0. はじめに
教師あり学習をするときにデータが不均衡なことってよくありますよね...
むしろ、均衡かつ多量に確保できるケースの方が少ないと思います。
今回は、そんなときのために imbalanced-learn という不均衡データのリサンプリングに役立ちそうなライブラリを紹介します。
主に、以下の記事を参考にさせて頂きました。
- imbalanced-learnで不均衡なデータのunder-sampling/over-samplingを行う
- Pythonでデータ分析:imbalanced-learnで不均衡データのサンプリングを行う
公式ドキュメンテーションはこちらです。
1. imbalanced-learn のインストール
Install and contribution に従ってインストールしていきます。
pip install -U imbalanced-learn
でインストールします。
ちなみに、2020年3月時点では以下のライブラリに対して次のような条件があるようです。
- numpy (>=1.11)
- scipy (>=0.17)
- scikit-learn (>=0.21)
2. 擬似的なデータを用意する
今回使用する擬似的なデータを用意します。
既にデータがある場合は飛ばし読みしてください。
make_classificationという関数を使用しています。
import pandas as pd
from sklearn.datasets import make_classification
df = make_classification(n_samples=5000, n_features=10, n_informative=2,
n_redundant=0, n_repeated=0, n_classes=3,
n_clusters_per_class=1, weights=[0.01, 0.05, 0.94],
class_sep=0.8, random_state=0)
この df の中には2つの返り値がタプルで入ってます。
df[0] にはいわゆる X が入っていて、
df[1] にはいわゆる y が入っています。
ですので、以下のような操作でデータフレームに格納します。
df_raw = pd.DataFrame(df[0], columns = ['var1', 'var2', 'var3', 'var4', 'var5', 'var6', 'var7', 'var8', 'var9', 'var10'])
df_raw['Class'] = df[1]
df_raw.head()
これを X と y に分割します。
X = df_raw.iloc[:, 0:10]
y = df_raw['Class']
y.value_counts()
2 4674
1 261
0 65
Name: Class, dtype: int64
見ての通り、ラベル2のデータを極端に多く用意しています。
これで擬似データの用意は完了です。
3. train_test_split でデータを分割する
先ほど用意したデータフレームを train_test_split を用いて分割します。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 71, stratify=y)
y_train.value_counts()
2 3272
1 183
0 45
Name: Class, dtype: int64
train と test に分割したあとの train データの各ラベル毎のデータ数はこの通りです。
ここで、train_test_split の引数 stratify に y を指定することで 層化抽出 をすることができます。
4. RandomUnderSampler でアンダーサンプリングを行う
ようやく本題です。
RandomUnderSampler でアンダーサンプリングをします。
APIはこちらです。
引数 sampling_strategy について説明します。
この引数でサンプリングの際の各クラスの比率などを決めることができます。
以前のバージョンでは ratio という引数だったようですが、バージョン0.6から sampling_strategy に変更されたようです。
この引数には、おもに float 、辞書型を与えることが可能です。
float の場合は、少数派のクラス÷多数派のクラスを指定してください。
ただし、2ラベル問題でしか適用できません。
辞書型の場合は以下のように各クラスのサンプルサイズを渡してください。
from imblearn.under_sampling import RandomUnderSampler
positive_count_train = y_train.value_counts()[0]
strategy = {0:positive_count_train, 1:positive_count_train*2, 2:positive_count_train*5}
rus = RandomUnderSampler(random_state=0, sampling_strategy = strategy)
X_resampled, y_resampled = rus.fit_resample(X_train, y_train)
y_resampled.value_counts()
Using TensorFlow backend.
2 225
1 90
0 45
Name: Class, dtype: int64
これでアンダーサンプリングをすることができました。
6. おまけ
せっかくなので、何らかのモデルで分類してみたいと思います。
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
model = LogisticRegression()
model.fit(X_resampled, y_resampled)
y_pred = model.predict(X_test)
print('Accuracy(test) : %.5f' %accuracy_score(y_test, y_pred))
Accuracy(test) : 0.97533
混同行列をヒートマップで出力してみます。
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm)
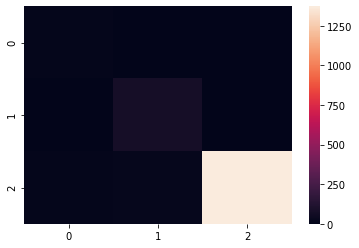
テストデータの側が不均衡だったので、ヒートマップも見づらくなってしまいました...
7. まとめ
今回はアンダーサンプリングに挑戦してみました。
この記事を書きながらいろいろ調べていると、アンダーサンプリング・オーバーサンプリングの中にもいろいろな手法があることが分かりました。
SMOTEとか面白そうなので勉強してみようと思います。
記事ネタ、コメントなど随時募集中です。