はじめに
Qiita初投稿です。普段、Railsを良く使っているのですが、Railsには元々ActiveRecordがあるためSQLを意識しなくてもアプリケーションを作ることができます。そのため、私自身基本的な部分は抑えてあるもののSQLの学習が疎かになっていたかと思います。ですがこれから先、エンジニアになることを考えるとSQLの知見は必要になると思いますし、業務レベルのアプリケーション規模ですとやはりパフォーマンスの問題はかなり重要な要素なのではないかと思います。ですので今回このような記事を書かせていただきました。私が学んだ中で、参考になったパフォーマンスチューニングをまとめてみたいと思います。
サブクエリを引数に取る場合、INよりもEXISTSまたは結合を使う。
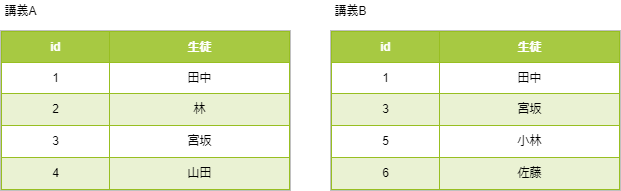
上のテーブルで講義Aと講義Bの両方の講義を受講している生徒を取り出す場合について考えます。
まずは結合は置いておいて、INとEXISTSの場合です。
--INを使う場合
SELECT *
FROM Kougi_A
WHERE id IN (SELECT id FROM Kougi_B);
--EXISTSを使う場合
SELECT *
FROM Kougi_A A
WHERE id EXISTS
(SELECT*
FROM Kougi_B B
WHERE A.id = B.id);
この場合 EXISTSの方がパフォーマンスで有利となります。その理由は下記の2点になります。
-
結合キー(この場合id)にインデックスが張られていれば、講義Bテーブルの実表は見に行かずに、
インデックスの参照のみで済むため。 -
EXISTSは1行でも条件に合致する行を見つけたらそこで検索を打ち切るのでINのように中間テーブル作成から全表検索の必要がないため。
私自身IN EXISTS の違いのところで
続いて 結合を使って書き換える場合ですが下記のように書き換えられます。
--結合を使う場合
SELECT A.id,A.name AS 生徒
FROM Kougi_A A, INNER JOIN Kougi_B B
ON A.id = B.id
この場合もまたINのように中間テーブルの作成から全表探索という仕事がない分、結合を使う方がパフォーマンスで有利となります。(EXISTSと結合の比較の場合はインデックスが使えなければEXISTS有利。)
ソートを回避する
ソートはメモリに結果を一時的に保存しておかなければならないので、非常にリソースを消費する処理です。あらかじめ行数を絞り込むなどしてソートに使うリソースの量を減らすことを考えることが重要です。私自身ソートが発生する関数について知らないものがいくつかあったのでまとめておきます。
ソートが発生する代表的な演算
- GROUP BY
- ORDER BY
- DISTINCT
- 集約関数(SUM, COUNT, AVG, MAX, MIN)
- 集合演算子(UNION, INTERSECT, EXCEPT)
- ウィンドウ関数(RANK, ROW, NUMBER...)
DISTINCTをEXISTSで書き換える
DISTINCTも、重複をなくすためにソートを行います。2つのテーブルを結合した結果を一意にするためにDISTINCTを使う場合はEXISTSを使うことでソートを回避できます。
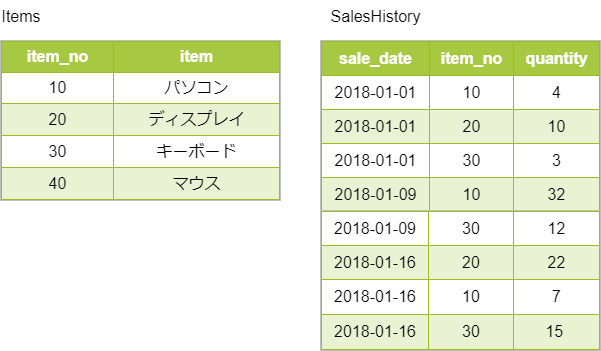
下記のテーブルで商品マスタから売上のあった商品を重複なく取り出す場合について考えます。
-- DISTINCTを使う場合
SELECT DISTINCT I.item_no
FROM Items I INNER JOIN SalesHistory SH
ON I. item_no = SH.item_no;
-- EXISTSを使う場合
SELECT item_no
FROM Items I
WHERE EXISTS (
SELECT *
FROM SalesHistory SH
WHERE I.item_no = SH.item_no);
上のクエリですとDISTINCTを使った場合はソートが行われますがEXISTSを使った場合はソートが行われませんのでその分後者のクエリがパフォーマンス的に優れているといえます。
GROUP BY句 ORDER BY句でインデックスを使う。
上記の通りGROUP BY句 ORDER BY句は並び替えのためにソートを行います。その際にあらかじめインデックスを用意することでソートのための検索を高速化することができます。
極地関数(MAX/MIN)でインデックスを使う。
SQLはMAXとMINという極値関数を持つがこの2つはどちらもソートを発生させます。ただ引数の列にインデックスを貼ることでインデックスのスキャンのみで済ませることができるのでインデックスのない場合と比べて検索を高速化できます。
WHERE句で書ける条件はHAVING句を使わない。
下のクエリは結果は同じですがパフォーマンスで違いが出ます。(下記は購入履歴に関するテーブルの例です。)
--集約した後に、HAVING句でフィルタリング
SELECT sale_date, SUM(quantity)
FROM SalesHistory
GROUP BY sale_date
HAVING sale_date = '2018-01-16'
--集約する前に、WHERE句でフィルタリング
SELECT sale_date, SUM(quantity)
FROM SalesHistory
WHERE sale_date = '2018-01-16'
GROUP BY sale_date
このクエリはパフォーマンス面でみるとWHERE句を使った方が効率が良くなります。理由は下記の2点。
- GROUP BYは「ソートを回避する」の中でも述べておりますがソートを発生させます。そこでWHERE句を使うことでソートを発生させる前にレコード数を絞り込めるためです。
- 2点目としましてはWHERE句を使うことでインデックスが使用できるためです。(
HAVING句で集約した後のテーブルに対しては元テーブルのインデックスは引き継がれません。)
中間テーブルを減らす
SQLでは、サブクエリの結果を新たな中間テーブルと見なすことで柔軟性のあるクエリを書くことができる訳ですが中間テーブルを不用意に増やすことはパフォーマンスの低下に繋がります。できる限り無駄な中間テーブルは省くようにすることが大切です。
HAVING句を活用することで中間テーブルの作成を集約と並行させる。
--GROUP BYで集約した後WHEREでフィルタリング
SELECT *
FROM (SELECT sale_date, MAX(quantity) AS max_qty
FROM SalesHistory
GROUP BY sale_date) --中間テーブルができる
WHERE max_qty >= 10;
--GROUP BYの集約と並行してフィルタリング
SELECT *
FROM SalesHistory
GROUP BY sale_date
HAVING MAX(quantity) >= 10;
「WHERE句で書ける条件はHAVING句を使わない」の部分で述べたことと矛盾しているように感じた方もいらっしゃるかと思いますが先ほどの例は先にWHERE句でレコード数を絞り込んでいる点に注意してください。今回は順序が違います。HAVING句はGROUP BYの集約と並行しながらフィルタリングするため今回のケースではHAVING句を使った方がパフォーマンスが良いです。WHERE句はGROUP BYで集約された後にフィルタリングします。
集約より結合を先に行う
集約と結合を併用するケースの場合にはできる限り集約よりもさきに結合を行うことで中間テーブルの作成を省略することができます。
ここでは商品マスタと商品の売上履歴のテーブルで商品ごとに総計でいくつ売れたかを調べる想定です。

-- 結合の前に集約し1対1の関係を作る
SELECT I.item_no, SH.total_qty
FROM Items I LEFT OUTER JOIN
(SELECT item_no, SUM(quantity) AS total_qty
FROM SalesHistory
GROUP BY item_no) SH
ON I.item_no = SH.item_no
-- 集約の前に一対多の結合を行う
SELECT I.item_no, SUM(SH.quantity) AS total_qty
FROM Items I
LEFT OUTER JOIN Sales_History SH
ON I.item_no = SH.item_no
GROUP BY item_no
クエリは結合の前に集約すると集約の前に結合する2パターンです。まず結合前に集約する方ですが先に集約しているので商品番号で一意になる中間テーブルが作成されその後item_noで結合することで1対1の関係ができます。しかし中間テーブル自体がリソースを使うことになりますし、元テーブルにインデックスがあっても使うことができません。
一方、後者の集約前に結合する方では、先に結合するため1対多の関係ができます。この時点では中間テーブルは作成されませんのでリソースの節約につながります。そのため、この2つのクエリを比較した際にパフォーマンスで優れているのは後者の「集約前に結合する」です。ポイントは下記の2点。
- 集約前に結合することで中間テーブルが作られない。
- 1対多の関係にはなるが不当に行数が増えることはない。
(私自身このことを知るまでは1対多になる分パフォーマンス的に良くないのではというイメージがありました...)
最後に
今回は、SQLのパフォーマンスについての知見を得ることができました。冒頭で述べた通り私はRailsを使うことが多いので、Activerecodの便利さを知っているわけですが、その便利さ故にSQLの深い部分について勉強してこなかったことを反省しました。これからはログ等を確認しながらどこかパフォーマンスを改善できるところがないかなどSQLについても気にする癖をつけたいと思います。SQLに関してまだまだ経験が足りていませんので、これからも知識を深めていけるようにしていきたいです。