はじめに
明けましておめでとうございます。本年もどうぞよろしくお願いいたします。
新年一発目のチャレンジとして、LINEボットから呼び出せるKendra+BedrockのRAGアプリを作ってみました。
参考にした記事
参考記事①
LINEボットからBedrockを呼び出せるようなコードが配布されていました。
めっちゃありがたい。。
参考、というかガッツリ利用させていただきました。
@moritalous さん、ありがとうございます!!
参考記事②
上記のコードにKendraとの連携部分を追記しました、というのがこの記事の内容なんですが
Kendraとの連携部分の記述は、以下の記事を参考にさせていただきました。
やったこと
以下について、それぞれ記載します。
- コーディング
- LINE Messaging APIの設定
- Bedrockの設定
- Kendraの設定
- AWS SAM(AWS Serverless Application Model)セットアップ
- AWS SAMでビルド・デプロイ
- Webhook URLの設定
コーディング
上記の記事を参考に、以下のようなコードを書きました。
※普段はコーディングを全くしないので、コーディングのお作法的なところが分かっておらず、改善点は多いかと思います。。
よろしければ、コメント欄にてご指摘いただけますと幸いです。
import os
import json
import boto3
from langchain.chat_models import BedrockChat
from langchain.memory.chat_message_histories import DynamoDBChatMessageHistory
from langchain.memory import ConversationBufferWindowMemory
from langchain.chains import ConversationChain
from linebot.v3 import (WebhookHandler)
from linebot.v3.exceptions import (InvalidSignatureError)
from linebot.v3.messaging import (
Configuration,
ApiClient,
MessagingApi,
ReplyMessageRequest,
TextMessage
)
from linebot.v3.webhooks import (MessageEvent,TextMessageContent)
LINE_CHANNEL_ACCESS_TOKEN = os.getenv('LINE_CHANNEL_ACCESS_TOKEN')
LINE_CHANNEL_SECRET = os.getenv('LINE_CHANNEL_SECRET')
NUM_OF_HISTORY = os.getenv('NUM_OF_HISTORY', 10)
FOUNDATION_MODEL = os.getenv('FOUNDATION_MODEL')
DYNAMODB_TABLE_NAME = os.getenv('DYNAMODB_TABLE_NAME')
# Amazon Kendra向け
KENDRA_INDEX_ID = os.getenv('KENDRA_INDEX_ID')
line_configuration = Configuration(access_token=LINE_CHANNEL_ACCESS_TOKEN)
line_handler = WebhookHandler(channel_secret=LINE_CHANNEL_SECRET)
# LLM定義(Bedrockを利用)
llm = BedrockChat(
model_id=FOUNDATION_MODEL,
model_kwargs={
"max_tokens_to_sample": 4096
},
client=boto3.client('bedrock-runtime')
)
@line_handler.add(MessageEvent, message=TextMessageContent)
def handle_message(event: MessageEvent):
print(event)
user_id = event.source.user_id
text = make_prompt(input=event.message.text)
response = conversation(input=text, session_id=user_id)
with ApiClient(line_configuration) as api_client:
line_bot_api = MessagingApi(api_client)
line_bot_api.reply_message_with_http_info(
ReplyMessageRequest(
reply_token=event.reply_token,
messages=[TextMessage(text=response)]
)
)
# プロンプトを作る
def make_prompt(input):
user_prompt = input
index_id = KENDRA_INDEX_ID
prompt = f"""\n\nHuman:
あなたは企業のシステム開発部の担当者で、AWSの専門家です。
参考情報(<reference>)をもとに、ルール(<rules>)に基づいて、質問(question)に適切に答えてください。
## 回答を生成する際に考慮すべき基本ルール
<rule>
### 日本語の文法について
誤字・脱字がなく、日本語の文法として正しい文章であること。
句読点を適切に使用すること。
助詞を正確に使用すること。
### ハルシネーション対策
答えを知っているか、あるいは十分な推測ができる場合のみ、質問に回答すること。
明確な回答ができない場合は、システム担当者に問い合わせるように案内すること。
### Kendra利用
Kendraからの情報を使って回答を生成するときは、参考にしたドキュメント名とそのリンク(URL)を、回答の最後に案内すること。
</rule>
## 質問
<question>
{user_prompt}
</question>
## 参考情報
<reference>
{get_retrieval_result(user_prompt,index_id)}
</reference>
Assistant:
"""
return prompt
# Kendraで検索
def get_retrieval_result(query_text,index_id):
kendra = boto3.client('kendra')
response = kendra.retrieve(
QueryText=query_text,
IndexId=index_id,
# 日本語で登録されているドキュメントを対象に検索
AttributeFilter={
"EqualsTo": {
"Key": "_language_code",
"Value": {"StringValue": "ja"},
},
},
)
# Kendraの応答から最初の5つの結果を抽出
results = response['ResultItems'][:5] if response['ResultItems'] else []
extracted_results = []
for item in results:
content = item.get('Content')
document_uri = item.get('DocumentURI')
extracted_results.append({
'Content': content,
'DocumentURI': document_uri,
})
print("Kendra extracted_results:" + json.dumps(extracted_results, ensure_ascii=False))
return extracted_results
# LangChainの処理
def conversation(input: str, session_id: str, num_of_history: int = NUM_OF_HISTORY):
message_history = DynamoDBChatMessageHistory(
table_name=DYNAMODB_TABLE_NAME,
session_id=session_id,
)
memory = ConversationBufferWindowMemory(
memory_key='history',
chat_memory=message_history,
return_messages=True,
k=num_of_history
)
conversation = ConversationChain(
llm=llm,
verbose=True,
memory=memory
)
return conversation.predict(input=input)
def lambda_handler(event, context):
print(event)
# get X-Line-Signature header value
signature = event['headers']['x-line-signature']
# get request body as text
body = event['body']
line_handler.handle(body,signature)
return {
'statusCode': 200,
'body': 'OK'
}
必要なライブラリを記述したrequirements.txtもあわせて作っておきます。
boto3==1.28.57
langchain==0.0.353
line-bot-sdk==3.5.0
LINE Messaging APIの設定
参考記事①で案内されている手順の通り、LINE Messaging APIの設定を行いました。
- LINE Messaging APIの設定
i. LINE Developersアカウントを作成します。
ii. こちらを参考にチャンネルを作成します。
iii. チャンネルシークレットと長期のチャネルアクセストークンを取得します。
Bedrockの設定
参考記事②で案内されている手順の通り、BedrockでClaudeを使えるようにします。
Claude2.1が東京リージョンでも利用できるようになったので、私は東京リージョンで検証を行いました。
Kendraの設定
以下の記事を参考に、Kendraでインデックスを作成し、データソースを登録しました。
データソースにはS3バケットを設定し、オリジナルのFAQ一覧(Excelファイル)を格納しました。
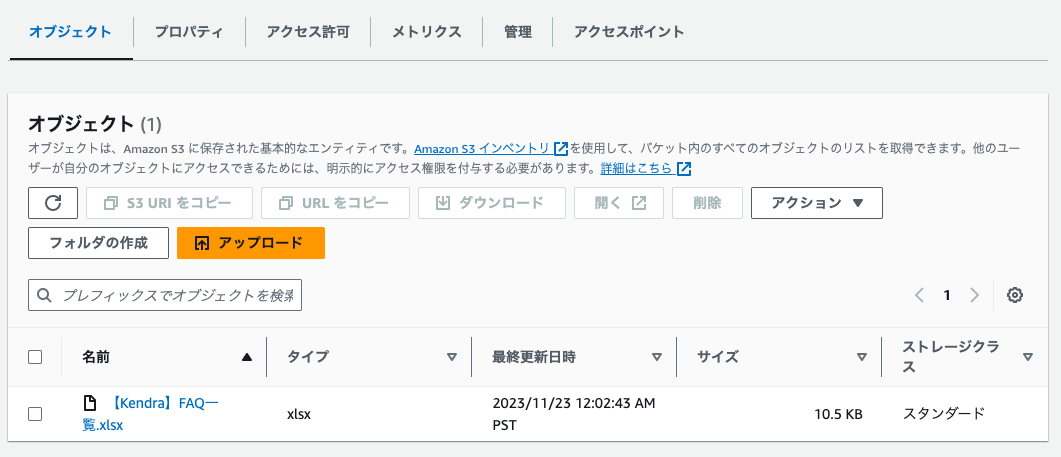
FAQ一覧の内容はこんな感じ。

※過去記事で使ったリソースの使い回しですw
AWS SAMセットアップ
今回はAWS SAMを利用してアプリケーションのビルド・デプロイを行います。
とはいえ、今までSAMを使ったことがなかったので、セットアップからのスタート。。
以下の記事を参考に、SAMを利用するための環境を整えました。
※AWS CLIのプロファイルの作成を忘れずに!
次に、こんな感じにディレクトリとファイルを作りました。
bedrock-line-chat-main
├── __init__.py
├── template.yaml
└── line_bot
├── __init__.py
├── app.py
└── requirements.txt
app.py と requirements.txt は上記の通り。
template.yaml は以下の通りです。
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
bedrock-line-chat
Parameters:
LineChannelAccessToken:
Type: String
LineChannelSecret:
Type: String
NumOfHistory:
Type: String
Default: '10'
FoundationModel:
Type: String
AllowedValues:
- anthropic.claude-v2:1
- anthropic.claude-v2
- anthropic.claude-v1
- anthropic.claude-instant-v1
Default: anthropic.claude-v2:1
KendraIndexId:
Type: String
Globals:
Function:
Timeout: 120
MemorySize: 512
Resources:
LineBotFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: line_bot/
Handler: app.lambda_handler
Runtime: python3.11
Architectures:
- x86_64
FunctionUrlConfig:
AuthType: NONE
Environment:
Variables:
LINE_CHANNEL_ACCESS_TOKEN: !Ref LineChannelAccessToken
LINE_CHANNEL_SECRET: !Ref LineChannelSecret
NUM_OF_HISTORY: !Ref NumOfHistory
FOUNDATION_MODEL: !Ref FoundationModel
DYNAMODB_TABLE_NAME: !Ref DynamoDBTable
KENDRA_INDEX_ID: !Ref KendraIndexId
Role: !GetAtt LineBotFunctionRole.Arn
Connectors:
DynamoDBConnector:
Properties:
Destination:
Id: DynamoDBTable
Permissions:
- Read
- Write
LineBotFunctionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
- arn:aws:iam::aws:policy/AmazonKendraFullAccess
Policies:
- PolicyName: LineBotFunctionRolePolicy0
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action: 'bedrock:*'
Resource: '*'
DynamoDBTable:
Type: AWS::DynamoDB::Table
Properties:
AttributeDefinitions:
- AttributeName: SessionId
AttributeType: S
KeySchema:
- AttributeName: SessionId
KeyType: HASH
BillingMode: PAY_PER_REQUEST
Outputs:
FunctionUrl:
Value:
Fn::GetAtt: LineBotFunctionUrl.FunctionUrl
AWS SAMでビルド・デプロイ
bedrock-line-chat-main ディレクトリにcdして、sam buildコマンドでビルドします。
$ pwd
/bedrock-line-chat-main/
$ sam build
Building codeuri:
/bedrock-line-chat-main/line_bot runtime:
python3.11 metadata: {} architecture: x86_64 functions: LineBotFunction
Running PythonPipBuilder:ResolveDependencies
Running PythonPipBuilder:CopySource
Build Succeeded
Built Artifacts : .aws-sam/build
Built Template : .aws-sam/build/template.yaml
Commands you can use next
=========================
[*] Validate SAM template: sam validate
[*] Invoke Function: sam local invoke
[*] Test Function in the Cloud: sam sync --stack-name {{stack-name}} --watch
[*] Deploy: sam deploy --guided
ビルドできました。
めっちゃ簡単ですね!!すごい!!
続いて sam deploy --guidedコマンドでデプロイします。
各種パラメータをインタラクティブに指定でき、いい感じにデプロイしてくれます。
$ sam deploy --guided
Configuring SAM deploy
======================
Looking for config file [samconfig.toml] : Not found
Setting default arguments for 'sam deploy'
=========================================
Stack Name [sam-app]: ※任意のCloudFormationスタック名※(デフォルト:sam-app)
AWS Region [us-east-1]: ※リソースを作りたいリージョン(デフォルト:us-east-1)※
Parameter LineChannelAccessToken []: ※LINEのチャネルアクセストークンの値※
Parameter LineChannelSecret []: ※LINEのチャネルシークレット※
Parameter NumOfHistory [10]: ※チャット履歴の件数(デフォルト:10)※
Parameter FoundationModel [anthropic.claude-v2:1]: ※利用したいモデル(デフォルト:anthropic.claude-v2:1)※
Parameter KendraIndexId []: ※KendraのインデックスID※
他にもAllow SAM CLI IAM role creation [Y/n]など聞かれるので、y/nで答えていきます。
参考記事①では以下の通り案内されているので、ここでもそれに従います。
Webhookのリクエストを認証なしの関数URLで受信する設計にしているため、ウィザードの途中で
LineBotFunction Function Url has no authentication. Is this okay? [y/N]と聞かれますので、Yで回答する必要があります。
入力が終わると、自動でCloudFormationスタックの作成が走ります。
完了すると、Successfully created/updated stack - (指定したスタック名) in (指定したリージョン)と表示されます。
なお、今回はFoundationModelでanthropic.claude-v2:1を選択しました。
Webhook URLの設定
最後に、Lambdaの関数URLのURLをWebhook URLとしてLINE Messaging APIに設定したら完成です。
Webhook URLの設定手順は、以下のページで案内されています。
これで完成!
動かしてみた
Kendraのデータソースの内容を踏まえた回答を試す
FAQ一覧で記載のある、ALBへの証明書の登録フローについて質問すると、ちゃんとFAQ一覧の内容を踏まえた回答を返してくれました。
参考文書として、FAQ一覧のファイル名とリンク(S3上のオブジェクトURL)も案内されています。
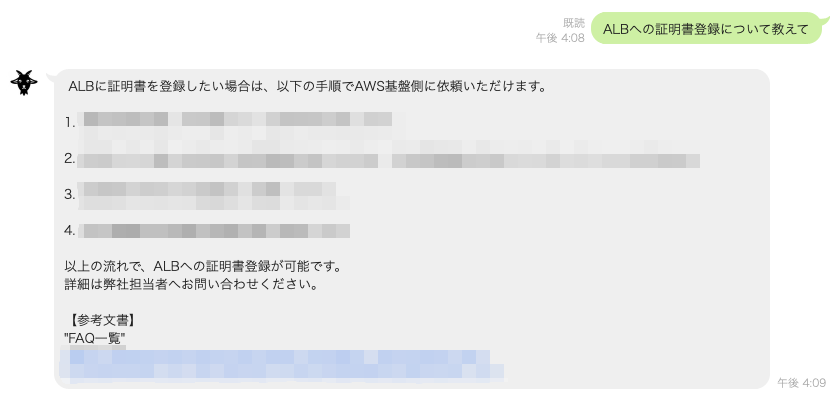
惜しいのは、参考文書として記載されているファイル名。
S3に配置したファイルの名前は【Kendra】FAQ一覧.xlsxでしたが、冒頭の【Kendra】とファイル拡張子.xlsxは無視されているようです。
プロンプトの書き方で改善できると思いますが、まあ今回は「分かればヨシ」ということで。。
データソースの内容に基づかない、Claude自身からの回答を試す
FAQ一覧で何の記載もないサービスについて質問すると、Claude自身が持っている情報から回答を返してくれました。
参考文書の案内もなく、いい感じ。
意地悪な質問をしてみる
FAQ一覧に記載されてそうで実は記載がない、というような内容について質問してみます。
FAQ一覧には、 "ALBへの証明書の登録" については記載されていますが、ALBの機能に関する内容の記載はありません。
ALBについてのふわっとした質問を投げて、変にFAQ一覧を参照したような回答が返ってこないか、確認します。

大丈夫そう!
Claude 2.1 すごいな。。
過去のチャットの内容を踏まえた質問をしてみる
NumOfHistoryで指定した数字の分だけチャットの履歴が保管されます。
チャットの履歴の内容を踏まえたやりとりができるか確認するため、以下2つの質問を連続して投げてみました。
- Amazon RDSについて、簡潔に説明して下さい
- 他の特徴はありますか
※言外に、"1の質問に対する回答で触れられていない"、"RDSの特徴"を質問する

ちゃんと文脈を捉えた回答を返してくれました。
※この辺りの機能に関しては、参考記事①で公開されているアプリで既に実装されていた部分になります。
改善点
プロンプトの改善
今回のプロンプト作成にあたっては、以下の記事を参考にしました。
よりClaude2.1にあったプロンプト、得たい回答を得られるようなプロンプトを研究し、回答精度の向上を目指したいです。
LangChainの機能の活用
今回は、Kendraの問い合わせ結果をプロンプトにそのまま突っ込んでLLM(Claude 2.1)に渡すという、強引な技を使いました。
せっかくコードの中でLangChainを使っていますし、LangChainのretrieverを利用すれば、もう少しスマートな書き方ができるんじゃないかと考えています。
実は、最初はretrieverを使った方法でやろうとしたんですが、、
様々なエラーが発生し、試行錯誤の結果、上記の強引なコードに辿り着きました。
もう少し勉強してリベンジしたいです。
以下、参考になりそうな記事(備忘)。
レスポンス時間の改善
LINEで質問を投げてから回答が返ってくるまでに10秒くらいかかります。
NWなど、様々な要因があるとは思いますが、アプリとしてのレスポンス改善は目指していきたいです。
参考記事①で公開されているアプリをそのまま動かすと、ここまでの遅延はなかったため、Kendra関連の処理による影響が大きいと考えています。
Kendraの検索精度向上がどこまでレスポンスの改善に寄与するかは不透明ですが、検証はしてみたいと思います。
また、Claude V2よりもClaude Instant V1の方がレスポンスまでの時間が短い、という情報もありました。
こちらも検証してみたいと思います。
終わりに
KendraとBedrockを利用して遊んでみました。
学びが多く、今後のモチベーションになるような機会でした。
LangChain分からんすぎる、、
勉強します。
勉強して、retrieverを使おうとした時に出てきたこのエラーの原因を明らかにするんや、、!
ValidationError: 1 validation error for AIMessage
content
str type expected (type=type_error.str)
最後までお目通しいただき、ありがとうございました。