AWS Step Functions とは
AWS Step Functions は、 アプリケーションを構築するために複数の AWS サービスを統合できるサーバーレスオーケストレーションサービスです。アプリケーションのワークフローを一連のイベント駆動型ステップとして確認・動作させることができます。
もう少しわかりやすくいうと、 イベントに基づいて、複数のAWSサービスを活用して、何かしらの手順(ワークフロー)を実行することができます。
どういうユースケースで使われているかというと、DynamoDBのデータをLambdaで取得して、データによっては翻訳を実施したり、計算を実施したりと細かくコントロールするユースケースなどに使われます。
詳しい説明は、ドキュメントを確認してみてください
AWS Step Functions Distributed Map とは?
2022年のAWS re:Invent で発表されたのが、 AWS Step Functions Distributed Map になります。
通常の Map は最大40回の並列ワークロードまでしか起動できませんでした。しかし、Distributed Map を利用することで、最大1万回の並列ワークロードを起動することができます。
さらに、 Input として、 Amazon S3 を指定できるようになりました。
Distributed Map の利用方法を考えてみた
Distributed Map の機能を利用できるかと考えてみたところ、バッチ処理に使えるのではないかと思ったので、今回は試してみたいと思います。
皆さんも、こんな経験ないでしょうか?
- バッチ処理を一つのコンピューティングリースで実行しているので、時間がかかる
- 対象データ量が増え、年々実行時間が長くなってくる
- 並列実行の処理をしているが、インスタンスサイズに依存して、スケールしづらい
上記のような悩みを解決する一つの方法として、 Distributed Map を使って解決できるのではないかと思ったので、早速試してみました
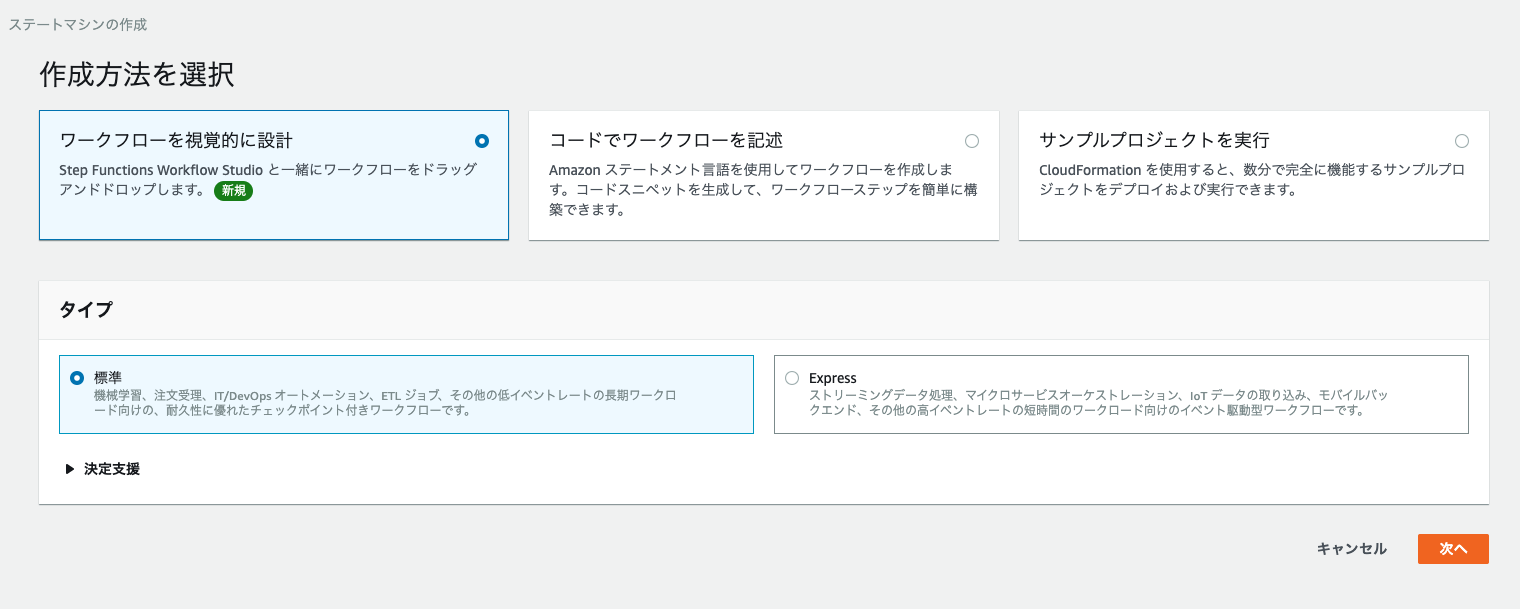
ステートマシンの作成
まずは、Step Functions のステートマシンを作成します。
今回は、標準タイプで作成します
ワークフローの設計
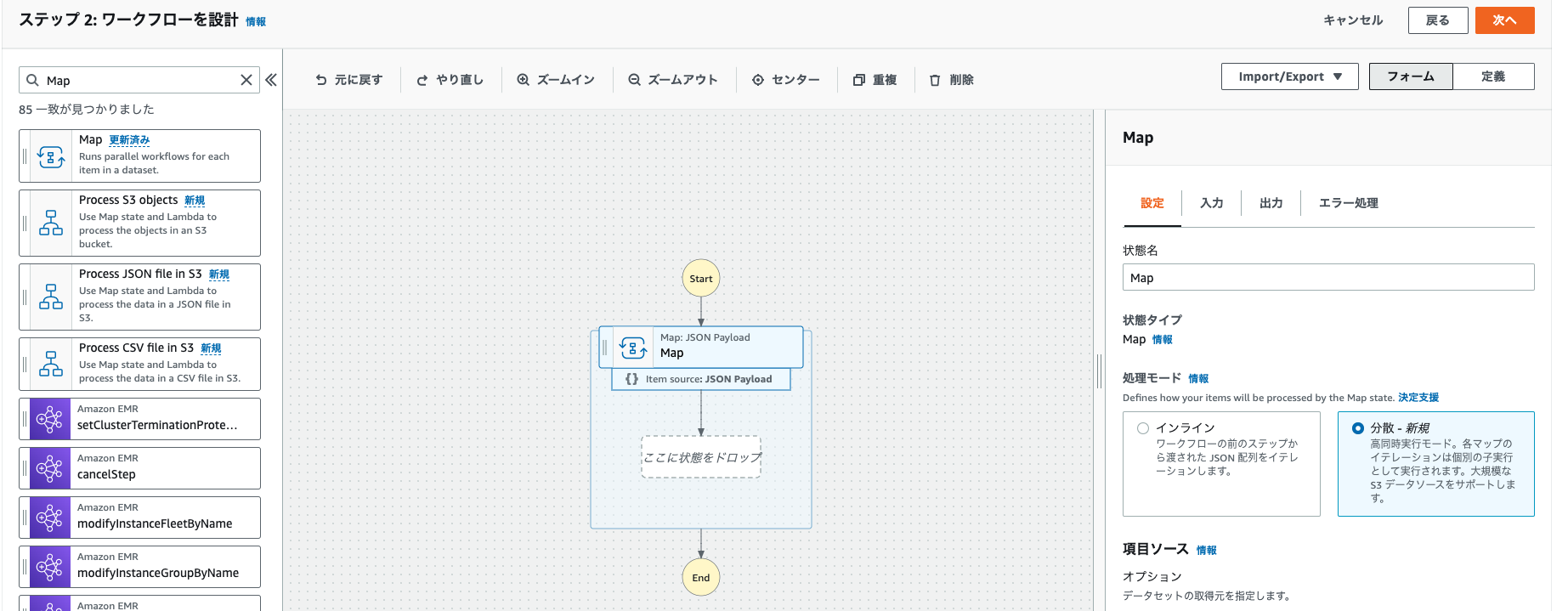
左の検索ボックスから、「Map」を検索して、追加します。
そして、処理モードに、分散が新規に追加されているので、そちらを選択します。
これで、 Distributed Map を利用することができます。
次に、項目ソースとして、今回は Amazon S3 に保存した CSVデータを利用したいので、 Amazon S3 と CSV file in S3 を選択し、保存しているバケットを指定します
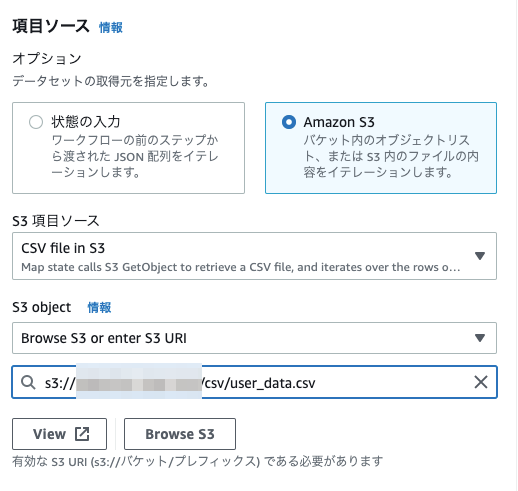
その他にも、追加設定として、 CSV ヘッダーの場所や、並列処理するアイテム数を制限、 ItemSelector を利用した項目の変更が可能です。
今回は、デフォルトのまま行きたいと思います。
次に、"項目のバッチ処理"の設定に移り、バッチ処理の有効化にチェックを入れます。そうすることで、バッチあたりに対して、最大項目数や最大KBでの制限をかけることができます。
今回は、1項目毎に AWS Lambda を実行したいので、 1項目 でいきます。
その他の項目は、デフォルトで行きたいと思います
今回は利用しませんが、バッチ処理のエクスポート先として、 Amazon S3 を指定できます。この機能については、後ほど触れていきたいと思います。
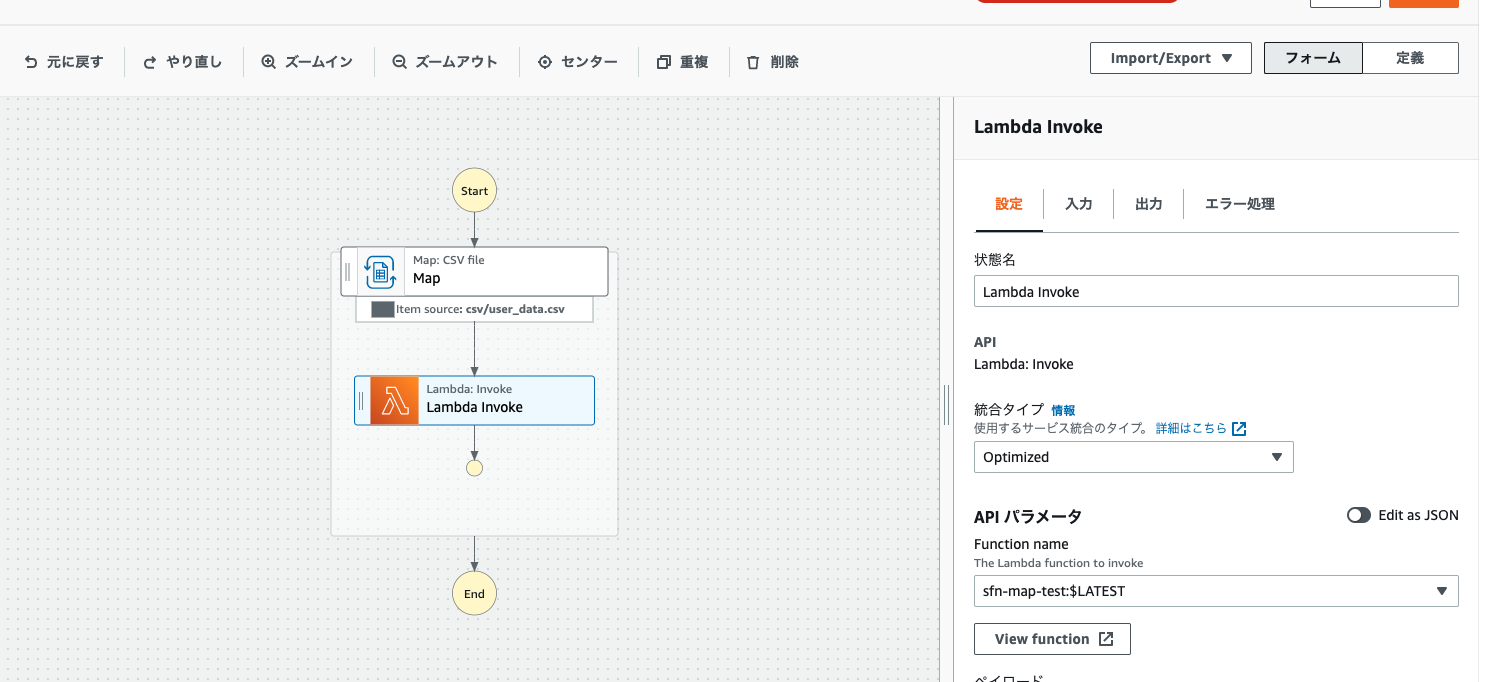
最後に、 Lambda Invoke をDistributed Map の中に設定し、対象のLambdaを指定することで、今回のワークフローは、準備完了です。
以下が、完成図になります。
今回実行する Lambda のコードは、こちらになります
今回は実験なので、ログに出力するのと、受け取ったものをそのまま返すLambda関数を作成しました。
export async function handler(event, context) {
console.log("Received Input:\n", event);
return {
'statusCode' : 200,
'inputReceived' : event
}
};
こちらで、諸々の設定ができたので、ステートマシンの名前を決め、ステートマシン作成を実行します。
ステートマシンが保存されたら、早速実行してみましょう!
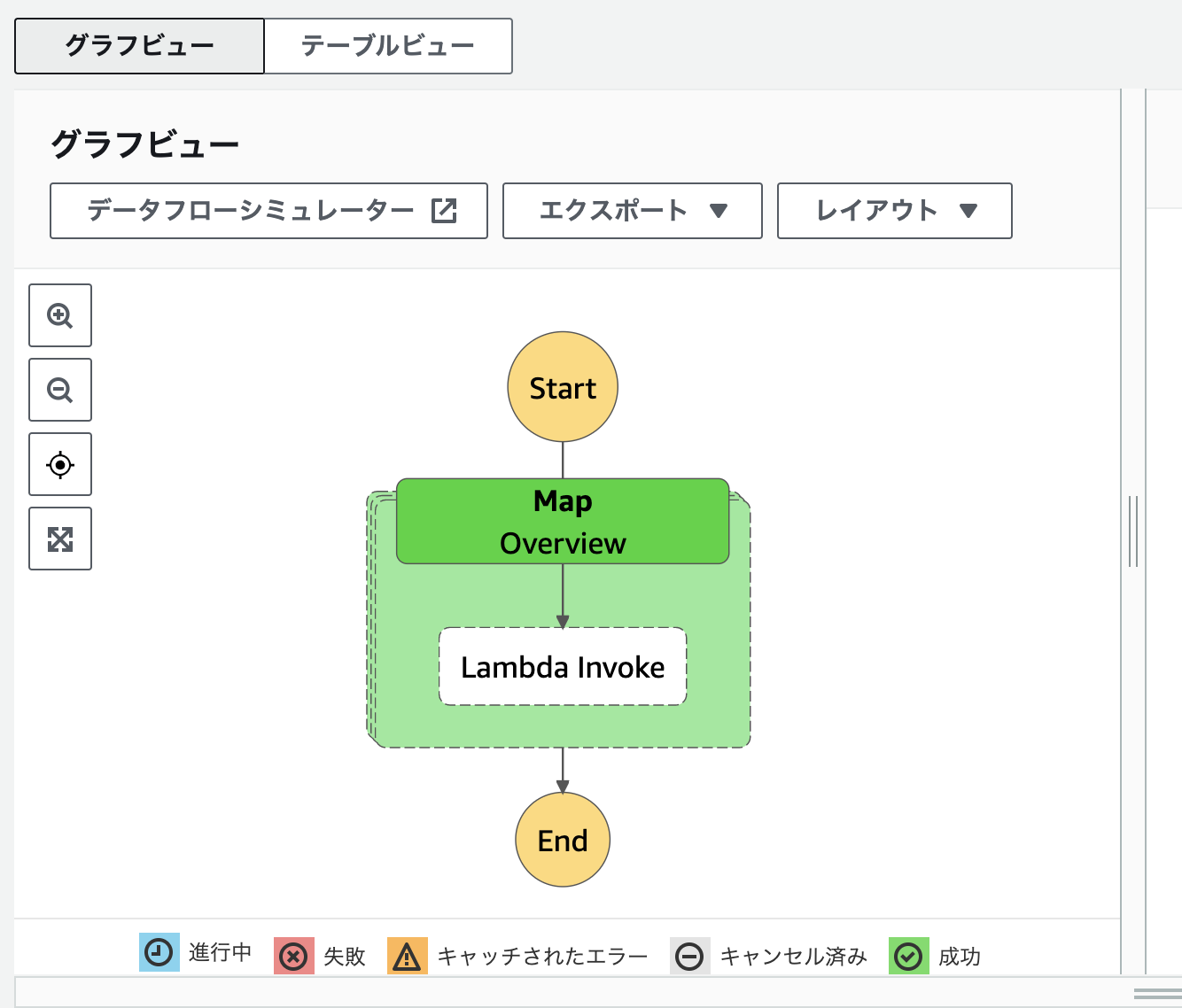
上手く実行できると、グラフビューで以下のように緑色に表記されます。
これで、Step Funtionsを使ってLambdaの並列実行が実現できました。
とても簡単に構築できるので、色々と使えるユースケースが多いのではないでしょうか?
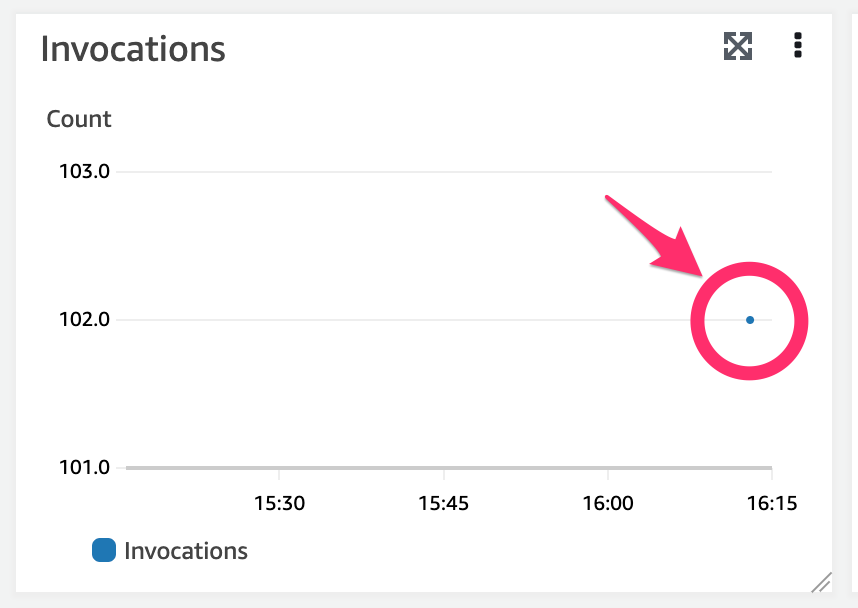
念の為、Lambda が本当に呼ばれているのかを確認したいと思います
Lambda のメトリクスから、 Invocation のメトリクスを確認してみて下さい。
今回は、100個のデータに対して実行したので、 100回の Lambda が Invocation されているのがわかるかと思います。
結果をS3バケットに集約
ここまでで、 AWS Step Functionsで、並列実行ができるところまで試してみました。
大規模な並列処理をしていると、処理結果をどこかにまとめたくなることがあると思います。
そこで、 Distributed Map の機能には、 S3バケットに集約できる機能があるので、試してみたいと思います。
集約するためには、Mapのアクションの中で、 Amazon S3 にエクスポートを有効にします。
そして、保存したい S3 バケットを指定すれば、完了です。
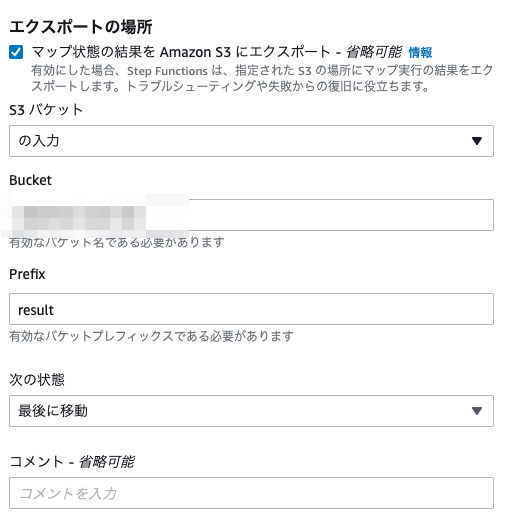
改めて、Step Functions を再実行すると、指定したバケットに結果が格納されることが確認できるかと思います。
出力されるファイルの種類は、以下のようになっています。
| ファイル名 | 説明 |
|---|---|
| manifest.json | エクスポート場所、Map Run ARN、結果ファイルに関する情報などの Map Run メタデータが含まれます。 |
| SUCCEEDED_n.json | 成功したすべての子ワークフロー実行のデータが含まれます。 n はファイルのインデックス番号を表します。 |
| FAILED_n.json | 失敗、タイムアウト、および中止されたすべての子ワークフロー実行のデータが含まれます。n はファイルのインデックス番号を表します。 |
| PENDIGN_n.json | Map 実行が失敗または中止されたために開始されなかったすべての子ワークフロー実行の統合データが含まれます。 n はファイルのインデックスを表します。 |
詳細を確認されたい方は、ドキュメントをみていただければと思います
実際に集約されたデータを見ると、このような感じで集約されていることがわかるかと思います。
さらに、この集約結果をカスタマイズしたい場合は、ResultSelector などを活用して、変換することもできます。
{
"_1": [
{
"ExecutionArn": "arn:aws:states:ap-northeast-1:xxxxx:express:MyStateMachine/Map:ced2d88d-a16f-35b2-828f-df89bdd6d304:8ee65604-203b-435f-8a8f-b78e348d7147",
"Input": "{\"Items\":[{\"undefinedid\":\"3303\",\"name\":\"FMV5G@test.net\"}]}",
"InputDetails": {
"Included": true
},
"Name": "ced2d88d-a16f-35b2-828f-df89bdd6d304",
"Output": "{\"statusCode\":200,\"inputReceived\":{\"Items\":[{\"undefinedid\":\"3303\",\"name\":\"FMV5G@test.net\"}]}}",
"OutputDetails": {
"Included": true
},
"StartDate": "2022-12-15T05:17:46.827Z",
"StateMachineArn": "arn:aws:states:ap-northeast-1:xxxxxxx:stateMachine:MyStateMachine/Map",
"Status": "SUCCEEDED",
"StopDate": "2022-12-15T05:17:46.888Z"
}
}
まとめ
ここまでで、 AWS Step Functions Distributed Map を簡単ではありますが、試してみました。
簡単に、並列実行を実現できるのは、すごく魅力的な機能ではないでしょうか。
今まで、 AWS Step Functions だと合わなかったユースケースも、使えるケースもあると思います。
ぜひ、皆さんも、 AWS Step Functions を活用してみてください。
免責
本投稿は、個人の意見で、所属する企業や団体は関係ありません。
また掲載しているサンプルプログラム等の動作に関しても一切保証しておりません。