今回は PyTorch Geometricを使って、グラフ構造データに対する機械学習の手法であるVGAE (Variational Graph Autoencoder) を実装し、その手順を紹介します。
VGAEは、GNN (Graph Neural Nework)の中でもVAE (Variational AuotoEncoder)をグラフデータ向けに改良したモデルです。今回はグラフ内の頂点同士が将来的に接続されるかどうかを予測するリンク予測のタスクに対してVGAEで実装します。
リンク予測
リンク予測は、ネットワーク分析における重要なタスクの一つです。ネットワーク上のノード間に新しいエッジが存在するかを予測するタスクです。リンク予測の例としてSNSにおける新たな友人関係の将来予測やECサイトにおける商品の推薦が存在します。
VAE (Variational AutoEncoder)
まずVGAEの理論の基礎になるVAE (Variational AutoEncoder)について紹介します。VAEはエンコーダーとデコーダーの2つのネットワーク層を組み合わせたモデルです。
- エンコーダ $q_{\phi}{(Z|X)}$ :入力されたデータ $X$ を低次元のベクトルデータに変換し、潜在空間に埋め込む層
- 潜在空間 $z_i \in Z$ :エンコーダーによって埋め込まれて圧縮・抽象化された低次元の確立的な表現空間
- デコーダー $p_{\theta}{(\hat{X}|Z)}$ :入力された特徴量である潜在空間からデータ $\hat{X}$ を再構成する層
潜在空間の特徴量である潜在変数 $z_i$ は、エンコーダーが出力する平均値 $\mu_i$ と分散 $\sigma_{i}^2$を用いて
$$
z_i = \mu_i + \sigma_i \odot \epsilon,\quad \epsilon \sim \mathcal{N}(0, I)
$$
という Reparameterization Trick によってサンプリングされます。
これにより、乱数を含む操作でも微分可能となり、誤差逆伝播による学習が可能になります。
潜在変数 $z$ が確率的に生成されることで、デコーダー $p_{\theta}{(X|Z)}$ は、入力データの多様性を反映した柔軟な再構成を行えるようになります。
つまりエンコーダーは入力されたデータを潜在空間に埋め込むことで入力されたデータの特徴を解釈し、デコーダーは潜在空間から意味のあるデータを生成できるように役割を分担して学習を行います。これによりデコーダーは、エンコーダから生成された潜在空間の特徴量を基に、エンコーダへの入力されたデータと同様の近似したデータを生成できます。
Reparameterization Trick
VAEでは潜在変数を確率分布からサンプリングしますが、サンプリング操作は微分不可能です。これにより誤差逆伝播法を用いたパラメータの更新が困難となります。
これらに対してReparameterization Trickでは、乱数部分を $\epsilon$ に切り離し、
$$
z = \mu + \sigma \odot \epsilon
$$
と書き換えることで、$\mu$ と $\sigma$ に対して微分可能な形に変換します。
VGAE(Variational Graph AutoEncoder)
先ほどのVAEにおけるエンコーダー・デコーダー・潜在空間の考え方をグラフ構造のデータに応用することでリンク予測を実現します。VGAEは、グラフ構造データから潜在表現を学習し、その潜在表現を用いてエッジの有無を確率的に推定するモデルです。VGAEは、グラフの隣接行列やノードの特徴量を用いて、グラフ構造を潜在空間にエンコードすることでそのグラフデータの特徴量を得ることが可能です。
-
グラフエンコーダー: $q_{\phi}{(Z \mid X, A)}$
- 入力されたグラフ構造情報としての隣接行列 $A$ とノード特徴量 $X$ を低次元の潜在変数 $Z$ に変換します
- 各ノード $i$ の潜在変数 $z_i$ は平均 $\mu_i$ と分散 $\sigma_{i}^2$ の正規分布に従います
q_{\phi}{(Z \mid X, A)} = \mathcal{N}(z_i \mid \mu_i, \text{diag}(\sigma_i^2))
-
グラフデコーダー: $p_{\theta}{(\hat{A} \mid Z)}$
- 入力された潜在変数 $Z$ から、元のグラフを近似した隣接行列 $\hat{A}$ を再構築します
- 内積による各ノード間の類似度に基づいたデコーダーです
p_{\theta}{(\hat{A} \mid Z)} = \sigma \left( z_i^\top z_j \right)
VGAEに用いられる目的関数
VGAEでは、主に再構成誤差とKLダイバージェンスの2つの目的関数を用いてモデルを学習します。
再構成誤差
- 入力されたグラフの隣接行列と同じグラフの隣接行列が生成されていることを評価します
- 隣接行列の各要素は 0/1 の二値であるため、再構成にはバイナリクロスエントロピーが用いられます
- 入力する隣接行列を $A$ ,出力する隣接行列 $\hat{A}$ とします
\mathcal{L}_{\text{rec}} = - \sum_{i,j} \left[ A_{ij} \log \hat{A}_{ij} + (1 - A_{ij}) \log (1 - \hat{A}_{ij}) \right]
KL(Kullback-Leibler)ダイバージェンス
- 潜在変数が正規分布に従ってランダムに生成されていることを評価します
- エンコーダが推定した潜在分布 $q_{\phi}(Z \mid X, A)$ が、標準正規分布 $p(z) = \mathcal{N}(0, I)$ にどれだけ近いかを測る指標です
\mathcal{L}_{\text{KL}}
= -\frac{1}{2} \sum_{i=1}^{N}
\left( 1 + \log \sigma_i^2 - \mu_i^2 - \sigma_i^2 \right)
検証環境
今回は以下の環境を用いて検証を行います。
| ライブラリ | バージョン | 利用用途 |
|---|---|---|
| CUDA | 12.9.1 | GPU計算の実行・高速化 |
| Python | 3.13.10 | 実行環境・スクリプト言語 |
| PyTorch | 2.8.0+cu12.9 | 深層学習フレームワーク |
| PyTorch Geometric | 2.8.0 | GNNモデル構築・グラフデータ処理 |
| NetworkX | 3.6.1 | グラフ構造の生成・操作・可視化 |
PyTorchインストール時にはCUDAのバージョンに合わせる必要があります
例) CUDA12.9 → cu12.9
またPyTorch Geometricをインストールする場合はCUDAとPyTorchのバージョンに合わせる必要があります
例) PyTorch2.8とCUDA12.9 → torch-2.8.0+cu129.html
データセットの準備
今回はPyTorch Geometricに含まれるCoraデータセットを使用します。RandomLinkSplitにより、train_data.edge_label_index には学習に使用する正例エッジ(pos_edge_label_index)が格納されます。
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures, RandomLinkSplit
dataset = Planetoid(root='data/Cora', name='Cora', transform=NormalizeFeatures())
transform = RandomLinkSplit(
num_val=0.05, # 検証用エッジの割合
num_test=0.1, # テスト用エッジの割合
is_undirected=True, # Cora は無向グラフ
add_negative_train_samples=False # train では負例を自動生成しない
)
train_data, val_data, test_data = transform(dataset[0])
VGAE モデルの実装
PyTorch Geometrics には VGAE クラスが用意されているので、エンコーダ部分を定義するだけで簡単に構築できます。今回は2層のGCNを活用して特徴量を抽出し、潜在分布の平均 $\mu_i$ と分散 $\log \sigma_{i}^2 $ を出力します。
from torch_geometric.nn import GCNConv, VGAE
# Encoderの定義
class GraphEncoder(torch.nn.Module):
def __init__(self, in_channels, out_channels):
super(GraphEncoder, self).__init__()
self.conv1 = GCNConv(in_channels, 2 * out_channels)
self.conv_mu = GCNConv(2 * out_channels, out_channels)
self.conv_logstd = GCNConv(2 * out_channels, out_channels)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index).relu()
return self.conv_mu(x, edge_index), self.conv_logstd(x, edge_index)
model = VGAE(GraphEncoder(in_channels=in_channels, out_channels=out_channels))
モデルの学習
VGAEのモデルの学習を行います。
- 学習回数は100に設定します
- Adamによる最適化手法でモデルのパラメータを更新します
- 再構成誤差とKLダイバージェンスを利用して損失を計算します
# 学習回数と最適化手法の設定
epoch_num = 100
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# モデルの学習
model.train()
for epoch in range(1, epoch_num + 1):
# 勾配の初期化
optimizer.zero_grad()
# モデルの出力
z = model.encode(train_data.x, train_data.edge_index)
# 損失の計算
# edge_label_index は train 用の正例エッジ(pos_edge_label_index)を指す
recon_loss = model.recon_loss(z, train_data.edge_label_index) # 再構成誤差
kl_loss = (1 / train_data.num_nodes) * model.kl_loss() # KLダイバージェンス
loss = recon_loss + kl_loss # 全体の損失
# パラメータの更新
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(f'Epoch {epoch}, Loss: {loss}')
リンク予測
リンク予測では2つのエッジを予測する2値分類の問題としています。
- 実際に存在するエッジを正例
- 存在しないエッジを負例
予測後は、ROC-AUCを計算し、Youden’s Jで最適な閾値を設定し、Accuracyを求めています。
from sklearn.metrics import roc_auc_score, accuracy_score
from sklearn.metrics import roc_curve
model.eval()
with torch.no_grad():
z = model.encode(val_data.x, val_data.edge_index)
# 正エッジを予測
pos_edge_index = val_data.pos_edge_label_index
pos_pred = model.decode(z, pos_edge_index).view(-1).cpu()
# 負エッジを予測
neg_edge_index = val_data.neg_edge_label_index
neg_pred = model.decode(z, neg_edge_index).view(-1).cpu()
# 予測スコアの結合
preds = torch.cat([pos_pred, neg_pred], dim=0)
# 正解ラベルの作成
pos_labels = torch.ones(pos_pred.size(0))
neg_labels = torch.zeros(neg_pred.size(0))
labels = torch.cat([pos_labels, neg_labels], dim=0)
# AUCスコアの計算
auc_score = roc_auc_score(labels, preds)
# ROC曲線の計算
fpr, tpr, thresholds = roc_curve(labels, preds)
# Youden's J statisticを利用して最適な閾値を決定
optimal_idx = (tpr - fpr).argmax()
optimal_threshold = thresholds[optimal_idx]
# 最適な閾値を用いてAccuracyの計算
binary_preds = (preds >= optimal_threshold).float()
accuracy = accuracy_score(labels, binary_preds)
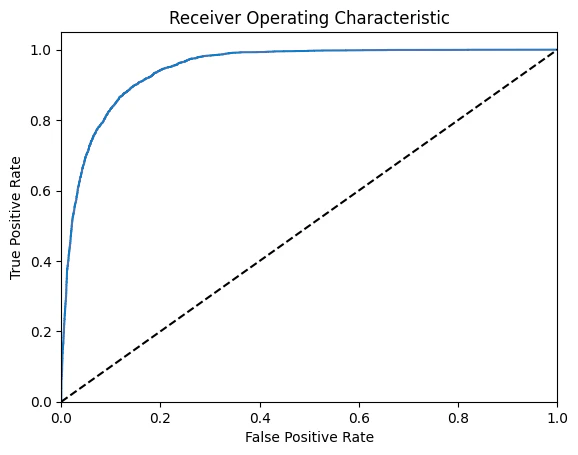
これらによって算出されたROC曲線はこちらになります。AUCは0.9473、Accuracyは0.8759となりました。
具体的なソースコードはこちらに掲載しておきます。
https://github.com/C0A21130/trust-score/blob/main/trust-engine/basic/vgae.ipynb
参考文献
- 論文: Variational Graph Auto-Encoders (Kipf & Welling, 2016)
- VAEって結局何者なの?、https://zenn.dev/asap/articles/6caa9043276424