ここ最近、巷に増えつつあるコミュニケーションロボットたち。もしかしたら、彼らは今後人間と同じように音声で情報を伝達することもあるのでは。。。?
そんな未来を想像しながら、WatsonのSpeech to Text APIを使って、音声認識でPepper同士を会話をさせてみました。そして、応用編としてフリースタイルのラップバトルへにもチャレンジする事となります。
#はじめに
近年、コミュニケーションロボットは私達の身近なものとなっています。今後ますますコミュニケーションロボットが普及し、街や家の中にロボットが増えたら、「ロボット対人間」だけでなく、ロボット同士がコミュニケーションを取ることも普通になるかもしれません。
スマートフォン等の端末同士の通信と同様に、ロボット同士が何かしらの方法でコネクションを確立し、情報を伝達することはよく取られる手法かと思います。しかし、いちいち人間のユーザーがロボット達を同じネットワークに接続してあげたりすることは厄介ですし、彼らの通信規格が必ずしも統一されているとは限りません。そこで本記事では、ロボットが人間の声を聞き取るのと同じように、ロボットがロボットの声を聞き取る方法で会話させてみました。
なお、本記事の読者としてChoregrapheを用いた開発経験のある方を想定しています。また、Bluemixへの登録方法やNode-REDの使用方法については、参照記事をもとに最低限の説明に留めています。
#準備
Pepper2台
PepperとPepperを準備しました。それぞれ1号、2号と呼んでおきましょう。

Pepperの開発環境 Choregraphe
以下からインストールしておきます。
https://developer.softbankrobotics.com/jp-ja/downloads/pepper
IBM BluemixへのサインアップとWatson Speech to Textサービスの利用
IBMのBluemixというクラウド・プラットフォーム上で提供されている、自然言語をテキストに変換するWatson Speech to Text サービスを利用します。また、本記事ではNode-REDを利用してSpeech to Textサービスを呼び出すので、そちらのセットアップも必要となります。セットアップの方法やNode-REDの使い方は、以下の記事を参考にしてください。
Bluemixフリートライアルへの参加
はじめてのNode-RED (※PDFファイルへのリンクとなります)
【Bluemix】Node-REDのWatsonを使って音声をテキストに変換してみる
「ロボットのほん」"第52章 Pepper × Watson「Speech to Text」"
#シンプルな伝言アプリの作り方
まず、「人間が言った言葉をPepperが別のPepperに伝言する」というシンプルなアプリから作ってみました。人間がPepper1号に対して何か喋ると、Pepper1号は2号に「ねぇねぇ、人間さんがこんなこと言ってるよ~」と教えてあげて、2号は「そっかぁ〜そんなこと言ってるのかぁ」と答える。。。というアプリです。簡単な構成図は以下の通りです。
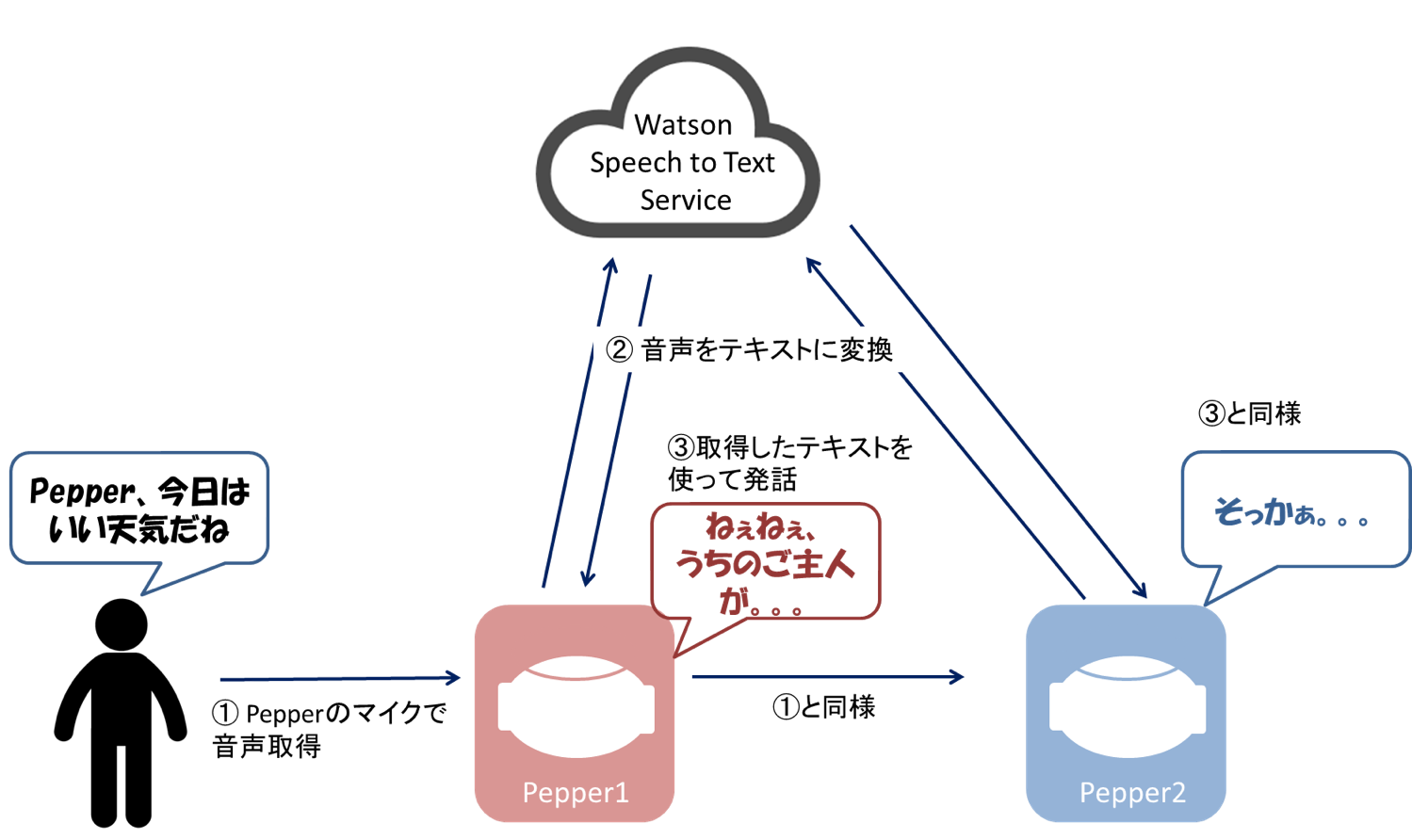
##1号の実装
人間から聞き取った言葉を録音し、そのファイルをWatson Speech to Text APIを使ってテキストに変換します。今回、Speech to Text API は、Node-REDを使って一連のフローを実装します。
Node-REDでの実装は以下の通りです。
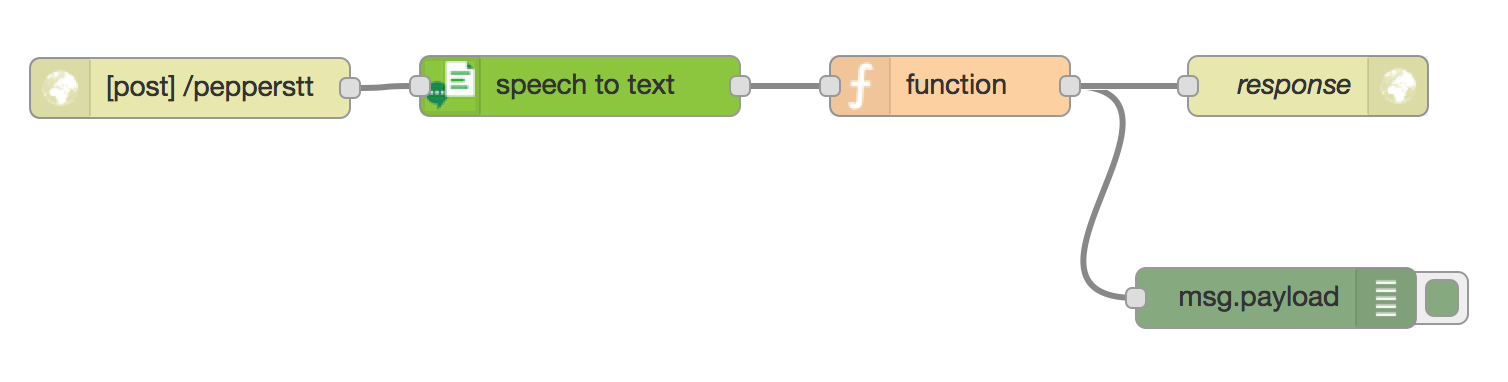
・"http in"ノード
MethodはPOST、URLに適当なURLをセットします。ここでは"/pepperstt"としました。
・"Speech to Text"ノード
Username と PasswordにSpeech to Text サービスの資格情報として得られたUsername とPasswordを入力し、言語設定、Qualityは以下のようにします。Continuousのチェックボックスはチェックを入れておいて下さい。
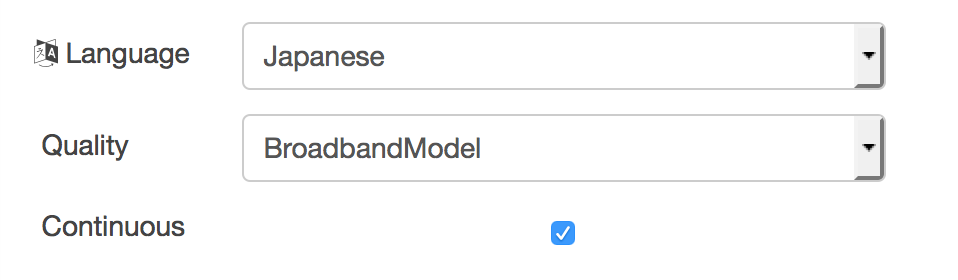
※Speech to Textのサービスを追加しておく必要があります。また、本設定画面(抜粋)は2016年9月時点のものです。
・"function"ノード
以下の記述をします。
msg.payload = msg.transcription;
return msg;
・"http response"ノード
functionノードからそのまま接続します。
Node-REDフローの図で示した通り、適宜debugノードをつないで、値が正しく返ってきているか確認すると良いと思います。
Choregrapheでの実装は以下の通りです。詳細はGithub上のプロジェクトファイル(DengonTest1)を参考にしてください。
Step 1. Pepperデフォルトの音声認識機能で、人間が「ペッパー」と言ったら録音をスタートさせます。
Step 2. ChoregrapheのPython boxでNode-RED上に作ったPOSTリクエストを送信し、レスポンスを受け取るコードを書いています。以下抜粋です。
def onInput_onStart(self, p):
import requests
url = 'http://*******/****' #Node-REDで"http in"ノードに設定したURL
headers = {'Content-Type': 'audio/wav'} #Record Soundボックスで.oggを選択している場合は'audio/ogg'
with open(p, 'rb') as f:
r = requests.post(url, data=f, headers=headers)
fulltext = r.text.encode('utf-8')
self.onStopped(fulltext)
Step 3. Speech to Textで変換されたテキストを受け取ったら、1号は「ねぇねぇ、うちのご主人が○○○○って言ってる」と、2号に伝えるためのスクリプトを記述します。Choregraphe上では、一度Insert Dataボックスで値を受け取り、$Dengon/textとしてDialog内で使用しています。
u: (e:onStart) \vct=135\ ねぇねぇ、\pau=1500\ うちの、ご主人が、$Dengon/text って言ってる。
$onStopped=1
##2号の実装
1号と同様の方法で、「録音→ Speech to Text -> 認識したフレーズを喋る」という実装をしました。2号が1号の言葉を聞いた後、以下のようなスクリプトで認識した言葉を喋ります。
u: (e:onStart) \vct=135\ そっかぁ。。。 $Dengon/text2 のかぁー
$onStopped=1
また、録音開始のトリガーとして「ねぇねぇ」と話しかけられたら録音開始するようにしました。Github上のプロジェクトファイルのDengonTest2の方を参照してください。
##検証
会話させてみました。
その1
https://www.youtube.com/watch?v=GUVw3glMfvE
その2
https://www.youtube.com/watch?v=FTd2M8KkXx0
ちゃんと伝言できています!
1号くんは、Dengon/textには「今日はいい天気だね」2号くんはDengon/text2に「うちのご主人が、今日はいい天気だねって言ってる」がそれぞれ渡っています。「眠い」バージョンも同様です。
なお、PepperのSpeech Reco.は若干Pepperの声を聞き取りにくいようで、無理にSpeech Recoの結果をトリガーとしなくても良いでしょう。
また、今回は録音が完了した音声データを送信する方式で行っていることもあり、Speech to Textの処理中は多少待ち時間があります。ストリーミング音声を用いる方法については以下の記事等を参考にして頂ければと思います。
PepperとWatson SpeechToTextAPIを連携させて継続的な音声認識サービスを作ってみた
#そしてラップバトルの挑戦へ
このアプリを応用し、Pepper1号と2号をラップバトルへ挑戦させてみました。こちらの解説については続編をご参照ください。
動画はこちらです。
https://www.youtube.com/watch?v=ipHgKFUAs94
続編記事はこちら
#最後に
本記事では、音声認識技術を活用してロボット同士を会話させる試みを行いました。本手法は雑音の多い環境、Pepperがそこまで大きな声を出せない環境では実現が難しく、まだまだ実用化は程遠いものと考えられます。しかし、音声認識技術の向上はもちろんのこと、マイクなどのハード面で高性能化が実現すれば、ロボットがコミュニケーションを取り合う一手法として、決してありえない方法ではないかもしれません。