
はじめに
AI エージェントや RAG(検索拡張生成)にドキュメントを読み込ませたいとき、パース(テキスト抽出)の品質は地味に重要です。PyPDF や PyMuPDF のような定番ライブラリは高速ですが、テーブルやレイアウトが崩れてしまうことが多く、かといって VLM(Vision Language Model)ベースのパーサーは精度が高い反面、クラウド依存だったり GPU が必要だったりします。
そんな中、LlamaIndex チームが LiteParse というオープンソースのドキュメントパーサーを公開しました。LlamaParse のコア技術をベースに、ローカル環境で高速に動作する軽量パーサーです。
この記事では、LiteParse の概要と、実際に手元のファイルで試してみた結果を紹介します。
LiteParse とは
LiteParse は、LlamaIndex が開発したオープンソースの CLI / TypeScript ライブラリです。PDF、Office ドキュメント(DOCX / XLSX / PPTX)、画像(PNG / JPG / TIFF)など 50 以上のファイル形式に対応し、レイアウトを考慮したテキスト抽出を行います。
公式リポジトリ: https://github.com/run-llama/liteparse
ブログ記事: https://www.llamaindex.ai/blog/liteparse-local-document-parsing-for-ai-agents
主な特徴
- 完全ローカル実行 — クラウド API 不要、GPU 不要。すべてローカルマシン上で動作します
- 高速 — コモディティハードウェアで約 500 ページを 2 秒で処理
- 50 以上のファイル形式に対応 — PDF はもちろん、PPTX / DOCX / XLSX / HTML / 画像ファイルなどをサポート
- レイアウト保持型のパース — テーブルを Markdown に変換しようとするのではなく、空間的なグリッドにテキストを配置することでレイアウト情報を保持
- スクリーンショット機能 — ページの画像を生成できるため、マルチモーダル AI との連携にも便利
- オープンソース・無料 — MIT ライセンスで公開
LiteParse vs LlamaParse
LlamaIndex は有料クラウドサービスの LlamaParse も提供していますが、LiteParse はその軽量版という位置づけです。
LiteParse は、コーディングエージェントやリアルタイムパイプラインなど、速度・シンプルさ・ローカル実行が重要なユースケースに向いています。オンプレミスや OCI などのクラウドで閉域で使いたいときには嬉しいですね。
一方、密なテーブル、複雑なマルチカラムレイアウト、手書き文字、スキャン PDF など高い精度が求められる場面では、有料クラウドサービスのLlamaParse を使ってねということのようです。これが LlamaIndex さんのビジネスになるんですね。
設計思想 — 「構造検出」より「レイアウト保持」
多くのパーサーはテーブルを検出して Markdown に変換しようとしますが、この方法は複雑さと失敗パターンを増やしがちです。LiteParse のアプローチは異なり、テキストを空間グリッド上に配置することで、テーブルの行列関係を人間にも AI にも読みやすい形で保持します。とのことです。
確かに、テーブルを正しく Markdown に変換するのは難しいですよね。
インストール方法
npm でインストール
今回は、Windows の Git Bash 環境なのでこちらで試しています。
"-g"
npm i -g @llamaindex/liteparse
Homebrew でインストール(macOS / Linux)
brew tap run-llama/liteparse
brew install llamaindex-liteparse
ソースからビルド
git clone https://github.com/run-llama/liteparse.git
cd liteparse
npm run build
npm pack
npm install -g ./liteparse-*.tgz
インストール後、lit コマンド(LiteParse の CLI コマンド)が使えるようになります。
基本的な使い方
テキスト抽出
# PDF からテキストを抽出
lit parse document.pdf
# 出力形式を指定(json / text)
lit parse document.pdf --format json -o output.md
# 特定のページだけ抽出
lit parse document.pdf --target-pages "1-5,10,15-20"
# OCR なしでパース
lit parse document.pdf --no-ocr
# OCR の言語を指定(デフォルトは en)
lit parse document.pdf --ocr-language jpn
バッチ処理
# ディレクトリ内のドキュメントを一括処理
lit batch-parse ./input-directory ./output-directory
スクリーンショット
# 全ページのスクリーンショットを取得
lit screenshot document.pdf -o ./screenshots
# 特定のページだけ
lit screenshot document.pdf --target-pages "1,3,5" -o ./screenshots
# DPI を指定
lit screenshot document.pdf --dpi 300 -o ./screenshots
Office ドキュメント(PPTX、DOCX、XLSX)は内部で LibreOffice を使って PDF に変換されてからパースされます。画像ファイルは ImageMagick で PDF に変換された後、OCR 処理が行われます。
ベンチマーク
LiteParse チームは、PyPDF、PyMuPDF、Markitdown といった既存ライブラリとの比較ベンチマークを行っています。
ベンチマークの手法が興味深いです。一般的な OCR データセット(OlmOCR など)は LiteParse の出力形式(非 Markdown、レイアウトベースの改行)と合わないため、独自のパイプラインを構築しています。具体的には、ページのスクリーンショットから LLM で Q&A ペアを生成し、手動で監査した上で、各パーサーの出力に対して LLM-as-a-Judge で評価するという方式です。
結果として、LiteParse はページベースの Q&A タスクで高い精度を示し、大規模ドキュメントに対するパースの速度もトップクラスだったと報告されています。特にテーブルを含む PDF では、PyPDF がテーブル構造を破壊してしまうのに対し、LiteParse は空間グリッドで行列関係を保持できる点が優位とされています。
お試し実験
今回は、手元にあった日本語のプレゼンテーション資料で LiteParse を試してみました。
- AI駆動AI普及活動AAAP.pdf(約 1.9 MB、17 ページの PDF ファイル)
-
AI駆動AI普及活動AAAP.pptx(↑のPDFファイルの元になった 約 15 MB の PowerPoint ファイル)
テストには Node.js v24.1.0 + npm 10.8.2 がインストールされた Windows 11 環境を使用しました。
インストール
$ npm i -g @llamaindex/liteparse
added 58 packages in 5s
インストールはあっという間に終わりました。バージョンを確認します。
$ lit --version
0.1.0
PDF のパース結果
まず PDF ファイルをパースしてみます。
$ lit parse AI駆動AI普及活動AAAP.pdf -o result_pdf.txt
Processing file: AI駆動AI普及活動AAAP.pdf
Loaded PDF with 17 pages
Warning: TT: undefined function: 21
Running OCR on pages (concurrency: 15)...
OCR on page 1...
OCR on page 4...
OCR on page 6...
Found 0 text items from OCR on page 1
Found 49 text items from OCR on page 4
Found 22 text items from OCR on page 6
✓ Parsed 17 pages → result_pdf.txt
17 ページの PDF を約 6 秒で処理完了しました。自動的に画像を含むページ(1, 4, 6 ページ)を検出して OCR を実行しています。抽出されたテキストは 7,015 文字、383 行でした。
出力の一部を見てみましょう。テキスト中心のページ(2 ページ目)では、空間グリッドによるレイアウト保持が確認できます。
実際の 2 ページ目
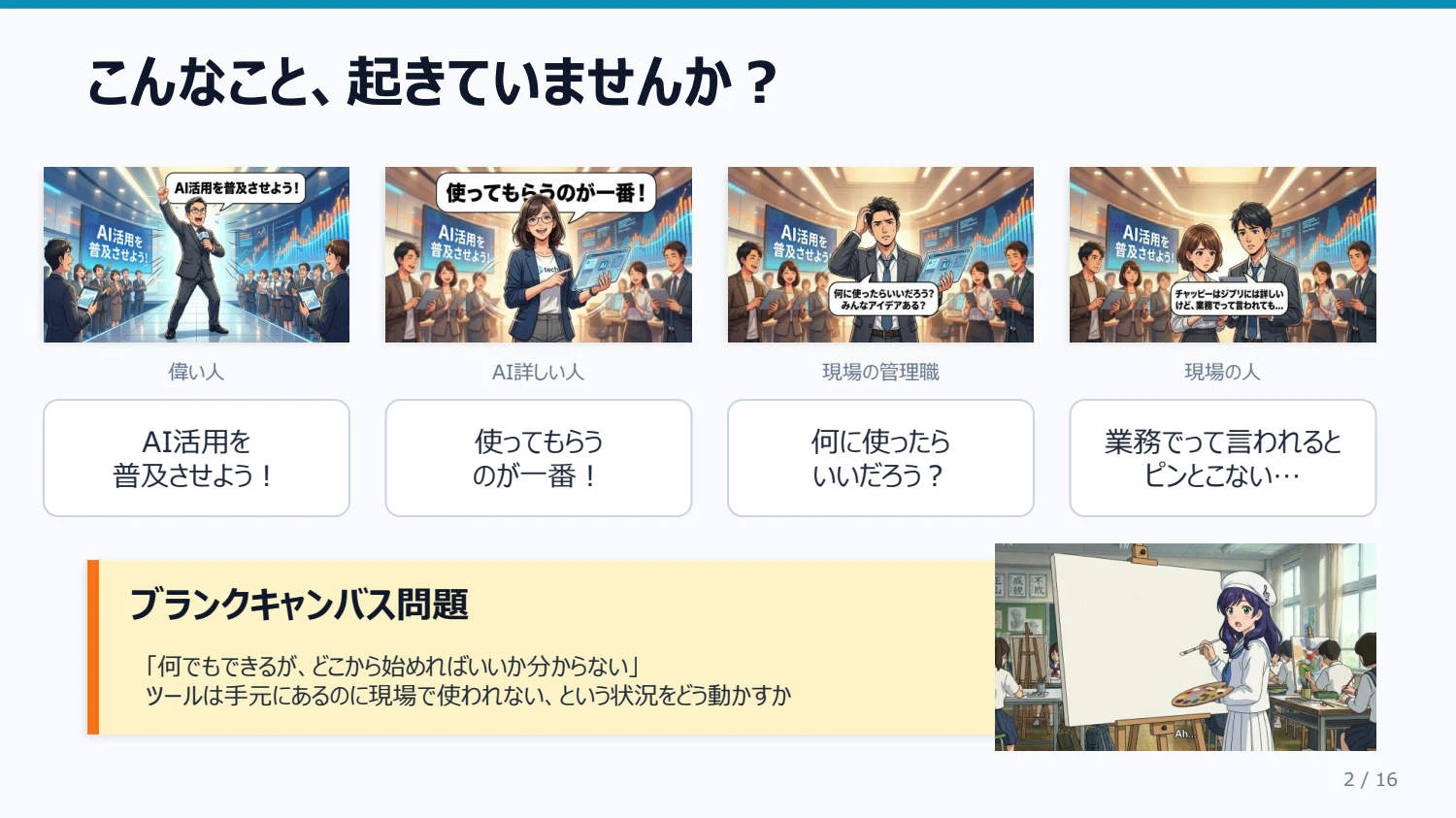
テキスト抽出結果
こんなこと、起きていませんか?
偉い人 AI詳しい人 現場の管理職 現場の人
AI活用を 使ってもらう 何に使ったら 業務でって言われると
普及させよう! のが一番! いいだろう? ピンとこない…
ブランクキャンバス問題
「何でもできるが、どこから始めればいいか分からない」
ツールは手元にあるのに現場で使われない、という状況をどう動かすか
4 つのカラムに並んだテキストが、スペースによる位置合わせでレイアウトを保っています。Markdown のテーブルに変換するのではなく、空間的な配置をそのまま保持するという LiteParse の設計思想がよく分かりますね。
テーブル構造を含むページ(14 ページ目)でも、行列の関係が読み取れる形で出力されています。
実際の 14 ページ目

テキスト抽出結果
第1段階 第2段階 第3段階
採用率を見る 行動変容を見る 成果を見る(任意)
AI体験ガイドの実行者数 → ワークフローにAIステップが含まれる → 業務サイクルタイム削減
発見共有ノートの共有率 割合 成果物の品質向上
AIツールの週間アクティブユーザー数 繰り返し利用の頻度 eNPS(従業員エンゲージメント)
一方、図やイラストが中心のページでは、OCR が画像内のテキストを読み取ろうとして英語のテキストの抽出には成功していますが、デフォルトでは日本語は全く抽出できていませんでした。
実際の 3 ページ目

テキスト抽出結果
N
Bz (Al-Driven Al Adoption Program)
HS
|
(@) AKER NO) = |
これは図形やイラスト内の文字を OCR が拾おうとした結果ですが、デフォルトの OCR 言語が英語(en)のため、日本語は認識できていません。
OCR 言語を日本語に指定してみる
lit parse --help を確認すると、--ocr-language オプションがあり、デフォルトは "en" になっています。日本語の jpn を指定して再実行してみます。
$ lit parse AI駆動AI普及活動AAAP.pdf --ocr-language jpn -o result_pdf_jpn.txt
Processing file: AI駆動AI普及活動AAAP.pdf
Loaded PDF with 17 pages
Warning: TT: undefined function: 21
Running OCR on pages (concurrency: 15)...
OCR on page 1...
OCR on page 4...
OCR on page 6...
Found 0 text items from OCR on page 1
Found 187 text items from OCR on page 4
Found 70 text items from OCR on page 6
✓ Parsed 17 pages → result_pdf_jpn.txt
OCR の検出数が大きく変わりました。ページ 4 は 49 → 187 アイテム、ページ 6 は 22 → 70 アイテムと、日本語テキストが認識されるようになっています。処理時間は約 7 秒で、英語 OCR のときとほぼ同じでした。
先ほど英語 OCR でノイズだらけだったページの抽出結果を比較してみましょう。
Al 駆動Al 普及活動(Al-Driven Al Adoption Program)
] 「" 教 える "」』か ら "Al を 使う 体験 "へ、普 及 活動 その ものを Al で 駆動 する アプロー チ
Al 、 の 。 = チームの気づき |
発見
共有 用 上
...
N 問題の解消 Al が 対話 ・ 整 理・統 合 を 担い、意 思 決 定の主体は参加者 (人
英語 OCR では「N」「Bz」「HS」のようなノイズだったものが、日本語 OCR では「Al 駆動Al 普及活動」「チームの気づき」「問題の解消」といった日本語テキストが読み取れています。まだまだ完璧ではありませんが、元の画像中のテキストをある程度拾えるようになりました。
もう一つの画像ページ(ページ 5、プロセスの全体像)も改善されています。
プロ セス の 全体 像
大
の共有 3. チー ムの気づき
1. Al 体験 2. 発見
| | 発見
7 共有ノート チー ム 気づき ノン
日本語 OCR の課題として、文字間にスペースが入る(「プロ セス」→「プロセス」)、「AI」が「Al」(小文字のエル)と誤認識される、拾えていないテキストが沢山あるといった状況ではありますが、英語 OCR に較べると良くなってはいますね。
なお、jpn+eng のように複数言語を指定することも試みましたが、Tesseract のデータファイルが見つからないというエラーが出ました。LiteParse v0.1.0 時点では、OCR 言語は単一指定が安全なようです。
OCR モード別の比較
--no-ocr オプションを使うと、PDF 内の埋め込みテキストのみを抽出できます。
$ time lit parse AI駆動AI普及活動AAAP.pdf --no-ocr -o result_pdf_noocr.txt
Processing file: AI駆動AI普及活動AAAP.pdf
Loaded PDF with 17 pages
Warning: TT: undefined function: 21
✓ Parsed 17 pages → result_pdf_noocr.txt
real 0m0.870s
各モードの比較結果をまとめます。
| モード | 処理時間 | 文字数 | 行数 | 備考 |
|---|---|---|---|---|
--no-ocr |
約 0.87 秒 | 6,370 文字 | 345 行 | 埋め込みテキストのみ。最速 |
--ocr-language en(デフォルト) |
約 6 秒 | 7,015 文字 | 383 行 | 画像内の日本語は認識できない |
--ocr-language jpn |
約 7 秒 | 8,096 文字 | 384 行 | 画像内の日本語もある程度抽出 |
--ocr-language jpn を指定すると、デフォルトの英語 OCR と比べて処理時間はほとんど変わらず、画像内の日本語テキストも抽出できるようになります。ただし、実用的な精度が出ているかというと課題が残りますね。RAG などで使う際には、VLM や AI-OCR との併用が必要かもしれません。
と思って README.md を読んでいたら Optional: HTTP OCR Servers という機能があって外部の OCR サーバーを呼べるようです。これはいいかもしれませんね。HTTP サーバーを立てれば OCI Document Understanding のようなクラウドの OCR サービスと統合することもできそうです。
OCR サーバーが返す必要がある項目は、text、bounding box、confidence だけなので大抵の AI-OCR は使えそうですね。
VLM(マルチモーダルLLM)は、bounding box が難しそうですね。confidence は、モデルが返さない場合は 1.0 にしておけば良いようです(LiteParse OCR API Specification)。
JSON 形式の出力
--format json を指定すると、ページごとのテキストに加え、各テキスト要素の座標・フォント情報が得られます。
$ lit parse AI駆動AI普及活動AAAP.pdf --format json -o result_pdf.json
出力の一部です。
{
"pages": [
{
"page": 1,
"width": 720,
"height": 405,
"text": "AI駆動AI普及活動\n\nAI-Driven AI Adoption Program (AAAP)\n\n社内AI活用の「何から始めれば?」をAIで突破する\n\n\n荒川 裕二",
"textItems": [
{
"text": "AI",
"x": 57.6,
"y": 91.37,
"width": 49.88,
"height": 39.96,
"fontName": "g_d0_f1",
"fontSize": 39.96
},
{
"text": "駆動",
"x": 107.42,
"y": 91.37,
"width": 79.92,
"height": 39.96,
"fontName": "g_d0_f2",
"fontSize": 39.96
}
]
}
]
}
座標情報が含まれているため、プログラムから位置ベースのテキスト抽出や、レイアウト分析に活用できます。
スクリーンショット機能
lit screenshot コマンドで、PDF の各ページを画像として出力できます。
$ lit screenshot AI駆動AI普及活動AAAP.pdf --target-pages "1-3" -o ./screenshots
Generating screenshots for: AI駆動AI普及活動AAAP.pdf
Rendering page 1...
Rendering page 2...
Rendering page 3...
Generated 3 screenshots
✓ ./screenshots/page_1.png (720x405)
✓ ./screenshots/page_2.png (720x405)
✓ ./screenshots/page_3.png (720x405)
✓ Generated 3 screenshots → ./screenshots
 |
|
 |
3 ページ分のスクリーンショットが約 2 秒で生成されました。デフォルトでは、720×405 の PNG 画像として出力されます。マルチモーダル AI にドキュメントの内容を理解させたい場合、テキスト抽出結果とスクリーンショットを組み合わせることで、テキストだけでは伝わらない図表の情報も補えますね。
PPTX のパース
LiteParse は Office ドキュメント(PPTX / DOCX / XLSX)を内部で LibreOffice を使って PDF に変換してからパースする仕組みです。LibreOffice がインストールされていない状態で PPTX ファイルをパースしようとすると、以下のようなエラーが出ます。
$ lit parse AI駆動AI普及活動AAAP.pptx -o result_pptx.txt
Processing file: AI駆動AI普及活動AAAP.pptx
Error: Conversion failed: LibreOffice is not installed. Please install LibreOffice
to convert office documents.
On macOS: brew install --cask libreoffice
On Ubuntu: apt-get install libreoffice
On Windows: choco install libreoffice-fresh
Windows 環境では winget でインストールできます。
$ winget install --id TheDocumentFoundation.LibreOffice
LibreOffice をインストールした上で再度実行してみます。
$ lit parse AI駆動AI普及活動AAAP.pptx --ocr-language jpn -o result_pptx.txt
Processing file: AI駆動AI普及活動AAAP.pptx
Converted .pptx to PDF
Loaded PDF with 17 pages
Warning: TT: undefined function: 21
Running OCR on pages (concurrency: 15)...
OCR on page 1...
OCR on page 4...
OCR on page 6...
Found 0 text items from OCR on page 1
Found 206 text items from OCR on page 4
Found 52 text items from OCR on page 6
✓ Parsed 17 pages → result_pptx.txt
PPTX から PDF への変換を含めて約 40 秒で処理が完了しました。内訳としては、LibreOffice による PPTX → PDF 変換に約 33 秒、その後の PDF パースに約 7 秒です。抽出されたテキストは 7,116 文字、390 行でした。
PDF を直接パースした場合(8,096 文字)と比べると約 1,000 文字少ないですが、これは LibreOffice が生成する PDF と元の PDF でレイアウトが若干異なるためです。テキストの内容としては同等の品質でした。PDF をすでに持っている場合は、PDF を直接パースするのが速度面で有利です。
実験から分かったこと
- 日本語テキストは正しく抽出される — PDF 内の埋め込みテキストレイヤーからの抽出精度は高く、日本語の文字化けはありませんでした
- レイアウト保持は効果的 — マルチカラムのレイアウトやテーブルが、空間グリッドで読みやすく配置されています
-
日本語ドキュメントでは画像中のテキストも抽出したい場合は、
--ocr-language jpnを忘れずに — デフォルトの英語 OCR では画像内の日本語が認識されません。jpnを指定すると処理時間はほぼ変わらず、画像内テキストの抽出量が大幅に増えます。ただし、内臓の OCR では、取りこぼしも多いので外部の OCR サーバーを呼び出すような構成も要検討です。 - 処理速度は非常に高速 — 17 ページの PDF で OCR ありでも約 7 秒、OCR なしなら 1 秒未満
- PPTX もパース可能だが LibreOffice が必要 — LibreOffice さえインストールすれば PPTX も問題なくパースできます。ただし PDF 変換のオーバーヘッド(約 33 秒)があるため、PDF が手元にあるならそちらを使う方が効率的です。
まとめ
LiteParse は、RAG を使った質問応答システムでも選択肢として検討に値すると思いますが、「速度」と「手軽さ」を両立している点で特に AI エージェントのためのドキュメントパースにおいて有力な選択肢と言えそうです。GPU もクラウド API も不要で、npm install 一発でセットアップが完了し、CLI からすぐに使い始められます。
実際に日本語の PDF と PPTX で試したところ、テキスト抽出の精度は良好で、特にレイアウト保持型のアプローチがマルチカラムやテーブルで効果を発揮していました。17 ページの PDF を 1 秒未満(OCR なし)〜 7 秒(OCR あり)で処理できる速度も魅力的です。
日本語ドキュメントを扱う際は --ocr-language jpn の指定が重要です。デフォルトの英語 OCR では画像内の日本語を認識できませんが、日本語を指定するだけで抽出量が大きく変わりました。文字間にスペースが入る、「AI」が「Al」と誤認識される、取りこぼしが多いといった OCR 特有の課題はありますが、画像内のテキストをある程度拾えるようになります。
また、JSON 出力による座標情報やスクリーンショット機能は、マルチモーダル AI との連携パイプラインで重宝しそうです。
もちろん、複雑なレイアウトやスキャン文書に対しては LlamaParse のようなより高精度なツールが必要になる場面もあるでしょう。ただ、コーディングエージェントに素早くドキュメントの内容を理解させたい、RAG パイプラインのデータ準備をローカルで手軽にやりたい、といったユースケースでは、LiteParse は非常に良い選択肢だと思います。
あとがき、あるいは、pdfminer.six との比較と RAG への影響
PDFファイルのパースを pdfminer.six とちょっと比較してみました。
入力PDFファイルは、ウィキペディアの「お隣の天使様にいつの間にか駄目人間にされていた件」をツールメニューの「PDF形式でダウンロード」で取得したものを使いました。
| pdfminer.six | LiteParse | |
|---|---|---|
| 変換時間 | 1.44秒 | 2.81秒 |
| 行数 | 818 | 1560 |
| 全文字数 | 22,554 | 32,010 |
| 空白、タブを 除いた文字数 |
20,038 | 20,836 |
行数が大きく違っているのは、段組みや表などのレイアウトの違いの扱いが異なることによるもののようです。
全文字数の違いは、LiteParse はレイアウトを表現するために空白を多用するため多くなっているようです。
ウィキペディアの「お隣の天使様にいつの間にか駄目人間にされていた件」 を見ていただくとわかるようにこのページは左に作品の説明が書かれていて(本文)、右には表形式で作品の属性がまとめられています(インフォボックス)。
pdfminer.six は、本文側とインフォボックスを分けて出力するため行数が多くなります。一方で、LiteParse は、レイアウトに関わらず同じ行(もしくは、同じ高さ)のテキストをすべて出力してから改行するようで行数が少なくなります(実レイアウトに近い行数)。ただし、本文とインフォボックスのようにレイアウト上のパーツが異なっているとそのパーツの位置を表現するために空白が多用されるので全文字数は多くなっているようです。
ウィキペディアの冒頭部分
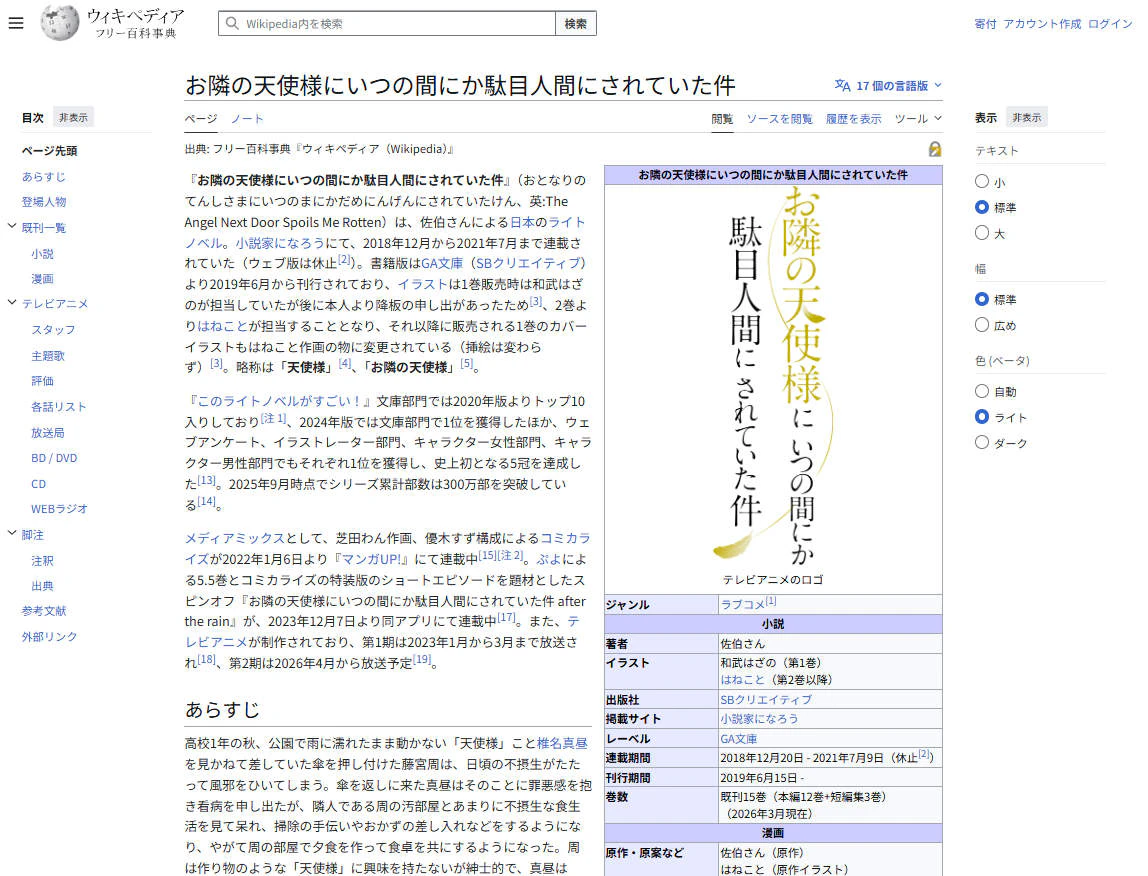
pdfminer.six の変換結果
お隣の天使様にいつの間にか駄⽬⼈間にされ ていた件出典: フリー百科事典『ウィキペディア(Wikipedia)』
『お隣の天使様にいつの間にか駄
⽬⼈間にされていた件』(おとな
りのてんしさまにいつのまにかだ
めにんげんにされていたけん、
英 :The Angel Next Door Spoils Me
Rotten)は、佐伯さんによる⽇本
のライトノベル。⼩説家になろう
にて、2018年12⽉から2021年7⽉
まで連載されていた(ウェブ版は
休⽌[2])。書籍版はGA⽂庫(SB
クリエイティブ)より2019年6⽉
から刊⾏されており、イラストは
1巻販売時は和武はざのが担当し
ていたが後に本⼈より降板の申し
出があったため[3]、2巻よりはね
ことが担当することとなり、それ
以降に販売される1巻のカバーイ
ラストもはねこと作画の物に変更
さ れ て い る ( 挿 絵 は 変 わ ら
ず) [3]。略称は「天使様」 [4]、
「お隣の天使様」[5]。
『このライトノベルがすごい!』
⽂庫部⾨では2020年版よりトップ
10⼊りしており[注 1]、2024年版で
は ⽂ 庫 部 ⾨ で 1 位 を 獲 得 し た ほ
か、ウェブアンケート、イラスト
レーター部⾨、キャラクター⼥性
部⾨、キャラクター男性部⾨でも
それぞれ1位を獲得し、史上初と
なる5冠を達成した[13]。2025年9
⽉時点でシリーズ累計部数は300
万部を突破している[14]。
メディアミックスとして、芝⽥わ
ん作画、優⽊すず構成によるコミ
カライズが2022年1⽉6⽇より『マ
ンガUP!』にて連載中[15][注 2]。ぷ
お隣の天使様にいつの間にか駄⽬⼈間にされていた件
テレビアニメのロゴ
ジャンル
ラブコメ[1]
著者
イラスト
出版社
掲載サイト
レーベル
連載期間
刊⾏期間
⼩説
佐伯さん
和武はざの(第1巻)
はねこと(第2巻以降)
SBクリエイティブ
⼩説家になろう
GA⽂庫
2018年12⽉20⽇ - 2021年7⽉9⽇(休⽌[2])
2019年6⽉15⽇ -
よによる5.5巻とコミカライズの
特装版のショートエピソードを題
材としたスピンオフ『お隣の天使
様にいつの間にか駄⽬⼈間にされ
ていた件 after the rain』が、2023
年12⽉7⽇より同アプリにて連載
中[17]。また、テレビアニメが制
作されており、第1期は2023年1⽉
から3⽉まで放送され[18]、第2期
は2026年4⽉から放送予定[19]。
あらすじ
⾼校1年の秋、公園で⾬に濡れた
まま動かない「天使様」こと椎名
真昼を⾒かねて差していた傘を押
し付けた藤宮周は、⽇頃の不摂⽣
がたたって⾵邪をひいてしまう。
傘を返しに来た真昼はそのことに
罪悪感を抱き看病を申し出たが、
隣⼈である周の汚部屋とあまりに
不摂⽣な⾷⽣活を⾒て呆れ、掃除
の⼿伝いやおかずの差し⼊れなど
をするようになり、やがて周の部
屋で⼣⾷を作って⾷卓を共にする
ようになった。周は作り物のよう
な「天使様」に興味を持たないが
紳⼠的で、真昼は
LiteParse の変換結果
お隣の天使様にいつの間にか駄⽬⼈間にされ ていた件出典: フリー百科事典『ウィキペディア(Wikipedia)
』
『お隣の天使様にいつの間にか駄 お隣の天使様にいつの間にか駄⽬⼈間にされていた件
⽬⼈間にされていた件』
(おとな
りのてんしさまにいつのまにかだ
めに ん げ ん にされていたけ ん 、
英 :The Angel Next Door Spoils Me
Rotten)は、佐伯さんによる⽇本
のライトノベル。⼩説家になろう
にて、2018年12⽉から2021年7⽉
まで連載されていた(ウェブ版は
休⽌[2])
。書籍版はGA ⽂庫(SB
クリエイティブ)より 2019年6⽉
から刊⾏されており、イラストは
1巻販売時は和武はざのが担当し
ていたが後に本⼈より降板の申し
出があったため[3]、2巻よりはね
ことが担当することとなり、それ
以降に販売される1巻のカバーイ
ラストもはねこと作画の物に変更
さ れ て い る ( 挿 絵 は 変 わ ら
ず ) [3]。 略 称 は「 天 使 様 」 [4]、
「お隣の天使様」[5]。
『このライトノベルがすごい!』
⽂庫部⾨では2020年版よりトップ
10⼊りしており[注 1]、2024年版で テレビアニメのロゴ
は ⽂ 庫 部 ⾨ で 1 位 を 獲 得 し た ほ ジャンル ラブコメ[1]
か、ウェブアンケート、イラスト
レーター部⾨、キャラクター⼥性 ⼩説
部⾨、キャラクター男性部⾨でも 著者 佐伯さん
それぞれ1位を獲得し、史上初と イラスト 和武はざの(第1巻)
なる5冠を達成した[13]。2025年9 はねこと(第2巻以降)
⽉時点でシリーズ累計部数は300 出版社 SBクリエイティブ
万部を突破している[14]。 掲載サイト ⼩説家になろう
メディアミックスとして、芝⽥わ レーベル GA⽂庫
ん作画、優⽊すず構成によるコミ 連載期間 2018年12⽉20⽇ - 2021年7⽉9⽇(休⽌[2])
カライズが2022年1⽉6⽇より『マ 刊⾏期間 2019年6⽉15⽇ -
ンガUP!』にて連載中[15][注 2]。ぷ
よによる 5.5巻とコミカライズの 巻数 既刊15巻(本編12巻+短編集3巻)
特装版のショートエピソードを題 (2026年3⽉現在)
材としたスピンオフ『お隣の天使 漫画
様にいつの間にか駄⽬⼈間にされ 原作‧原案など 佐伯さん(原作)
ていた件 after the rain』が、 2023 はねこと(原作イラスト)
年12⽉7⽇より同アプリにて連載
中[17]。また、テレビアニメが制 作画 芝⽥わん
作されており、第1期は2023年1⽉ 出版社 スクウェア‧エニックス
から3⽉まで放送され[18]、第2期 掲載サイト マンガUP!
は2026年4⽉から放送予定[19]。 レーベル ガンガンコミックス
発表期間 2022年1⽉6⽇ -
あらすじ 巻数 既刊6巻(2025年10⽉現在)
その他 構成:優⽊すず
⾼校1年の秋、公園で⾬に濡れた 漫画:お隣の天使様にいつの間にか駄⽬⼈間にされていた件
まま動かない「天使様」こと椎名 after the rain
真昼を⾒かねて差していた傘を押 原作‧原案など 佐伯さん(原作)
し付けた藤宮周は、⽇頃の不摂⽣ はねこと(原作イラスト)
がたたって⾵邪をひいてしまう。 作画 ぷよ
傘を返しに来た真昼はそのことに 出版社 スクウェア‧エニックス
罪悪感を抱き看病を申し出たが、 掲載サイト マンガUP!
隣⼈である周の汚部屋とあまりに
不摂⽣な⾷⽣活を⾒て呆れ、掃除 レーベル ガンガンコミックスUP!
の⼿伝いやおかずの差し⼊れなど 発表期間 2023年12⽉7⽇ -
をするようになり、やがて周の部 巻数 既刊2巻(2025年4⽉現在)
屋で⼣⾷を作って⾷卓を共にする アニメ
ようになった。周は作り物のよう 原作 佐伯さん
な「天使様」に興味を持たないが 監督 王麗花(第1期)
紳⼠的で、真昼は
これだけ見て同じ行に本文とインフォボックスの作品属性が混在している LiteParse は RAG に不向きに感じてしまいますが、実際に gpt-5 に、上の LiteParse の変換結果を与えて、以下のようなプロンプトで質問すると正確に答えることができました。
添付の情報を元に以下の質問に答えてください。 添付情報からだけでは答えられない場合は回答できないと答えてください。 質問:添付情報にある「あらすじ」をすべて教えてください。
以下が、添付情報に記載されている「あらすじ」の全文です。
⾼校1年の秋、公園で⾬に濡れたまま動かない「天使様」こと椎名真昼を⾒かねて差していた傘を押し付けた藤宮周は、⽇頃の不摂⽣がたたって⾵邪をひいてしまう。傘を返しに来た真昼はそのことに罪悪感を抱き看病を申し出たが、隣⼈である周の汚部屋とあまりに不摂⽣な⾷⽣活を⾒て呆れ、掃除の⼿伝いやおかずの差し⼊れなどをするようになり、やがて周の部屋で⼣⾷を作って⾷卓を共にするようになった。周は作り物のような「天使様」に興味を持たない
次に、以下のような表を見てみます。

pdfminer.six の変換結果
スタッフ原作
キャラクター原案
監督
監修
シリーズ構成‧シナリオ
キャラクターデザイン
サブキャラクターデザイン
プロップデザイン
美術監督
⾊彩設計
CGラインディレクター
撮影監督
編集
⾳響監督
⾳楽
⾳楽プロデューサー
第1期[18][73]
第2期[19]
佐伯さん
はねこと
王麗花
今泉賢⼀
⼤知慶⼀郎
野⼝孝⾏
N/A
新⾕真昼
三宅昌和
有尾由紀⼦
齋藤威志
上條智也
丹彩⼦
明⽥川仁
⽇向萌
有⾺由⾐
熊野千尋
未公表
倉橋N濘
河合良介
鈴⽊よう
こ
未公表
三嶋章紀
未公表
⾳楽制作
東宝ミュージック、ミラクル‧バス
⾼橋敦司、武井克弘、⻑瀬奈津⼦、伊藤裕史、外川明宏、中路亮輔、
⼭下良平
未公表
⽥⼝翔⼀朗、松本⼀貴、三輪靖史、三浦史、佐藤潤、富原⼤稀、
⾦⼦広孝
椛⾕智司
project No.9
アニメ「お隣の天使様」製作委員会
チーフプロデューサー
プロデューサー
アニメーションプロデュー
サー
制作
製作
表の形は維持されず1カラムづつ改行して出力されます。
LiteParse の変換結果
スタッフ 第1期[18][73] 第2期[19]
原作 佐伯さん
キャラクター原案 はねこと
監督 王麗花 熊野千尋
監修 今泉賢⼀ 未公表
シリーズ構成‧シナリオ ⼤知慶⼀郎
キャラクターデザイン 野⼝孝⾏
サブキャラクターデザイン N/A 倉橋N濘
プロップデザイン 新⾕真昼
美術監督 三宅昌和 河合良介
⾊彩設計 有尾由紀⼦ 鈴⽊よう
こ
CGラインディレクター 齋藤威志 未公表
撮影監督 上條智也
編集 丹彩⼦ 三嶋章紀
⾳響監督 明⽥川仁 未公表
⾳楽 ⽇向萌
⾳楽プロデューサー 有⾺由⾐
⾳楽制作 東宝ミュージック、ミラクル‧バス
チーフプロデューサー ⾼橋敦司、武井克弘、⻑瀬奈津⼦、伊藤裕史、外川明宏、中路亮輔、
⼭下良平 未公表
プロデューサー ⽥⼝翔⼀朗、松本⼀貴、三輪靖史、三浦史、佐藤潤、富原⼤稀、
⾦⼦広孝
アニメーションプロデュー 椛⾕智司
サー
制作 project No.9
製作 アニメ「お隣の天使様」製作委員会
タグや罫線などの区切りで明確に構造は表現されていませんが、表の構造は、カラムの並び位置に残っています。
ここで今度は以下のような質問をしてみました。
添付の情報を元に以下の質問に答えてください。 添付情報からだけでは答えられない場合は回答できないと答えてください。 質問:2期の編集者は?
未公表です。添付情報では第2期の「編集」は未公表と記載されています。
完全にテーブルの構造を見誤って間違った回答をしています。
2期の編集者は三嶋章紀です。
こちらは正解できています。