はじめに
勉強をしていると、海外ではものすごい有名な教科書だけど、翻訳されていないので勉強のハードルがとても高い、ということありませんか?
日々そのように感じていたのですが、そんな折に見かけた記事がこちら。
試してみると、今のAIってこんな汚い文章も正確に文字抽出できるの?! と非常に驚きました。
そして LLMは翻訳とも相性が良いし、 これはOCR→翻訳の流れが簡単にできるのでは、と考えGeminiと相談することで、
- 無料で
- Gemini 3.0 Flashを使って
- 英語のpdfを読み取って
- 日本語に翻訳して
- 数式はきれいに表示して
- 図表も抽出して
- マークダウン形式で出力する
Pythonプログラムを作ることができました。
出版できるほど完璧ではないものの、pdfを指定して2回プログラムを実行するだけで、十分実用には耐えられるものが出力されました。
誰でも使えるようにプログラムを公開するので、概要やプログラムの説明をしていきます。
特にプロンプトやノウハウについても詳しく説明していきます。
出来上がったもの
忙しい人のために、こちらが翻訳前後の比較です。
文章も専門用語含め適切に翻訳され、図の範囲もおおむねよし、数式もきれいに変換されています。
個人が勉強に使う分には十分なものが出来上がったのでないでしょうか。
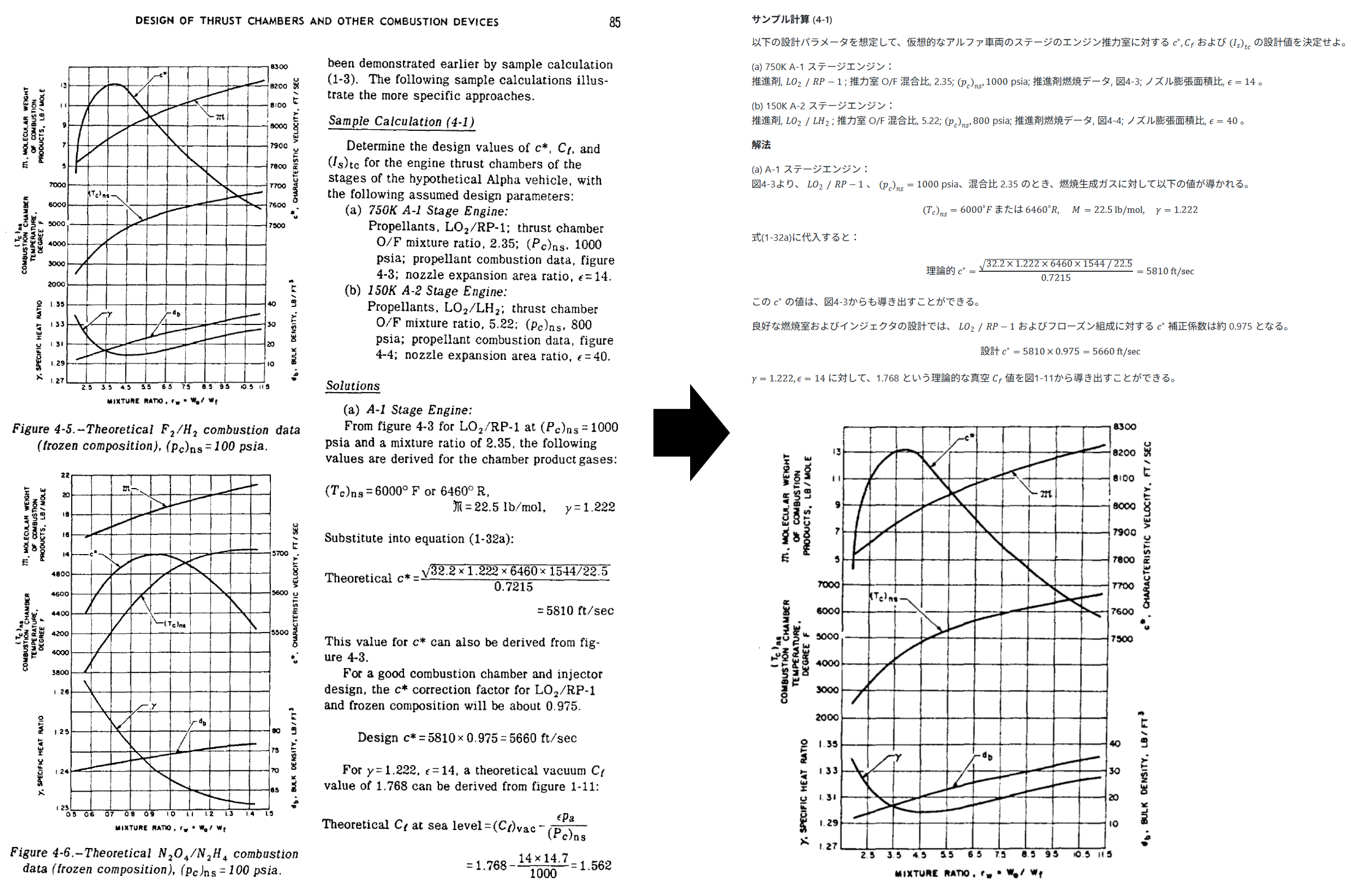
今回は、NASAが公開しているロケット設計の伝説的教科書である、NASA sp125 Design of Liquid Propellant Rocket Engines Second Editionを変換してみました。
5ページほど翻訳しましたが、全体を比較したい場合は、以下を見てください。
元のファイル:
https://github.com/yuki-2000/OCRwithGemini_release/blob/main/NASA_sp125_Chapter4.pdf
出力ファイル:
https://github.com/yuki-2000/OCRwithGemini_release/blob/main/output.md
詳細の比較
見出し
章番号に応じて適切なマークダウンの見出しが出力されています。

スタイル
番号を振った箇条書きも再現されています。

翻訳
元の英語の文章と変換後の日本語の文章ですが、
省略されることなく翻訳されています。
While the proud designers of the various subsystems
of a rocket engine each consider their
product as "the heart of the engine, .. the thrust
chamber assembly undeniably embodies the essence
of rocket propulsion: the acceleration and
ejection of matter, the reaction of which imparts
the propulsive force to the vehicle. The designer's
goal is essentially to accomplish this with
a device of maximum performance, stability and
durability, and of minimum size, weight, and
cost.
ロケットエンジンの様々なサブシステムの誇り高き設計者たちは、
自らの製品を「エンジンの心臓部」と考えているが、
推力室アセンブリがロケット推進の本質を体現していることは否定できない。
それは物質の加速と噴射であり、その反作用が車両に推進力を与えるのである。
設計者の目標は、本質的にこれを、最高の性能、安定性、耐久性を備え、
最小のサイズ、重量、コストで実現することである。
数式(文字)
一か所wの大文字と小文字が間違っていますが、それ以外は下付き文字含め正確に抽出されています。文字と単位の斜体か否かも正確です。

数式(数字)
具体的な数字が入った計算部分も完璧です。

図の切り抜き
図の切り抜き範囲もGeminiに出力してもらったのですが、
少しキャプションが見切れている部分はありましたが、
今回の文書ではすべての図が切り抜かれていました。

プログラムの解説
プログラムはこちらに保存しています。
忙しい人向けに、すぐに自分のpdfで試したい場合は、以下の部分を適切に変えて、1_OCR_translate.py→2_image_extract.pyの順番で実行してください。3_md2html.pyはおまけです。
api_key="YOUR API KEY"
upload_file = "./NASA_sp125_Chapter4.pdf"
pdf_file = "./NASA_sp125_Chapter4.pdf"
OCRプログラムの流れ
プログラムの流れとして、
- apiでGeminiにpdfを送り、翻訳語のマークダウン文書と、図表の座標をもらう
- マークダウン文法の検査及び修正
- 図表の座標をもとにローカルでpythonを使って画像を抽出して保存する
- ローカル、もしくはgithubのアクションでマークダウンファイルをhtmlに変換する(必要とあらば)
という3段構成のプログラムとなっています。
特に、構造化出力を用いて画像の座標を厳密なjson形式で出力させた点、プロンプトの工夫が今回の重要な成果かと考えています。
ノウハウも含め、それぞれについて説明していきます。
Geminiのapiキーの準備【無料】
Google様は非常に素晴らしく、gemini-3-flash-previewを無料で使わせてくれます。
google ai studioを使用して、apiキーを取得しましょう。
よくある、無料だけどクレジットカードの登録が必要、などなしで簡単に無料で始められます。
ライブラリのインストール
以下のライブラリが必要となります。
- Geminiを使用するための
google-genai - 構造化出力を使用するための
pydantic - pdfから画像を切り出すための
PyMuPDF - マークダウンからhtmlに変換するための
pypandoc
文章と画像座標を出力てもらうための構造化出力
後から画像をプログラムでpdfから切り出したいため、厳密な構造の、座標データを含んだファイルが必要でした。
さらに、マークダウンに画像を埋め込みたいので、切り出した後のファイル名をマークダウン文書に含める必要もありました。
そこで、Geminiの構造化出力を使用し、マークダウンと座標のjsonファイルとして出力してもらうことにしました。
「どんな形式でデータを返してほしいか」を教えるために、Pydanticというライブラリを使います。これにより、AIの回答がプログラムで扱いやすいJSON形式になることが保証されます。
class FigureTableItem(BaseModel):
"""
ドキュメント内の図または表の情報を定義するモデル
"""
id: str = Field(description="図表の一意識別子(例: p1_fig1, p5_tab1)")
filename: str = Field(description="保存する際のファイル名(例: p1_fig_01.png)")
page_number: int = Field(description="1から始まるページ番号")
box_2d: List[int] = Field(
description="[ymin, xmin, ymax, xmax] の順で、0-1000の範囲で正規化された座標",
min_items=4,
max_items=4
)
type: Literal["figure", "table"] = Field(description="図(figure)か表(table)かの種別")
#caption: str = Field(description="図表の説明(キャプション)")
caption: str = Field(description="本文中の図表の番号(例: Fig. A6.3, Table A5.1)")
class DocumentExtractionResponse(BaseModel):
"""
Geminiからの最終的なレスポンス形式
"""
extractions: List[FigureTableItem] = Field(description="抽出された図表のリスト")
#content_markdown: str = Field(description="図表のリンク()を含む、Markdown形式の本文")
content_markdown: str = Field(description="図表のリンク()を含む、Markdown形式の本文")
[
{
"id": "p2_fig1",
"filename": "p2_fig_01.png",
"page_number": 2,
"box_2d": [
588,
86,
960,
480
],
"type": "figure",
"caption": "Figure 4-1.-Thrust chamber assembly."
},
{
"id": "p2_fig2",
"filename": "p2_fig_02.png",
"page_number": 2,
"box_2d": [
588,
510,
960,
910
],
"type": "figure",
"caption": "Figure 4-2.--Thrust chamber injector."
}
]
プロンプト
今回の一番の心臓部です。
ここを試行錯誤することで、出来が大きく変わります。
Geminiに相談しながら作りました。
もともとは英語の文書を抽出して一度保存してから、改めてそれをGeminiに送って日本語に翻訳するという流れを考えていました。
しかし、マークダウン構造やurlが壊れるのが嫌で、いきなり日本語で出力させています。
20260117更新
実際にOCRを進める中でプロンプトを大幅にアップデートしました。
詳しい考え方や説明は最後のノウハウの章で説明します。
最初のシンプルなプロンプトはこちら
prompt = """
あなたは高度な文書解析および翻訳の専門AIです。添付されたPDF(画像スキャン)を解析し、以下の指示に従って「1. 図表のJSONリスト」および「2. 日本語翻訳のMarkdownテキスト」の順で出力してください。
### 1. 処理の基本ルール
- **言語**: 英語から日本語へ翻訳してください。
- **読解順序**: ページ内のレイアウト(2段組など)を正確に認識し、人間が読む自然な順序でテキストを抽出してください。
- **欠落の禁止**: 文中のいかなるセクション、段落、一文も省略したり要約したりせず、全文を翻訳してください。
- **除外事項**: ページ番号、ヘッダー、フッターの翻訳・抽出は不要です。
### 2. **図と表の抽出リスト (JSON形式)**
- 文書内のすべての「図(Figure)」と「表(Table)」を特定してください。
- 図表番号がなく文章の行内に存在する「図(Figure)」と「表(Table)」も存在するので、すべて特定してください。
- 各図表の範囲は図表に加え、存在する場合は図表番号(例: Fig. A6.3, Table A5.1)がある部分まで含んでください。
- 各図表について、切り出すための座標(Bounding Box)を特定してください。
- 座標はPDFのページサイズに対する相対値として **0から1000の範囲(正規化座標)** で `[ymin, xmin, ymax, xmax]` の順に出力してください。
- `page_number` は 1 から始まるページ番号です。
- `filename` は `p1_fig_01.png`, `p5_table_01.png` のように`p[ページ番号]_[fig/table]_[連番].png`命名してください。
### 3. **ドキュメント内容 (Markdown形式)**
- 本文を日本語に翻訳し、Markdown形式で出力してください。
- 翻訳する際は以下のルールを必ず守ってください
***Markdown形式の維持**: すべてのMarkdownタグ(#、-、1.、>、|、[ ]など)はそのまま維持し、構造を崩さないでください。
***全文翻訳**: 文章の一部を省略したり、要約したりせず、すべての内容を正確に翻訳してください。
***専門用語**: 技術的な文脈で一般的に英語のまま使われる用語(例:Instance, Deploy, Repositoryなど)は、無理に訳さずカタカナ表記にするか、英語のままにしてください。
***トーン**: 自然で丁寧な技術文書のスタイル(だ・である調)で翻訳してください。
- Markdownのスタイルは以下のルールを守ってください。
*見出し(#)、箇条書き(-)、太字(**)を適切に使用し、視認性を高めてください。
*段落の区切りには必ず空行を1行入れてください。
*改行を行う場合は、行末に半角スペース2つを付与してください。
*マークダウンファイルの見やすさや、マークダウンタグの範囲を指定するためにも、適切に改行や空行、空白を入れください。
- 数式はtex形式でインラインもしくはブロック数式で表現し、以下のルールを守ってください。
*数式はtex形式で$マークを使って表現し、特殊文字と特殊記号は適切にバックスラッシュを使用してください。
*tex形式のインライン数式を表現する際は、`本文 $\tau$ 本文`というように数式の前後には半角スペースを入れ、`$`と中身の数式コマンドの間には空白文字を絶対に入れないでください。**正しい例**: `$\tau$`、`$x+y=z$‘、**悪い例**: `$ \tau $`、`$ x+y=z $`(これらは絶対に避けてください)
*tex形式のブロック数式を表現する際は、`本文\n\n$$\n\tau\n$$\n\n本文`というように数式の前後には改行を2つ入れ、数式中の$$で囲まれた数式コマンドの前後には改行を入れて空白文字は入れないでください。
*空白や改行はtexにおける数式コマンドが適切に機能するように配置してください。
*数式内の文字の順番は、元のPDFの順番のままで変えないでください。
- **重要:** 抽出リストで特定した図表がある位置には、対応する画像リンク `` を挿入してください。summerize this pdf in Japanse"
"""
prompt = """
あなたは高度な文書解析および翻訳の専門AIです。添付されたPDF(画像スキャン)を解析し、以下の指示に従って「1. 図表のJSONリスト」および「2. 日本語翻訳のMarkdownテキスト」の順で出力してください。
### 1. 処理の基本ルール
- **言語**: 英語から日本語へ翻訳してください。
- **読解順序**: ページ内のレイアウト(2段組など)を正確に認識し、人間が読む自然な順序でテキストを抽出してください。2段組の場合「左カラムの最上部から最下部まで」を完全に処理したあと、次に「右カラムの最上部」に移動して処理を継続してください。
- **欠落の禁止**: 文中のいかなるセクション、段落、一文も省略したり要約したりせず、全文を翻訳してください。
- **情報の完全性**: 特に大きな数式のブロック(積分、分数、行列などが含まれるもの)は、最も重要な情報です。 これらが連続する場合でも、一つ一つを独立した数式としてすべて書き出してください。「〜(以下同様の数式が続く)」といった要約は絶対に禁止します。
- **除外事項**: ページ番号、ヘッダー(章名のリピート)、フッターの翻訳・抽出は不要です。
- **JSON優先の原則**: 本文(Markdown)内に挿入する画像リンク  は、必ず「2. 図と表の抽出リスト (JSON形式)」に存在する filename のみを使用してください。JSONリストに含まれていない図表については、本文中に画像リンクを作成しないでください。
### 2. **図と表の抽出リスト (JSON形式)**
- 文書内のすべての「図(Figure)」と「表(Table)」を特定してください。
- 図表番号がなく文章の行内に存在する「図(Figure)」と「表(Table)」も存在するので、すべて特定してください。
- 各図表の範囲は図表に加え、存在する場合は図表番号(例: Fig. A6.3, Table A5.1)がある部分まで含んでください。
- 各図表について、切り出すための座標(Bounding Box)を特定してください。
- 座標はPDFのページサイズに対する相対値として **0から1000の範囲(正規化座標)** で `[ymin, xmin, ymax, xmax]` の順に出力してください。
- `page_number` は 1 から始まるページ番号です。
- `filename` は `p1_fig_01.png`, `p5_table_01.png` のように`p[ページ番号]_[fig/table]_[連番].png`命名してください。
### 3. **ドキュメント内容 (Markdown形式)**
- 本文を日本語に翻訳し、Markdown形式で出力してください。
- ページをまたいだ段落の継続を正しく認識し、不自然に見出しを挿入しないでください。
- 翻訳する際は以下のルールを必ず守ってください
***Markdown形式の維持**: すべてのMarkdownタグ(#、-、1.、>、|、[ ]など)はそのまま維持し、構造を崩さないでください。
***全文翻訳**: 文章の一部を省略したり、要約したりせず、すべての内容を正確に翻訳してください。
***専門用語**: 技術的な文脈で一般的に英語のまま使われる用語(例:Instance, Deploy, Repositoryなど)は、無理に訳さずカタカナ表記にするか、英語のままにしてください。
***トーン**: 自然で丁寧な技術文書のスタイル(だ・である調)で翻訳してください。
***見出しの階層化**:
- `# ` (H1): 「A5」や「Chapter 4」などの大見出し
- `## ` (H2): 「A5.1」などのピリオドが1つ含まれる中見出し
- `### ` (H3): 適切に使用してください。
- Markdownのスタイルは以下のルールを守ってください。
*見出し(#)、箇条書き(-)、太字(**)を適切に使用し、視認性を高めてください。
*段落の区切りには必ず空行を1行入れてください。
*改行を行う場合は、行末に半角スペース2つを付与してください。
*マークダウンファイルの見やすさや、マークダウンタグの範囲を指定するためにも、適切に改行や空行、空白を入れください。
- 数式はtex形式でインラインもしくはブロック数式で表現し、以下のルールを守ってください。
*数式はtex形式で$マークを使って表現し、特殊文字と特殊記号は適切にバックスラッシュを使用してください。
*tex形式のインライン数式を表現する際は、`本文 $\tau$ 本文`というように数式の前後には半角スペースを入れ、`$`と中身の数式コマンドの間には空白文字を絶対に入れないでください。**正しい例**: `$\tau$`、`$x+y=z$‘、**悪い例**: `$ \tau $`、`$ x+y=z $`(これらは絶対に避けてください)
*tex形式のブロック数式を表現する際は、`本文\n\n$$\n\tau\n$$\n\n本文`というように数式の前後には改行を2つ入れ、数式中の$$で囲まれた数式コマンドの前後には改行を入れて空白文字は入れないでください。
*空白や改行はtexにおける数式コマンドが適切に機能するように配置してください。
*数式内の文字の順番は、元のPDFの順番のままで変えないでください。
* 数式はすべて標準的なLaTeXコマンドを使用して記述してください。
* 分数は必ず \frac{分子}{分母} を使用してください。バックスラッシュを他の記号(矢印など)と誤認しないでください。
* u_x, u_y^2 などの下付き・上付き文字は、極めて小さい文字まで注意深く読み取り、省略せず _ および ^ を使って表現してください。
* 行列及び行列式は、行と列の対応関係を正確に維持してください。
* 行の右端にある式番号(例: (7), ---(6))は、必ず数式ブロック $$ ... $$ の内部に含めてください。
- 数式の記号順序の厳密な維持(数学的最適化の禁止)をするため、以下のルールを守ってください。
*数式内の記号や変数の順序は、画像に見える通りの並び順を左から右へ厳密に維持してください。
*「数学的な正しさ」や「一般的な書き方」に基づいて順序を入れ替えることは絶対に禁止です。
*特に、∑(シグマ)や ∫(積分)の外側にある変数(例:X,Y)を、勝手に記号の中(右側)に移動させないでください。
*AIとしての「気を利かせた修正」は不要です。人間がタイプミスをしている場合でも、画像にある通りの順序で出力する「逐一出力(Verbatim)」モードで動作してください。
- **重要:** 抽出リストで特定した図表がある位置には、対応する画像リンク `` を挿入してください。summerize this pdf in Japanse"
"""
Geminiへの送信と返信
基本的にgoogleのディベロッパーガイドをベースに作成しています。
thinking_levelは、low以下だと試行しなくなり、トークンの節約ができ、lowだとmediumの4割ぐらいになりました。
また、出力の品質として、lowでもmediumでも変わらなかったため、lowを使用しています。
20260117更新
thinking_levelは、pdfが複雑になるほどmediumやhighの方が品質が良くなるように感じます。
また、画像やpdfをGeminiに読み取ってもらう際の解像度media_resolutionを指定できるようにアップデートしました。デフォルトではpdfはmedia_resolution_mediumのようです。
client = genai.Client(api_key=api_key, http_options={'api_version': 'v1alpha'})とv1alphaのapiを指定しなければ動きません。
あまりトークンの使用量が変わらないので、とりあえず私はmedia_resolution_highを使っています。media_resolution_ultra_highは画像用で、pdfには対応していないようです。
#client = genai.Client(api_key=api_key)
# for media resolution only
client = genai.Client(api_key=api_key, http_options={'api_version': 'v1alpha'})
file_upload = client.files.upload(file=upload_file)
#apiでサーバーに送信
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Content(
parts=[
types.Part(prompt),
types.Part(file_upload, media_resolution={"level": "media_resolution_medium"})
])], #media_resolution_low、media_resolution_medium、media_resolution_high、media_resolution_ultra_high
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(
thinking_level="high",#"high", #"medium", #"low" <, "minimal" #low and minimal has no thinking
include_thoughts=True),
response_mime_type="application/json",
response_schema=DocumentExtractionResponse
)
)
#返ってきた内容を表示。
for part in response.parts:
if not part.text:
continue
if part.thought:
print("### Thought summary:")
print(part.text)
print()
else:
print("### Answer:")
print(part.text)
import json
result = json.loads(part.text)
print()
数式の修正
geminiにいくらmarkdownにおける数式の書き方を教えても、間違えて出力してしまします。
具体的には、本文 $\tau$ 本文というように数式の前後には半角スペースを入れ、$と中身の数式コマンドの間には空白文字を絶対に入れず、
正しい例: 本文 $\tau$、$x+y=z$ 本文
悪い例: 本文$ \tau $、$ x+y=z $本文
とする必要がありますが、このルールを破ってきます。
そのため、あとからプログラムで修正しています。
なおこのプログラムはGeminiに作ってもらいました。
import json
import os
import re
# markdownでtex数式が適切に出力されるように処理
def fix_inline_math_spaces(text):
# インライン数式 ($...$) の中身だけを抽出して前後スペースを消す正規表現
# (?<!\$) : 前に $ がない(ブロック数式 $$ を避ける)
# \$ : 開始の $
# ([^\$]+) : $ 以外の文字(数式の中身)をグループ1としてキャプチャ
# \$ : 終了の $
# (?!\$) : 後ろに $ がない(ブロック数式 $$ を避ける)
inline_pattern = r'(?<!\$)\$([^\$]+)\$(?!\$)'
def shrink_match(match):
# match.group(1) は数式の中身(例: " \tau ")
# これを strip() して両端の空白を消し、再び $ で囲む
inner_content = match.group(1).strip()
return f" ${inner_content}$ "
# 数式の中身だけをきれいにし、外側のスペースには触れない
fixed_text = re.sub(inline_pattern, shrink_match, text)
return fixed_text
#このコードのメリット
#外側のスペースを守る: $ $ のペアを見つけてからその「中身」だけを処理するため、本文 $ の間にあるスペースは削除されません。
#ブロック数式を壊さない: $$(ブロック数式)は正規表現の否定条件((?<!\$)など)によって除外されるため、改行が必要なブロック数式が崩れることはありません。
#複雑な数式に対応: $ x + y = z $ のように中にスペースが含まれる場合も、「両端のスペース」だけを消して $x + y = z$ にしてくれます。
改行文字の修正
Geminiは改行文字を\nではなく、表示用に\\nで出力することがたまにあります。
対策として\\nを\nに置き換えています。
extraction_data.content_markdown.replace('\\n', '\n')
保存
抽出されたデータをJSONファイルとMarkdownファイルに保存しています。
なおこのプログラムはGeminiに作ってもらいました。
20260117更新
たまに、markdown中では画像のリンクが書かれているのに、その画像がjsonに存在せず画像ファイルとして切り出せていないことがあります。
そのような場合html変換時にエラーが出てしまうので、確認するプログラムを追加しました。
# 保存用
def save_outputs(extraction_data, json_filename="output.json", md_filename="output.md"):
"""
抽出されたデータをJSONファイルとMarkdownファイルに保存する
"""
# 1. JSONファイルの保存
# extractions(図表リスト)のみを保存する場合
extraction_list = [item.model_dump() for item in extraction_data.extractions]
with open(json_filename, "w", encoding="utf-8") as f:
# ensure_ascii=False を指定することで日本語の文字化けを防ぎます
json.dump(extraction_list, f, ensure_ascii=False, indent=2)
# 2. Markdownファイルの保存
with open(md_filename, "w", encoding="utf-8", newline='\n') as f:
f.write(fix_inline_math_spaces(extraction_data.content_markdown.replace('\\n', '\n'))) #geminiはエスケープして出力することあり
print(f"保存完了: {json_filename}, {md_filename}")
#3. Markdown中の画像リンクがJSONで指定されているか確認
# JSONにあるファイル名のセット
json_filenames = {item.filename for item in extraction_data.extractions}
# Markdownからリンクを抽出
md_filenames = re.findall(r'!\[.*?\]\((.*?)\)', extraction_data.content_markdown)
for md_file in md_filenames:
if md_file not in json_filenames:
print(f"\nWarning: Markdownにある {md_file} がJSONに見当たりません。\n")
画像の切り出し
PyMuPDFというライブラリを使用して、出力されたjsonファイルをもとに画像を切り出しています。
2点注意があります。
Geminiは0から1000の範囲の正規化座標で画像を指定してくるので、実際のpdfのサイズをかけることで実際の座標に変換しています。
Geminiの指定範囲はたいてい狭くて見切れているので、padding_ratioである割合広く切り出しています。クリッピングは簡単なので。
なおこのプログラムはGeminiに作ってもらいました。
import fitz # PyMuPDF
import json
import os
def crop_images_from_pdf(pdf_path, json_path, output_dir="./", padding_ratio=0.05):
"""
JSONの座標をもとに、指定割合(padding_ratio)だけ広い範囲を切り出す
padding_ratio=0.05 は、上下左右にそれぞれ5%広げ(計10%拡大)ることを意味します。
"""
with open(json_path, 'r', encoding='utf-8') as f:
extractions = json.load(f)
if not os.path.exists(output_dir):
os.makedirs(output_dir)
doc = fitz.open(pdf_path)
for item in extractions:
page_num = item['page_number'] - 1
filename = item['filename']
ymin, xmin, ymax, xmax = item['box_2d']
# 1. 元のサイズを計算
width = xmax - xmin
height = ymax - ymin
# 2. 範囲を広げる (上下左右に指定割合ずつ)
# 左右に width * 0.05 ずつ、上下に height * 0.05 ずつ広げる
xmin_new = xmin - (width * padding_ratio)
xmax_new = xmax + (width * padding_ratio)
ymin_new = ymin - (height * padding_ratio)
ymax_new = ymax + (height * padding_ratio)
# 3. 0〜1000の範囲内に収まるように補正 (ページ外はみ出し防止)
xmin_new = max(0, xmin_new)
ymin_new = max(0, ymin_new)
xmax_new = min(1000, xmax_new)
ymax_new = min(1000, ymax_new)
# 4. PDFの実際の座標に変換
page = doc.load_page(page_num)
p_width = page.rect.width
p_height = page.rect.height
left = (xmin_new / 1000) * p_width
top = (ymin_new / 1000) * p_height
right = (xmax_new / 1000) * p_width
bottom = (ymax_new / 1000) * p_height
rect = fitz.Rect(left, top, right, bottom)
# 5. 保存 (高画質設定)
zoom = 3.0
mat = fitz.Matrix(zoom, zoom)
pix = page.get_pixmap(matrix=mat, clip=rect)
output_path = os.path.join(output_dir, filename)
pix.save(output_path)
print(f"Saved: {output_path} (Expanded 10%)")
doc.close()
# 実行
pdf_file = "./NASA_sp125_Chapter4.pdf"
json_file = "output.json"
crop_images_from_pdf(pdf_file, json_file)
markdownからhtmlへの変換
markdownファイルのままでも、githubやVSCodeで変換後のきれいな状態で見ることができます。しかし、それ以外の環境でも簡単に閲覧できるよう、htmlファイルに変換しました。
ライブラリはいろいろとありましたが、GithubのActionも簡単に作れるPandocを使用しました。
そして、ローカルで変換する用と、Githubにマークダウンをpushしたら自動でマークダウンファイルを作ってくれるActionの2つを作りました。
そこまで情報が豊富ではなかったのですが、下記サイトを参考に作れました。
引数
引数には以下を使用しています。
- ヘッダーやCSSを含む完全なHTMLを作成するために
--standalone - 画像などをHTML内に埋め込むために
-self-contained - 数式の描写をするために
--katex - 目次(左の方にあるリンク)の作成をするために
--toc
また、テンプレートを使用するために、easy-pandoc-templatesからテンプレートをダウンロードしてフォルダに保存し--template=./templates/bootstrap_menu.htmlというように使用しています。
数式は、調べると--mathjaxを使用するのが一般的なようですが、なぜか動作しなかったので--katexを使用しています。
ローカルで動作するプログラム
ローカルのPythonで動作させることができます。
なおこのプログラムはGeminiに作ってもらいました。
import pypandoc
def convert_md_to_html():
input_file = 'output.md'
output_file = 'output_local.html'
# Pandocのオプション設定
# --standalone: ヘッダーやCSSを含む完全なHTMLを作成
# -self-contained: 画像などをHTML内に埋め込む (オプション)
# --katex: 数式の描写。mathjaxはうまくいかず
# --metadata title="タイトル": ページのタイトルを設定
# --toc: 目次の作成
args = [
'--standalone',
'--self-contained',
'--katex',
'--template=./templates/bootstrap_menu.html',
'--toc'
]
try:
# 変換実行
output = pypandoc.convert_file(
input_file,
'html',
format='md',
extra_args=args,
outputfile=output_file
)
print(f"Success: {output_file} generated.")
except RuntimeError as e:
print(f"Error: {e}")
if __name__ == "__main__":
convert_md_to_html()
Github actionsで動作するプログラム
.mdファイルが変更されたときのみ動作し、自動でhtmlに変換してコミットしてもらうようにしました。
Github Actionsを使用するのは初めてなのですが、Geminiに相談しながら作ってもらい、何とか理解できたという状況です。
name: Convert Markdown to HTML
on:
push:
paths:
- '**.md' # .mdファイルが変更されたときのみ実行
permissions:
contents: write # HTMLをコミットするために書き込み権限が必要
jobs:
convert:
runs-on: ubuntu-latest
steps:
# 1. コードのチェックアウト(履歴をすべて取得)
- name: Checkout code
uses: actions/checkout@v4
with:
fetch-depth: 0
# 2. Pandocのセットアップ (公式Action)
- name: Install Pandoc
uses: pandoc/actions/setup@v1
with:
version: '3.1.11' # 'latest' の代わりに具体的なバージョンを指定
# 3. 変更された.mdファイルを特定して変換
- name: Convert Changed Markdown to HTML
run: |
# 今回のプッシュで追加・修正された .md ファイルを取得
# (最初のコミットなどの場合は比較対象がないため、全ファイルを対象にする等の考慮が必要)
files=$(git diff --name-only --diff-filter=AM ${{ github.event.before }} ${{ github.sha }} | grep '\.md$' || true)
if [ -z "$files" ]; then
echo "No markdown files changed."
exit 0
fi
for file in $files; do
echo "Converting $file..."
# 拡張子を .html に変更したファイル名を生成
output="${file%.md}.html"
# Pandocで変換 (--standalone でHTMLの完全な構造にする --tocで目次)
# pandoc "$file" --standalone --self-contained --katex -o "$output"
# pandoc "$file" --standalone --self-contained --katex --template="$GITHUB_WORKSPACE/templates/easy_template.html" -o "$output"
# pandoc "$file" --standalone --self-contained --katex --template="$GITHUB_WORKSPACE/templates/elegant_bootstrap_menu.html" --css "$GITHUB_WORKSPACE/templates/elegant_bootstrap.css" -o "$output"
pandoc "$file" --standalone --self-contained --katex --template="$GITHUB_WORKSPACE/templates/bootstrap_menu.html" --toc -o "$output"
done
# 4. 生成されたHTMLをリポジトリにコミット
- name: Commit and Push changes
uses: stefanzweifel/git-auto-commit-action@v5
with:
commit_message: "Auto-convert Markdown to HTML [skip ci]"
file_pattern: '**.html'
ノウハウ
20260117更新
実際にOCRを進める中でプロンプトを大幅にアップデートし、また運用方法に大きな知見を得られました。それらを共有します。
基本的には使用して問題になったことをGeminiにプログラムと一緒に渡せば解決法を示してくれます。
入力するPDFのページ数
PDFの長さが長すぎると、出力が途中で終わっていたり、真ん中がカットされてしまうことがありました。
原因としては、現Gemini3.0では出力トークンの上限が65,536となっているためと考えられます。入力トークンの上限は1,048,576と非常に大きいので長いPDFを理解することはできても、出力時にトークンが足りなくなってしまう、ということが考えられます。
さらに、PDFの内容によっても長いページを処理できるか変わってくることが分かり、
- 数式が多い
- 表や文字を含んだ画像が多い
- ごちゃごちゃしていて理解に時間がかかる
PDFはページ数を短くする必要がありました。
たくさん試行錯誤していると、体感ですが、人間である自分がざっとPDFをスクロースした際に理解しずらいほど、PDFを短くする必要があるという感覚を持ちました。
私は最終的にはPDFを10ページ前後でかつ、文がいい感じで切れる部分で手動でPDFを分割し、順番に渡していました。
自動にしたい場合、下記の感じのプロンプトを最初に追加し、適切に関数を追加するとそれっぽいものはできます。(実装したい人はGeminiにお願いしてください。)
ただ、プロンプトでPDFのページを与えても本当にそのページを見ている保証はないですし、使ってみた体感まともに読めるものは出てきたが、画像の抽出が正しくできていなかったりと、私は使っていません。
BASE_PROMPT = """
あなたは高度な文書解析および翻訳の専門AIです。添付されたPDFの **{start_page}ページから{end_page}ページまで** を解析し、以下の指示に従って「1. 図表のJSONリスト」および「2. 日本語翻訳のMarkdownテキスト」の順で出力してください。
### 文脈の維持(重要)
直前のページは以下の内容で終わっています:
---
{previous_context}
---
この内容を考慮し、文章が途中で切れている場合は自然に繋がるように翻訳を開始してください。
書籍のレイアウトについて
書籍は2段組でヘッダーやフッターがあります。
特に指示をしないと右のカラムから翻訳したり、マイページヘッダーの見出しを出力してきます。
そのため、以下のプロンプトを与えています。
- **読解順序**: ページ内のレイアウト(2段組など)を正確に認識し、人間が読む自然な順序でテキストを抽出してください。2段組の場合「左カラムの最上部から最下部まで」を完全に処理したあと、次に「右カラムの最上部」に移動して処理を継続してください。
- **除外事項**: ページ番号、ヘッダー(章名のリピート)、フッターの翻訳・抽出は不要です。
特に、左上に数式があり、右上に文章がある場合、右上から抽出することがありました。そこでGeminiに相談した結果、2段組の場合「左カラムの最上部から最下部まで」を完全に処理したあと、次に「右カラムの最上部」に移動して処理を継続してください。という一文を追加しました。
見出しについて
PDFを分割して翻訳していると、PDFごとに章の見出し階層が変わってしまうことがありました。(例えばA2.1節を1つ目の出力はH1、2つ目の出力はH2、など)
そこで以下のようなプロンプトを与えました。
ある程度改善はされましたが、完ぺきではないので要改善です。
***見出しの階層化**:
- `# ` (H1): 「A5」や「Chapter 4」などの大見出し
- `## ` (H2): 「A5.1」などのピリオドが1つ含まれる中見出し
- `### ` (H3): 適切に使用してください。
数式について
一番プロンプトによる改善が見られたのが数式でした。
数式の導出の省略
複雑な数式が続くと、途中を省略されることがありました。(PDFが長すぎることが原因の時もあります。)
そこで、以下のプロンプトを追加しました。
- **情報の完全性**: 特に大きな数式のブロック(積分、分数、行列などが含まれるもの)は、最も重要な情報です。 これらが連続する場合でも、一つ一つを独立した数式としてすべて書き出してください。「〜(以下同様の数式が続く)」といった要約は絶対に禁止します。
数式の改変
Geminiは数式を理解できるが故、数学的な正しさを保ったまま数式の順番を変えることがありました。
例えば、∫xydyを勝手にx∫ydyと出力されることがありました。
そこで、以下のプロンプトで改善しました。
- 数式の記号順序の厳密な維持(数学的最適化の禁止)をするため、以下のルールを守ってください。
*数式内の記号や変数の順序は、画像に見える通りの並び順を左から右へ厳密に維持してください。
*「数学的な正しさ」や「一般的な書き方」に基づいて順序を入れ替えることは絶対に禁止です。
*特に、∑(シグマ)や ∫(積分)の外側にある変数(例:X,Y)を、勝手に記号の中(右側)に移動させないでください。
*AIとしての「気を利かせた修正」は不要です。人間がタイプミスをしている場合でも、画像にある通りの順序で出力する「逐一出力(Verbatim)」モードで動作してください。
Tex数式の出力
数式が多くなってくると、たまにtex数式として成り立っていないものが出力されました。
そこで以下のプロンプトを与えて改善しました。
* 数式はすべて標準的なLaTeXコマンドを使用して記述してください。
* 分数は必ず \frac{分子}{分母} を使用してください。バックスラッシュを他の記号(矢印など)と誤認しないでください。
* u_x, u_y^2 などの下付き・上付き文字は、極めて小さい文字まで注意深く読み取り、省略せず _ および ^ を使って表現してください。
* 行列及び行列式は、行と列の対応関係を正確に維持してください。
* 行の右端にある式番号(例: (7), ---(6))は、必ず数式ブロック $$ ... $$ の内部に含めてください。
最後に
今回は、英語の教科書を読みたいがために、Gemini APIでPDFを丸ごと翻訳&Markdown変換し図表の自動抽出もできるプログラムを作りました。
以前はpdfを微妙な精度のOCRをしてdeeplに手動で突っ込み、数式は作り直しという非常に大変なことをしていたのですが、このプログラムのおかげで翻訳ではなく勉強に集中できそうです。
今回Geminiが非常に活躍してくれ、これらのプログラムは計5日ぐらいで作ることができました。知らないことだらけだったので、正直生成AIがない時代だったら学びは大きいかもしれませんが、一つ一つのステップに何か月もかかっていたと思います。
これからの時代はいかにAIを使いこなすかか、ということを強く実感しました。
このプログラムが皆様の勉強の助けになればと思います。
ちなみに今回紹介したNASA sp-125は和訳版が大学生により翻訳され同人誌として販売されています。自分はAIを使ってずるをしている中、何も使わず本全部を翻訳して出版するなんて、と翻訳者に頭が上がりません。
実はタイトルはgeminiに考えてもらっていました。
初期の自分で考えたものは、【無料】Geminiを使って英語のpdfをOCRして図表付きのマークダウンに変換してもらった話でした。さてどっちがよかったのでしょうか。