はじめに
RAG-1グランプリ。新しい形のデータ分析コンペですが、とても楽しく、そしてDataikuを使えば比較的簡単にできるので、それをみなさんにお伝えしたく記事を書きました。
この記事では、SIGNATEのRAG-1グランプリに付録されている例題を使って、Dataiku(無料版)でRAGモデルを構築する手順について解説します。
(※注意)Dataikuは無料で使えますが、LLMはご自身がご契約されるものを使いますのでご注意ください。
目次
-
事前準備①
1-1. Dataiku無料版のインストール
1-2. Python環境をインストール
1-3. データのダウンロード -
事前準備②(Dataiku起動後に行うこと)
2-1. Python Envの設定
2-2. LLM(例:ChatGPT)のAPIキーの取得および設定
2-3. Plugin(Text extraction and OCR)の設定
1. 事前準備①
1-1. Dataiku無料版のインストール
Dataiku無料版から無料版をダウンロードしてインストールします。

※Windows版のみ動作保証していないのでご注意ください
初期ログイン情報は下記の通り
- user:admin
- pass:admin
インストールできたらUIの言語を日本語にしておきましょう。
1-2. Python環境をインストール
Python 3.xと必要なパッケージをインストールします。
私はこの手順でインストールしました。
Homebrewでpython3系の最新をインストールする方法
1-3. データのダウンロード
こちらの記事で使ったデータはこちらからDLいただけます。
2. 事前準備②(Dataiku起動後に行うこと)
右上のナインドッツから『アドミニストレーション』をクリックする。
2-1. Python Envの設定
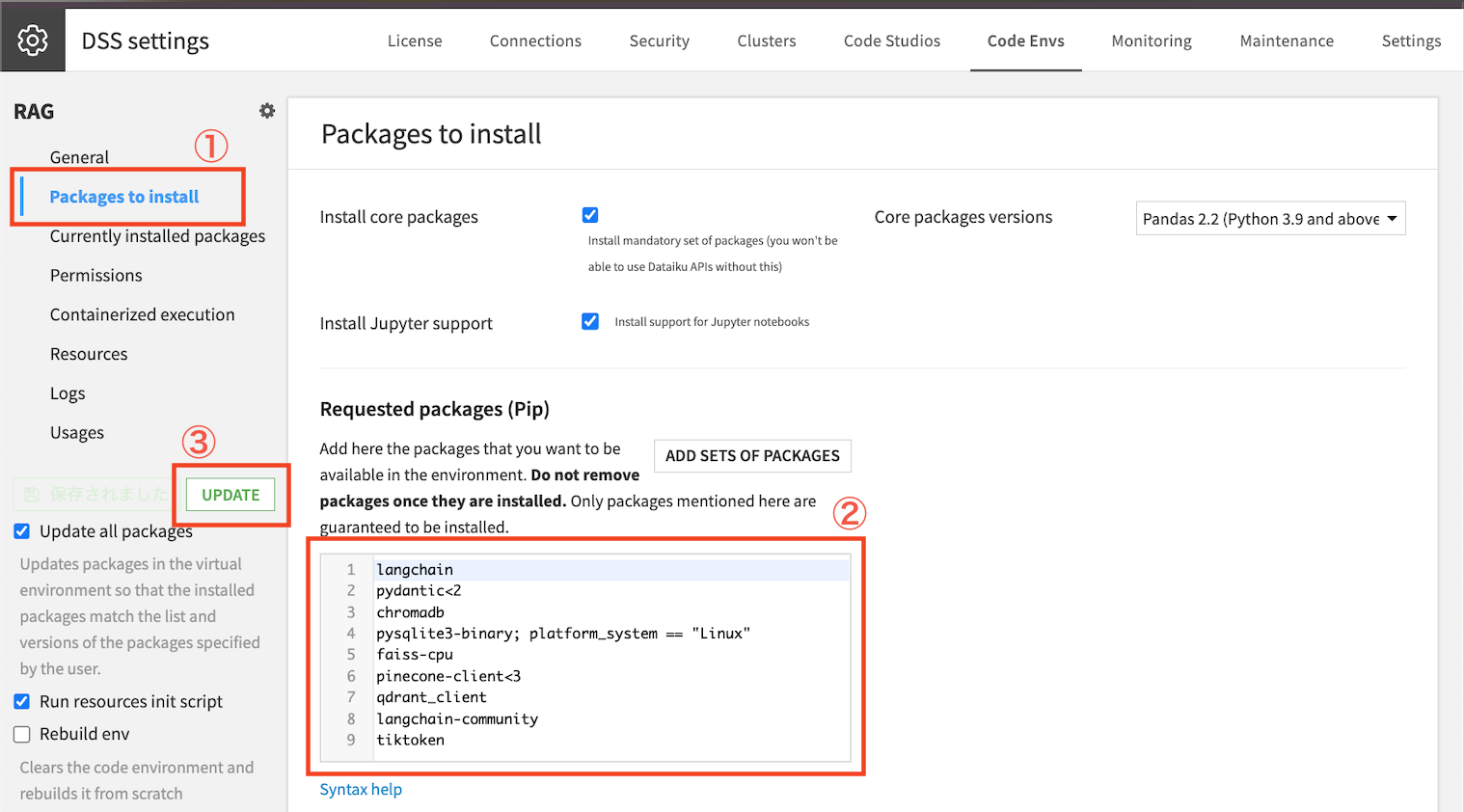
Dataikuを起動し、「設定」→「コード環境」→「新しい環境の作成」を選択し、Python環境を設定します。
右上『NEW PYTHON ENV』をクリック
①左の『Packages install』をクリック
②Requested packages(Pip)に下記の入力
langchain
pydantic<2
chromadb
pysqlite3-binary; platform_system == "Linux"
faiss-cpu
pinecone-client<3
qdrant_client
langchain-community
tiktoken
③左側の『UPDATE』をクリック
2-2. LLM(例:ChatGPT)のAPIキーの取得および設定
ご自身で契約しているLLMからAPIキーを取得し、Dataiku内で設定します。
APIキーの取得方法はこちらをご参照ください。
APIキーを取得できたら、『ナインドッツ』→『アドミニストレーション』→『Connections』→『NEW CONNECTION』から任意のLLMを選択し、APIキーを入力。
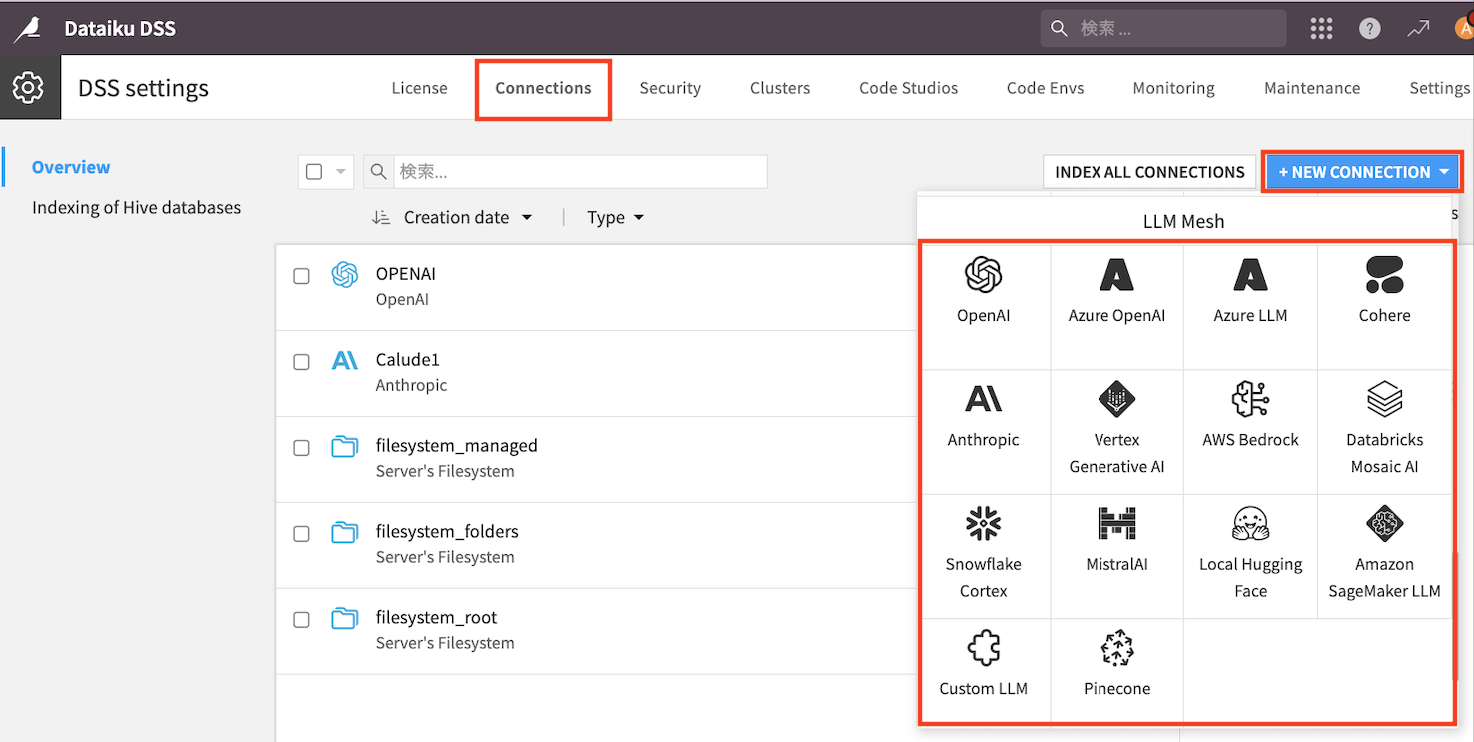
APIキーを入力→これから使いたいモデルを選択→『SAVE』をクリック
2-3. Plugin(Text extraction and OCR)の設定
プラグインから文字起こしの機能を追加しておきます。
『ナインドッツ』→『プラグイン』をクリック
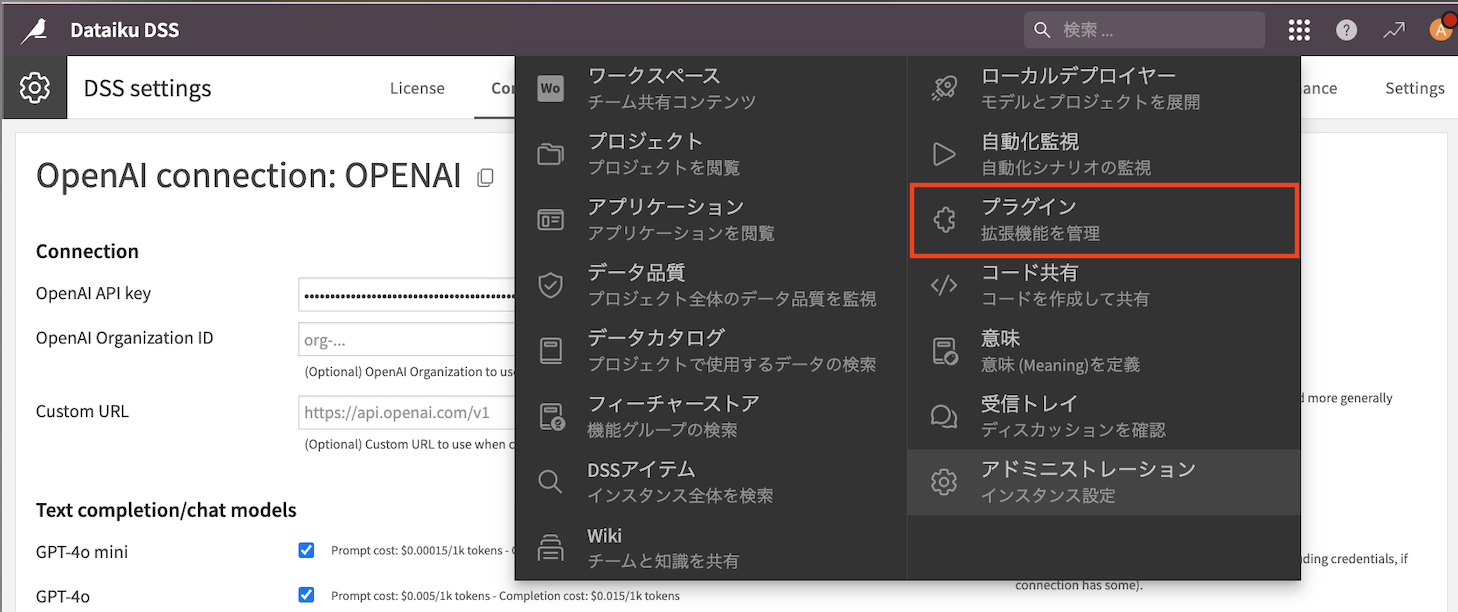
OCRと検索し、Text extraction and OCRを『INSTALL』する。
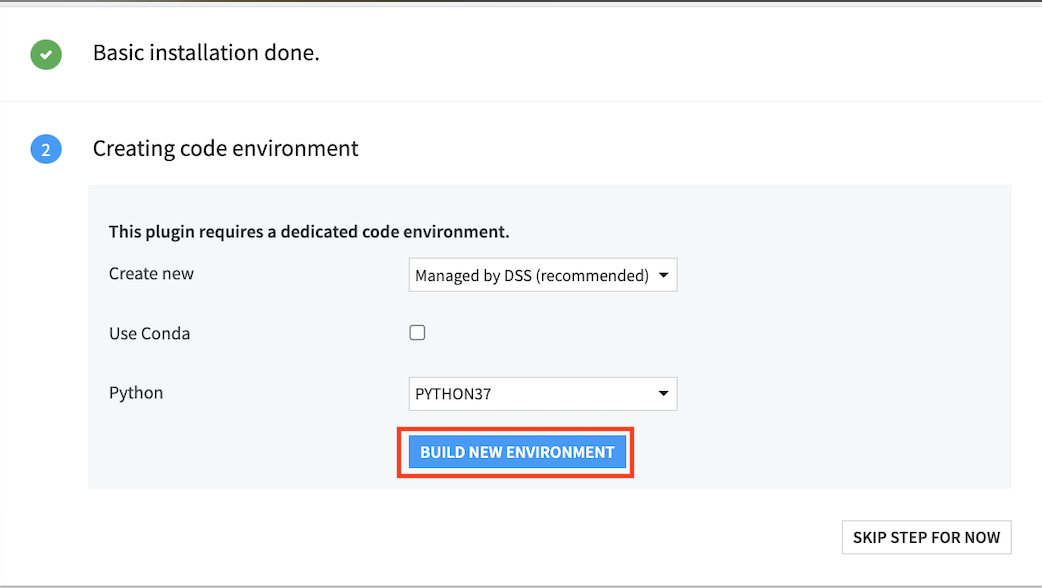
これで準備完了!!
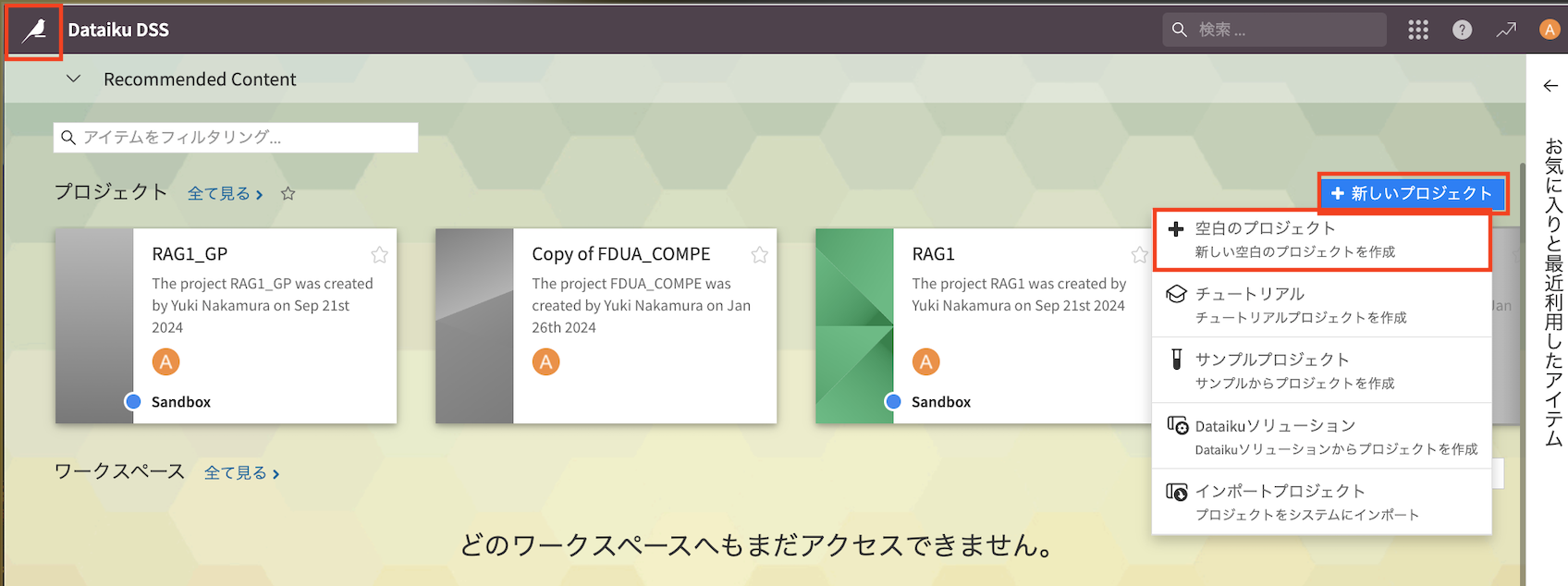
3. 新しいプロジェクトを作成
- 左上の鳥さんのアイコンでトップ画面に戻り、右側の『新しいプロジェクト』をクリック
- プロジェクト名を入力し、『CEATE』をクリックする。
4. データ接続
プロジェクト内でデータソースを接続します(CSVファイルやデータベースなど)。必要なデータをインポートします。
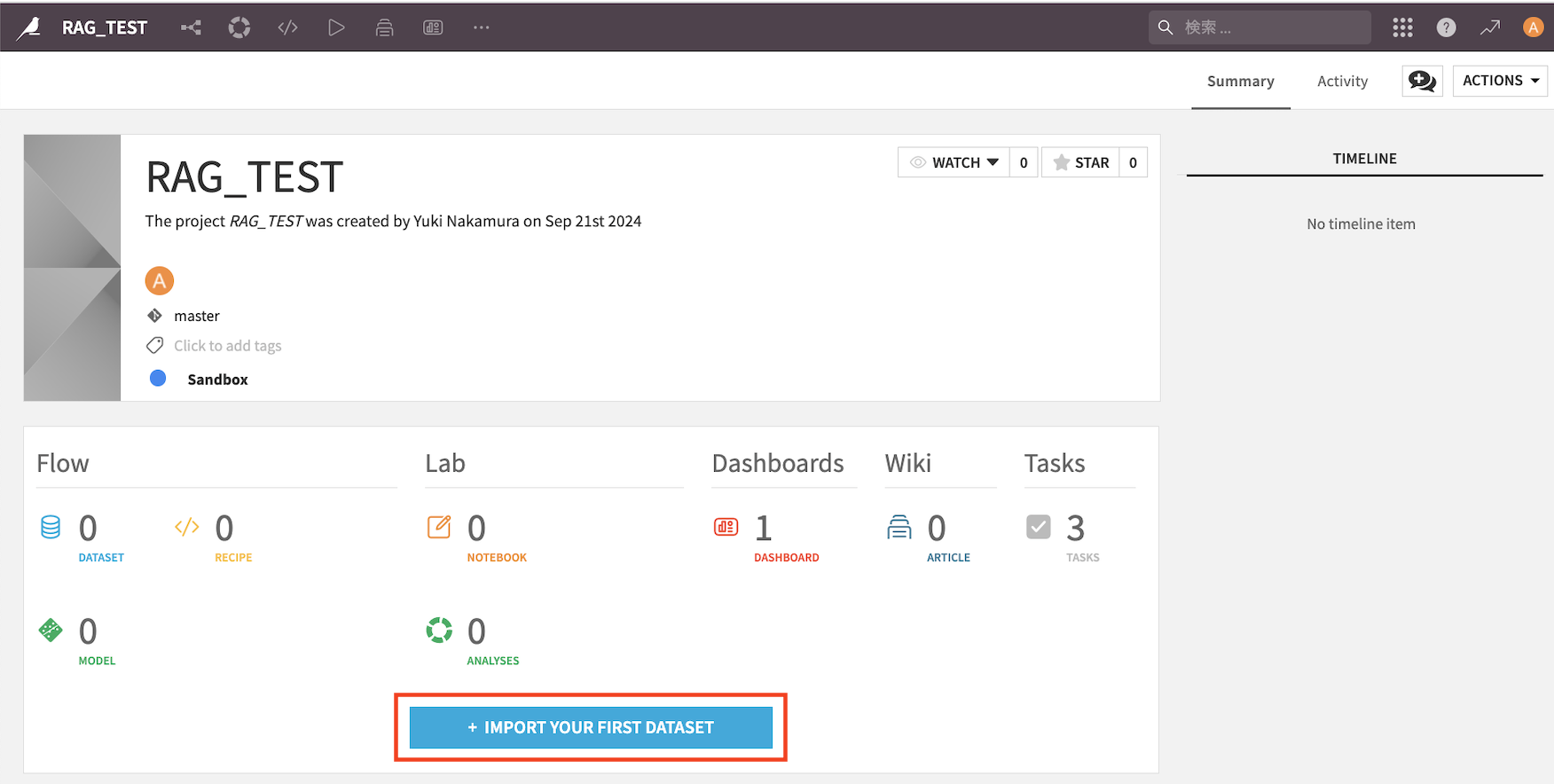
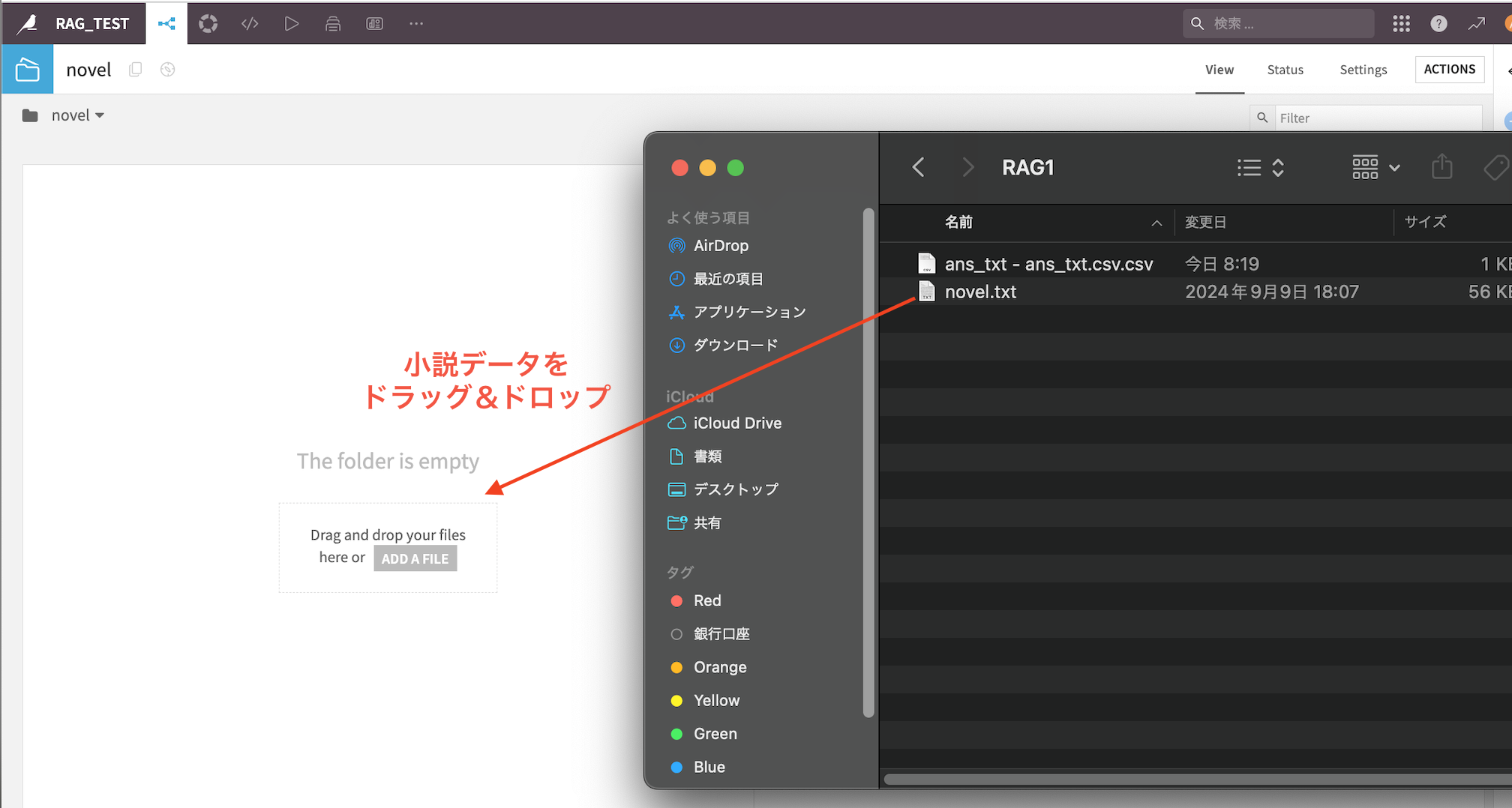
『IMPORT YOUR FIRST DATASET』→『フォルダ』を選択
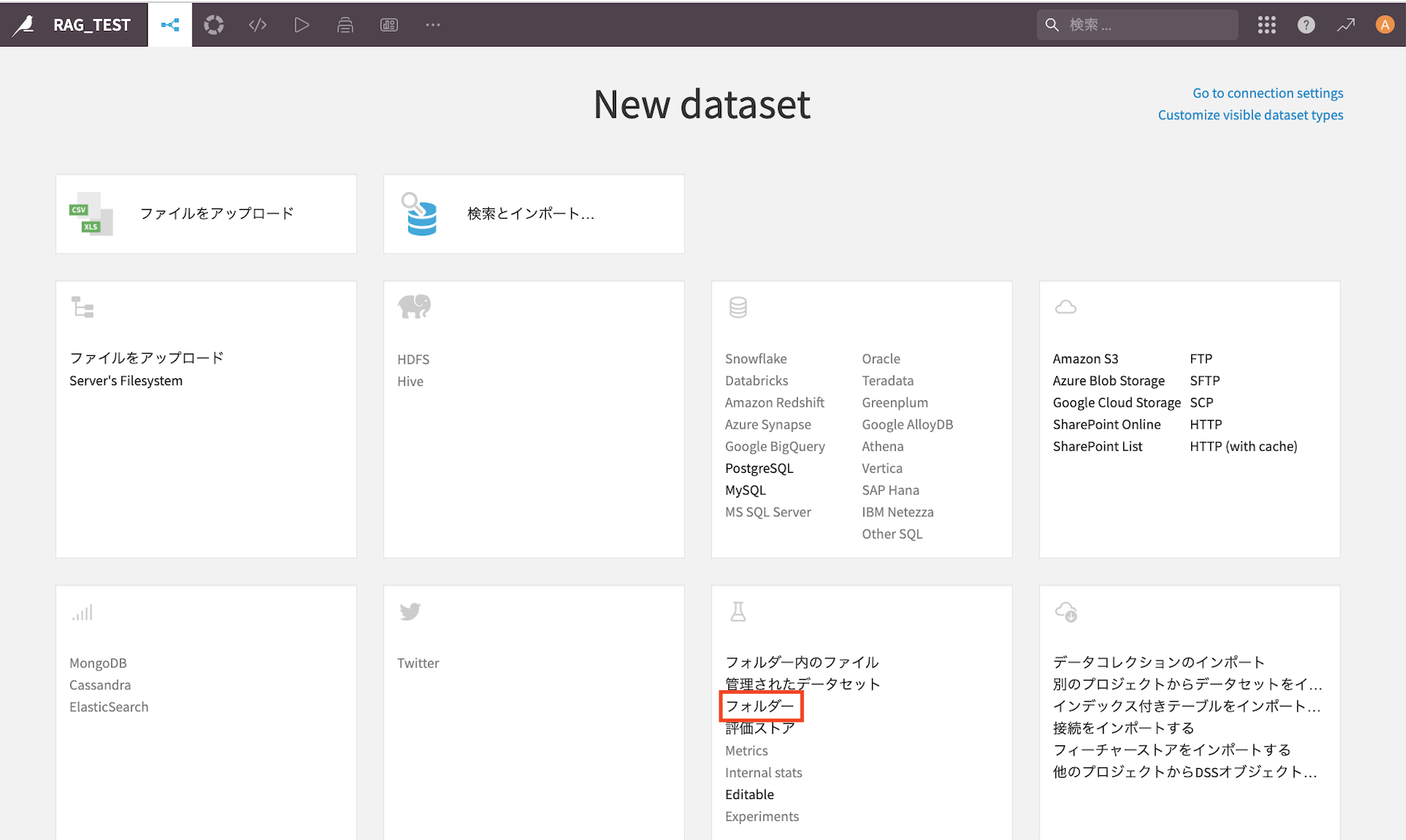
小説データをフォルダにドラッグ&ドロップ
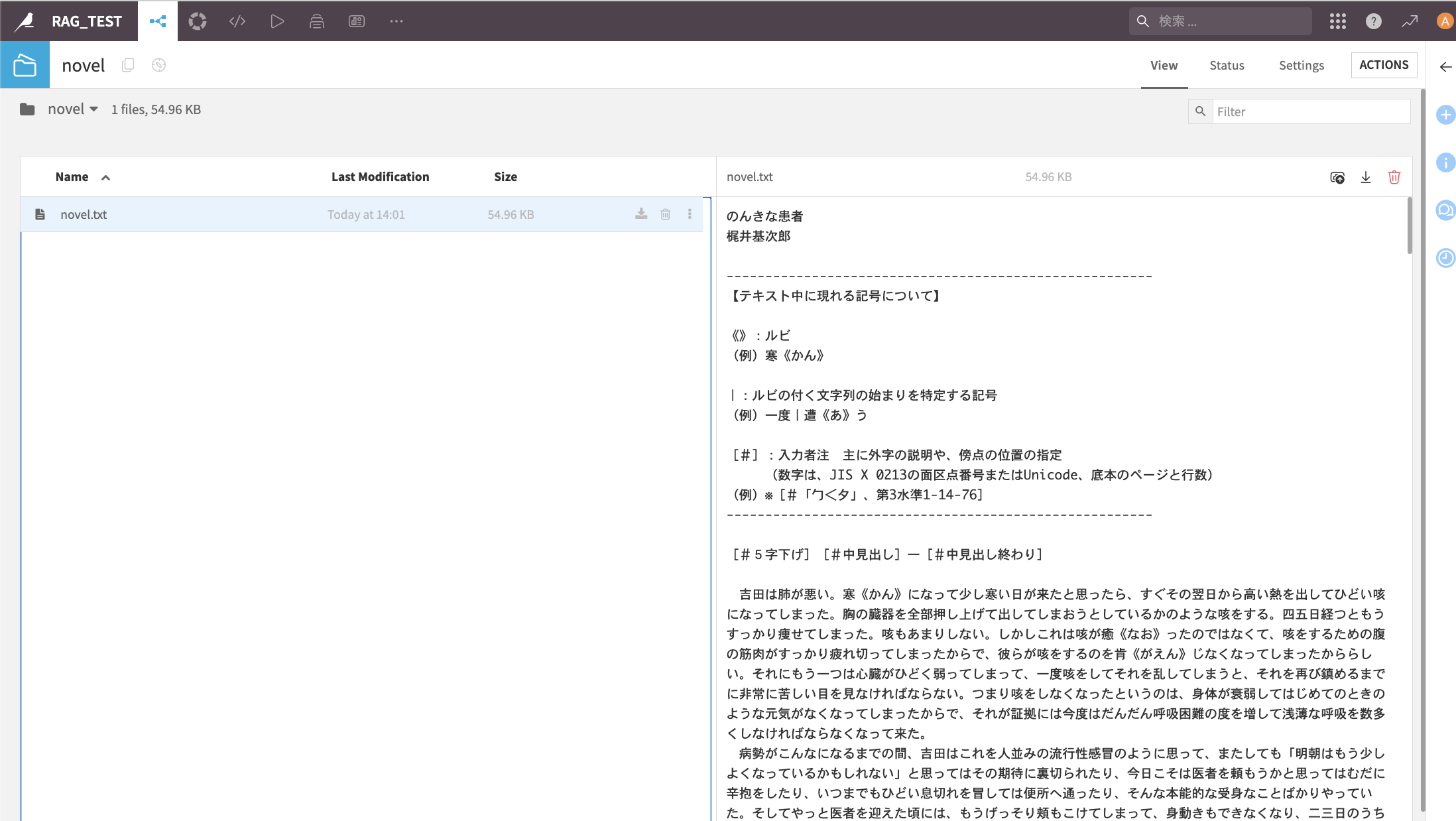
内容を確認する
5. テキストを抽出
「Text extraction and OCR」プラグインを使い、アップロードしたファイルからテキストを抽出します。
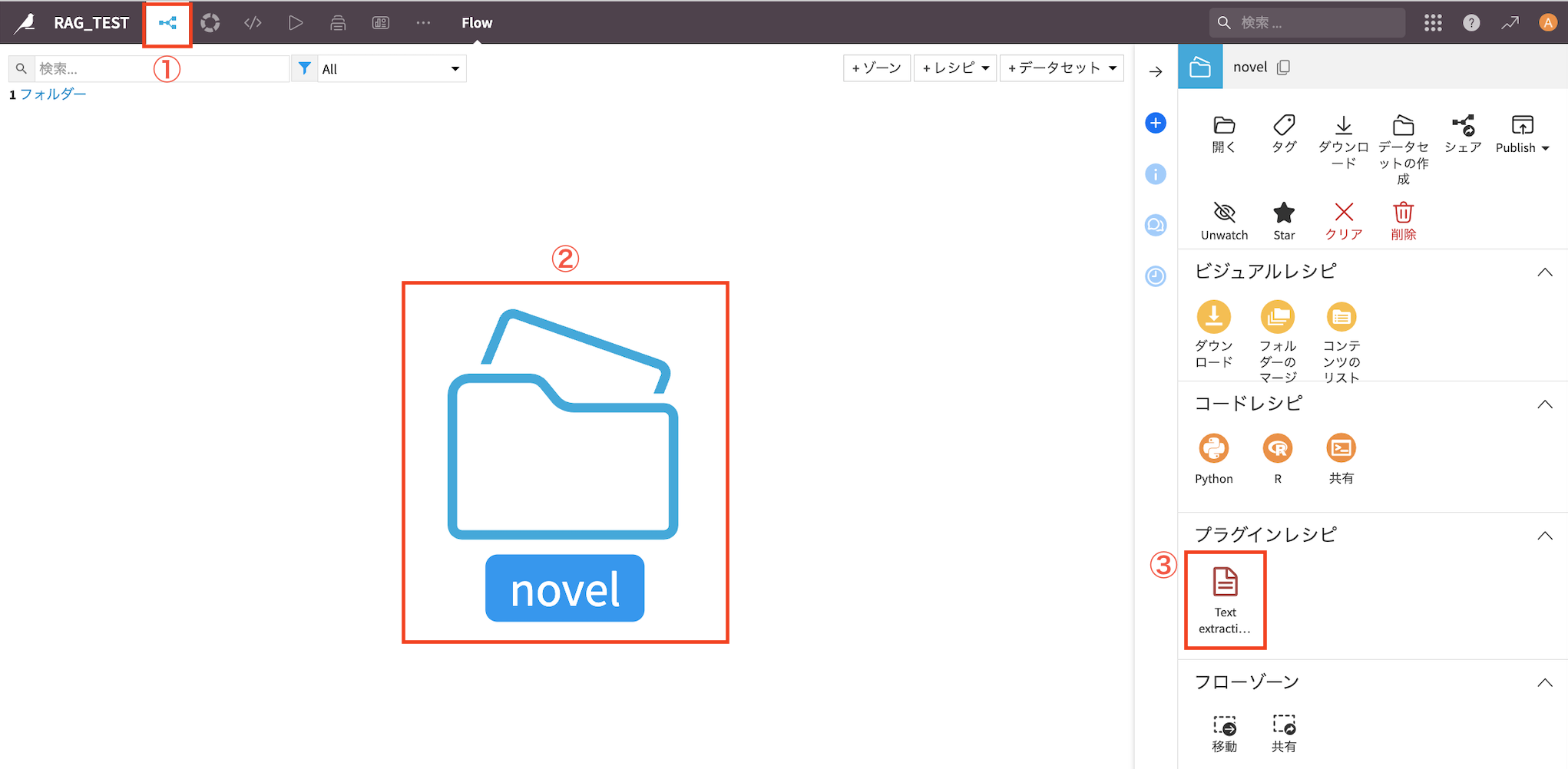
『Text extraction』をクリック
Optput Datasetの名前をつけて、そのまま『実行』
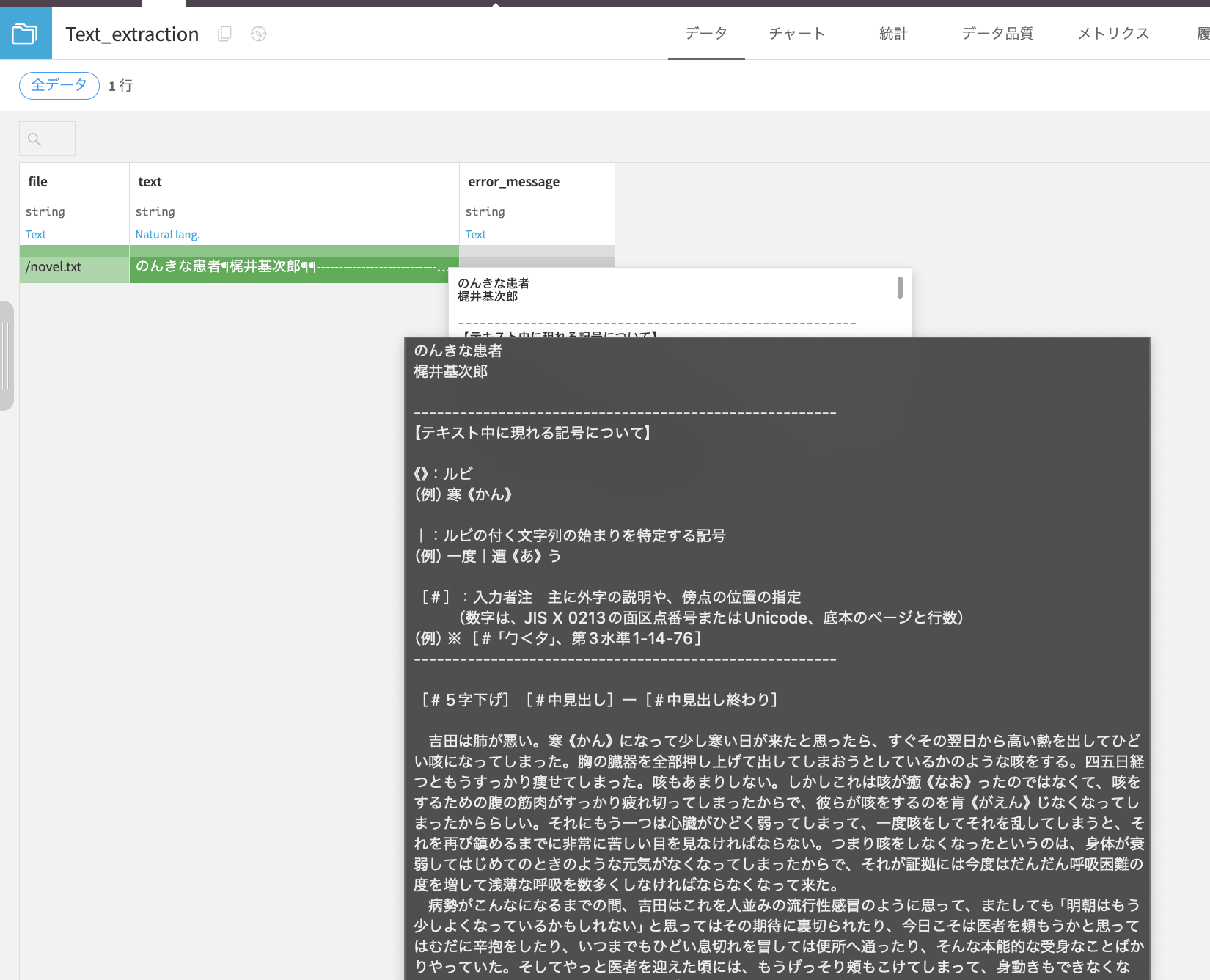
そうするとテキストが抽出されます。
6. RAG構築
いよいよ、RAG(Retrieval-Augmented Generation)モデルを作成します。
LLMレシピの『埋め込み』をクリック
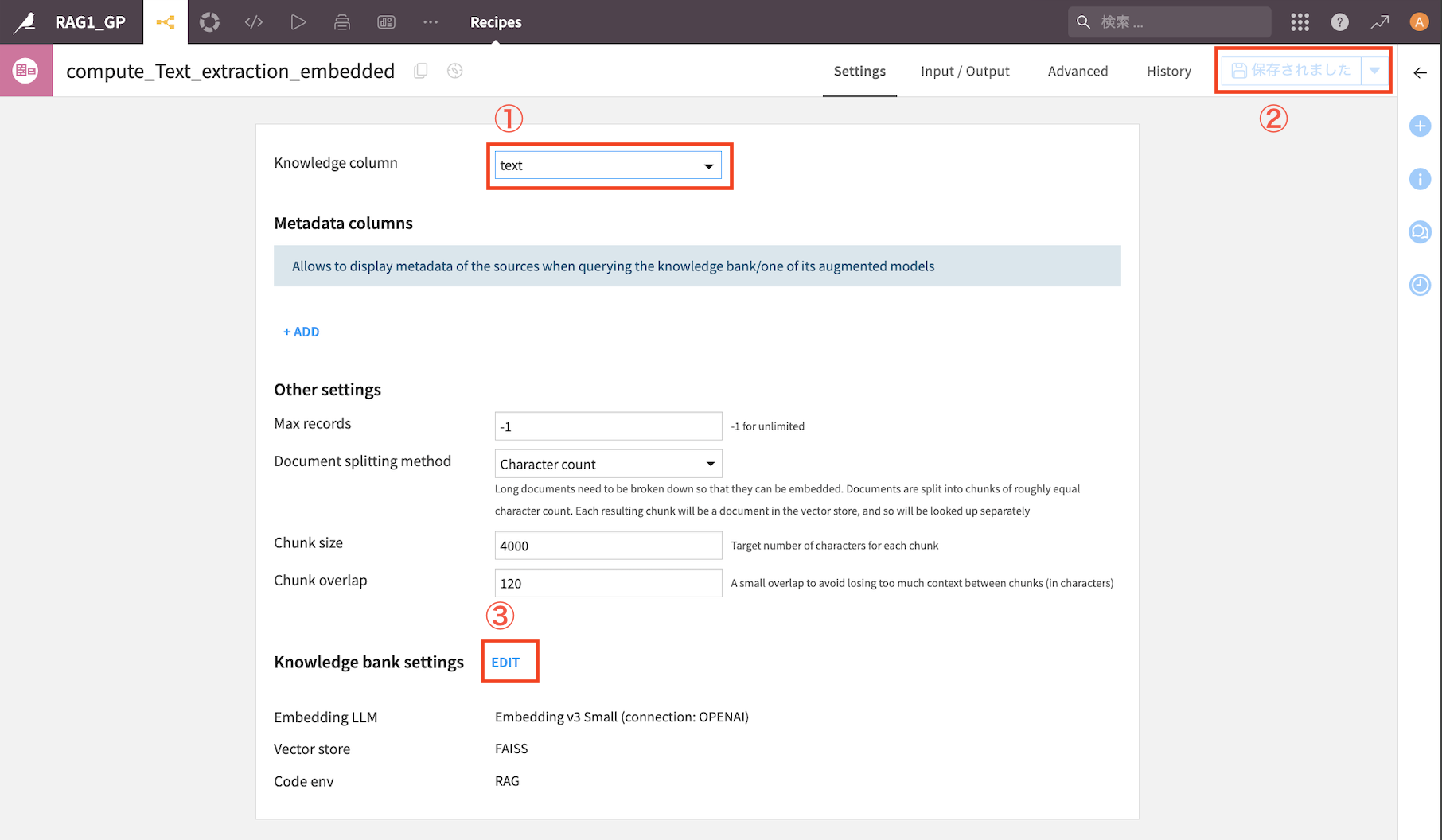
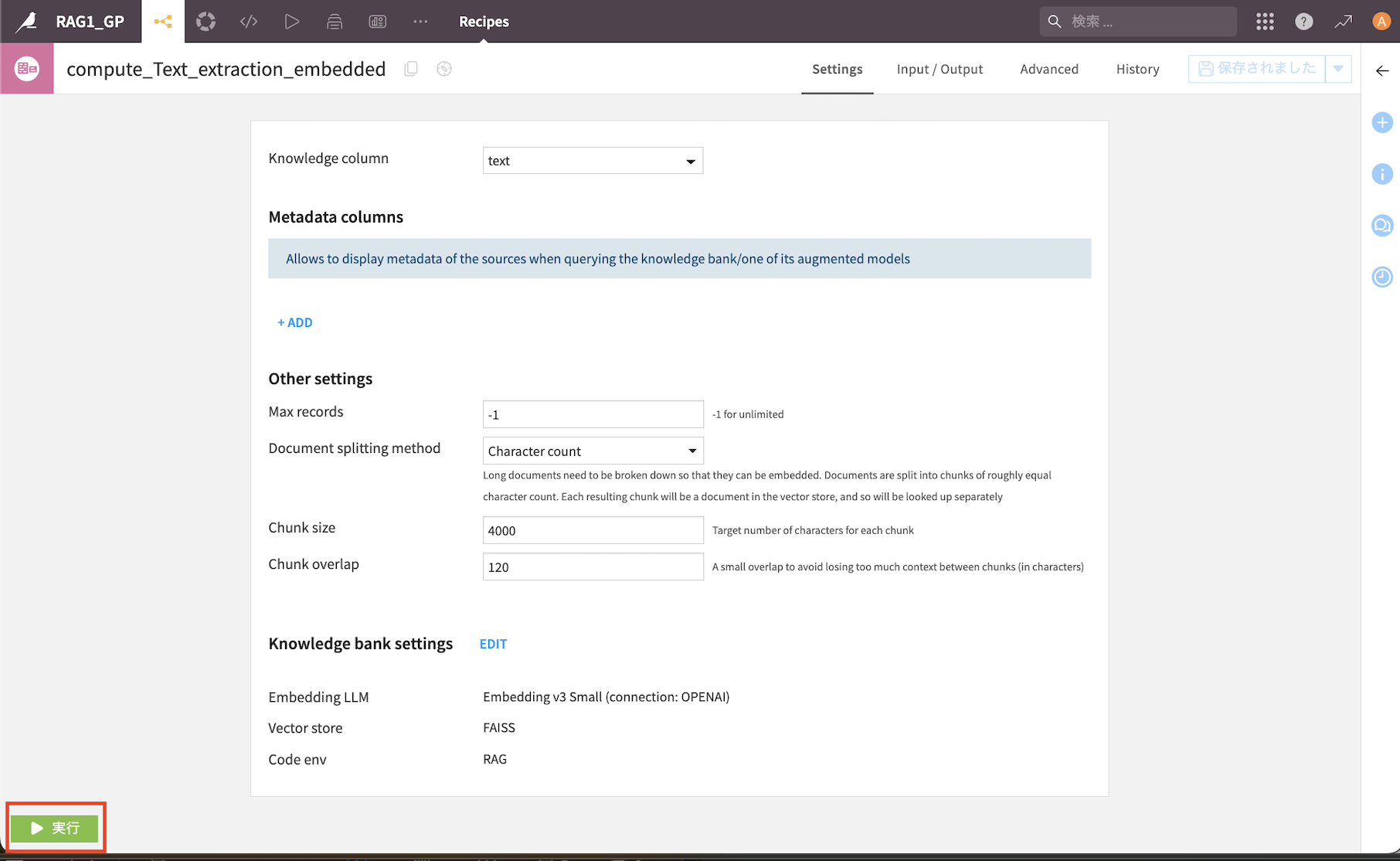
①Knowledge columnは『text』を選択
②右上『保存』をクリック
③Knowledge bank serringsの『EDIT』をクリック
『Core setting』のタブにいき、添付の通り設定し、『保存』をクリック。
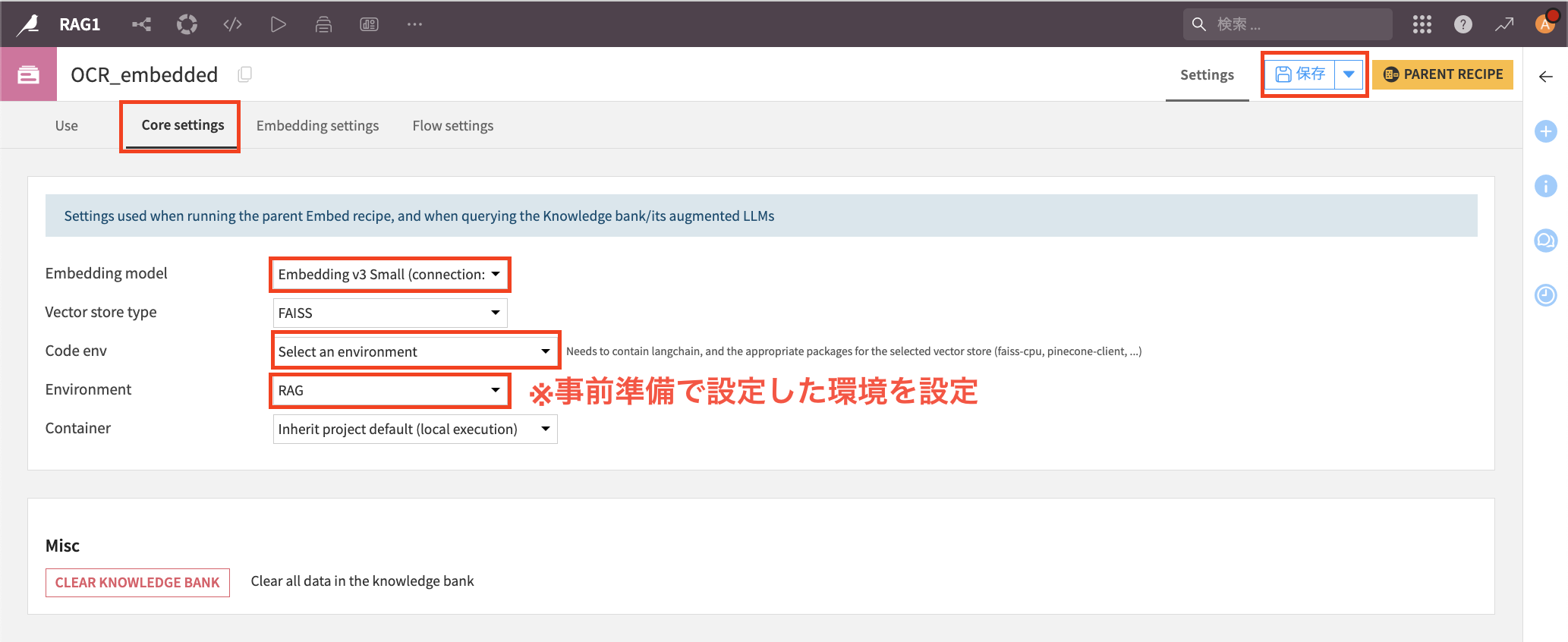
『Use』のタブに戻る
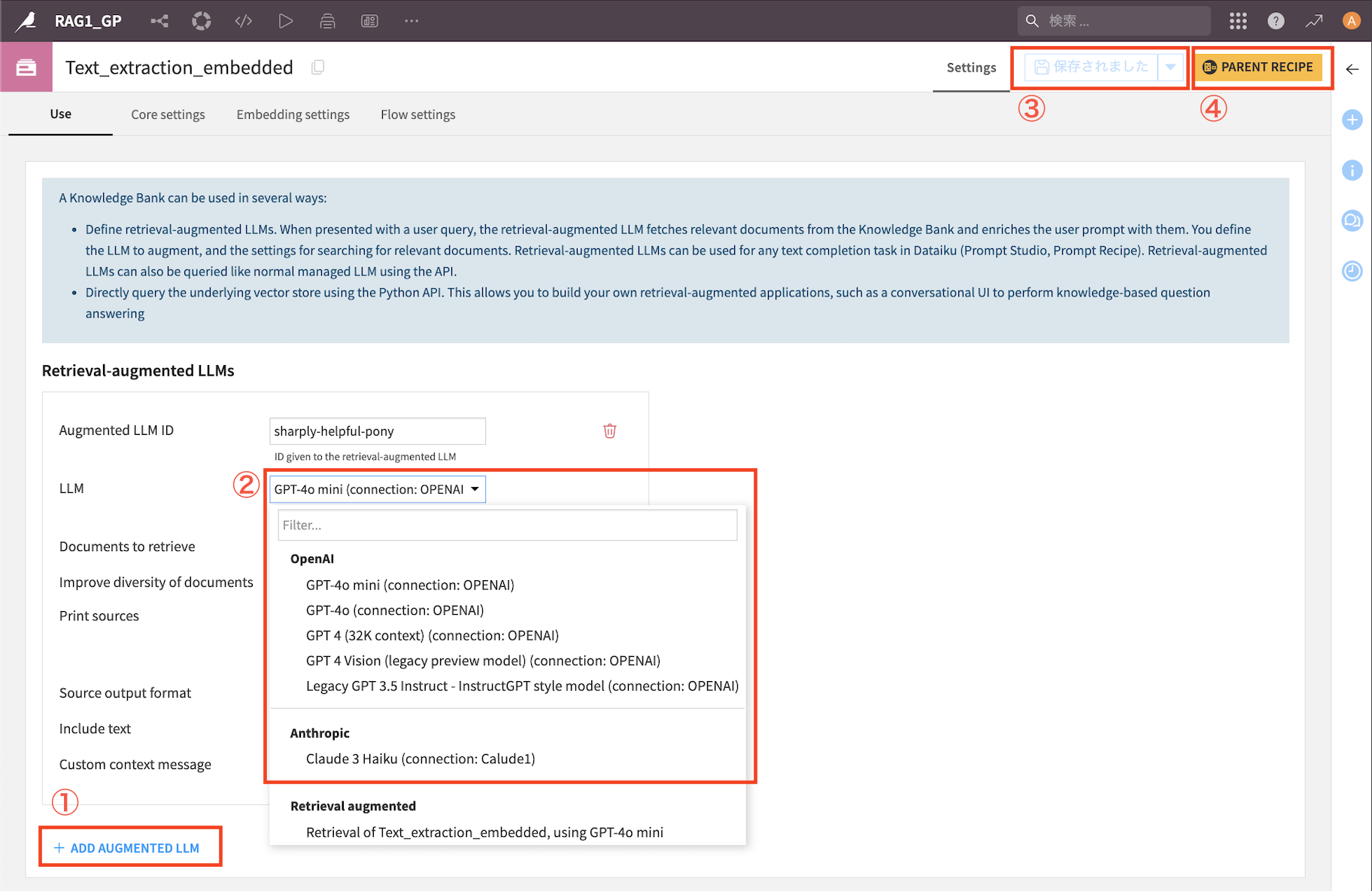
①『ADD AUGMENTED LLM』をクリック
② LLMを選択(※ご自身のお財布とご相談ください ご参考
③『保存』をクリック
④『PARENT RECIPE』をクリック
※GPT-4o miniを含む最新のOpenAI、VertexAI、ClaudeのAPI利用料まとめ(2024年7月21日時点))
『実行』をクリック
7. 質問データのアップロード
質問データをCSVやExcel形式でアップロードし、RAGモデルに使用します。
①トップに戻る
②データセットを追加
③『ファイルをアップロード』をクリック
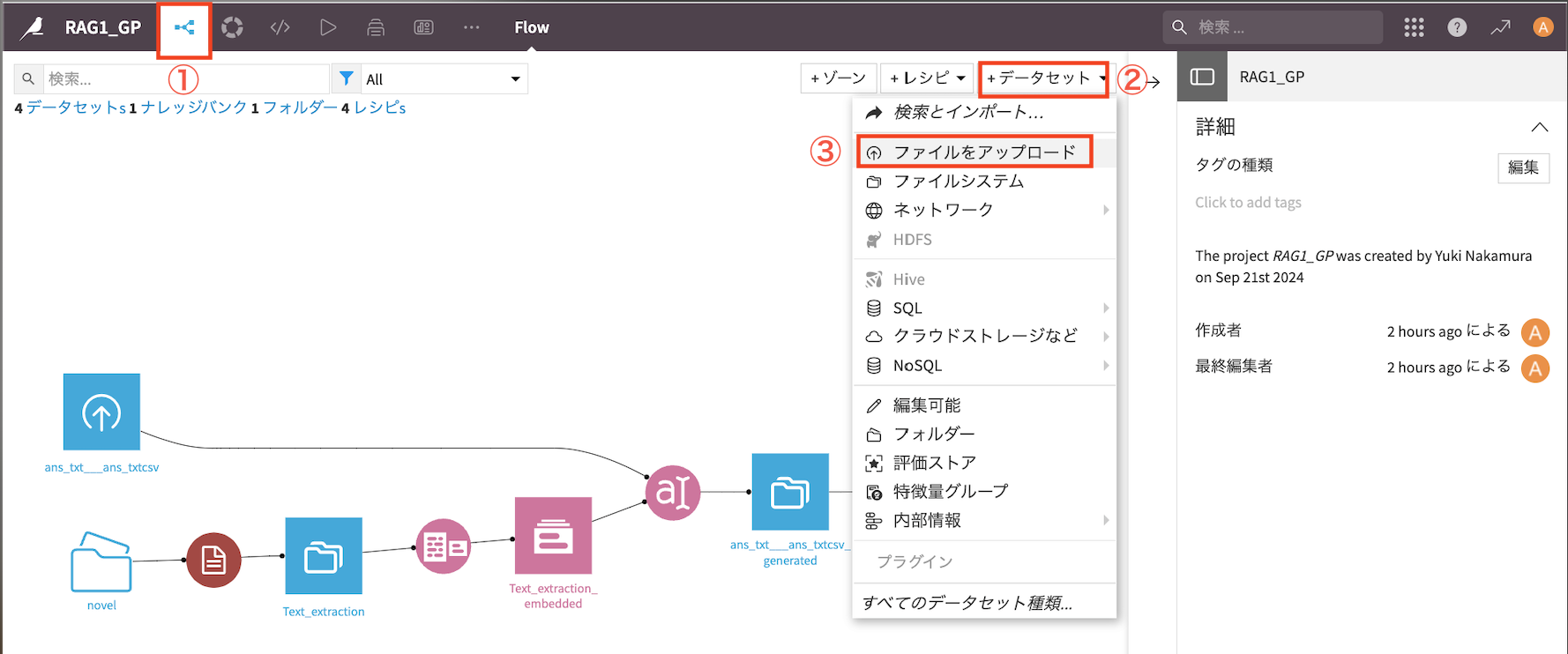
質問の内容が入っているCSVをドラッグ&ドロップ
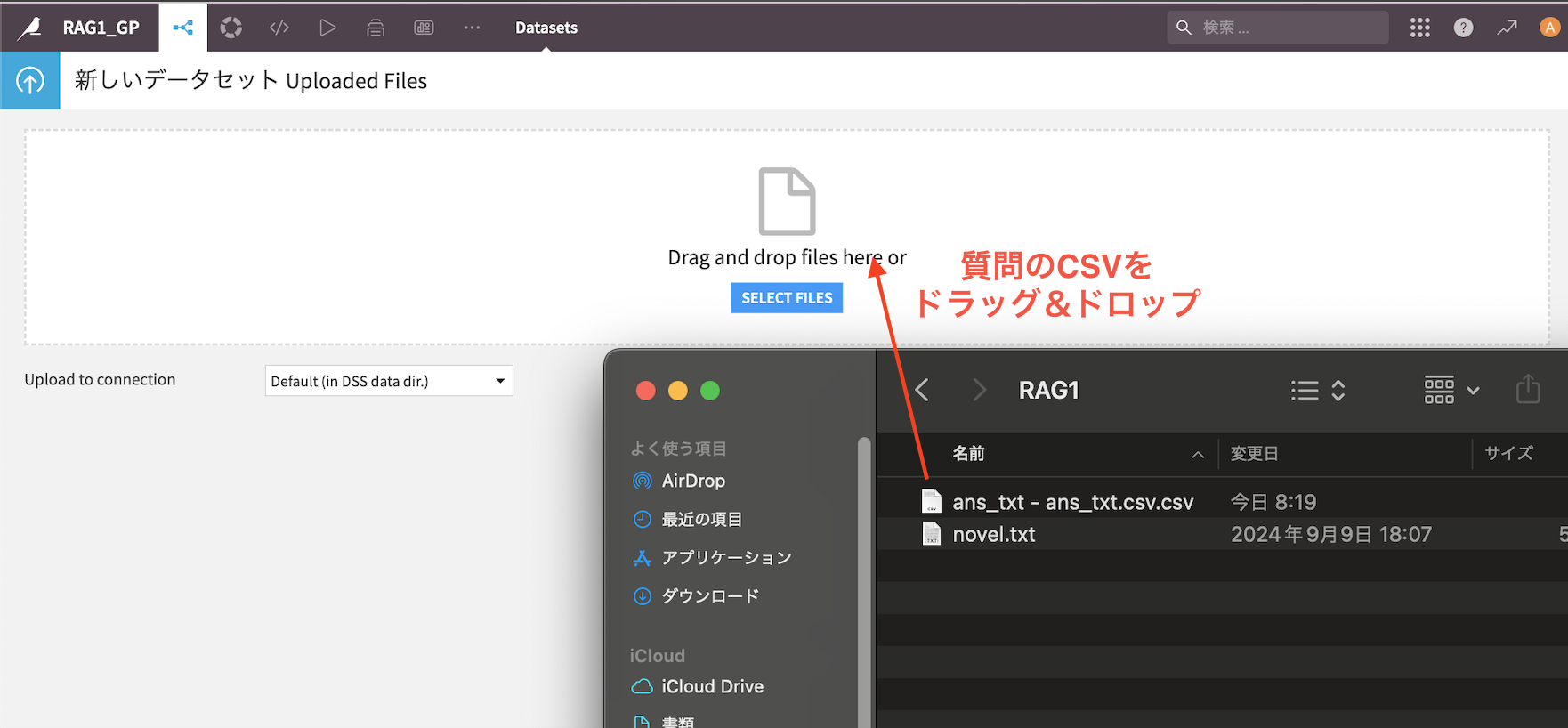
8. プロンプトを書き作成済みのRAGで回答する
質問ファイルに『プロンプトレシピ』を適用
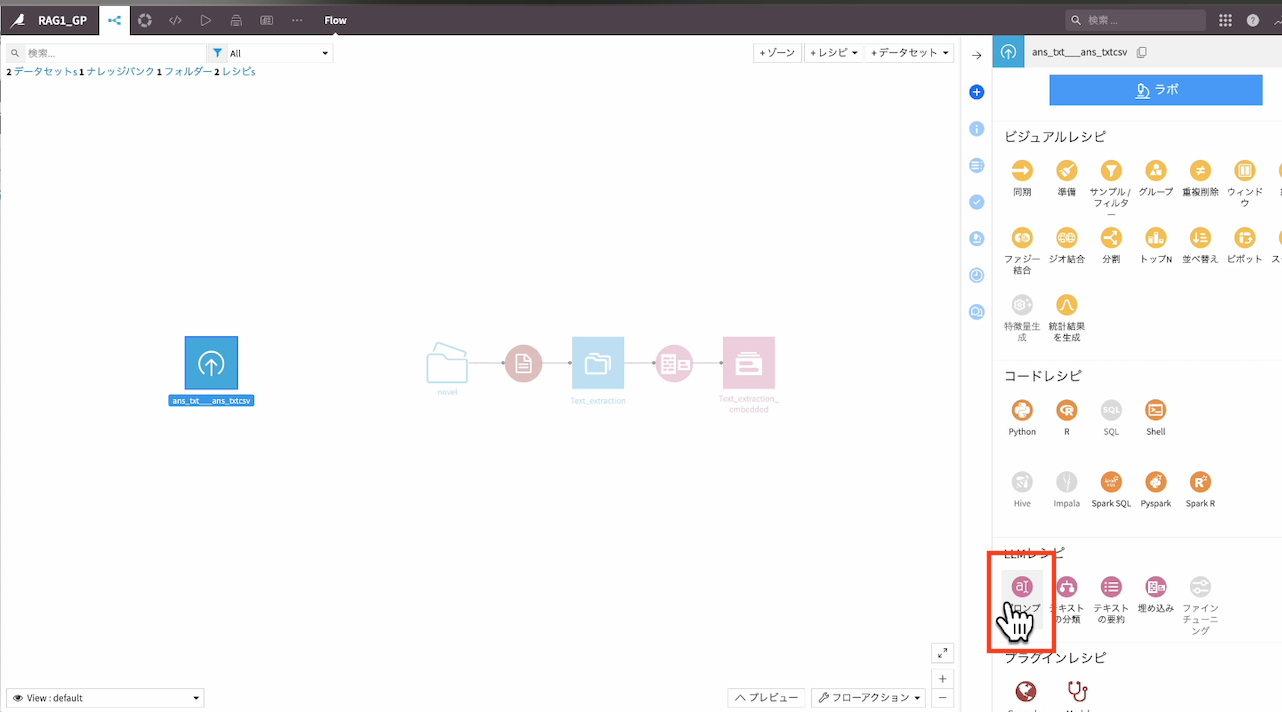
右上の『EDIT IN PROMPT STUDIO』をクリック
①LLMから先ほど作成したRAGのモデルを選択
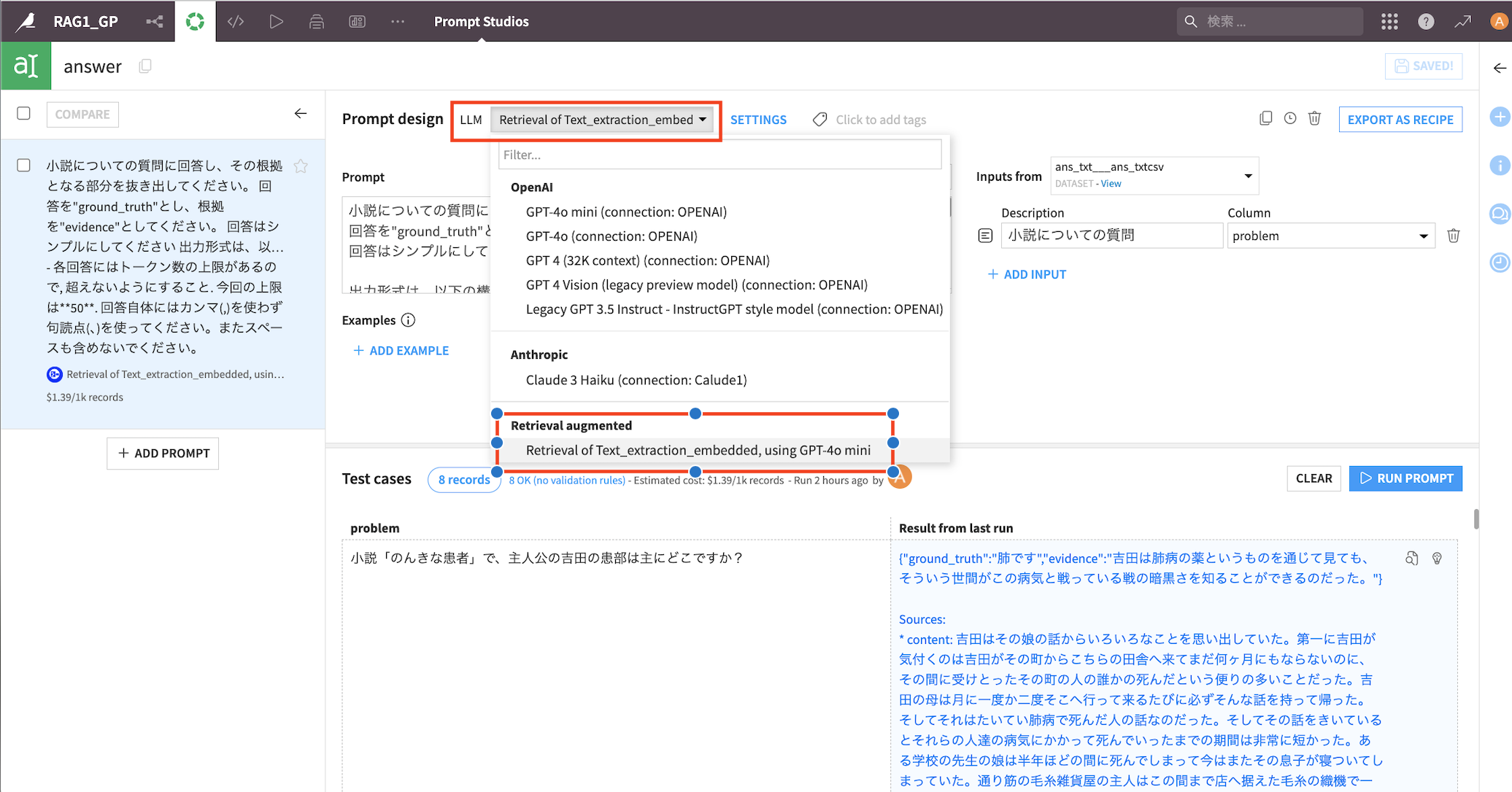
①『ADD INPUT』で列を指定
②Promptを記載する(※)
③『RUN PROMPT』で小レコードでまわして確認する
④『EXPORT AS RECIPE』をクリック→その後『実行』
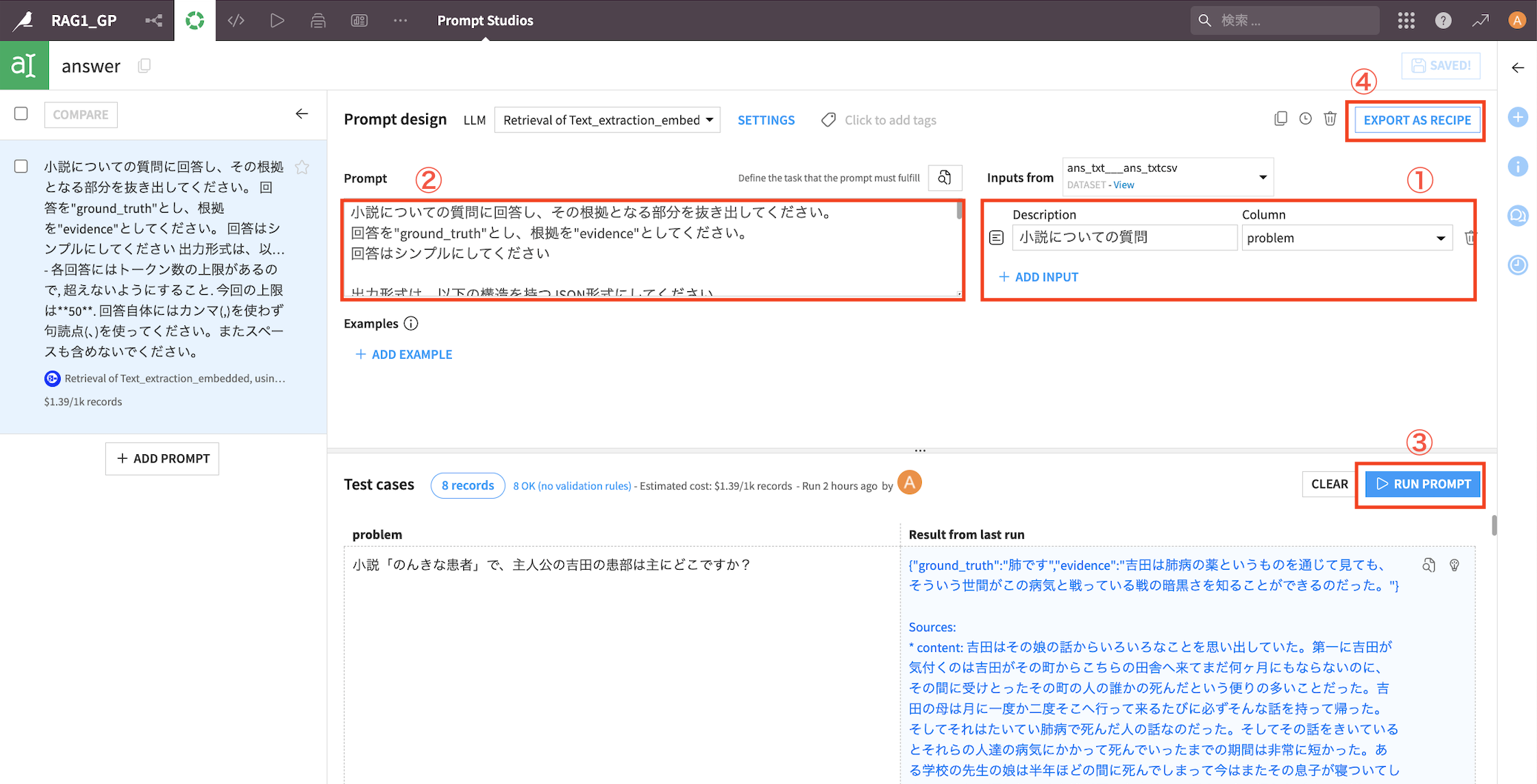
(※)私はこのようなプロンプトを書いてみました
小説についての質問に回答し、その根拠となる部分を抜き出してください。
回答を"ground_truth"とし、根拠を"evidence"としてください。
回答はシンプルにしてください
出力形式は、以下の構造を持つJSON形式にしてください。
Outputは{"ground_truth":で始まる形式のみにしてください。
回答がわからない時は他の回答と同様に{"ground_truth":"わかりません" と返してください。
回答に関する注意点
- 参照元の小説から回答を導くこと.
- 数量で答える問題の回答には単位を付けること.
- 参照元に答えの手がかりが見つからないと判断される場合はその旨を「分かりません」と答えること.
- 質問自体に誤りがあると判断される場合は「質問誤り」と答えること.
- [質問データ](#質問データ)の問題に過不足なく回答すること.
- 各回答にはトークン数の上限があるので, 超えないようにすること. 今回の上限は**50**.
回答自体にはカンマ(,)を使わず句読点(、)を使ってください。またスペースも含めないでください。
9. データ整形
準備レシピでデータ整形をしあす。
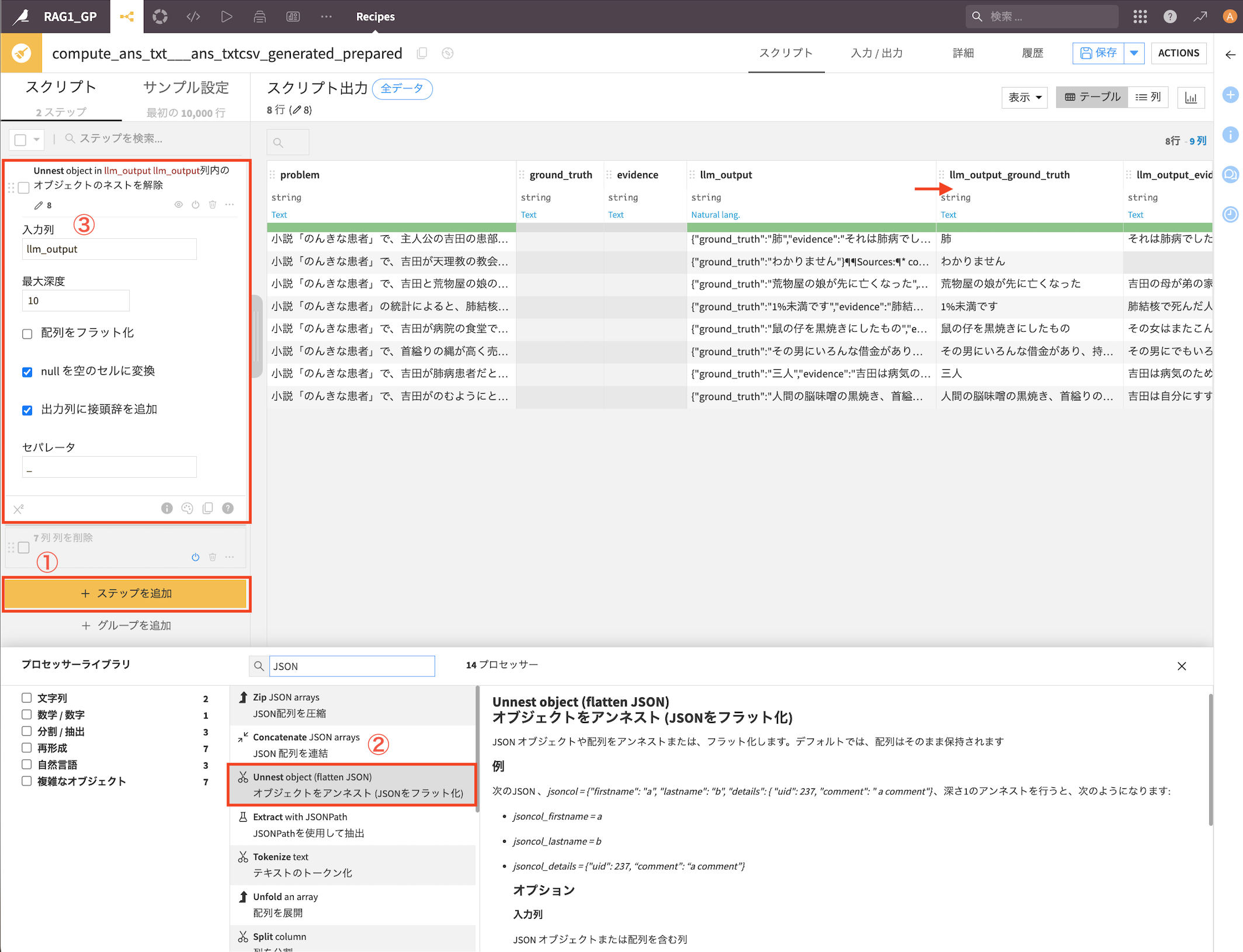
このように列が分割されます。
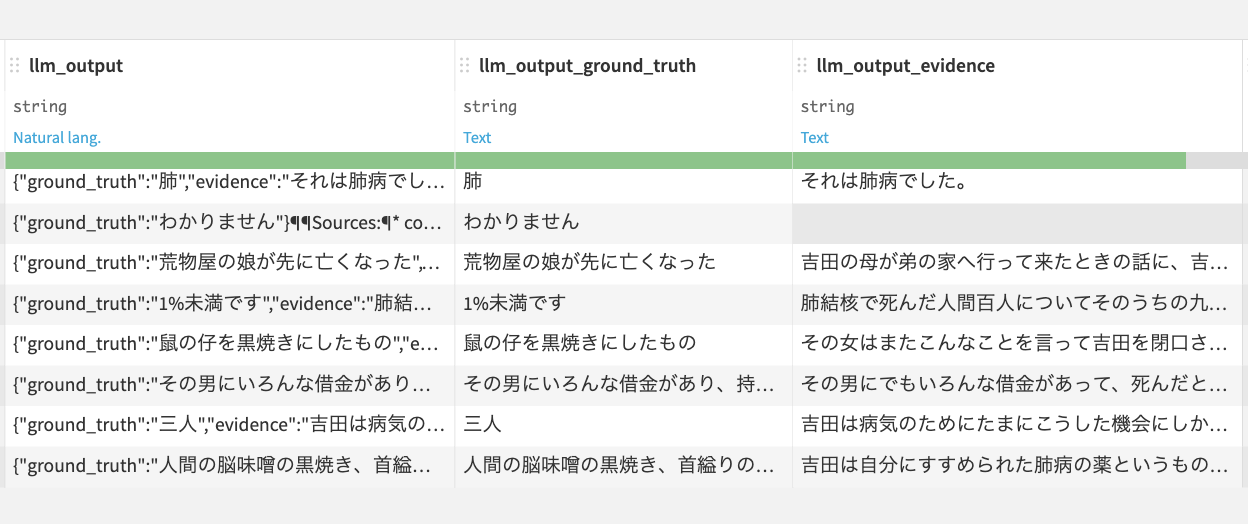
余計な列を削除します。
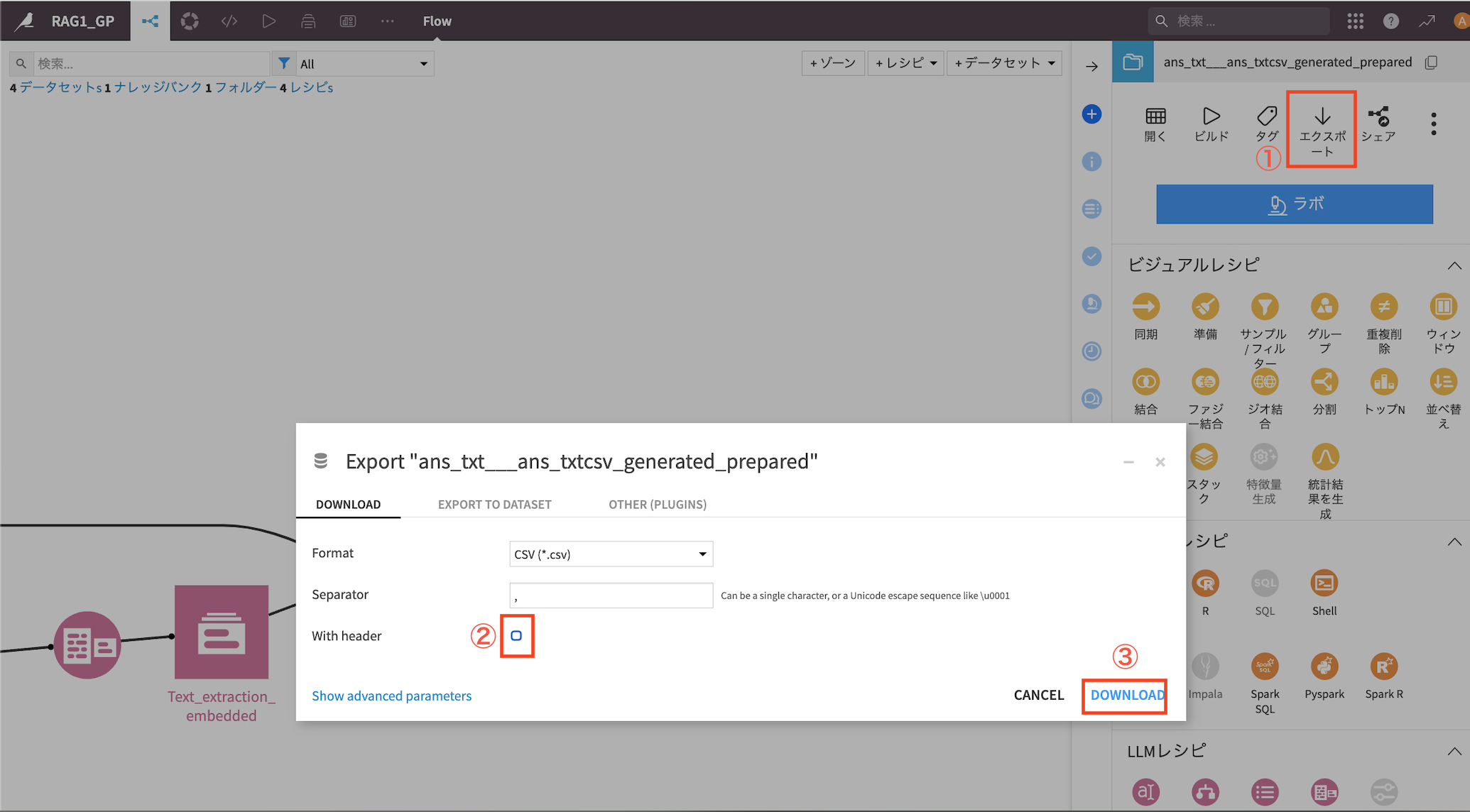
10. CSVダウンロード
整形したデータをCSV形式でダウンロードします。
さいごに
エラーがでてきたらその対処法をLLMに聞いて進めてみてください。