はじめに
以前こちらの記事で2クラス分類について紹介した。
ただ、データセットが簡単すぎたため、この記事で紹介したtoyota_carsデータセットで画像分類をしてみる。
なお、toyota_carsデータセットはKaggleで公開されているもの。
https://www.kaggle.com/datasets/occultainsights/toyota-cars-over-20k-labeled-images
ラベル付け
toyota_carsで公開されている38種類の車種のうち2種類をピックアップし、画像分類ができるかを試してみる。
画像とそのラベルをリストで保存し、pytorchのDatasetに設定する方式をとる。ラベル付けは以下のように行った。
import os
def get_files_list_toyota_cars(path_input, label_0=None, label_1=None):
if (label_1 == None) or (label_1==None):
print('if mode toyota_cars, select label name as label_0 and label_1')
return
path_label_0 = os.path.join(path_input, label_0)
path_label_1 = os.path.join(path_input, label_1)
dict_list_filenames = {
label_0: os.listdir(path_label_0),
label_1: os.listdir(path_label_1)
}
list_file = []
for key, val in dict_list_filenames.items():
if key == label_0:
label = 0
for filename in val:
list_file.append([os.path.join(path_label_0, filename), label, key])
elif key == label_1:
label = 1
for filename in val:
list_file.append([os.path.join(path_label_1, filename), label, key])
return list_file
ここで得たリストを、以下のDatasetに渡す。
import torch.utils.data as data
class MyDataset(data.Dataset):
def __init__(self, list_file, transform=None, phase='train'):
self.list_file = list_file
self.transform = transform
self.phase = phase
def __len__(self):
# ファイル数を返す
return len(self.list_file)
def __getitem__(self, index):
# 画像をPillowsで開く
path_image = self.list_file[index][0]
pil_image = Image.open(path_image).convert('RGB')
# 画像の前処理
image_transformed = self.transform(pil_image)
# ラベルを取得
label_class = self.list_file[index][1]
label_type = self.list_file[index][2]
return image_transformed, label_class
実験結果
この記事で調査した結果、最も画像枚数が多い車種はcamryとcorollaで、それぞれ2,000枚あった。まずはこの2種で分類ができないか試してみた。
評価は分類性能で図るため、accuracyを重視。
label_0とlabel_1のそれぞれに車種を入れ、上のget_files_list_toyota_carsに渡せば、データセットは得られる。
学習回数を増やすに連れて、スコアが上昇していることがわかるが、スコアが0.6程度までしか上昇せず。

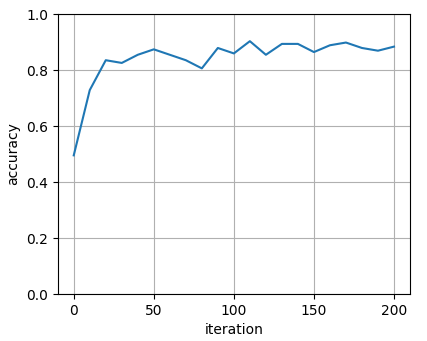
2番めに画像数の多い4runnerとhighlanderで試してみる。
学習回数を増やすに連れてスコアが上昇し、0.8程度まで上げられることを確認!
最後に
今回は以前紹介した2クラス分類問題のデータセットを変えて試してみた。
前よりも難易度が上がり、スコアは急に上昇することは無くなった。
今後は同じデータセットで、不均衡データセットの場合のクラス分類について挑戦してみる。