Neo4jで Knowledge Graph を使ったRAGを試してみました。LangChainブログの以下の記事を理解し、途中のNeo4jの状態などを併せて見ていきます。
理解にあたり、以下の記事を参考にしています。
後編はWikipediaの記事を読み込んで試した結果の感想です。
また、事前に前提として以下の記事を書いています(Neo4j使っている人は見なくてOK)。
別方法としてGraphCypherQAChainを使うこともできます。PromptからCypherをLLMで作ります。
詳しくは、以下の記事を参照ください。
環境
Python3.12.2 で以下のライブラリを使っています。色々使っている仮想環境なので漏れがあるかも。
Knowledge Graph としてNeo4j/5.21-auraを使っています。
| Package | Version | 備考 |
|---|---|---|
| langchain | 0.2.7 | |
| langchain-experimental | 0.0.62 | |
| langchain-openai | 0.1.14 | |
| neo4j | 5.22.0 | |
| pandas | 2.2.2 | 表の表示に使っただけ |
| python-dotenv | 1.0.1 | 暗黙的に使用 |
処理
プログラムを以下の2種類に分けています
- Neo4jへのデータ格納
- RAGでのLLM実行
共通
ファイル.envをpython-dotenvパッケージを使って暗黙的に読み込んでいます。
OPENAI_API_KEY=<key>
OPENAI_API_TEMPERATURE=0.5
LANGCHAIN_TRACING_V2=true
LANGCHAIN_API_KEY=<key>
NEO4J_URI=<url>
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<password>
1. Neo4jへのデータ格納
1.1. パッケージインポート
必要なパッケージをインポート
import os
import pprint
from tempfile import NamedTemporaryFile
from langchain_community.document_loaders import TextLoader
from langchain_community.graphs import Neo4jGraph
from langchain_community.vectorstores import Neo4jVector
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from neo4j import GraphDatabase
import pandas as pd
1.2. Neo4j初期処理
Neo4j初期処理として接続と、データ削除しています。
接続情報は裏で環境変数から読み込んでくれるようです。
graph = Neo4jGraph()
graph.query("MATCH (n) DETACH DELETE n;")
1.3. データ読込
Temporaryのテキストファイルを作ってTextLoaderから読み込んでいます。もっとシンプルにできる方法もあるかもしれないですが、あまり調べていません。
私が以前見ていた花田少年史のwikiからテキスト抜粋しました。
text = """
近所でも有名な腕白小僧、花田一路は悪戯を叱る母親から逃げようと道路に飛び出し、車にはねられてしまう。
"""
with NamedTemporaryFile(delete=True) as t:
with open(t.name, 'w+') as f:
f.write(text)
loader = TextLoader(t.name)
documents = loader.load()
1.4. Graph作成
テキストをLLMでGraph化してNeo4jにデータ挿入しています。ここは高度なAPIになっていて何やっているかよくわからないですね。
llm=ChatOpenAI(temperature=0, model_name="gpt-4o")
llm_transformer = LLMGraphTransformer(llm=llm)
# ここでLLMでgraph化
graph_documents = llm_transformer.convert_to_graph_documents(documents)
graph.add_graph_documents(
graph_documents,
baseEntityLabel=True,
include_source=True
)
pprint.pprint(graph.query("MATCH (s)-[r:!MENTIONS]->(t) RETURN s,r,t LIMIT 50"))
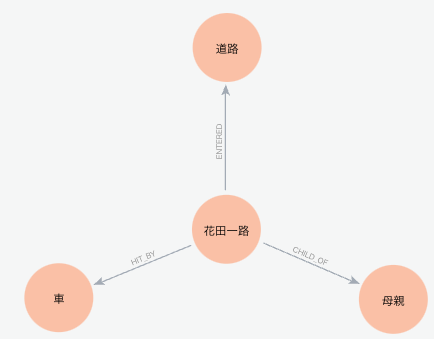
Cypher結果。EntityとRelationshipの登録状況がわかります。
[{'r': ({'id': '花田一路'}, 'HIT_BY', {'id': '車'}),
's': {'id': '花田一路'},
't': {'id': '車'}},
{'r': ({'id': '花田一路'}, 'RAN_INTO', {'id': '道路'}),
's': {'id': '花田一路'},
't': {'id': '道路'}},
{'r': ({'id': '花田一路'}, 'CHILD_OF', {'id': '母親'}),
's': {'id': '花田一路'},
't': {'id': '母親'}}]
Grpaph全体
Neo4j Aura Console でCypher実行しています。
MATCH p=()-[]-() RETURN p
Document が登録され、そこに全文が入り、各 Entityに対して MeintionsのRelationshipが作られています。

Graph Document以外
Cypherで Document以外を見ていきます。
MATCH (s)-[r:!MENTIONS]->(t) RETURN s,r,t

convert_to_graph_documents の処理
LangSmith で関数convert_to_graph_documentsの処理を見ます。

ChatOpenAI
ChatOpenAIの処理だけクローズアップします。
Function & Tools
Function & ToolsとしてDynamicGraphが使われていて、その内容がnodesとrelationshipsで2種類。
description: List of nodes
type: array
items:
type: object
properties:
id:
description: Name or human-readable unique identifier.
type: string
type:
description: |-
The type or label of the node.Ensure you use basic or elementary types for node labels.
For example, when you identify an entity representing a person, always label it as **'Person'**. Avoid using more specific terms like 'Mathematician' or 'Scientist'
type: string
required:
- id
- type
description: List of relationships
type: array
items:
type: object
properties:
source_node_id:
description: Name or human-readable unique identifier of source node
type: string
source_node_type:
description: |-
The type or label of the source node.Ensure you use basic or elementary types for node labels.
For example, when you identify an entity representing a person, always label it as **'Person'**. Avoid using more specific terms like 'Mathematician' or 'Scientist'
type: string
target_node_id:
description: Name or human-readable unique identifier of target node
type: string
target_node_type:
description: |-
The type or label of the target node.Ensure you use basic or elementary types for node labels.
For example, when you identify an entity representing a person, always label it as **'Person'**. Avoid using more specific terms like 'Mathematician' or 'Scientist'
type: string
type:
description: The type of the relationship.Instead of using specific and momentary types such as 'BECAME_PROFESSOR', use more general and timeless relationship types like 'PROFESSOR'. However, do not sacrifice any accuracy for generality
type: string
required:
- source_node_id
- source_node_type
- target_node_id
- target_node_type
- type
Input - system
Inputの systemの内容。マークダウンで書かれていた。
Knowledge Graph Instructions for GPT-4
1. Overview
You are a top-tier algorithm designed for extracting information in structured formats to build a knowledge graph.
Try to capture as much information from the text as possible without sacrificing accuracy. Do not add any information that is not explicitly mentioned in the text.
- Nodes represent entities and concepts.
- The aim is to achieve simplicity and clarity in the knowledge graph, making it
accessible for a vast audience.2. Labeling Nodes
- Consistency: Ensure you use available types for node labels.
Ensure you use basic or elementary types for node labels.- For example, when you identify an entity representing a person, always label it as 'person'. Avoid using more specific terms like 'mathematician' or 'scientist'.- Node IDs: Never utilize integers as node IDs. Node IDs should be names or human-readable identifiers found in the text.
- Relationships represent connections between entities or concepts.
Ensure consistency and generality in relationship types when constructing knowledge graphs. Instead of using specific and momentary types such as 'BECAME_PROFESSOR', use more general and timeless relationship types like 'PROFESSOR'. Make sure to use general and timeless relationship types!3. Coreference Resolution
- Maintain Entity Consistency: When extracting entities, it's vital to ensure consistency.
If an entity, such as "John Doe", is mentioned multiple times in the text but is referred to by different names or pronouns (e.g., "Joe", "he"),always use the most complete identifier for that entity throughout the knowledge graph. In this example, use "John Doe" as the entity ID.
Remember, the knowledge graph should be coherent and easily understandable, so maintaining consistency in entity references is crucial.4. Strict Compliance
Adhere to the rules strictly. Non-compliance will result in termination.
Input - Human
InputのHumanの内容
Tip: Make sure to answer in the correct format and do not include any explanations. Use the given format to extract information from the following input:
近所でも有名な腕白小僧、花田一路は悪戯を叱る母親から逃げようと道路に飛び出し、車にはねられてしまう。
Output
OpenAIのOutput。
nodes:
- id: 花田一路
type: person
- id: 母親
type: person
- id: 道路
type: place
- id: 車
type: object
relationships:
- source_node_id: 花田一路
source_node_type: person
target_node_id: 母親
target_node_type: person
type: child_of
- source_node_id: 花田一路
source_node_type: person
target_node_id: 道路
target_node_type: place
type: entered
- source_node_id: 花田一路
source_node_type: person
target_node_id: 車
target_node_type: object
type: hit_by
1.5. Vector Store インデックス作成
Graphの内容からVector Store(同じNeo4j)のインデックスを作成します。
ここのsearch_type="hybrid"はVectorでの類似度検索と全文検索両者を意味します(GraphDBとVectorなのかと最初思いました)。
詳細のCypherはリンク先参照
vector_index = Neo4jVector.from_existing_graph(
OpenAIEmbeddings(model='text-embedding-3-small'),
search_type="hybrid",
node_label="Document",
text_node_properties=["text"],
embedding_node_property="embedding"
)
# 確認クエリ
docs_with_score = vector_index.similarity_search_with_score("花田", k=3)
print(docs_with_score)
確認クエリの結果。
[(Document(metadata={
'source': '/var/folders/x1/1vhvsm7j0l59n4mnz_6280tm0000gn/T/tmpvey4s3le'},
page_content='\ntext: \n
近所でも有名な腕白小僧、花田一路は悪戯を叱る母親から逃げようと道路に飛び出し、車にはねられてしまう。\n'),
1.0)]
ConsoleからCypher実行。
MATCH (d:Document) RETURN d
Documentにembeddingが追加されているを確認。

vector indexが追加されている。
display(pd.DataFrame(graph.query('show vector indexes')))

1.6. Full Text Index作成
# Full Text Index作成
graph.query(
"CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:__Entity__) ON EACH [e.id]")
display(pd.DataFrame(graph.query("SHOW FULLTEXT INDEXES")))
Index

他のVector Store作り方
ここには詳細書きませんが、
関数from_existing_relationship_indexを使ったリレーションシップからVectorStoreを作る方法があります。詳細は、リンク先記事「3. グラフのリレーションシップ情報からベクトル検索を実行」が詳しいです。
また、関数from_documentsを使った(GraphDB情報ではなく)DocumentからVectorStoreを作る方法もあります。詳細は、リンク先記事「4. テキストからハイブリッド検索(全文検索とベクトル検索)を実行」が詳しいです。
2. RAGでのLLM実行
2.1. パッケージインポート
必要なパッケージをインポート
import os
from typing import List
from langchain_community.graphs import Neo4jGraph
from langchain_community.vectorstores import Neo4jVector
from langchain_community.vectorstores.neo4j_vector import remove_lucene_chars
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
2.2. Neo4j接続
Neo4jのGraphおよびVector Indexに接続。
graph = Neo4jGraph()
vector_index = Neo4jVector.from_existing_index(
OpenAIEmbeddings(model='text-embedding-3-small'),
url=os.environ["NEO4J_URI"],
username=os.environ["NEO4J_USERNAME"],
password=os.environ["NEO4J_PASSWORD"],
index_name="vector",
)
2.3. Entity Extraction
Entity ExtractionのChainを作ります。ここで取得したEntityでクエリを生成します。
class Entities(BaseModel):
"""Identifying information about entities."""
names: List[str] = Field(
...,
description="All the person, organization, or business entities that "
"appear in the text",
)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are extracting organization and person entities from the text.",
),
(
"human",
"Use the given format to extract information from the following "
"input: {question}",
),
]
)
# Entity ExtractionのChain
llm_ner=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
entity_chain = prompt | llm_ner.with_structured_output(Entities)
entity_chain.invoke({"question": "花田一路はどんな人間?"}).names
['花田一路']
2.4. Retriever
GraphとVector StoreからのRetrieverです。
2.4.1. Structured Retriever
GraphからのRetrieverです。
def generate_full_text_query(input: str) -> str:
"""
Generate a full-text search query for a given input string.
This function constructs a query string suitable for a full-text search.
It processes the input string by splitting it into words and appending a
similarity threshold (~2 changed characters) to each word, then combines
them using the AND operator. Useful for mapping entities from user questions
to database values, and allows for some misspelings.
"""
full_text_query = ""
# remove_lucene_chars は特殊文字(|など)を削除
# スペース分割なので日本語では機能しない
# 最後のifは文字があればTrueになるので、意味がよくわからない(splitでスペース分割後にブランクがelに来るパターンが?)
words = [el for el in remove_lucene_chars(input).split() if el]
# ANDを末尾につけるのは最後以外
for word in words[:-1]:
full_text_query += f" {word}~2 AND"
full_text_query += f" {words[-1]}~2"
return full_text_query.strip()
# Fulltext index query
def structured_retriever(question: str) -> str:
"""
Collects the neighborhood of entities mentioned
in the question
"""
result = ""
# Entity Extraction
entities = entity_chain.invoke({"question": question})
for entity in entities.names:
# 方向が逆のものをUNIONしている
response = graph.query(
"""CALL db.index.fulltext.queryNodes('entity', $query, {limit:2})
YIELD node,score
CALL {
WITH node
MATCH (node)-[r:!MENTIONS]->(neighbor)
RETURN node.id + ' - ' + type(r) + ' -> ' + neighbor.id AS output
UNION ALL
WITH node
MATCH (node)<-[r:!MENTIONS]-(neighbor)
RETURN neighbor.id + ' - ' + type(r) + ' -> ' + node.id AS output
}
RETURN output LIMIT 50
""",
{"query": generate_full_text_query(entity)},
)
result += "\n".join([el['output'] for el in response])
return result
generate_full_text_query("Donald Trump")
スペースで区切ってANDで繋がります。(よく調べておらず間違っているかもしれませんが)"~2"はFuzzy Searchで使う文法のようです。以下を参照。
'Donald~2 AND Trump~2'
print(structured_retriever("花田はどんな人間?"))
花田一路 - CHILD_OF -> 母親
花田一路 - HIT_BY -> 車
花田一路 - RAN_INTO -> 道路
花田一路 - CHILD_OF -> 母親
2.4.2. Retriever
Structured Retriever と Vector StoreからのRetrieval結果を結合しています。
def retriever(question: str):
print(f"Search query: {question}")
structured_data = structured_retriever(question)
vector_index.similarity_search(question)
unstructured_data = [el.page_content for el in vector_index.similarity_search(question)]
final_data = f"""Structured data:
{structured_data}
Unstructured data:
{"#Document ". join(unstructured_data)}
"""
return final_data
print(retriever("花田はどんな人間?"))
Search query: 花田はどんな人間?
Structured data:
花田一路 - CHILD_OF -> 母親
花田一路 - HIT_BY -> 車
花田一路 - RAN_INTO -> 道路
花田一路 - CHILD_OF -> 母親
Unstructured data:
近所でも有名な腕白小僧、花田一路は悪戯を叱る母親から逃げようと道路に飛び出し、車にはねられてしまう。
2.5. Chain 実行
すべてをChainでつなげて実行。
template = """Answer the question based only on the following context:
{context}
Question: {question}
Use natural language and be concise.
Answer:"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
RunnableParallel(
{
"context": retriever,
"question": RunnablePassthrough(),
}
)
| prompt
| ChatOpenAI(temperature=0, model_name="gpt-4o")
| StrOutputParser()
)
chain.invoke("花田はどんな人間?")
花田一路は近所でも有名な腕白小僧です。