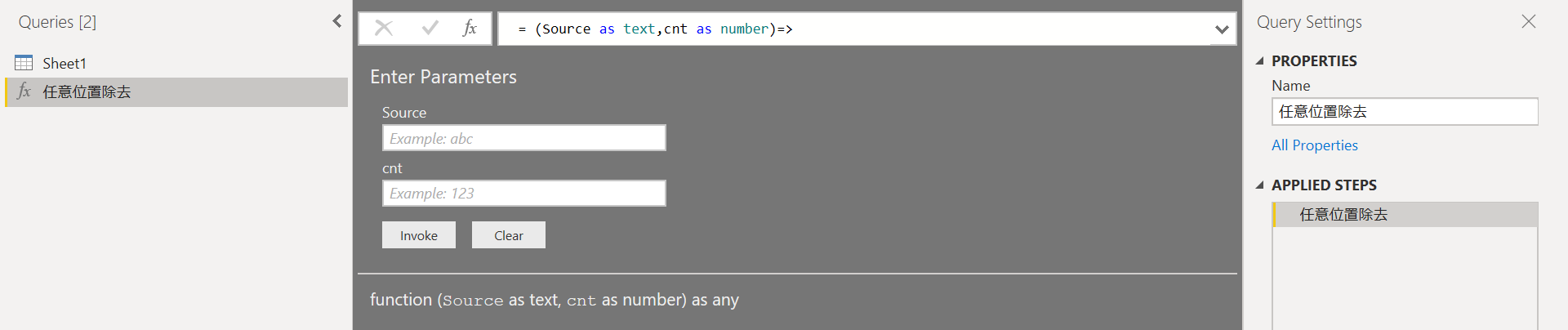
Add Columnタブから"Invoke Custom Function"を選択して、
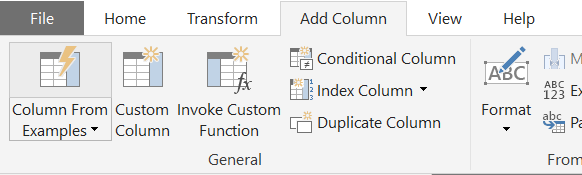
上から順に、追加する列名、使用するカスタム関数の名前、置換したい元データの列、置換したい任意の位置(数値)を入力しOKを押します。
「任意の位置で除去」の列のように2番目の位置で改行を除去できました。

任意位置の改行除去以外にも2つのアイデアをいただきましたので、同じくカスタム関数として使用できる形で下記にまとめています。
最初の位置で改行を除去したい場合は?
(Source as text)=>
let
文字列生成=Text.Combine(Splitter.SplitTextByEachDelimiter({"#(lf)"})(Source))
in
文字列生成
Splitter.SplitTextByEachDelimiter関数にオプションを付けない場合は、1つ目のDelimiterで分割することになるのでクエリが簡潔になりますね。
最後の位置で改行を除去したい場合は?
(Source as text)=>
let
//改行で全部ばらす.改行の数+1個のリストになる.
Source = Splitter.SplitTextByDelimiter("#(lf)")(Source),
//リストに入っている個数だけ,頭から適用される.なので,改行数を1個減らす.
Custom1 = Combiner.CombineTextByEachDelimiter(
List.Repeat({"#(lf)"},List.Count(Source)-2)
)(Source)
in
Custom1
オプションで分割の位置指定ができるので、一度全ての改行位置で文字列を分割したリストを作り、それを再び最後の位置以外で結合させるという方法。
未検証ですがListで処理をした方が早い気がするので、大規模データにはこちらを使用した方が良いかもしれません。
@tanuki_phoenixさん、ありがとうございました。