RAGの精度改善するために何があるかを学びました。基本系のNaive RAGを知っている人向けの記事です。
方法が多すぎるので、Youtubeの「RAG From Scratch」を中心に少し整理してみました。LangChainをよく使っているので、LangChain出典が多いです。
全体像
まずは、RAGの全体像。Indexingが同じ流れにあるのが少しわかりにくいのですが、実行タイミングとしてはRAGの前準備としてやっておきます。

画像出典: RAG from scratch: Overview
もう少し粒度を細かくした図です。

画像出典: RAG from scratch: Overview
表形式で分類します。Generationだけ少し特殊です。
| 大分類 | 中分類 | 内容 |
|---|---|---|
| Indexing | Chunk Optimization | 文書Indexing時のChunk最適化 |
| Multi-representation indexing | 文書を複数種類にIndexing | |
| Specialized Embeddings | 特別なEmbedding方法 | |
| Hierarchical Indexing | 階層的なIndex作成 | |
| Retrieval | Query Translation | クエリを変換 |
| Routing | クエリ内容に応じたRetrieve方法のルーティング | |
| Query Construction | 自然言語をクエリ言語に変換(text2SQL等) | |
| Retrieval | 最終的にLLMに渡すRetrieveした文書内容最適化 | |
| Generation | Generation | モデルをFine-TuneしてRAG内で使用(既存モデルでも可能) |
手法一覧
手法を一覧化しました。
| 手法 | 種別 | 内容 |
|---|---|---|
| Fixed Size Chunking | Indexing - Chunk Optimization | 文書を固定長でチャンク分割 |
| Recursive Chunking | Indexing - Chunk Optimization | 設定サイズを下回るまで再帰的にチャンク分割 |
| Document Based Chunking | Indexing - Chunk Optimization | 文書の構造ごと(MarkdownやPythonプログラムなど)にチャンク分割分割 |
| Semantic Chunking | Indexing - Chunk Optimization | 文単位で分割・Embeddingをして、次の文との類似度が大きく異なる箇所でチャンク分割 |
| Agentic Chunking | Indexing - Chunk Optimization | LLMで文書から命題を作り、命題内容に応じたチャンク作成(Dense Xと同じ) |
| Summary Embedding | Indexing - Multi-representation indexing | LLMが元文書を要約し要約をIndex。 |
| Parent Document | Indexing - Multi-representation indexing | LLMへ渡す文書(Parent)とIndexする文書(Child)に分割 |
| Dense X | Indexing - Multi-representation indexing | LLMが元文書を命題に変換し命題をIndex。 |
| Fine-tuning | Indexing - Specialized Embeddings | クエリと文書をEmbeddingするモデルをFine-Tune |
| ColBERT | Indexing - Specialized Embeddings & Retrieval | クエリと文書をToken単位でEmbeddingし、両者の最大類似度でスコアリング |
| RAPTOR | Indexing - Hierarchical Indexing | 元文書をEmbeddingすると同時にクラスタリング・要約を繰り返して各要約もEmbedding |
| Multi-query | Query Translation | LLMでクエリを言い換えて複数作成し、それぞれのクエリで文書Retrieve後単純結合 |
| RAG-Fusion | Query Translation & Retrieval - Ranking | LLMでクエリを言い換えて複数作成し、それぞれのクエリで文書Retrieve後RRFでランキング・結合 |
| Decomposition | Query Translation | LLMでクエリを分解して、そのクエリに順次回答させて最終回答に導く |
| Step-back | Query Translation | LLMにクエリを抽象化させ、元と抽象化後の2クエリで文書Retrieve後単純結合 |
| HyDE | Query Translation | LLMでクエリの仮回答を作成し、仮回答で文書Retrieve |
| Logical Routing | Routing | LLMにクエリからRetrieve元の種類を判断させる |
| Semantic Routing | Routing & Query Translation | 複数プロンプトを準備し、クエリとの類似度が高いプロンプトを使用 |
| Text-to-SQL | Query Constuction | LLMでクエリをSQLに変換 |
| Text-to-Cypher | Query Constuction | LLMでクエリをCynperに変換 |
| Self-query retriever | Query Constuction | LLMでクエリをEmbeddingとMetadata検索条件作成 |
| Re-Rank | Retrieval - Ranking | 文書Retrieve結果をリランク用モデルでリランク |
| RankLLM | Retrieval - Ranking | 文書Retrieve結果をLLMでリランク |
| CRAG | Retrieval - Refinement & Active Retrieval | Retrieve結果文書をLLMで3種類(関連、曖昧、非関連)に評価し、種類ごとに文書改善 |
| Self-RAG | Generation - Active Retrieval & Routing | 文書Retrieve要否判断を最初にLLM/Fine-Tunedモデルで行い、必要な場合はRetrieveした文書とクエリとの関連度をLLMで評価 |
| RRR(Rewrite-Retrieve-Read) | Generation - Active Retrieval & Query Translation | LLM/Fine-Tunedモデルでクエリ書換 |
| Hybrid Search | Indexing & Query Constuction & Routing & Retrieval | 複数種類のデータソースから文書Retrieve |
| RAFT | Others | クエリと無関係な文書が来ても無視するようにLLMをFine-Tune |
手法詳細
Indexing
全体図での場所です(色塗りの部分)。RAG実行前に文書Index作成手法。

画像出典: rag_from_scratch_12_to_14.ipynb
Chunk Optimization
文書を分割するときの分割手法最適化。

画像出典: RAG from scratch: Overview
Chunk Optimizationは難易度別に5レベルあるそうです。レベル1が最も簡単。
Level1: Fixed Size Chunking
文書の内容、構造にかかわらず、固定長または区切り文字でChunk分割。
| 参考リンク | 備考 |
|---|---|
| LangChain: How to split by character | 文字数と区切り文字でのChunk分割 |
| LangChain: How to split text by tokens | Token単位でChun分割 |
Level2: Recursive Chunking
チャンクサイズの制限を下回るまで再帰的にChunk分割
| 参考リンク | 備考 |
|---|---|
| LangChain: How to recursively split text by characters |
RecursiveCharacterTextSplitterを使用 |
Level3: Document Based Chunking
文書の構造ごと(MarkdownやPythonプログラムなど)にChunk分割
LangChainだと以下のリンクにHTMLやJSなどのSplitterのHow toがあります。
| 参考リンク | 備考 |
|---|---|
| LangChain: Text splitters | How To の一覧 |
Level4: Semantic Chunking
文ごとに分割しEmbeddingをして、次の文との類似度が大きく異なる箇所でChunk分割。
X軸は文のID(文書内の順番)。Y軸(コサイン類似度)が高くなった文でChunk分割しています。

画像出典: 5_Levels_Of_Text_Splitting.ipynb
| 参考リンク | 備考 |
|---|---|
| 5_Levels_Of_Text_Splitting.ipynb | サンプルコード |
Level5: Agentic Chunking
後述の Dense X と同じなので、そちら参照。
Multi-representation indexing
Multi-representation indexingは、文書をRetrieveしやすい単位・形式に変換。Summary Embeddingとして以下の絵。

画像出典: RAG from scratch: Overview
3種類を紹介します。
| 手法 | 概要 | Index対象 | Retrireve対象 |
|---|---|---|---|
| Summary Embedding | LLMが元文書を要約し要約をIndex | 元文書の要約(LLMが要約) | 元文書 |
| Parent Document | LLMへ渡す文書(Parent)とIndexする文書(Child)に分割 | 親文書(大きいチャンク) | 子文書(小さいチャンク) |
| Dense X | LLMが元文書を命題に変換し命題をIndex | 元文書の命題(LLMが作成) | 元文書 |
Summary Embedding
LLMが元文書を要約してその結果をIndex。RAG実行時に、クエリは要約に対して検索し、LLMへは元文書を渡します。
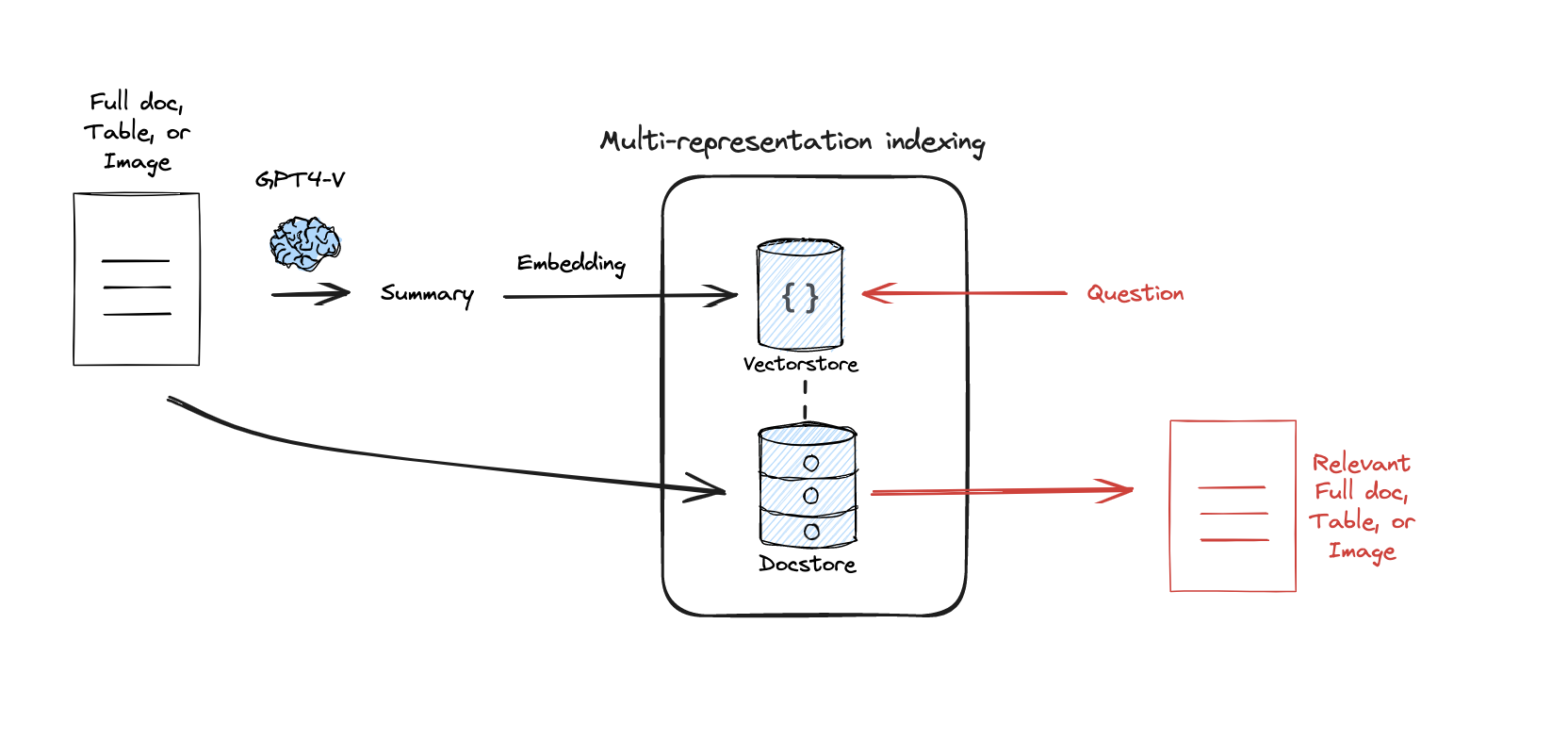
画像出典: rag_from_scratch_12_to_14.ipynb
Parent Document
LLMへ渡す文書(Parent)とIndexする文書(Child)に分割。検索は子供で小さいChunk、LLMへの文書提供は大きいChunk(親)にする。

画像出典: Advanced Retriever Techniques to Improve Your RAGs
| 参考リンク | 備考 |
|---|---|
| LangChain: How to use the Parent Document Retriever |
ParentDocumentRetrieverの実装 |
Dense X Retrieval
LLMが文書を命題に変換して、命題(Proposition)をIndexする。変換時に代名詞を元の名詞に置換。元文書:命題=1:N。
論文に掲載されているAの部分が文書を命題にしているパート。複数の命題に分割しているので、Multi-representation indexing となる。A内のPropositionizerがLLMの役割。

画像出典: Dense X Retrieval: What Retrieval Granularity Should We Use?
Prompt質問に対してPassage、Sentence、Proposition(命題)だと、それぞれどれが関連するかを絵にしています(論文内抜粋)。ベクトルでの類似度検索なので、Proposition(命題)の方が高い検索精度なのがわかります。

画像出典: Dense X Retrieval: What Retrieval Granularity Should We Use?
Chunk内容の例です。
Chunk #0
Chunk ID: fc52f
Summary: This chunk contains information about specific dates and times related to the current month and year.
Propositions:
-The month is October.
-The year is 2023.
Chunk #1
Chunk ID: a4a7e
Summary: This chunk discusses the concept of superlinear returns across different sectors and its implications for understanding economic, social, and personal growth dynamics.
Propositions:
-I did not understand the degree to which the returns for performance are superlinear when I was a child.
-The returns for performance are superlinear.
命題が複数種別(マルチラベル)にならないのか?Chunkが結果的に大きくなることないのか?と思いました。
| 参考リンク | 備考 |
|---|---|
| Dense X Retrieval: What Retrieval Granularity Should We Use? | 論文 |
| Dense X 解説記事 | 基本はここの情報を読み解きました |
| langchain-dense-x-retrieval.ipynb | LangChainの実装 |
| 5_Levels_Of_Text_Splitting.ipynb | サンプルコード |
Specialized Embeddings
Embeddingsを工夫する手法です。

画像出典: RAG from scratch: Overview
Fine-tuning
クエリと文書をEmbeddingするモデルをFine-Tuneします。これは金融業などドメイン特化したい場合や、社内用語が多い場合などで特に有効です。
日本語では以下のモデルがベースモデルの候補にあがるかと思います(2024年7月時点)。以前GluCoSEは仕事で使いましたが、そこそこ良い結果でした。
ColBERT
Indexingの際にDocumentはToken単位でEmbeddingしておく。それに対してQueryもToken単位でEmbeddingして、それぞれの類似度が最も高いものを足してスコアにします。

画像出典: LangChain: Conceptual guide - Retrieval
ColBERTは、Indexing - Specialized Embeddings だけでなく、Retrievalの機能も含んでいます
スコアリングの概要です。Document側でMaxSimを足していった値(∑)がスコアになっているのがわかります。

画像出典: 論文「ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT」
計算量が多くて、遅そうですが、論文内ではそこまで遅くもないと(グラフY軸のスケールは指数になっているので注意)。少なくてもIndexingは時間かかりそう。

画像出典: 論文「ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT」
ragatouilleというPythonパッケージがあって、コーディングそのものは簡単そう。LangChain公式にも以下のサンプルあります。試してないですが、bclavie/JaColBERTという日本語モデルもあるので軽く動かす分には簡単そうです。
| 参考リンク | 備考 |
|---|---|
| RAGatouille | RAGatouilleのLangChainでの使用法 |
| RAG From Scratch: Part 14 (ColBERT) | Youtube 解説動画 |
| rag_from_scratch_12_to_14.ipynb | サンプル実装 |
| ColBERT が開発者による RAG の限界の克服にどのように役立つか | 理解しやすい記事 |
Hierarchical Indexing
階層的なIndexing。RAPTORしか例がないので、解説はそちらで。
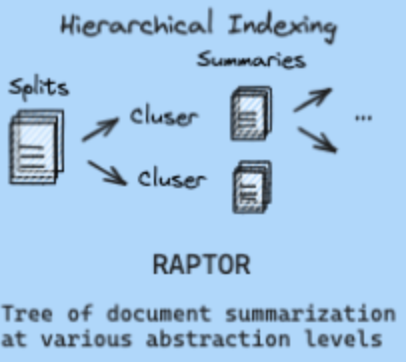
画像出典: RAG from scratch: Overview
RAPTOR
RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)は様々な粒度の文書を使えるようにします。元文書をEmbedding・クラスタリング・要約して親を作っていき、最後に1つになるまで再帰的にIndexingを続けます。

画像出典: LangChainのCookbook RAPTOR.ipynb
| 参考リンク | 備考 |
|---|---|
| RAG From Scratch: Part 13 (RAPTOR) | Youtube 解説動画 |
| RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval | 論文 |
| cookbook/RAPTOR.ipynb | サンプル実装 |
Retrieval
Query Translation
全体図の中の色付き部分がQuery Translation。よりRetrieveしやすい形にクエリを変換します。

画像出典: rag_from_scratch_5_to_9.ipynb
質問「地球温暖化の影響を軽減するための具体的な対策は何ですか?」を例にとった各Query Translation比較です。
| 手法 | 概要 | 書換例 |
|---|---|---|
| Multi-query / RAG-Fusion | LLMでクエリを言い換えて複数作成し、それぞれのクエリで文書Retrieve後単純結合 | 「地球温暖化を防ぐための政府の政策は何ですか?」 「個人ができる地球温暖化対策にはどんなものがありますか?」 「企業が取り組むべき地球温暖化対策とは?」 |
| Decomposition | LLMでクエリを分解して、そのクエリに順次回答させて最終回答に導く | 「地球温暖化の主な原因は何ですか?」 「これらの原因を減らすために政府が取れる対策は何ですか?」 「これらの原因を減らすために個人ができる行動は何ですか?」 |
| Step-back | LLMにクエリを抽象化させ、元と抽象化後の2クエリで文書Retrieve後単純結合 | 「地球温暖化とは何ですか?」 |
| HyDE | LLMでクエリの仮回答を作成し、仮回答で文書Retrieve | 「地球温暖化を軽減するための対策としては、再生可能エネルギーの導入、植林活動、エネルギー効率の改善などが含まれます。」 |
Multi-query
LLMでクエリを言い換えて複数作成し、それぞれのクエリで文書Retrieve後単純結合。


画像出典: RAG from scratch: Query Translation (Multi-Query)
サンプルプログラムrag_from_scratch_5_to_9.ipynbでのプロンプト。
| 用途 | プロンプト |
|---|---|
| Multi-query | You are an AI language model assistant. Your task is to generate five different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of the distance-based similarity search. Provide these alternative questions separated by newlines. Original question: {question} |
| 最終回答取得 | Answer the following question based on this context: {context} Question: {question} |
| 参考リンク | 備考 |
|---|---|
| RAG from scratch: Part 5 (Query Translation -- Multi Query) | Youtube 解説動画 |
| rag_from_scratch_5_to_9.ipynb | サンプル実装 |
| RAG from scratch: Query Translation (Multi-Query) | Slide |
RAG-Fusion
LLMでクエリを言い換えて複数作成するまでは、Multi-Queryと同じ。文書取得結果をランキングする部分のみが異なります。

画像出典: 論文「RAG-Fusion: a New Take on Retrieval-Augmented Generation」
RAG-FusionはQuery Translationだけでなく、Retrieval - Ranking の機能
も含んでいます。
RRF(Reciprocal Rank Fusion)で文書のランキングを実施。文書dのスコアRRF(d)は、文書dの順位$rank_i(d)$とハイパーパラメータkを用いて、以下の式で計算します。kが大きいほど、高順位と低順位の差が小さくなり、複数クエリに対して複数回ランクインすることが重要視されます(複数回ランクインされるのでシグマで総和)。
RRF(d) = \sum_i \frac{1}{k+rank_i(d)}
Pythonでは rag_from_scratch_5_to_9.ipynb で、以下の計算。
def reciprocal_rank_fusion(results: list[list], k=60):
""" Reciprocal_rank_fusion that takes multiple lists of ranked documents
and an optional parameter k used in the RRF formula """
# Initialize a dictionary to hold fused scores for each unique document
fused_scores = {}
# Iterate through each list of ranked documents
for docs in results:
# Iterate through each document in the list, with its rank (position in the list)
for rank, doc in enumerate(docs):
# Convert the document to a string format to use as a key (assumes documents can be serialized to JSON)
doc_str = dumps(doc)
# If the document is not yet in the fused_scores dictionary, add it with an initial score of 0
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# Retrieve the current score of the document, if any
previous_score = fused_scores[doc_str]
# Update the score of the document using the RRF formula: 1 / (rank + k)
fused_scores[doc_str] += 1 / (rank + k)
# Sort the documents based on their fused scores in descending order to get the final reranked results
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
# Return the reranked results as a list of tuples, each containing the document and its fused score
return reranked_results
| 参考リンク | 備考 |
|---|---|
| RAG from scratch: Part 6 (Query Translation -- RAG Fusion) | Youtube 解説動画 |
| rag_from_scratch_5_to_9.ipynb | サンプル実装 |
| 実行ログ | LangSmith |
Decomposition
LLMでクエリを分解して、そのクエリに順次回答させて最終回答に導く。

画像出典: rag_from_scratch_5_to_9.ipynb
具体例の絵。CoT(Chain of Thought)ですね。

画像出典: 論文「Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions」
Step-back
LLMにクエリを抽象化させ、元と抽象化後の2クエリで文書Retrieve後単純結合。その両者を使ってLLMにクエリを投げます。
LLMにクエリを投げて最終回答を得る例。

画像出典: 論文「Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models」
HyDE
HyDE(Hypothetical Document Embeddings)はLLMでクエリの仮回答を作成し、仮回答で文書Retrieveします。クエリと文書より、(仮想的な)回答と文書の方が似ている、という概念です。

画像出典: rag_from_scratch_5_to_9.ipynb
LangChainのHyDEの使い方が詳しい解説記事です。
拡張したAutoHyDEに関する言及があります。クエリでキーワード検索をして得られた結果文書をクラスタリングして各クラスタごとの文書のEmbeddingを使って検索をします(短時間で確認したので、理解に少し自信なし)。
Routing
クエリ内容に応じた文書Retrieve方法のルーティング。
全体図の中の位置づけ(色つきの部分)。

画像出典: RAG from scratch: Routing
| 参考リンク | 備考 |
|---|---|
| RAG from scratch: Part 10 (Routing) | Youtube 解説動画 |
| rag_from_scratch_10_and_11.ipynb | サンプルコード |
| RAG from scratch: Routing | Slide |
Logical Routing
LLMにクエリからRetrieve元の種類を判断させます。

画像出典: RAG from scratch: Routing
以下、サンプルコードではPydantic使って判断しています。
# Data model
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasource: Literal["python_docs", "js_docs", "golang_docs"] = Field(
...,
description="Given a user question choose which datasource would be most relevant for answering their question",
)
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm = llm.with_structured_output(RouteQuery)
# Prompt
system = """You are an expert at routing a user question to the appropriate data source.
Based on the programming language the question is referring to, route it to the relevant data source."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
# Define router
router = prompt | structured_llm
Semantic Routing
複数プロンプトを準備し、クエリとの類似度が高いプロンプトを使用。

画像出典: RAG from scratch: Routing
具体例がないとわかりにくかったので、サンプルコードrag_from_scratch_10_and_11.ipynbにあった2種類のプロンプトを以下に書きました。物理と数学に関するプロンプト。
| Prompt |
|---|
| You are a very smart physics professor. You are great at answering questions about physics in a concise and easy to understand manner. When you don't know the answer to a question you admit that you don't know. Here is a question: {query} |
| You are a very good mathematician. You are great at answering math questions. You are so good because you are able to break down hard problems into their component parts, answer the component parts, and then put them together to answer the broader question. Here is a question:{query} |
| 参考リンク | 備考 |
|---|---|
| ログ | LangSmith |
Query Construction
Query Constructionは、自然言語のクエリをクエリ言語に変換(text2SQL等)します。

画像出典: rag_from_scratch_10_and_11.ipynb
そもそも構造化、半構造化、非構造化データごとにデータストアが異なり、それに対するRetrieveのためのクエリ化が必要です。
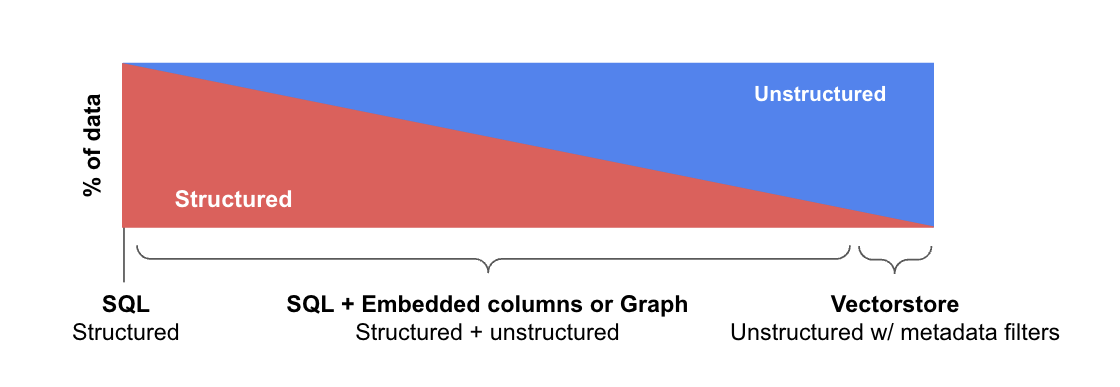
画像出典: LangChain: Query Construction
それぞれのデータストアごとの処理概要です。

画像出典: LangChain: Query Construction
Text-to-SQL(Relational DBs)
クエリをLLMでSQLに変換します。
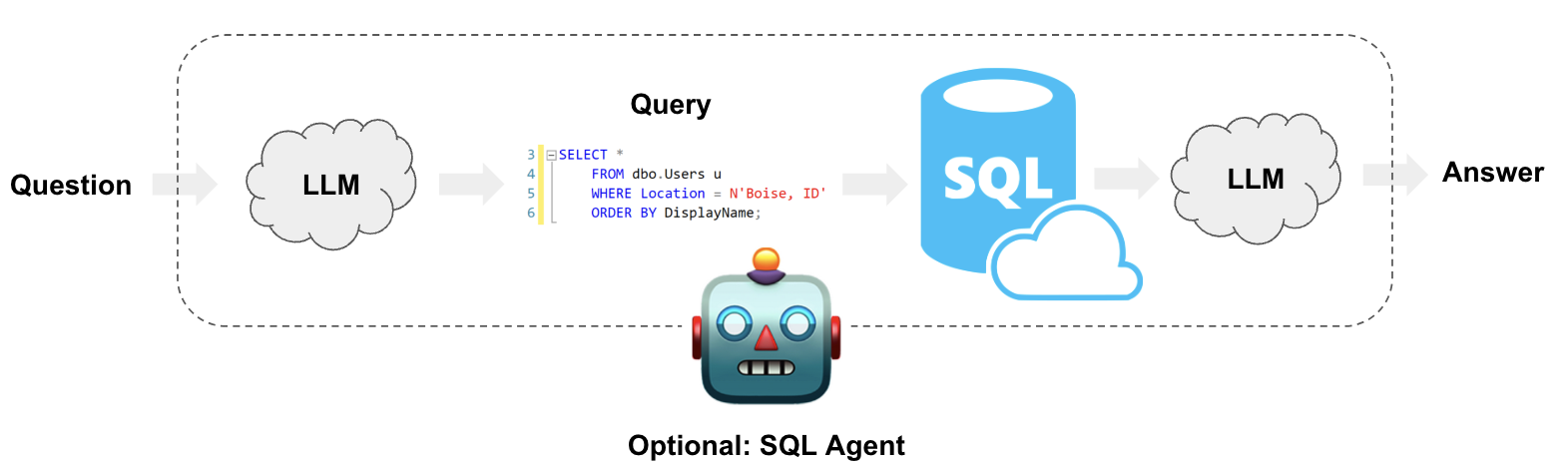
画像出典: LangChain: Query Construction
LangChainではSQL変換にcreate_sql_query_chainを使い、SQL実行にQuerySQLDataBaseToolを使います。
こんなChainを作ります。
execute_query = QuerySQLDataBaseTool(db=db)
write_query = create_sql_query_chain(llm, db)
chain = write_query | execute_query
LangChainにSQLDatabaseToolkitというToolkitもあって、テーブルIDを探す処理などもやってくれたりします。詳しくはこちら参照。
| 参考リンク | 備考 |
|---|---|
| LangChain: Query Construction | ブログ記事 |
| LangChain: Build a Question/Answering system over SQL data | チュートリアル |
Text-to-Cypher(GraphDBs)
クエリをCypherに変換してGraphDBからRetrieveします。

画像出典: LangChain: Build a Question Answering application over a Graph Database
LangChainのGraphCypherQAChainを使うことで比較的簡単にQAタスクのChainを作れます。
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
chain = GraphCypherQAChain.from_llm(graph=graph, llm=llm, verbose=True)
response = chain.invoke({"query": "What was the cast of the Casino?"})
| 参考リンク | 備考 |
|---|---|
| LangChain: Build a Question Answering application over a Graph Database | チュートリアル |
| How to best prompt for Graph-RAG | How to(Few-Shot Promptingあり) |
| LangChain: Query Construction | ブログ記事 |
| Knowledge Graphを使った RAG をLangChainで実装[前編] | 別アプローチだが細かい解説あり |
Self-query retriever(VectorDBs)
LLMでクエリをVectorStoreの検索条件(Metadataの比較演算含む)に変換します。

画像出典: LangChain: How to do "self-querying" retrieval
LangChainにはSelfQueryRetrieverという便利な機能があって、クエリのSQLへの変換からRetrieveまで一気にやってくれます。
詳細は以下参照で、LCELに組み込んで使う方法も記載があります。
| 参考リンク | 備考 |
|---|---|
| RAG from scratch: Part 11 (Query Structuring) | Youtube 解説動画 |
| rag_from_scratch_10_and_11.ipynb | サンプルコード |
| LangChain: Query Construction | ブログ記事 |
| How to do "self-querying" retrieval | LangChain: How to |
Retrieval
最終的にLLMに渡すRetrieveした文書内容最適化。
全体図の中の位置づけ(色つきの部分)。

画像出典: rag_from_scratch_15_to_18.ipynb
Ranking
文書Retrieve結果一覧のランキング方法を工夫します。

画像出典: rag_from_scratch_15_to_18.ipynb
RRF(Reciprocal Rank Fusion)でランキングするRAG-Fusionは前述。
Re-Rank
文書Retrieve結果をリランク用モデルでリランク
文書Retrieve結果を(類似度と別に)リランク用のモデルを使ってもう一度スコアリング・リランクします。

画像出典: rag_from_scratch_15_to_18.ipynb
検索した文書を個々にEncoderでスコアリングします(このInputは文書だけでなくクエリもくっつける)。

画像出典: Pine Cone: Rerankers and Two-Stage Retrieval
LangChainでは、以下のページにやり方があり、コード自体は大した手間じゃないです(Encoderの日本語モデルを確認、必要に応じてFine-Tuningするのが大変なはず)。
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CrossEncoderReranker
from langchain_community.cross_encoders import HuggingFaceCrossEncoder
model = HuggingFaceCrossEncoder(model_name="BAAI/bge-reranker-base")
compressor = CrossEncoderReranker(model=model, top_n=3)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke("What is the plan for the economy?")
pretty_print_docs(compressed_docs)
| 参考リンク | 備考 |
|---|---|
| 日本語最高性能のRerankerをリリース / そもそも Reranker とは? | 参考記事 |
| rag_from_scratch_15_to_18.ipynb | サンプルコード |
RankLLM
仕組みは先程のRe-Rankと同じ。スコアリング・リランクにLLMを使います。このとき使うLLMがGPTだとRankGPTと呼ぶようです。
LangChainではRankLLMRerankでモデル定義をして、ContextualCompressionRetrieverのRetrieverを使います。こちらにLangChainでの呼び出し方が書いてあります。
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
from langchain_community.document_compressors.rankllm_rerank import RankLLMRerank
compressor = RankLLMRerank(top_n=3, model="zephyr")
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
Refinement & Active Retrieval
CRAG
CRAG(Corrective Retrieval Augmented Generation)は、Retrieve結果文書をLLMで3種類(関連、曖昧、非関連)に評価し、種類ごとに文書改善。
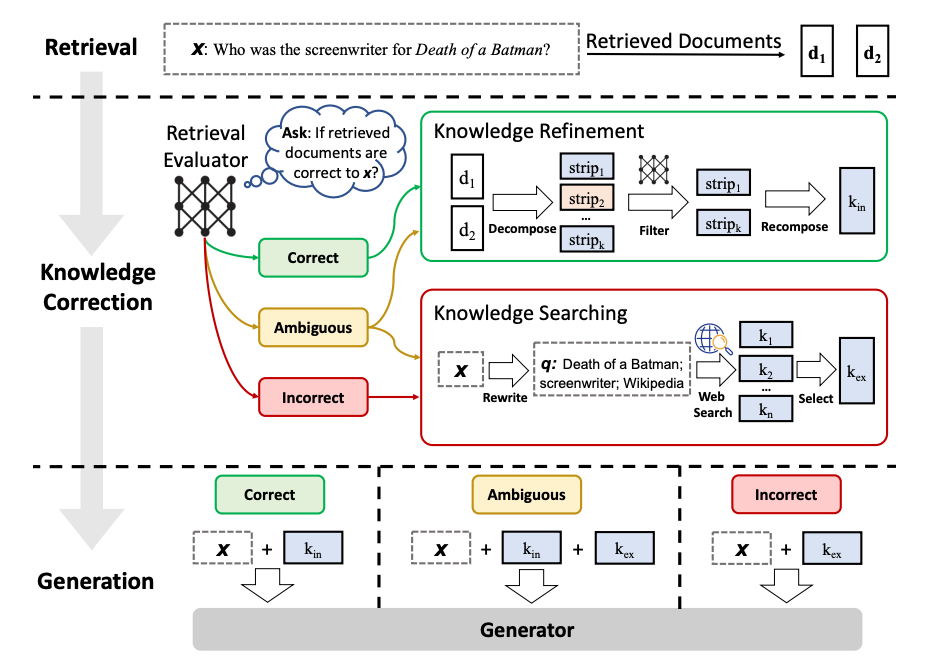
画像出典: Corrective Retrieval Augmented Generation
LangGraphでの簡易的な実装(Knowledge Refinementや Ambiguousの判断などいろいろ省略)。LangSmithへのリンクがあって、長いChainになっているのがわかります(LangGraphを使ったことないので判断できないですが、LangGraphを使うとLangSmithでのログが長くなる?)。
| 参考リンク | 備考 |
|---|---|
| RAGを超えたCRAGを実装する。 | 参考記事 |
| Corrective Retrieval Augmented Generation | 論文 |
| examples/rag/langgraph_crag.ipynb | サンプルコード |
| ログ1 | LangSmith |
| ログ2 | LangSmith |
Generation
Generationは全体図で右下にあり、AnswerからVectorStoreに矢印があり、Generate結果をFine-Tuningをしています。
画像出典: RAG from scratch: Overview
Self-RAG
文書Retrieve要否判断を最初にLLM/Fine-Tunedモデルで行い、必要な場合はRetrieveした文書とクエリとの関連度をLLMで評価します。

画像出典: LangChain: Conceptual guide - Generation
Naive RAGを使うと必ず文書Retrieveするので、「こんにちは」のようなプロンプトにはRetrieveは無駄なばかりか、精度低下の原因となります。そのため、Self-RAG では、Retrieve要否をLLMで最初に判断します。Retrieveが必要な場合には、複数件を取得し、それぞれをLLMで比較評価して良いスコアの結果を出力します。

画像出典: Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
RRR(Rewrite-Retrieve-Read)
LLM/Fine-Tunedモデルでクエリ書換。どちらかというとQuery Transformationnカテゴリ。
論文内に記載のあるフロー。真ん中はGPTなどをそのまま使った場合。右は強化学習でSmall PrLM(Pre-Trained Language Model)をFine-Tuneした場合。

画像出典: Query Rewriting for Retrieval-Augmented Large Language Models
| 参考リンク | 備考 |
|---|---|
| LLMを用いたクエリ書き換えによる検索性能の変化を検証する | 解説記事 |
| rewrite_retrieve_read | LangChain Template |
| rewrite.ipynb | サンプル実装 |
| Query Rewriting for Retrieval-Augmented Large Language Models](https://arxiv.org/abs/2305.14283) | 論文 |
その他
Hybrid Search
Routingにカテゴライズするのが正しいでしょうか。「その他」にしています。非常に有名なので、簡潔に。
Vector Storeに対して類似度検索と別にキーワード検索も同時に実施します。お互いの短所を打ち消し合うのが目的。Vector Storeに限らず、Graph DBでもHybrid Searchと呼ぶのだと思います。
Vector Storeに実装は方法依存しますが、Pineconeだと以下の実装。
RAFT
RAFT(Retrieval Augmented FineTuning)は特定ドメインに向けてLLMをFine-Tuningします。特徴的なのは、関係ない文書をRAGとして含んでいても無視するように訓練している点です。

画像出典: RAFT: Adapting Language Model to Domain Specific RAG
こんなデータセットでFine-Tune。
- クエリ
- 2文書: 回答に関係する文書と無関係の文書
- 回答
- Chain-of-thought 説明
以下が論文。
| 参考リンク | 備考 |
|---|---|
| RAFT: Adapting Language Model to Domain Specific RAG | 論文 |
| 【論文瞬読】大規模言語モデルを特定ドメインに適応させる新手法RAFT | 解説記事 |
参考リンク