これは GLOBIS Advent Calender 2021 6日目の記事です。
TL;DR
アプリケーションのログは標準出力/標準エラーに JSON で吐き出しておけば大抵のケースで嬉しくなる
はじめに
この記事では、主にサーバーサイドで動くアプリケーションのログを取り扱う仕組みを説明しつつ、アプリケーション側でどのようにログを出力すると扱いやすくなるのか、というプラクティスを SRE の視点から紹介します。
対象読者としては普段ロギングの仕組みに触れることがあまりない開発者を想定しています。そのため、上の TL;DR を見て「当たり前じゃん」と思う人にとっては目新しい情報はないかもしれません。
また、今回は監視、アラートついては取り扱わないので、エラーログの監視についても範囲外とします。
ロギングとは
一般的に、ある時点で起こったイベントとその時刻を記録することをロギングと呼びます。Web アプリケーションの場合は、Web サーバーのアクセスログやアプリケーションサーバーの実行ログ、及びエラーログなどを記録して、ストレージやログ集約サービスに永続化し、活用する仕組み全体を指していることが多いです。
ログを収集する目的は様々ですが、いくつか例をあげると次の通りです。
- セキュリティ要件を満たすためにアクセスログを長期間保存したい
- 不具合を調査するためにアプリケーションのエラーログを検索したい
- アクセスログの統計情報をとってダッシュボードに表示したい
いずれにしても、ログを正しく記録して活用することは Web システムを運用する上で必須の要件です。ここでは、アプリケーションがログを出力してから永続化されるまでの流れを次の3つのフェーズに分けて、インフラ構成のパターンごとに説明していきます。
-
ログ出力
- アプリケーションがどういう形でログを出力して、どう記録されるか
-
ログローテート
- 無尽蔵に増えるログに対してどう対処するか
-
ログ集約
- どうやってストレージや外部サービスにログを永続化するか
VM ベースの場合
まずは、AWS の EC2 で動いているようなアプリケーションでのロギングの流れを説明します。様々な方法があると思うのであくまで一例です。
ログ出力
まず思いつくのはアプリケーションが直接ログファイルに出力するパターンです。Ruby on Rails や Laravel などのフルスタックなフレームワークの初期設定はこうなっていることが多いと思います。
ですが、実は Twelve-Factor App では次のように述べられています。
Twelve-Factor Appはアプリケーションの出力ストリームの送り先やストレージについて一切関知しない。 アプリケーションはログファイルに書き込んだり管理しようとするべきではない。代わりに、それぞれの実行中のプロセスはイベントストリームをstdout(標準出力)にバッファリングせずに書きだす。
本番環境でどうするかというと、標準出力に吐いたログを systemd がハンドリングしてファイルに出力したりします。
ログローテート
ログをファイルに記録し続けるとディスクを圧迫するので、定期的に過去のログファイルを消してローテーションする必要があります。これもフレームワーク側で対応している場合もありますが、サーバー側で用意している logrotate を使って行うことが一般的です。
ログ集約
各種クラウド/SaaS 用の agent や fluentd などのログ収集ツールを別プロセスとして起動して、ログファイルを読み取って転送します。
これらのツールはログのバッファリングや再送処理を備えており、ログの取り扱いに最適化されているので、アプリケーションで直接ログを転送するよりもオーバーヘッドの発生やログの欠損を防ぐことができます。
コンテナベース(kubernetes)の場合
K8s 上で動くアプリケーションは Docker コンテナとして運用するので、そのお作法に従いつつ k8s でロギングの仕組みを構築する必要があります。
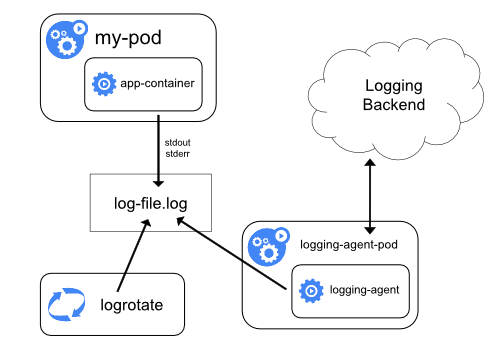
出典: Logging Architecture | Kubernetes
ログ形式
コンテナの場合はログを標準出力/標準エラーに吐き出す必要があります。直接ファイルに出力してもコンテナ内部でしか読み取れないので意味がありません。
吐き出されたログはコンテナの実行環境(Docker だったり Docker 以外のランタイムだったりします)によってホスト上のログファイル /var/log/pods/<file-name>.log に記録されます。
ログローテート
K8s の責務なので特に気にすることはありません。少しだけ説明すると、各ノードでコンテナの外部に直接配置されている kubelet というコンポーネントがホスト上のログファイルをローテートしています。
ログ集約
各種クラウド/SaaS 用の agent や fluentd などのログ収集ツールを使うのは VM ベースの場合と同じですが、k8s 上で動かす場合は Pod (DaemonSet など) として起動します。
ただし、コンテナからホスト上のログファイル読み取る必要があるので、マニフェストにホストパスをマウントする設定を追加します。
コンテナベース(PaaS)の場合
K8s よりも抽象度の高い PaaS だと、ログを標準出力/標準エラーに吐き出せばあとはよしなにやってくれる場合が多いです。
例えば AWS の ECS や EKS on Fargate では組み込みのログドライバーを設定するだけで CloudWatch Logs へ転送してくれますし、GCP の GAE や Cloud Run に至っては何も設定せずとも Cloud Logging に転送してくれます。
ロギングにおけるプラクティス
構造化ロギング
アプリケーションログのフォーマットを統一することで、単なるテキストではなく構造化されたデータセットとして扱うことを構造化ロギングといいます。フォーマットとしては JSON 形式が一般的なので、要はログを JSON で吐き出すように揃えよう、という話です。
メリット
ログを構造化することで、検索のインデックスとして使用したり、各フィールドの値に意味を持たせたりすることができます。
さらに、複数行のログやスタックトレースも1つの JSON で表現できるので、fluentd のプラグインで正規表現を駆使するような処理が不要になって SRE としても嬉しいです。
デメリット
デメリットとしてはローカル開発で JSON ログが流れると逆に見づらくなるということが考えられますが、環境変数や環境ごとの設定ファイルで切り替えられるようにしておけば問題ないでしょう。
各種クラウド/SaaS の対応状況
JSON をパースして値を解釈するのはログ集約サービスの役割です。私が触ったことのある以下のサービスでは対応していました。
- CloudWatch Logs (AWS)
- Cloud Logging (GCP)
- Datadog
サービスによっては単に JSON をパースするだけではなく、特定のフィールドを使ってログレベルや様々な属性を表現することができます。
例えば Cloud Logging では severity というフィールドでログレベルを指定することで、自動で UI に色付けしたり、次のような単純一致よりも柔軟なクエリをかけたりできるようになります。
severity > DEBUG AND severity <= WARNING
ログの中身について
何をログとして出力するか、ということも重要な要素です。クラウドといえどリソースは(コスト的に)有限ですし、検索のノイズを減らすためにも必要十分なログを考えて吐き出す必要があります。
ベストプラクティスは個々のケースごとに変わりますが、アプリケーションサーバーの実行ログであれば、以下のコンテキストを含めると十分活用できるログになります。基本的には各言語でデファクトなライブラリを使えば必然と満たせているはずです。
- ログレベル
- Syslog の重大度 に合わせると収集サービス側でハンドリングしてくれる
- リクエストを一意に特定する ID
- Web サーバーのアクセスログと紐付けることができる
- タイムスタンプ
- ファイル名、関数名、行数
- エラー発生時のスタックトレース
タイムスタンプの扱い
ログのタイムスタンプには、タイムゾーンを含めて出力する方が扱いやすいです。
細かいケースですが、Rails のデフォルトのログフォーマットにはタイムゾーンが含まれていないため、Rails が JST でログを出力するとログ集約サービス側では UTC として取り扱われてしまう、ということがありました。
個別に fluentd などで変換する事もできますが、出力側でタイムゾーンを含めるように統一した方が抜け漏れを防ぐことが出来ます。
インシデントを防ぐ
絶対に避けたいのは「個人情報を平文でログに記録してしまう」ことです。もちろん個人情報を流出させようとしてログに出力する人は普通はいませんが、うっかり開発初期に残したままのデバッグ用のコードが個人情報を記録してしまっていた、という状況は十分起こりえます。
ログ集約のタイミングでマスキングするといった対策も考えられますが、それだけで全てのログパターンを網羅することは実質不可能です。デバッグログをそもそも使わない、または使うとしてもログレベルを適切に設定して本番環境で出力しないようにする、などアプリケーション側でも気をつけることで複合的に対策します。
まとめ
これまでロギングの流れについてざっくり説明してきました。
ただ、システムを本番運用するにあたり、ロギングは単体で完結する話ではなく他のさまざまな要素と組み合わせて構築する必要があります。私自身まだまだ経験不足で全ては詳しく語れないので、ここではキーワードの紹介に留めたいと思います。
-
メトリクス
- OS の CPU/メモリ使用率や Web サーバーのコネクション数など、システムのパフォーマンスを表す時系列データです。
-
モニタリングとアラート
- ログとメトリクスを収集したら、閾値を超える異常がないか監視して、異常があれば開発者に通知する必要があります。ここまで実装できていれば一般的な監視システムとして実運用できるレベルだと言えます。
-
トレーシング/APM
- Microservices のような場合だと1つのリクエストのログが複数のサーバーで出力されるため、それらを紐付けたいという需要が出てきます。クライアントでトレース ID を発行することで、複数サービスのログを追跡し、アプリケーションの詳細なパフォーマンスを測定できるようになります。
-
オブザーバビリティ
- 従来のモニタリングにトレーシングを加えて1つのプラットフォームに統合すると、システムの状態を監視するだけでなく、よりシステムのデバッグを効率的に行ってボトルネックを改善しやすくなります。最近ではオブザーバビリティ(可観測性)というワードで語られることが増えてきました。