はじめに
昨年のre:Inventで発表されたStepFunctionsの新機能である、Distribution Mapは我々開発者にとってかなり強力な機能だと思います。
(Distribution Mapがどんな機能かは、リンクを確認してみてください。)
今回はDistribution Map(Step Functions)を利用して分かった「限界」に関して記録したいと思います。
目次
- 何をしたかったか。
- やったこと・起こったこと
- どのように乗り越えたか
- まとめ
1. 何をしたかったか。
我々は開発フローの中でCICDでデプロイされるWeb資材をS3にビルドを実施しています。
さらにそのWeb資材をユーザー毎に展開していくために、これまではVBAツールを利用して1ユーザーずつコピーを行っていました。
(1つずつ行うのは、ユーザー毎にWeb資材のカスタマイズがあるため、一括コピーができないため)
ただこのツールはお察しの通り、ユーザーが増えるのに比例して処理時間も増え、すでに5時間を超すまでになっていました。
迅速なリリースを実現し、運用保守稼働を低減させることを目的として、LambdaとStep FunctionsのDistribution Mapを利用して超高速な並列処理を実装していくことに至ったわけです。
2.やったこと・起こったこと
やったこと
- Lambda×PythonでVBAツールをLambda化(ソースは割愛)
- 以下2つのLambdaを実装
- Web資材の更新対象の顧客リストをDBから取得し、JSON形式でリストをreturnする関数
- StepFunctionsでリストから1件ずつ抽出された顧客データを元にS3からコピーを実行する関数
- 以下2つのLambdaを実装
- StepFunctionsのステートマシン作成
- 以下の構成でDistributionMapを利用して、リストのアイテム数だけLambdaを並列実行させるステートマシンの作成
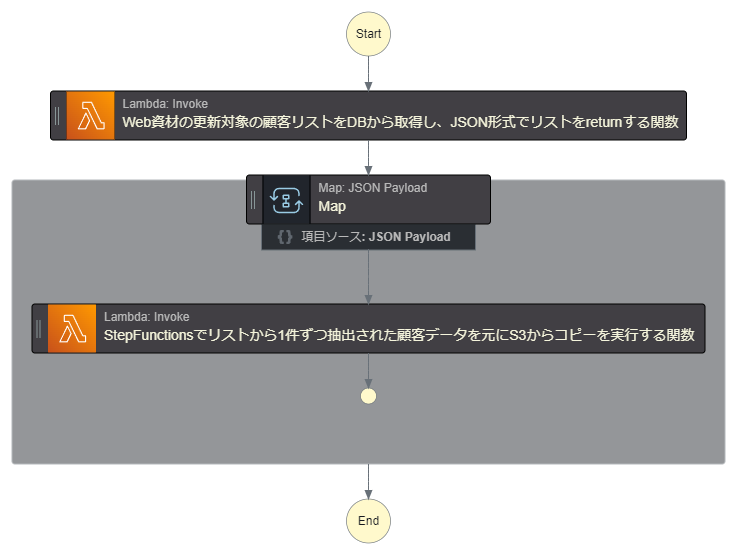
- 以下の構成でDistributionMapを利用して、リストのアイテム数だけLambdaを並列実行させるステートマシンの作成
起こったこと
開発環境での動作確認は以下のように成功し、実行時間の短さに驚嘆していました。
やっぱDistribution Mapすごいですわ。

しかし負荷試験用の環境で、このステートマシンを実行させると、以下のエラーになり、ステート遷移に失敗してします。
The state/task 'lambda' returned a result with a size exceeding the maximum number of bytes service limit.
上記の参考記事にもAWS公式ドキュメントにも、S3にデータを一時保存して後続処理に渡す的なことが書いてありましたが、今回扱っているデータはシーケンスレスで後続処理がどのデータを処理しているか判断することが難しそうだったので、ここでStep Functionsを利用することを諦めました。(先に調べておけよという感じですね)
3.どのように乗り越えたか
Step Functionsが使えなくなったので、その他のAWSサービスを利用して並列処理を実現する方法を考えたところ、
1のLambdaからSQSにユーザー毎のデータでSQSキューに渡して、そのキューを2のLamabdaにサブスクライブさせる方法を思いつきました。
Step FunctionsならJSON定義で記載できるし、実行結果がビジュアライズされているので分かりやすいので好きだったんですが、今回の場合は、Lambda×SQSで大規模並列処理を実現させました。
Lambdaの処理自体もあまり変わらないので、変更は容易でした。
構成としては以下のようになります。
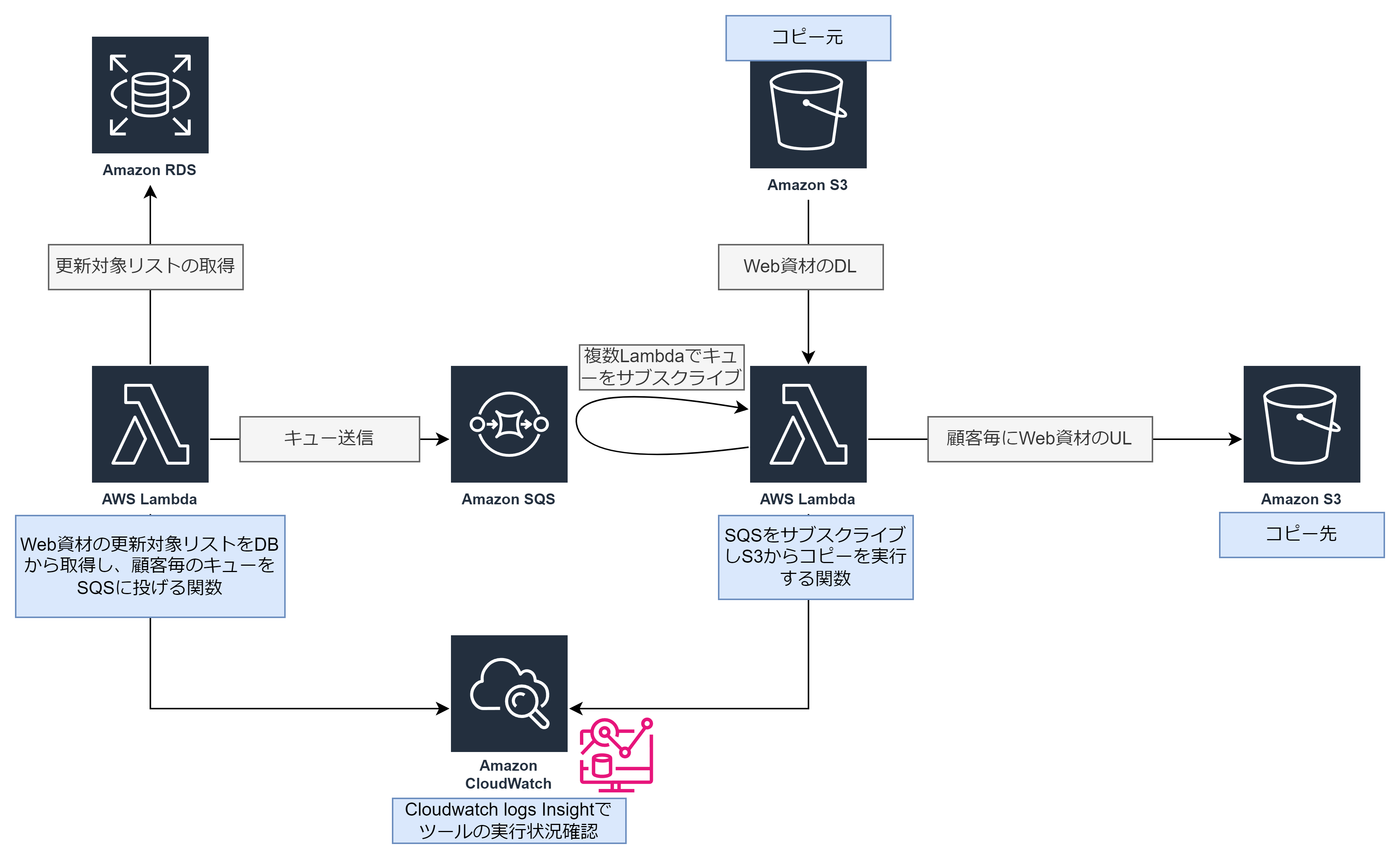
Step Functionsを利用したかったのは、実行結果がかなり見やすく成功失敗の判断が容易なこともあり、その点を補うためにLambdaログをCloudWatch Logs Insightのクエリで、成功ログがSQSにキューイングされた数と一致していることを確認することにしています。
少し手運用が入ってしまうことは残念ですが、上記構成でも処理時間は15分以内で実行できるので、稼働削減効果としては、莫大です。
4.まとめ
今回はStep Functionsのデータサイズリミットに苦しみましたが、まとめると
- Step FunctionsのDistribution Mapは優秀。だが扱うデータはシーケンスのある、細分化されたデータが好ましい。
- それでもStep Functionsのデータサイズ上限、256KBは小さすぎる、、AWSさんなんとかしてください。。
- Distribution Mapを使わなくてもSQSで同じように大規模並列処理を実行することは可能
といった具合です。データサイズの大きい並列処理を検討している方はご参照ください!