はじめに
お疲れ様です。yuki_inkです。
社内文書の内容を踏まえた回答をしてくれるチャットbotが欲しい!
と言っていたら「KendraとBedrockの組み合わせでRAG作れば?」という助言をいただき、時流に乗ってやってみようと思い立ちました。
事前知識も何もない状態で、なんとなく想像していたイメージはこう。
※全然違うので参考にしないでください
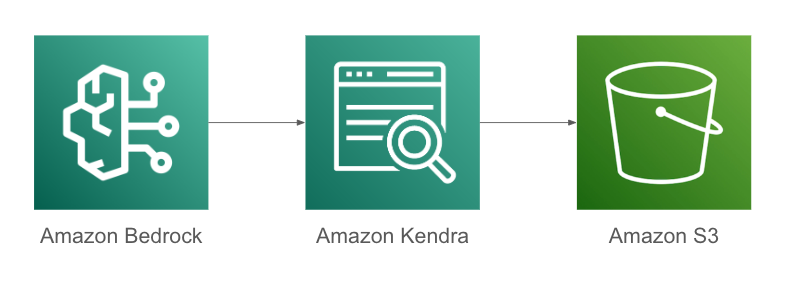
- ユーザからのリクエストをBedrockが受ける
- Bedrockの裏にKendraがいて(?)、社内文書に関するリクエストが来たときはBedrockがKendraにいい感じに(?)その内容を問い合わせに行く
- 問い合わせをもらったKendraは、S3などのデータソースに格納されたファイルに検索をかけにいき、得られた内容をいい感じに(?)問い合わせ元(Bedrock)に返す
※Kendra自体はデータを持たないと思っていた
実際にKendraとBedrockを触ってみると、実態は上記のイメージと全然違うことがわかったので、この記事でその気づきをまとめます。
結論
実態はこうなるみたいです。
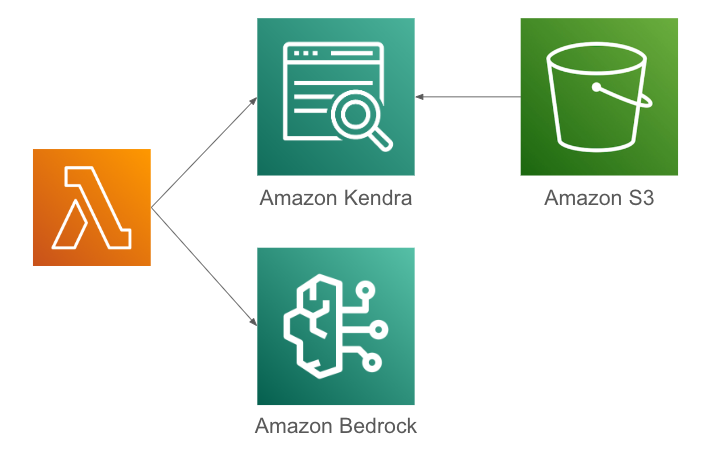
- 事前にKendraに「Index」を作成し、データソースからデータを同期
- ユーザはRAGアプリケーション(図ではLambda)に検索のリクエストを投げ、アプリケーションはその内容をもとにKendraに検索をかけにいく
- KendraはIndexに登録された情報をもとに検索を行い、検索結果を返す
- RAGアプリケーションはKendraから返された検索結果をBedrockに投げ、Bedrockが生成した回答文をユーザに返す
Kendraはデータを全然持つし、Bedrockの裏にKendraがいるわけでもない。
そもそもBedrockとKendraをいい感じに連携するには自力でアプリケーションを書いて、その辺の処理をコントロールする必要がある。
BedrockのPlaygroundsから遊べるのはあくまでBedrockの機能のみであって、Kendraとの連携を行うことはできない。
※「Bedrock」という言葉と各種基盤モデルを分けずに語っていますが悪しからず、、
やったことと感想
1. Kendraを触ってみた
以下の記事を参考に、KendraでIndexを作成し、データソースを登録しました。
データソースにはS3バケットを設定し、オリジナルのFAQ一覧(Excelファイル)を格納しました。
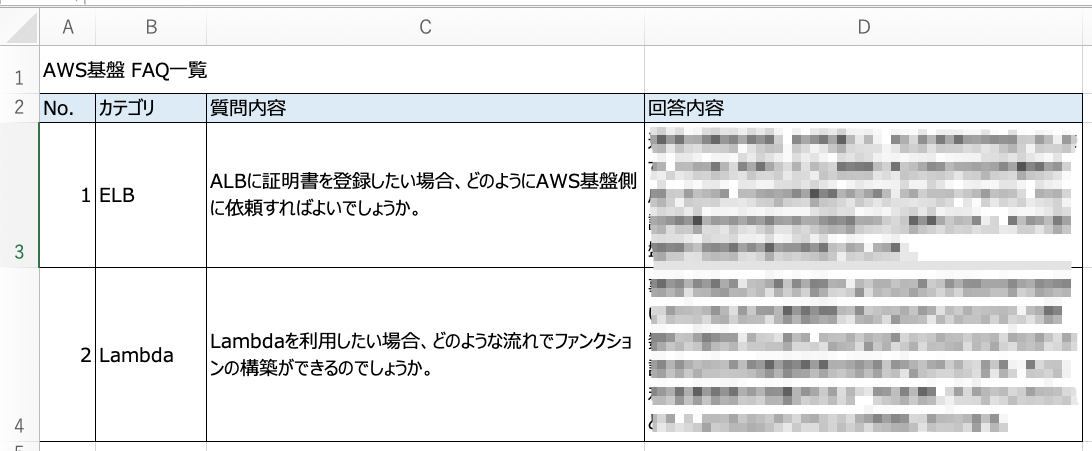
FAQ一覧の内容はこんな感じ。
Kendra単体での動作を確認するため、KendraのSearch consoleで検索をかけてみたところ、確かにFAQの中身を見て、該当の箇所は引っ張ってきているようだが、
あくまでFAQのファイル自体が案内されており、質問に対する的確な回答を返してくれているとは言えない。
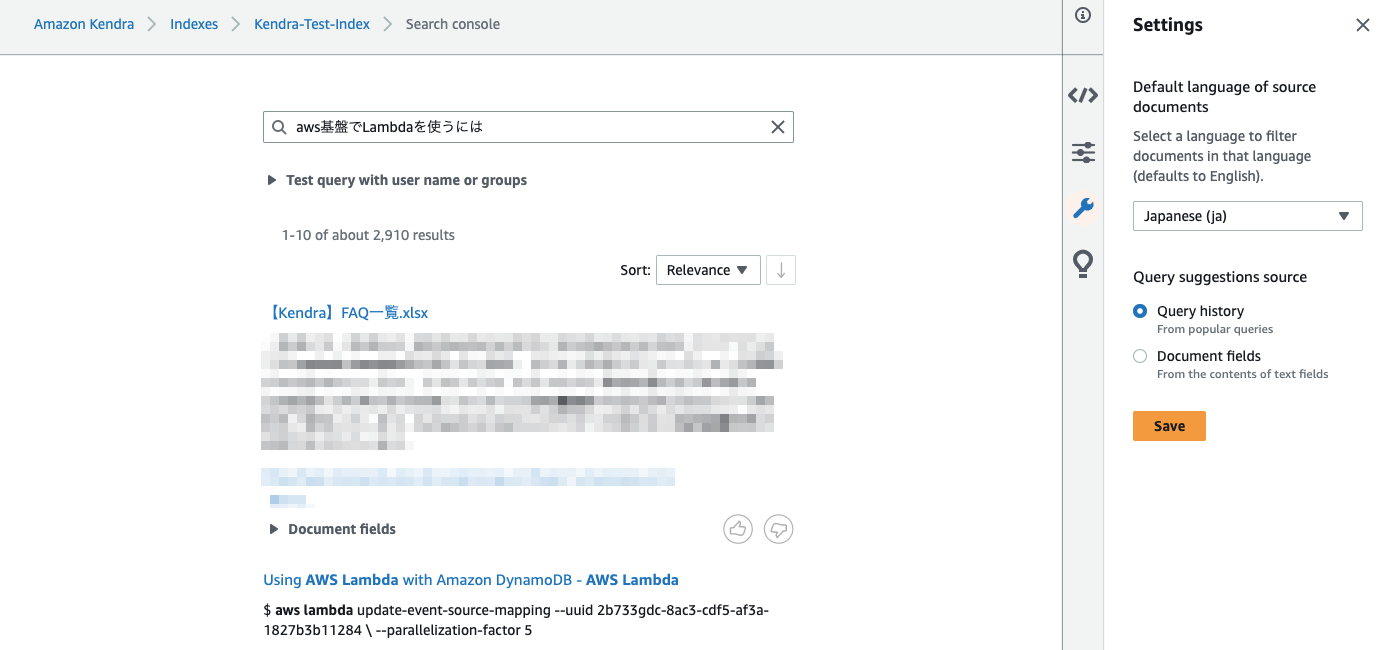
何か質問をしても、「この回答らしきものはこのファイルに書いてあるぜ!」とFAQのExcelファイルまるごと投げられても困るのである。
違う、そうじゃない、感。
そのファイルの中から問いの答えを探して、その答えだけを教えて欲しい。
他の感想としてはデータソースの登録、かなり時間がかかりますね。
特にIndexingの時間が長かった、、
FAQ一覧のExcelファイル1つ読み込むのに、5時間くらいかかりました。
私が作業した時に、たまたま遅かっただけかもですが、、
Lambdaを書いてみた
と、Kendra単体の機能の限界を感じたところで、Lambdaでアプリ部分を作ってみました。
と言っても、以下のクラメソ様の記事を参考にしただけです。
クラメソ様、いつもありがとうございます!!!
私の担当する業務では東京リージョンが第一候補となるので、東京リージョンでやってみました。
東京リージョンでClaudeを使おうと思ったらClaude Instant v1.2しか利用できないため、それを利用。
クラメソ様の記事からコピーペースト&上記変更を加えて以下のソースコードが完成。
import boto3
import json
kendra = boto3.client('kendra')
bedrock = boto3.client(service_name='bedrock-runtime', region_name="ap-northeast-1")
def get_retrieval_result(query_text,index_id):
response = kendra.retrieve(
QueryText=query_text,
IndexId=index_id,
AttributeFilter={
"EqualsTo": {
"Key": "_language_code",
"Value": {"StringValue": "ja"},
},
},
)
# Kendra の応答から最初の5つの結果を抽出
results = response['ResultItems'][:5] if response['ResultItems'] else []
extracted_results = []
for item in results:
content = item.get('Content')
document_uri = item.get('DocumentURI')
extracted_results.append({
'Content': content,
'DocumentURI': document_uri,
})
print("Kendra extracted_results:" + json.dumps(extracted_results, ensure_ascii=False))
return extracted_results
def lambda_handler(event, context):
user_prompt = event.get('user_prompt')
# Kendra インデックス ID に置き換えてください
index_id = '<<index ID>>'
prompt = f"""\n\nHuman:
[参考]情報をもとに[質問]に適切に答えてください。
[質問]
{user_prompt}
[参考]
{get_retrieval_result(user_prompt,index_id)}
Assistant:
"""
# 各種パラメーターの指定
modelId = 'anthropic.claude-instant-v1'
# modelId = 'anthropic.claude-v2'
accept = 'application/json'
contentType = 'application/json'
body = json.dumps({
"prompt": prompt,
"max_tokens_to_sample":600,
})
response = bedrock.invoke_model(
modelId=modelId,
accept=accept,
contentType=contentType,
body=body
)
response_body = json.loads(response.get('body').read())
# print("Received response_body:" + json.dumps(response_body, ensure_ascii=False))
return response_body.get('completion')
Lambda関数の構築だけでなく、以下のような対応も行います。
- IAMロールの権限の設定
- Lambdaのタイムアウト時間を伸ばす
- Lambdaレイヤーを作成して最新のBoto3を使えるようにする
以下の記事を参考にしました。
クラメソ様、いつもありがとうございます!!!(2回目)
以上が終わり、早速テスト。
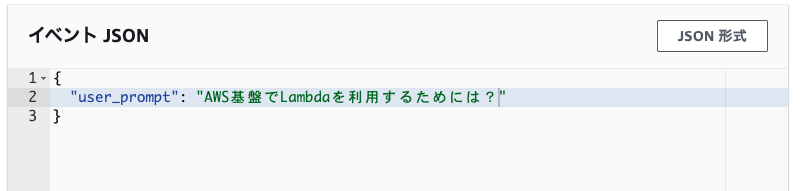
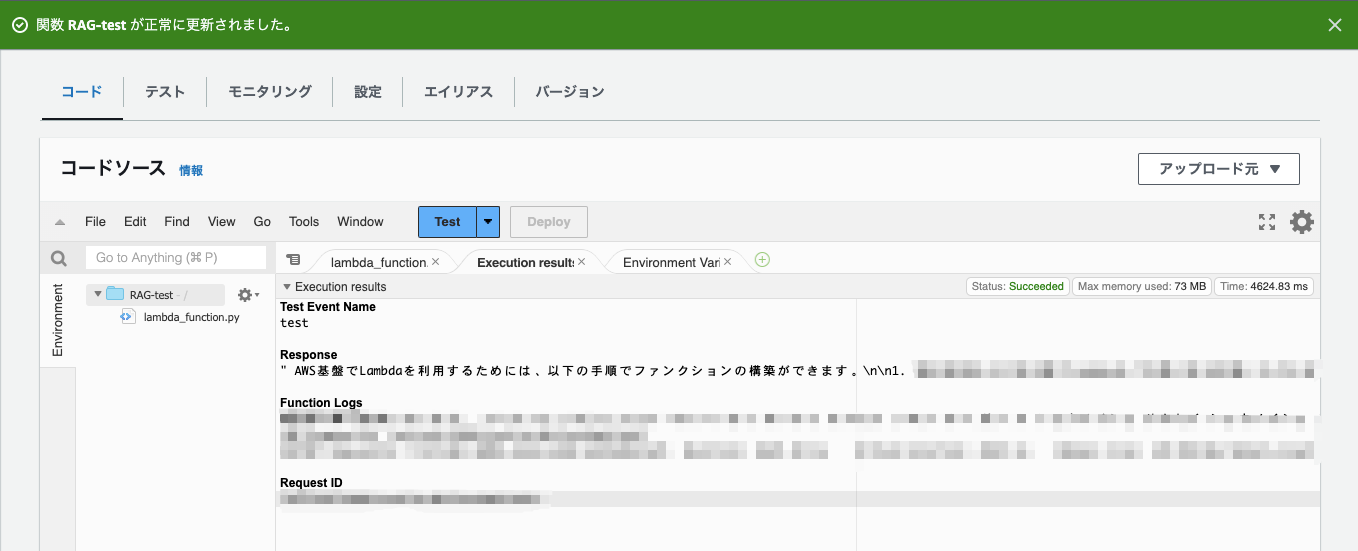
無事、FAQの内容を踏まえた簡潔な回答が返ってきました!!やったぁ
終わりに
今の流行に追いつくべく、KendraとBedrockを触ってみました。
今回作ったLambdaの前段にAPI Gatewayをおけば、色々な場面に展開できそうです。
とはいえ、今回参考にさせていただいた記事にもありましたが、業務利用に向けては検討しなければならないポイントも残っています。
ただし、Lambdaコードはあくまでも参考例とご認識下さい。実際の環境で使用する際には、「API呼び出しのレスポンスチェック」や「適切なエラーハンドリング」、「機密情報はハードコーディングしない」などを行う必要があります。
このあたりは別途考えてみたいと思います。
最近よく見るKendra・Bedrockの組み合わせですが、実際に触る前と後ではサービス・構成に対する理解に大きな差があり、今回自分の手でやってみてよかったと心から思いました。
協力してくれた同僚諸君ありがとう!!