この記事はHacobu Advent Calendar 2024の10日目の記事です。
株式会社Hacobu テクノロジー本部CTO室 ソフトウェアエンジニアの須田です。社内FAQをRAG化した際の精度検証がとても有用だった話を書きます。
RAGはハルシネーション対策になりうるか?
近年、生成AI、特に大規模言語モデル(LLM)の進化が著しく、その適用先は日々、広がりつつあります。しかし、LLMの実用化には様々な課題があり、その最大の課題の一つがハルシネーション(幻覚)、つまりはLLMが尤もらしく嘘の回答をしてしまう現象です。特にビジネスシーンにおいては深刻な問題と捉えられ、LLMの採用を妨げる大きな要因となっています。
この課題に対する有力な解決策として注目されているのが、Retrieval-Augmented Generation(RAG)です。RAGは、LLMの知識を外部の情報源で補完し、モデルの知識不足を克服する技術であり、社内の膨大な情報を効果的に活用する手段として、最近、特に注目されています。
特に、ITヘルプデスクへのRAGの適用が成功事例として語られることが多く、IT関連の社内の問い合わせに対して、FAQや社内データを読み込んだRAGが回答するチャットシステムは業務効率を大幅に改善できると言われています。もし仮にチャットシステムで解決できない場合、人間が対応することで、結果的にヘルプデスクの対応が70%減少するそうで、ユーザにとってデメリットは全くありません。
一般的なRAGのシステム構成を以下に示し、簡単の処理の流れをご説明します。
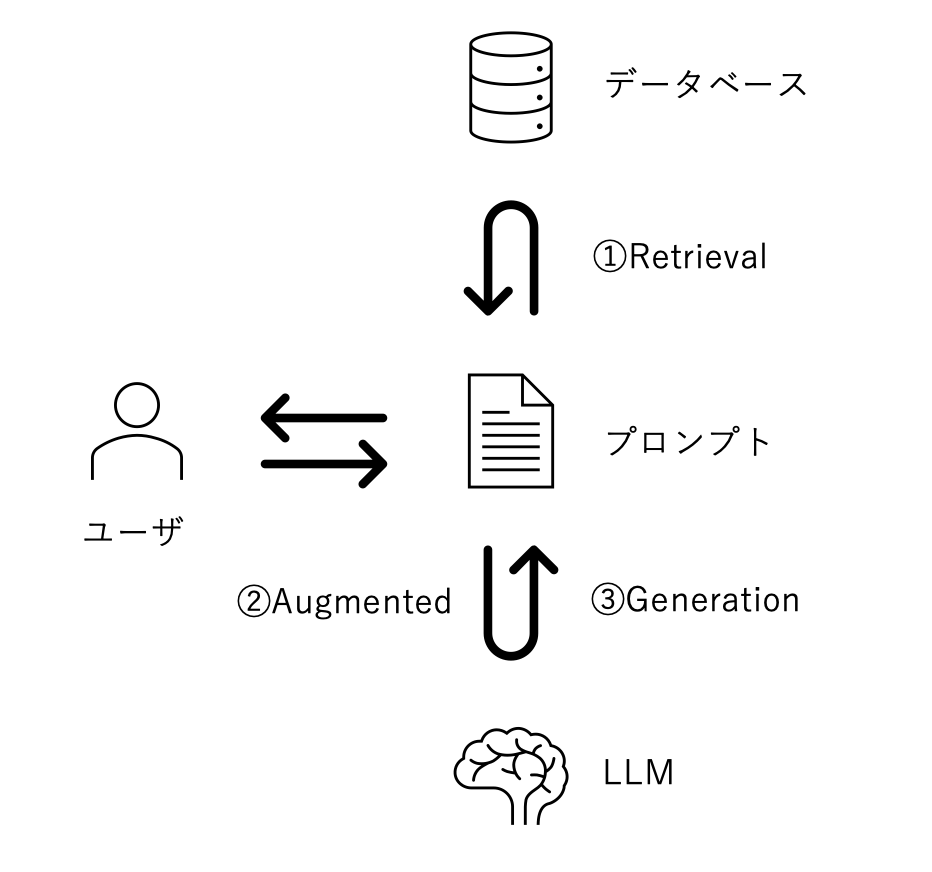
① Retrieval
- 社内ドキュメントやFAQから生成したデータベースを検索し、質問に関連する情報を抽出
② Augmented
- 抽出した情報と質問とでプロンプトを拡張し、LLMに問い合わせ
③ Generation
- 提供した情報に基づいた回答をLLMに生成させることで、ハルシネーションを防止
このような構成であるため、RAGの最大の弱点は、データベースから抽出した情報の中に、質問に対する回答が含まれていない場合、LLMが正解となる文章を作成できない点です。そのため、従来からある検索エンジン技術を駆使して、回答を含む情報をデータベースから引き出す検索技術がとても重要となります。
検索精度を向上するための技術
参考文献[1]にも示す通り、RAGにおける検索精度を向上させるための方法は多数あります。これらの一部を技術分野毎に図式化したものを下記に示します[2]。

とりわけ図中の中央から右側の技術は検索精度への影響度が大きく、主な技術分類とその詳細を以下でご説明します。
- チャンキング
文章を様々な粒度で分割し、処理の効率化や精度向上を図るための処理ですが、一般的にLLMのトークンサイズに上限があるため、チャンキングは必須と言えます。 - エンベッディング
文章をベクターデータに変換するための処理で、単語を浮動小数点の値に変換します。ベクターデータベースでの検索処理では、浮動小数点同士を比較する類似検索を行います。 - ベクターデータベース(DB)
様々なフォーマットが存在し、類似検索の精度や検索速度に差異があります。 - リトリーバル
ベクター検索だけでなく、TF-IDF(Term Frequency–Inverse Document Frequency)やBM25(Best Matching 25)などのキーワード検索を組み合わせたハイブリッド検索や、HyDE(Hypothetical Document Embeddings)と呼ばれる、仮の回答をLLMに生成させ、ベクター検索で正解を抽出しやすくする手法などがあります。質問と回答文書が類似しているとは限らないため、HyDEは仮の回答でデータベースを類似検索する方が精度は高まるという考えに基づいています。 - リランキング
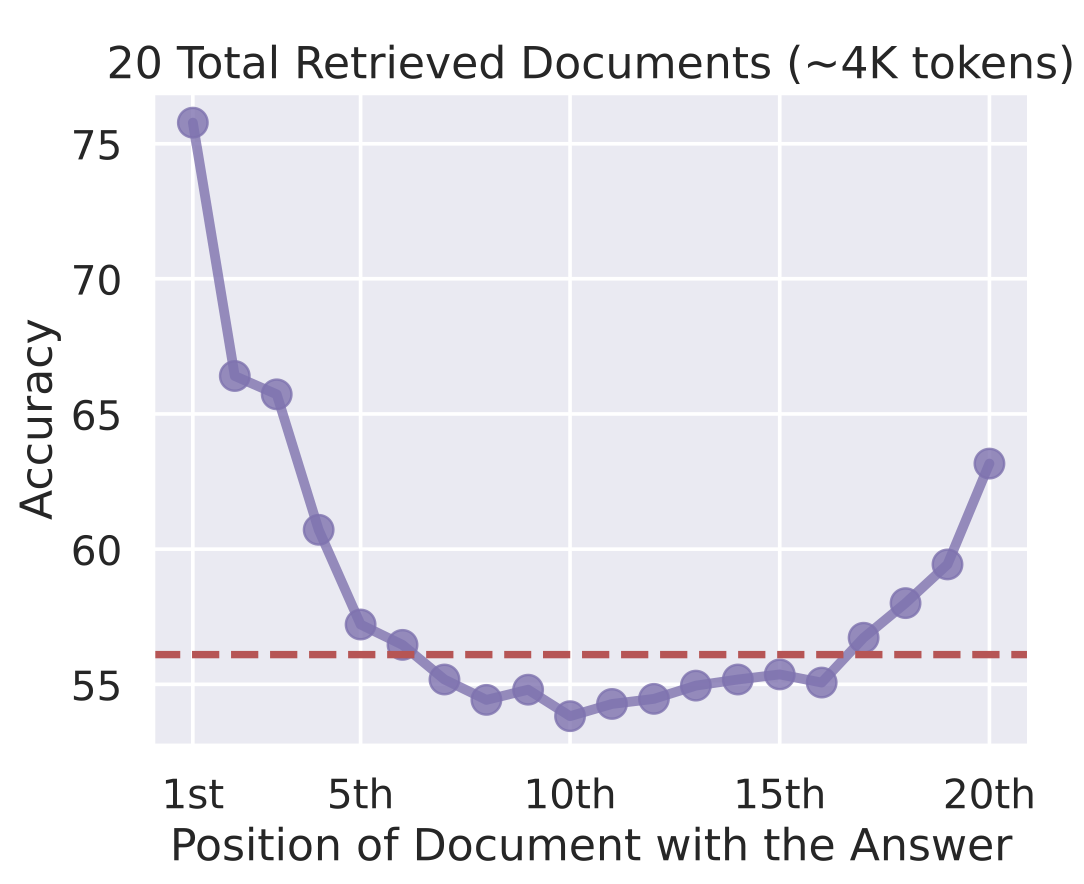
下図に示すように、LLMには”Lost in the Middle”という問題が報告されています[3]。拡張したプロンプトに含める関連情報の列挙順序が、LLMの回答精度に影響を与え、順序が前に位置するほど、回答に利用されやすいという問題です。そのため、関連情報がより前に位置するようにベクター検索結果を再ソートするのが、リランキングです。
検索精度検証のすゝめ
前節では、検索精度を向上させる方法として様々な方法があることを示しました。それでは、どのようは手法を組み合わせてシステムを構築すれば、RAGの精度は向上するのでしょうか?
答えは「試してみないとわかりません」です。
最近、SIGNATE社が主催となって、RAG-1グランプリなるコンペが開催されました。筆者も参戦しましたが、その開催目的には「RAGはまだ黎明期にあり、標準化された手法や確立されたノウハウが十分ではないため、多くの企業がどのようにRAGを構築すべきかが分からない、あるいは構築しても期待通りの結果が得られないという課題に直面している」と記されています。
精度向上のための手法がいろいろあることに加え、システムの構築できる場所や利用できる技術・ソフトウェアの制限などは企業によってまちまちであることも影響しているはずです。まずは、検証のためだけのシステムをさくっと構築し、RAGの”Retrieval”に相当する検索精度をテストデータで検証することを強くおすすめします。
評価用データセット
東京都立大学で導入されたeラーニングシステムのユーザーから2015年4月から2018年7月までに報告された問題点をQ&Aデータとして集約し、インターネットでCSVファイルとして公開されています[5]。
質問は全部で427個あり、回答が79個あります。すべての質問に対して正解となる回答のラベルが付けられているため、検証データとして利用できます。様々な技術を組み合わせて、回答内容から独自のベクターDBを構築し、各質問に対する検索結果を用いて精度検証ができます。
評価指標
回答精度の評価指標としては様々な指標が考えられますが、まずは下記の2つの指標を利用すれば問題ないと思います。
- NDCG@k(Normalized Discounted Cumulative Gain)
一般的な検索エンジンの指標として広く利用され、検索結果上位k件を対象とし、実際の検索結果を理想(最も関連度の高い文書が上位にくるとき)の検索結果で割った正規化された値です。
関連性スコアの高い文書が上位に提示されているほどスコアが大きくなり、関連性スコアが低い文書を上位に提示するほどスコアが小さくなる。 - Recall@k
正解ドキュメントが上位k位以内に入っているかどうかの評価指標です。
生成AIに渡すドキュメントは、上位ほど利用される可能性が高いため、kが小さい場合の精度を重視すべきと言える。
Hacobuでの検証事例
参考までに、Hacobuで実施した検証事例をご紹介します。Hacobuでは下記の技術を選択的に組み合わせて、精度検証を行いました。
ベクターデータベース
- FAISS
- Chroma
エンベッディング
- OpenAI社
- text-embedding-ada-002
- text-embedding-3-small
- text-embedding-3-large
- BAAI(清華大学)
- bge-m3[6]
リトリーバル
- キーワード検索(ハイブリッド検索のための事前検証)
- TF-IDF
- BM25
- ハイブリッド検索
リランキング
- Cohere[7]
検証結果
精度の検証結果を上記で示した項目別に示します。
ベクターデータベース
数値では示しませんが、エンベッディングモデルを問わず、FAISSとChromaとに精度差は見られませんでした。念のため、検索レスポンス速度も計測しましたが、差異はありませんでした
この結果を受けて、インターネットで公開されている事例が多かったFAISSを採用しました
エンベッディング
OpenAI社が提供する3つのモデルとBAAI(清華大学)が開発したオープンモデルを比較しました。
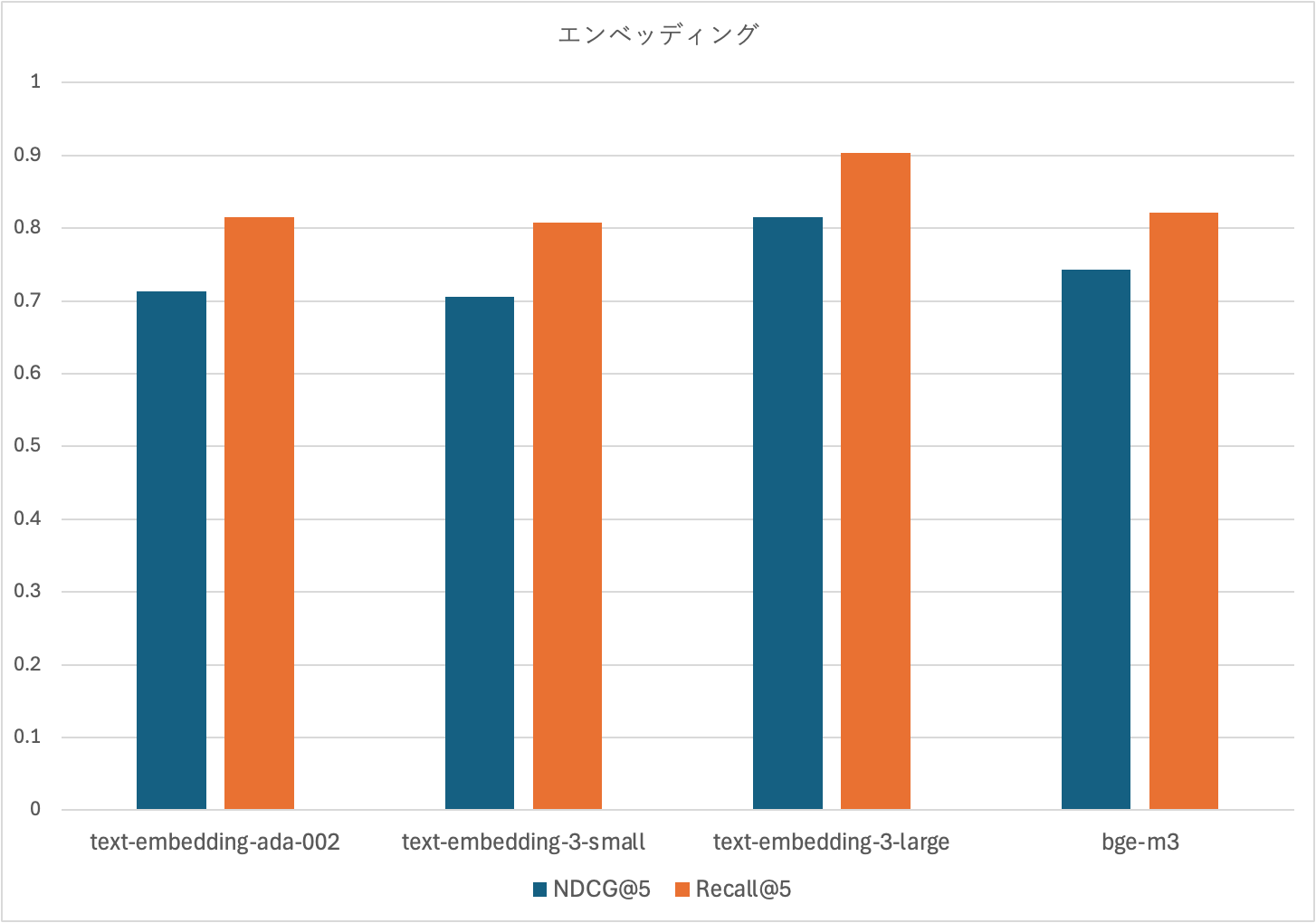
最大3072次元のベクトルを生成できる、OpenAIから提供されているエンベッディングモデルtext-embedding-3-largeが最も高精度だったため、このエンベッディングモデルを今後の検証の比較軸としました。
キーワード検索
TF-IDFとBM25を比較しました。
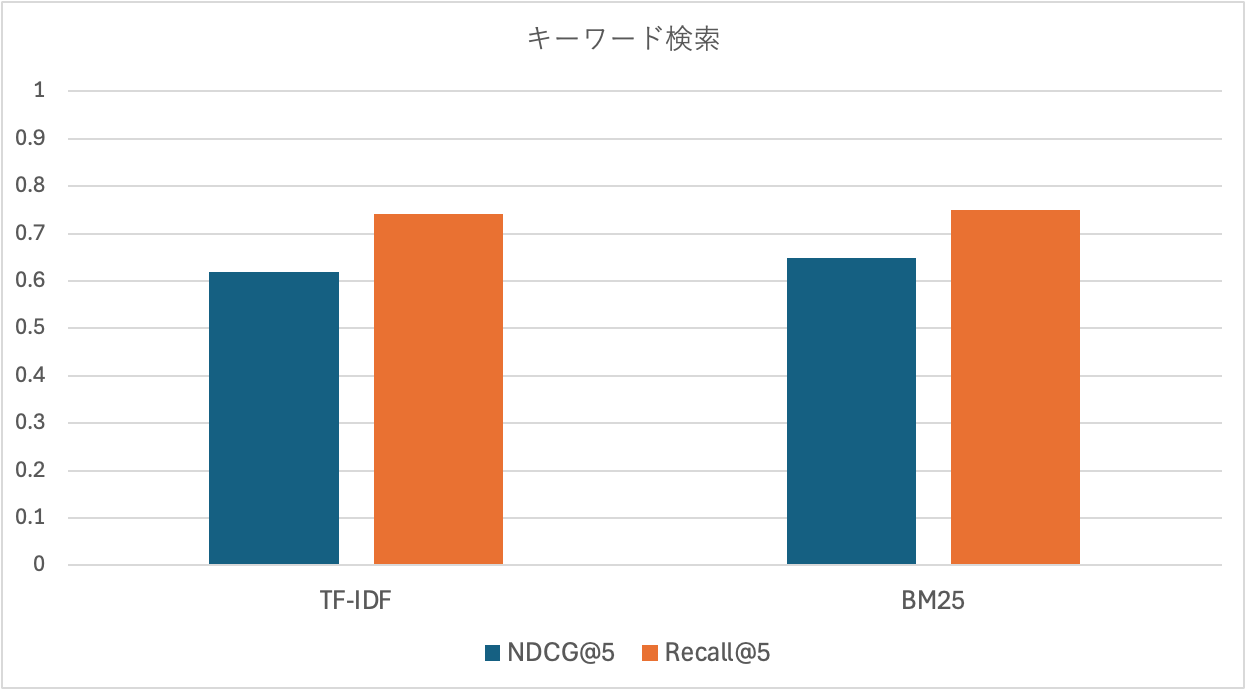
どちらの指標もほぼ変わらないが、若干BM25の方が高精度です。もしハイブリッド検索を実施する場合はBM25を採用する方針としました。
ハイブリッド検索
エンベッディングモデルtext-embedding-3-largeのベクター検索のみとBM25とのハイブリッド検索とを比較しました。
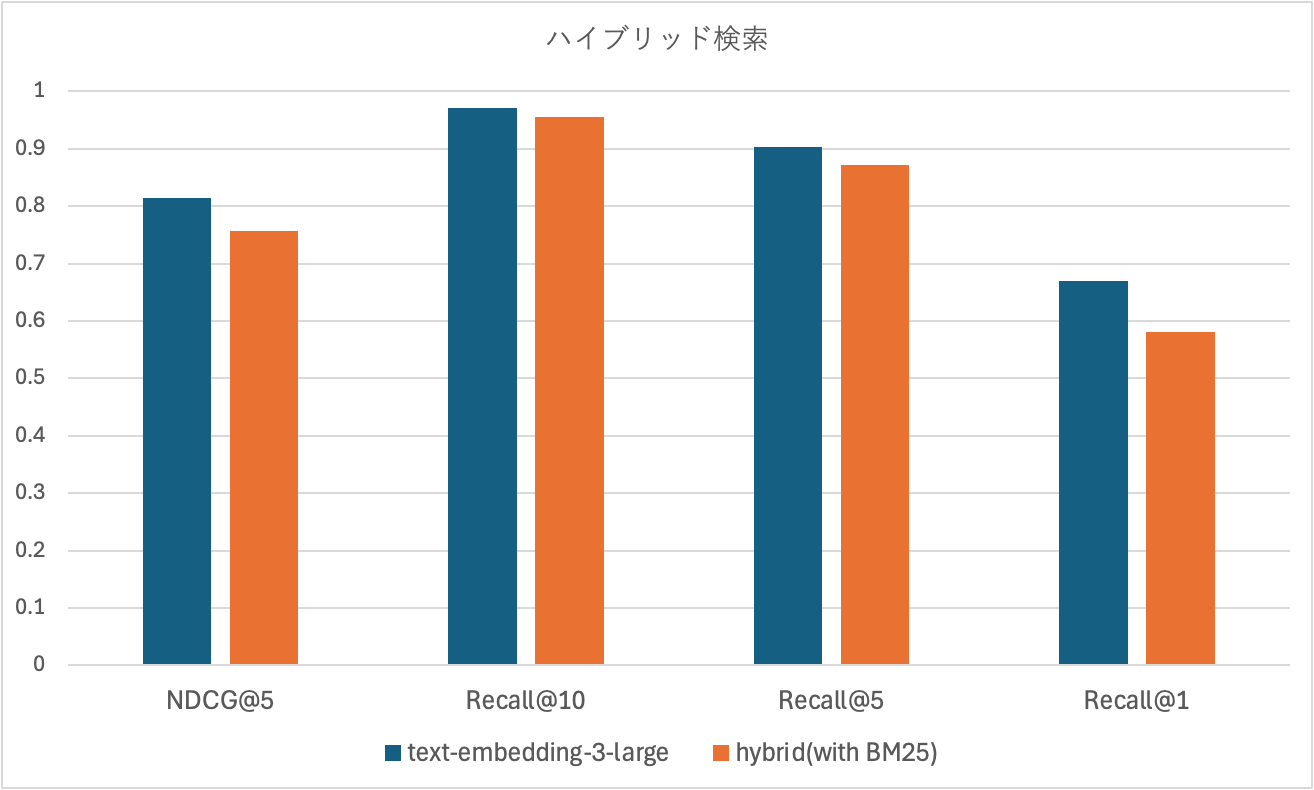
LLMには検索結果の10件をプロンプトに含めるつもりだったため、Recall@10も比較した結果、すべての指標において、ハイブリッド検索より、ベクター検索のみの場合が高精度でした。
この結果を受けて、ハイブリッド検索の採用は見送り、ベクター検索のみを採用する方針とした。もし実運用でベクター検索のみで精度問題が発生した場合に、改めてハイブリッド検索を検討することとしました。
リランキング
cohere社のリランキングを利用するために、同社が提供するエンベッディングモデルembed-multilingual-v3.0を利用する必要があり、このモデルを利用して検証しました。
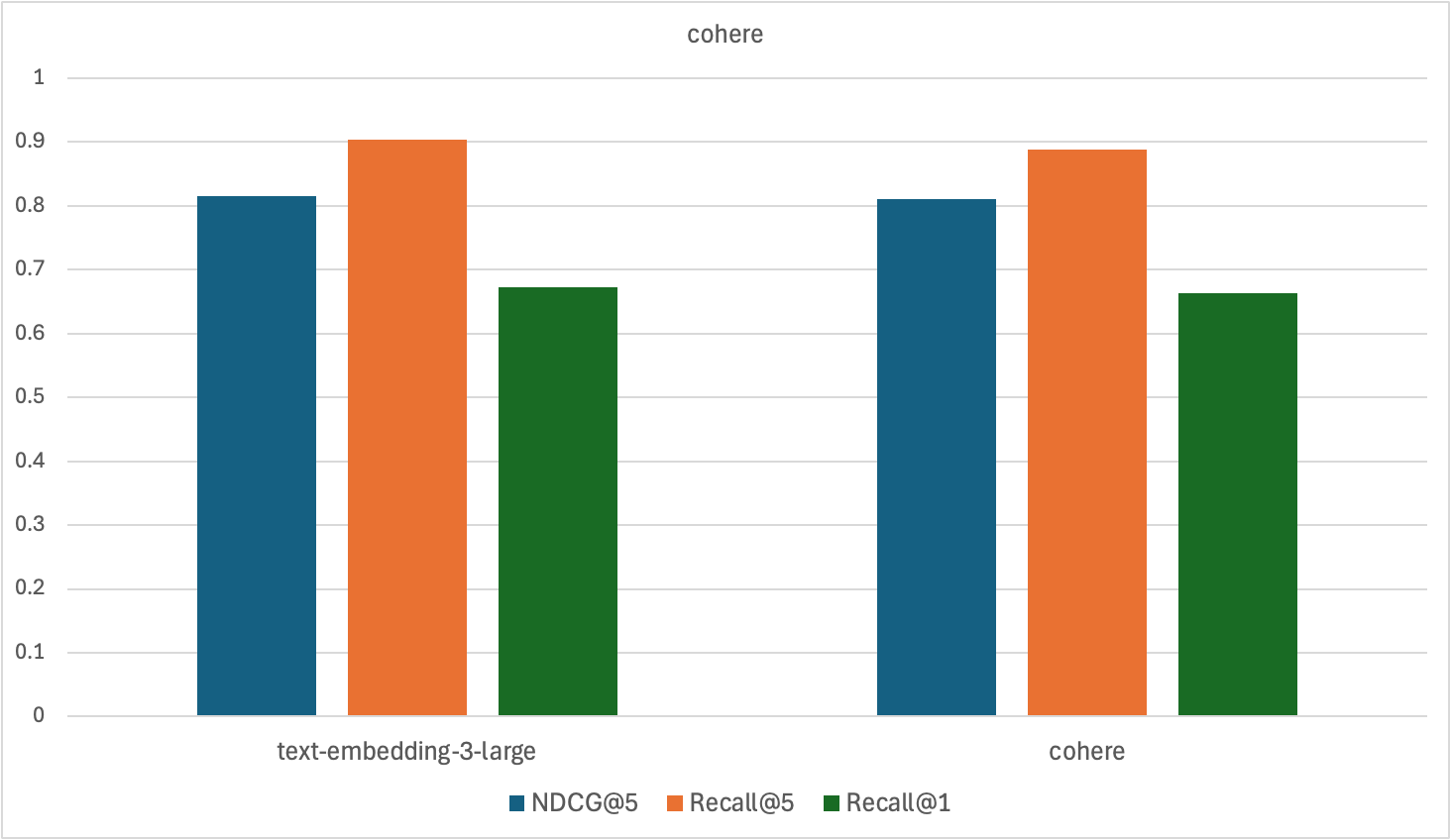
Recall@1で精度が上がることを期待しましたが、精度がほぼ変わらなかったため、cohereのリランキングモデルの採用は見送りました。
まとめ
LLMのハルシネーション対策としてRAGが有力候補であり、社内FAQをRAGシステム化するに際して、今回の検証結果を踏まえ、下記技術の組み合わせでシステム設計を行い、社内FAQのRAGシステムを開発し、既に運用を開始している。
- ベクターDB:FAISS
- エンベッディングモデル:text-embedding-3-large
- ハイブリッド検索:採用せず
- リランキングモデル:採用せず
RAGシステムのリリース以後、利用者が徐々に増え、問い合わせに対して人による対応件数は、RAGシステム導入前と比べて、70%ほど削減できた。読者の方が所属する企業でも、是非、社内FAQのRAG化を行う際には、みっちり検証することをおすすめします。
参考文献
[1] RAG入門: 精度改善のための手法28選
[2] Searching for Best Practices in Retrieval-Augmented Generation
[3] Lost in the Middle: How Language Models Use Long Contexts
[4] RAG-1グランプリ
[5] 東京都立大学のeラーニングシステムのQ&Aデータ
[6] https://huggingface.co/BAAI/bge-m3
[7] https://cohere.com