はじめに
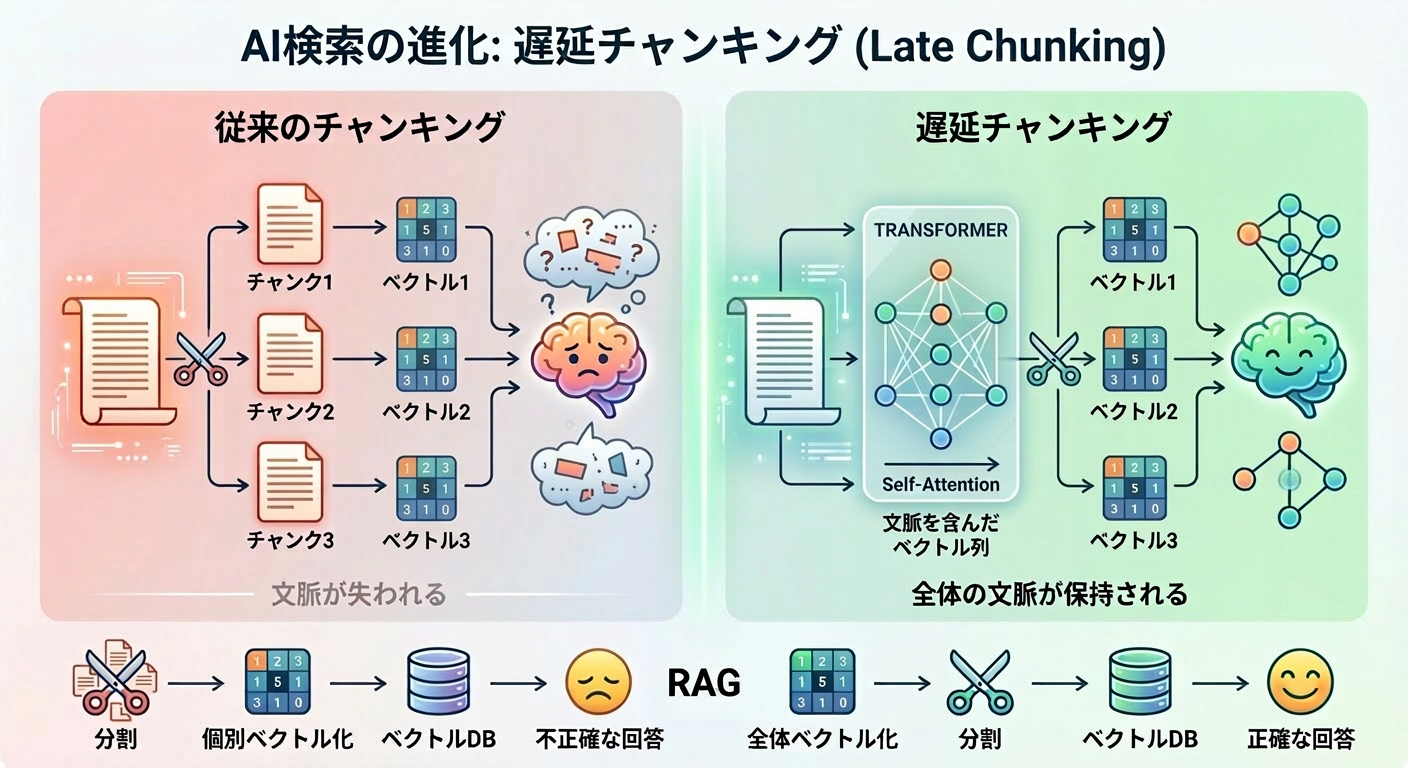
Web検索と AI による回答生成が一体となったAI検索エンジン(AI アンサーエンジン)が世の中に出始めの頃、こんな経験をしたことはなありませんでしたか?
「OCI の API Gateway には、どんな機能がありますか?」と質問したら OCI だけでなく、AWS や Google Cloud、Alibaba Cloud などの API Gateway の情報を引っ張って来てイイトコドリしたスーパー API Gateway の仕様をでっちあげて回答してきた!
AI検索エンジン(AI アンサーエンジン)も、質問に基づいて検索を行って検索結果を AI に渡して回答を生成するという意味では、RAG(Retrieval-Augmented Generation ー 検索拡張生成)の一種と言えるわけですが、この問題は RAG あるあるで、原因はチャンク分割にあります。長い文書を小さなチャンクに分割してからベクトル化すると、「API Gateway の主要な機能は…です」というチャンクが、どの会社の API Gateway について説明しているのかわからなくなってしまうんですね。そして、全部併せてスーパー API Gateway 爆誕 となるわけです!
これを回避するためには、Web検索を元にしたAI検索エンジン(AI アンサーエンジン)であろうと社内文書を格納したデータベースの検索を元にしている場合であろうと、まずはメタデータによるフィルタリングが使われます。しかし、そのWebサイトやページの素性やデータベースに登録されているドキュメントのタイトルや素性はメタデータにできても文書内の細かな文脈すべてをタグとしてメタデータに設定することは不可能です。
2024年に Jina AI が提案した「遅延チャンキング(Late Chunking)」は、この問題に対するエレガントな解決策です。そして 2026年2月、Perplexity AI がリリースした pplx-embed ファミリーは、この遅延チャンキングを API 一発で実現できるモデルを提供しています。
本記事では、私なりに理解した遅延チャンキングの考え方と、実際に pplx-embed を試してみた実験結果をご紹介します。
この記事の内容は私個人の経験・見解であり所属する企業・団体・組織を代表するものではありません。
RAG におけるチャンキングの課題
なぜチャンキングが必要なのか
RAG の R(Retrieval、つまり、検索)はベクトルデータベースで実現しなければならないということは 全くありませんが、このブログはベクトル化がテーマですので、RAG については、ベクトル検索を使っていることを前提としています。
RAG では、検索対象の文書をベクトルデータベースに格納します。しかし、埋め込みモデルには入力長の制限があり、また長すぎるテキストを1つのベクトルにまとめると意味が薄まってしまいます。そこで、文書を適切な大きさの「チャンク」に分割してからベクトル化するのが一般的です。
文脈が失われる問題
このアプローチには根本的な問題があります。チャンクに分割した時点で、チャンク間の文脈が失われてしまうのです。
具体的な例で見てみましょう。ある文書に以下の3つのチャンクがあるとします。
チャンク1: 「蒼月ロボティクス株式会社は2012年に大阪で創業した先端企業である。
AI技術を活用した産業用ロボットの開発で知られている。」
チャンク2: 「同社の画像認識AIは製造ラインの不良品検出に特化しており、
99.7%の検出精度を実現している。」
チャンク3: 「同社の予測分析プラットフォームは、製造設備のセンサーデータから
72時間以内に故障が起きる確率を推測する。」
ここで「蒼月ロボティクスの予測分析サービスは何を予測していますか?」と質問した場合を考えます。
人間が読めば、チャンク3の「同社」が蒼月ロボティクスを指していることは明らかです。しかし、チャンク3だけを切り出してベクトル化すると、「同社」がどの会社を指すのかという情報が失われてしまいます。
もし他にも予測分析を行っている企業のチャンクが9社分あったら、10社のチャンクがすべて似たようなスコアで返されてしまい、正解にたどり着けなくなります。
これが「チャンキングしてからベクトル化する」従来手法の限界です。
遅延チャンキング ー 発想の転換
ベクトル化してからチャンキングする
遅延チャンキング(Late Chunking)の発想はシンプルです。
チャンキングしてからベクトル化するか、ベクトル化してからチャンキングするか。
従来手法では「先に分割してから、それぞれをベクトル化」していました。遅延チャンキングでは、この順番を逆にします。「先に文書全体をベクトル化してから、分割する」のです。
なぜこれで解決するのか
Transformer の Self-Attention は、文書全体のトークン間の関係を計算します。文書全体を Transformer に通すと、チャンク3の「同社」というトークンは、チャンク1の「蒼月ロボティクス」というトークンを参照した状態のベクトル表現になります。
つまり、文書全体を見た後で分割することで、各チャンクのベクトルに「このチャンクが文書全体の中でどういう位置づけにあるか」という文脈情報が埋め込まれるのです。
これにより、チャンク3の「同社の予測分析プラットフォームは…」というベクトルには、「同社 = 蒼月ロボティクス」という情報がすでに含まれており、「蒼月ロボティクスの予測分析」というクエリと正しくマッチするようになります。
遅延チャンキングの処理ステップ
技術的な処理の流れを整理すると、以下の4ステップになります。
ポイントは、ステップ2の時点で各トークンのベクトルが文書全体の文脈を反映しているということです。ステップ3で分割しても、その文脈情報は各チャンクのベクトルに保持されます。
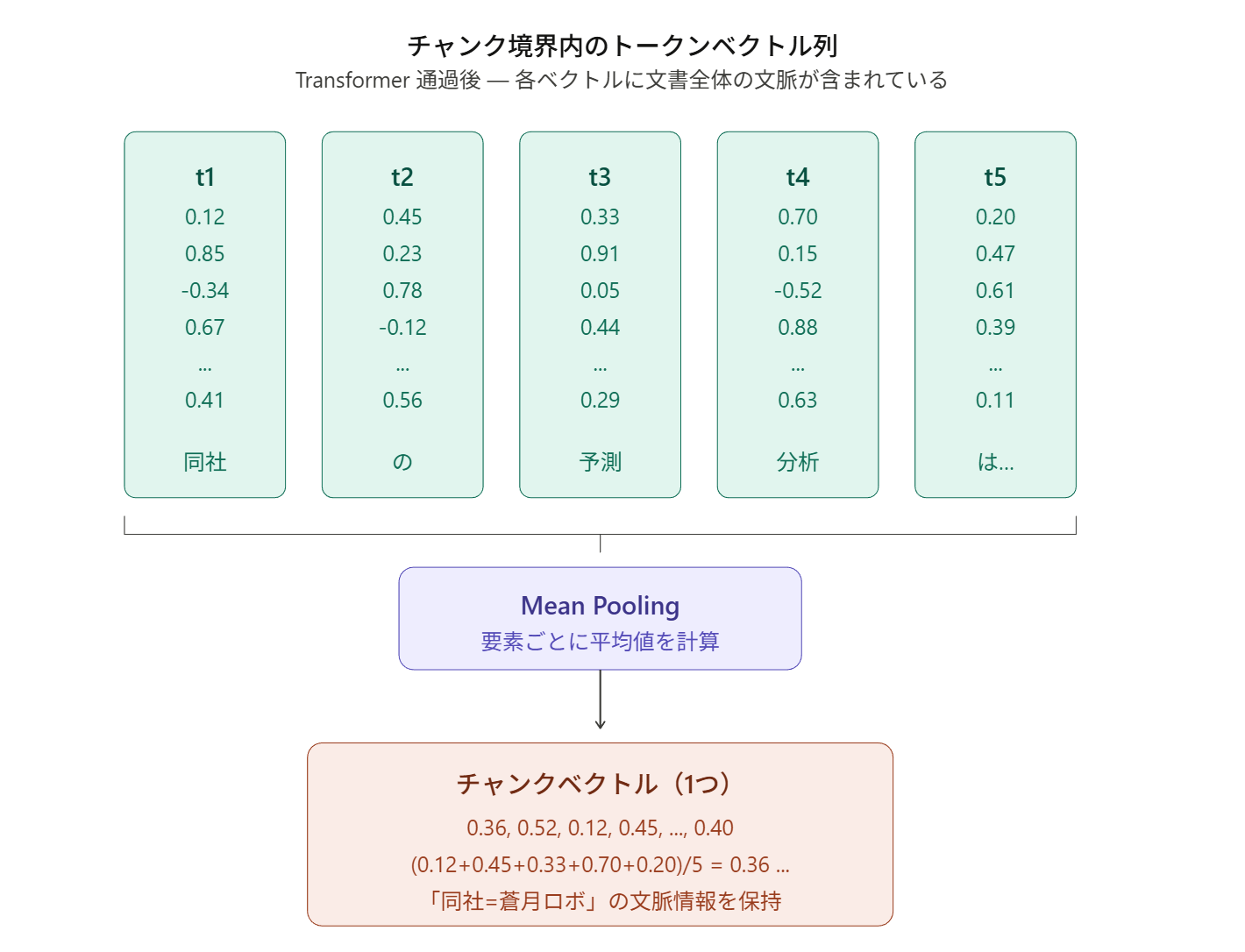
ステップ4の平均プーリングについてもう少し詳しく見てみましょう。ステップ3でチャンク境界によって分割されたトークンベクトル列には、1つのチャンクの中に複数のトークンベクトルが含まれています。たとえば「同社の予測分析は…」というチャンクが5トークンで構成されていれば、5つのベクトルが存在します(t1~t5)。しかし、ベクトルデータベースに格納するにはチャンクごとに1つの代表ベクトルが必要です。そこで、チャンク内の全トークンベクトルを各次元ごとに平均し、1つのベクトルに集約します。これが平均プーリング(Mean Pooling)です。ここで重要なのは、平均化される前の各トークンベクトルにはすでに文書全体の文脈が Self-Attention によって織り込まれているという点です。そのため、平均後のチャンクベクトルにも「同社 = 蒼月ロボティクス」という文脈情報がしっかりと保持されます。
Perplexity の pplx-embed ファミリー
2つのモデル
2026年2月、Perplexity AI は遅延チャンキングを組み込んだ埋め込みモデルファミリーをリリースしました。
| モデル | 用途 | サイズ |
|---|---|---|
| pplx-embed-v1 | 標準的なベクトル検索・クエリの埋め込み | 0.6B / 4B |
| pplx-embed-context-v1 | 文書文脈を考慮したチャンク埋め込み(遅延チャンキング) | 0.6B / 4B |
使い分けは非常にシンプルです。
- インデックス構築時(文書チャンク側)→ pplx-embed-context-v1 を使用
- 検索時(クエリ側)→ pplx-embed-v1 を使用
入力形式の違い
2つのモデルの最大の違いは入力形式です。通常版は文字列のフラットなリストを受け取りますが、文脈対応版は「文書ごとにチャンクをグループ化したリストのリスト」を受け取ります。
# pplx-embed-v1(通常版)ー 文字列のフラットなリスト
texts = ["チャンク1", "チャンク2", "チャンク3"]
# pplx-embed-context-v1(文脈対応版)ー 文書ごとにチャンクをグループ化
doc_chunks = [
["文書Aのチャンク1", "文書Aのチャンク2", "文書Aのチャンク3"], # 文書A
["文書Bのチャンク1", "文書Bのチャンク2"], # 文書B
]
文脈対応版にリストのリストを渡すだけで、モデルが内部で遅延チャンキングの処理を行ってくれます。開発者が意識するのは入力形式の違いだけです。
その他の特徴
pplx-embed ファミリーには他にもいくつかの注目すべき特徴があります。
- インストラクションプレフィックス不要 ー 多くの埋め込みモデルでは
"query: "や"passage: "等のプレフィックスを付与する必要がありますが、pplx-embed ではプレフィックスなしでそのままテキストを渡すことができます - ネイティブ INT8 量子化 ー 学習時から INT8 量子化を前提として訓練されているため、最大32倍のストレージ圧縮が可能です
- 32K トークンのコンテキスト長 ー 長い文書もそのまま処理できます
- MIT ライセンス ー オープンソースで商用利用可能です
- Perplexity AI の APIサービスでも、セルフホスティングでも利用可能
実験 ー 本当に効果があるのか検証してみた
実験設計
遅延チャンキングの効果を検証するため、意図的に照応解決が難しい状況を作りました。
遅延チャンキングの動作の理解を深めるためと効果を確かめるために意図的に文全体のコンテキストが必要なデータセット(ドキュメントと質問群)を用意しています。この結果の正解率などをどんな文書・データに対しても成り立つ汎用的なものと思わないでください。
架空のAI企業10社を用意し、すべての企業が「画像認識AI」「音声AI」「予測分析」という同じ3種類の技術を持つように設計しました。各社5チャンク、合計50チャンクです。
ポイントは以下の通りです。
- チャンク0 にだけ社名が出現し、チャンク1〜4 では「同社」「この企業」「この〇〇の企業」で参照されている
- 10社が同じ技術分野を持つため、社名の文脈なしでは正解チャンクを特定するのが非常に困難
この条件で、「〇〇社の△△技術は?」のようなクエリ10問を実行し、従来手法と遅延チャンキングの検索結果を比較しました。
実験で使用したコード
この記事の最後の Appenxid-1 に掲載しています。
結果(ローカル版 0.6B)
まず、ローカル環境で 0.6B モデルでベクトル検索した結果です。
- クエリのベクトルと全チャンクのベクトルのコサイン類似度を計算して、類似度が高い順に 3件を取り出しています。正解チャンクがこの 3件に入っていない場合は下の表では「圏外」と記載しています
- 遅延CKは、遅延チャンキングを意味しています
| Q | クエリ | 従来手法 | 遅延CK | 改善 |
|---|---|---|---|---|
| Q1 | 星風テクノロジーズの画像認識AI技術はどこで使われている? | 圏外 | #1 (0.5992) | 圏外→1位 |
| Q2 | 蒼月ロボティクスの予測分析サービスは何を予測していますか? | 圏外 | #1 (0.5733) | 圏外→1位 |
| Q3 | 翠嶺データサイエンスの音声AI技術はどのような成果を? | 圏外 | #2 (0.4784) | 圏外→2位 |
| Q4 | 暁光システムズの画像認識AIの検出精度 | #3 (0.6021) | #1 (0.6693) | +0.0673 |
| Q5 | 碧海テックラボの音声AIシステムの特徴 | #2 (0.5462) | #1 (0.6169) | +0.0707 |
| Q6 | 京都のAI企業のAI予測分析の経済効果 | #2 (0.5059) | #1 (0.5067) | +0.0009 |
| Q7 | 朱鷺AIソリューションズの画像認識AIは何の自動化に? | 圏外 | #2 (0.5386) | 圏外→2位 |
| Q8 | 広島のAI企業の音声AIの学習効果 | 圏外 | #3 (0.4518) | 圏外→3位 |
| Q9 | 金沢のAI企業の予測分析の不正検知性能 | #1 (0.6417) | #1 (0.6561) | +0.0144 |
| Q10 | 蒼月ロボティクスの画像認識AIの不良品検出率 | #1 (0.6994) | #1 (0.7373) | +0.0379 |
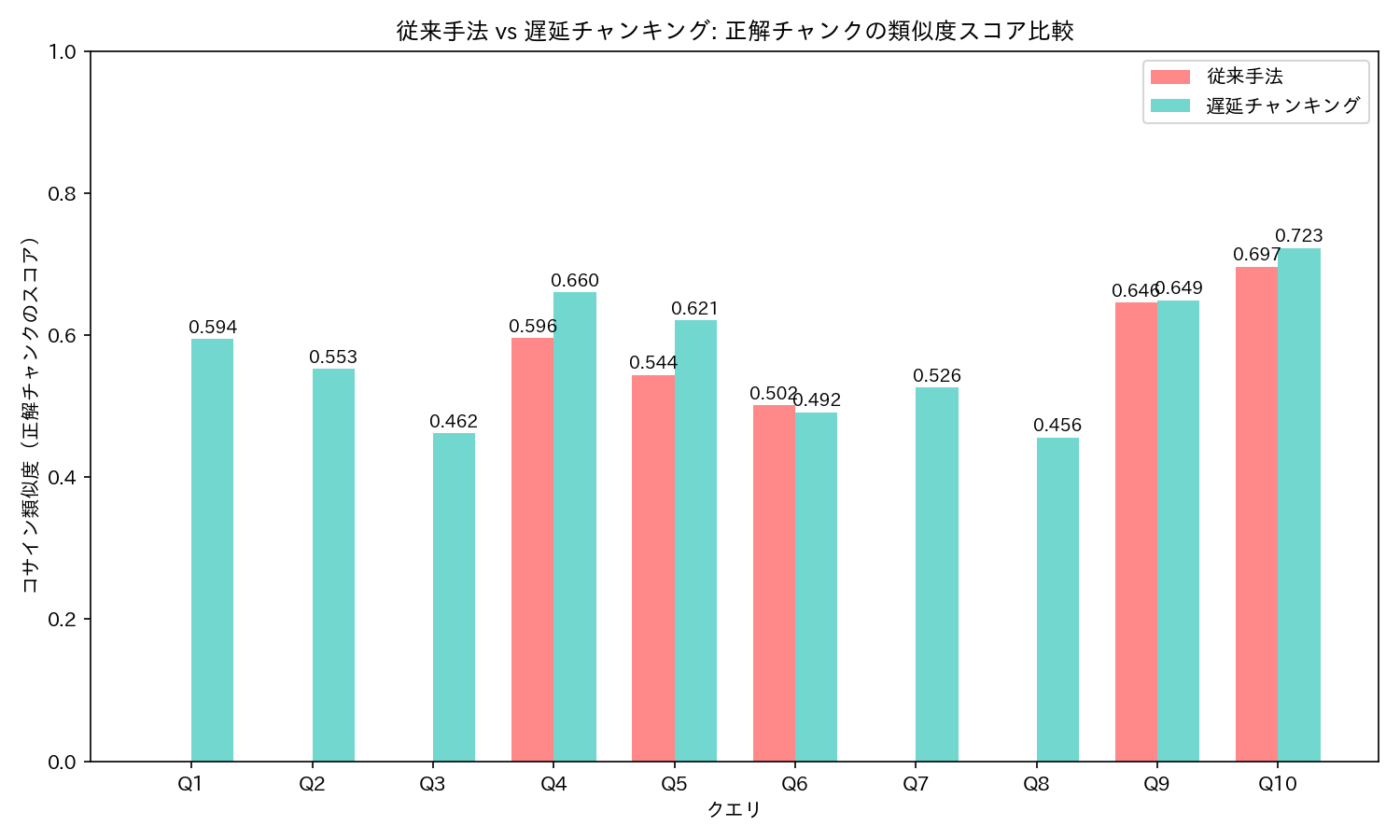
結果は非常に明確でした。
Q1〜Q3、Q7、Q8 の5問では、従来手法は正解チャンクを上位3件に入れることすらできませんでした。これは、10社すべてが同種のAI技術チャンクを持っているため、「同社の画像認識AIは…」のようなチャンクがどの会社のものか判別できず、無関係な会社のチャンクが上位に来てしまったためです。遅延チャンキングではこれらすべてを上位3位以内に引き上げています。
一方、Q9 と Q10 は「不正検知」「不良品検出率」というキーワードが正解チャンクに固有であるため、従来手法でも1位を取得できています。このように、キーワードマッチが効くケースでは従来手法でも十分な精度が出ます。遅延チャンキングが特に威力を発揮するのは、代名詞や指示語の解決が必要な場面です。
結果(API版 4B)
次に、Perplexity API 経由で 4B モデルを使った結果です。
| Q | 従来手法 | 遅延CK | 改善 |
|---|---|---|---|
| Q1 | 圏外 | #1 (0.6436) | 圏外→1位 |
| Q2 | #3 (0.5236) | #1 (0.6773) | +0.1537 |
| Q3 | #3 (0.5398) | #1 (0.6138) | +0.0740 |
| Q4 | 圏外 | #1 (0.6707) | 圏外→1位 |
| Q5 | #2 (0.5105) | #1 (0.6327) | +0.1223 |
| Q6 | 圏外 | #1 (0.5029) | 圏外→1位 |
| Q7 | #3 (0.5544) | #2 (0.6621) | +0.1077 |
| Q8 | #2 (0.5816) | #1 (0.5438) | 順位改善 |
| Q9 | #1 (0.6890) | #1 (0.6473) | -0.0416 |
| Q10 | #1 (0.6605) | #1 (0.7235) | +0.0630 |
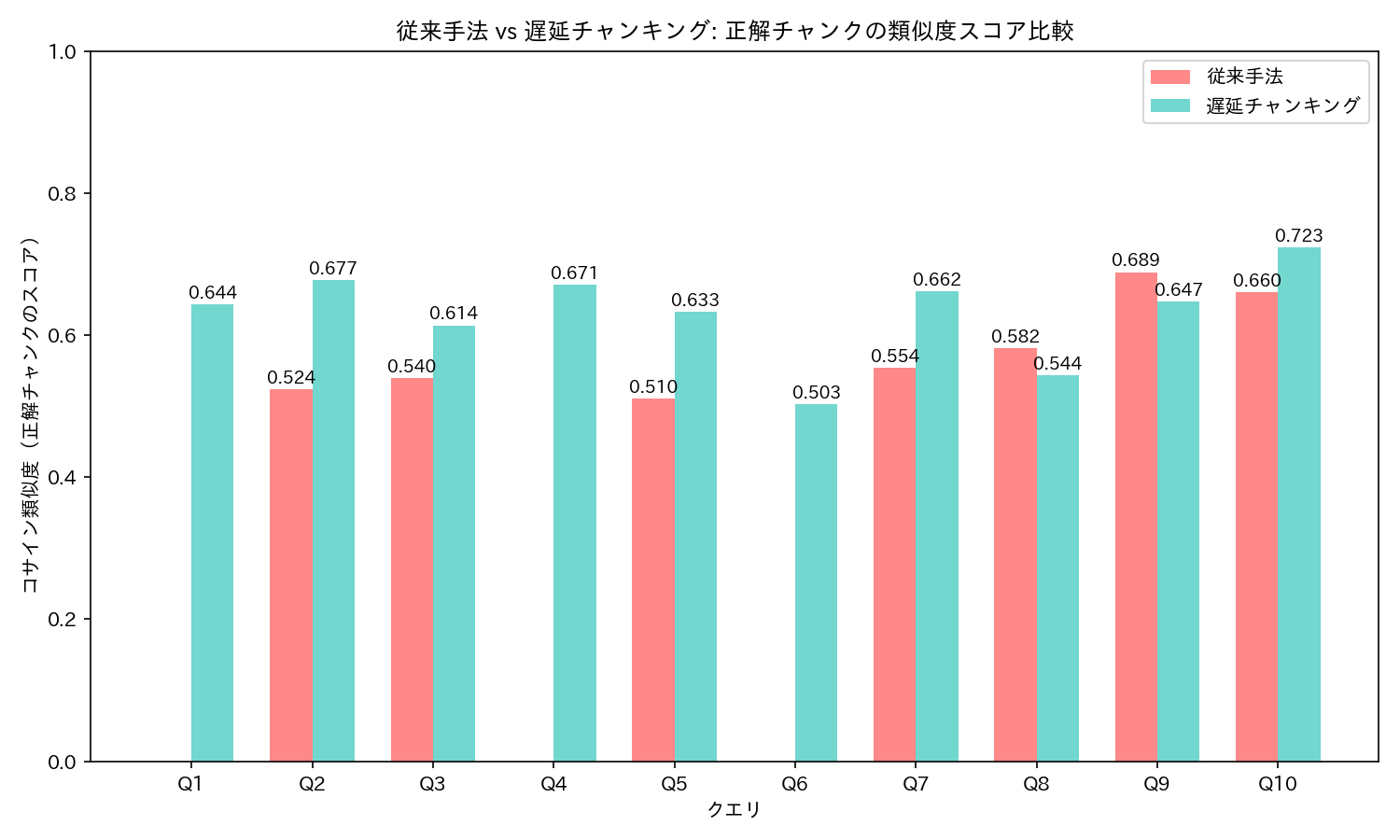
4B モデルでは、Q2 で類似度スコアが +0.1537 という大幅な改善が見られました。モデルの表現力が高くなるほど、遅延チャンキングとの相乗効果が大きくなる傾向があるのかもしれませんね。
興味深いのは Q4 と Q6 です。0.6B では従来手法でも #2〜#3 に入っていたクエリが、4B ではかえって正解チャンクを見失っています。モデルが大きいほど多様な意味を捉えられる反面、文脈なしでは類似チャンクに引き寄せられやすくなるのかもしれません。いずれにしても、遅延チャンキングを使えばすべて正解しています。
全実行の横断比較
3パターンの実行結果を並べてみます。
| Q | ローカル 0.6B | API 0.6B | API 4B |
|---|---|---|---|
| Q1 | 圏外→#1 | 圏外→#1 | 圏外→#1 |
| Q2 | 圏外→#1 | 圏外→#1 | #3→#1 |
| Q3 | 圏外→#2 | 圏外→#2 | #3→#1 |
| Q4 | #3→#1 | #3→#1 | 圏外→#1 |
| Q5 | #2→#1 | #2→#1 | #2→#1 |
| Q6 | #2→#1 | #2→#1 | 圏外→#1 |
| Q7 | 圏外→#2 | 圏外→#2 | #3→#2 |
| Q8 | 圏外→#3 | 圏外→#3 | #2→#1 |
| Q9 | #1→#1 | #1→#1 | #1→#1 |
| Q10 | #1→#1 | #1→#1 | #1→#1 |
すべての実行で一貫して、遅延チャンキングは正解チャンクの順位を改善または維持しています。
実装方法
API版(手軽に試したい場合)
Perplexity API を使えば、モデルのダウンロードなしで遅延チャンキングを試すことができます。
※課金が発生します!
pip install requests numpy
従来手法(通常版)での埋め込み
import requests
import numpy as np
HEADERS = {
"Authorization": f"Bearer {PERPLEXITY_API_KEY}",
"Content-Type": "application/json",
}
# 従来手法 ー 各チャンクを個別にエンコード
resp = requests.post(
"https://api.perplexity.ai/v1/embeddings",
headers=HEADERS,
json={
"input": ["チャンク1", "チャンク2", "チャンク3"], # フラットなリスト
"model": "pplx-embed-v1-0.6b",
"encoding_format": "base64_int8",
},
)
遅延チャンキング(文脈対応版)での埋め込み
# 遅延チャンキング ー 文書ごとにチャンクをグループ化してエンコード
resp = requests.post(
"https://api.perplexity.ai/v1/contextualizedembeddings", # エンドポイントが異なる
headers=HEADERS,
json={
"input": [
["文書Aのチャンク1", "文書Aのチャンク2"], # 文書A
["文書Bのチャンク1", "文書Bのチャンク2"], # 文書B
], # リストのリスト
"model": "pplx-embed-context-v1-0.6b",
"encoding_format": "base64_int8",
},
)
従来手法との違いは、エンドポイントが /v1/contextualizedembeddings に変わることと、入力をリストのリストにすることの2点だけです。既存の RAG パイプラインへの組み込みも容易です。
クエリの埋め込み
# クエリは常に通常版でエンコードする
resp = requests.post(
"https://api.perplexity.ai/v1/embeddings",
headers=HEADERS,
json={
"input": ["蒼月ロボティクスの予測分析サービスは何を予測していますか?"],
"model": "pplx-embed-v1-0.6b",
"encoding_format": "base64_int8",
},
)
クエリの埋め込みには常に通常版 pplx-embed-v1 を使用する点に注意してください。文脈対応版はインデックス構築時のみ使用します。
ローカル版(オンプレミスやクラウド内の閉じた環境で使いたい場合)
GPU がなくても 0.6B モデルなら CPU で動作します。もちろん、4B版もローカルで利用することができます。
pip install torch transformers sentence_transformers
from sentence_transformers import SentenceTransformer
from transformers import AutoModel
# 通常版(クエリ用 & 従来手法比較用)
model_std = SentenceTransformer(
"perplexity-ai/pplx-embed-v1-0.6B",
trust_remote_code=True,
)
# 文脈対応版(遅延チャンキング用)
model_ctx = AutoModel.from_pretrained(
"perplexity-ai/pplx-embed-context-v1-0.6B",
trust_remote_code=True,
)
# 従来手法 ー フラットなリストを渡す
naive_embeddings = model_std.encode(["チャンク1", "チャンク2", "チャンク3"])
# 遅延チャンキング ー 文書ごとのリストのリストを渡す
doc_embeddings = model_ctx.encode([
["文書Aのチャンク1", "文書Aのチャンク2"],
["文書Bのチャンク1", "文書Bのチャンク2"],
])
ローカル版では、通常版は SentenceTransformer 経由で encode() を呼び出し、文脈対応版は AutoModel 経由で encode() を呼び出します。文脈対応版の encode() は内部で文書全体を Transformer に通した後にチャンク境界で分割して Mean Pooling を適用しています。
RAG への影響
実際の RAG パイプラインでは、検索結果の上位K件が LLM に渡されます。従来手法で圏外だった正解チャンクが遅延チャンキングで1〜3位に入ることは、LLM の回答品質に直接影響します。
今回の実験で言えば、仮に RAG の G(Generate、つまり、回答の生成)で LLM に渡される検索結果が 3件だった場合、Q1〜Q3 のような照応解決が必要なクエリでは、従来手法だと正解チャンクが上位3件に含まれないため、LLM は正しい情報を参照できません。遅延チャンキングを使えば正解チャンクが1〜2位に入るため、LLM は正確な回答を生成できると期待できます。
まとめ
遅延チャンキングは「チャンキングしてからベクトル化するか、ベクトル化してからチャンキングするか」という処理順序の発想の転換で、ベクトル検索の精度を改善しようとする手法です。
今回の実験では以下のことが確認できました。
- 代名詞や指示語(「同社」「この企業」等)の解決が必要なクエリでは、従来手法で圏外だった正解チャンクが遅延チャンキングで1〜3位に浮上する
- キーワードが固有のケースでは従来手法でも十分な精度が出るが、遅延チャンキングはさらにスコアを上乗せする
- この傾向は 0.6B / 4B、ローカル / API のいずれの組み合わせでも一貫している
Perplexity の pplx-embed-context-v1 を使えば、API のエンドポイントと入力形式を変えるだけで遅延チャンキングを導入できます。既存の RAG パイプラインへの組み込みコストは非常に小さいので、試してみる価値がありそうですね。また、オンプレミスや閉域で使いたい場合には、Hugging Face からモデルをダウンロードしてセルフホストすることができます。ライセンスも MIT ですので安心して使えますね。
Appendix-1 使用したコード
ローカル版 pplx-embed-context-v1-0.6B 遅延チャンキングテストコード
"""
=============================================================================
pplx-embed-context-v1-0.6B 遅延チャンキング(Late Chunking)デモ
=============================================================================
従来手法チャンキング vs 遅延チャンキングの検索精度を比較するデモスクリプト。
■ 必要パッケージ:
uv pip install torch transformers numpy scikit-learn matplotlib japanize-matplotlib sentence_transformers
■ 実行:
uv run demo_late_chunking.py
■ ハードウェア:
- CPU のみでも動作(0.6B モデル)
- GPU(CUDA) があれば高速化される
"""
import warnings
from datetime import datetime
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# transformers の remote code(pplx-embed)由来の既知 FutureWarning を抑制
warnings.filterwarnings(
"ignore",
message=r"`input_embeds` is deprecated and will be removed in version 5\.6\.0 for `create_causal_mask`\. Use `inputs_embeds` instead\.",
category=FutureWarning,
)
# ============================================================================
# 1. サンプルデータ定義
# ============================================================================
# 文書: [文書名, [チャンク1, チャンク2, ...]]
DOCUMENTS = [
{
"title": "星風テクノロジーズ",
"chunks": [
"星風テクノロジーズ株式会社は2015年に札幌で設立されたスタートアップである。研究開発費は売上高の45%に達しており、業界平均の約3倍である。"
"研究員の約6割が博士号を保有し、論文発表数は国内スタートアップでトップクラスである。",
"この札幌の企業は、音声認識AIと自然言語処理AIを中核技術とし、医療・介護分野向けのソリューションを提供している。",
"同社の音声AIシステムは、高齢者の発話パターンから健康状態の変化を検知する。"
"全国200以上の介護施設に導入され、緊急搬送件数が平均30%減少した。",
"この企業は画像認識AI分野にも進出しており、内視鏡画像からポリープを自動検出する"
"診断支援システムを開発した。国内21の大学病院に導入されている。",
"同社の予測分析サービスは、電子カルテデータをもとに患者の再入院リスクを推定する。"
"予測精度は92%に達し、医療費削減への貢献が評価されている。",
],
},
{
"title": "蒼月ロボティクス",
"chunks": [
"蒼月ロボティクス株式会社は2012年に大阪で創業した先端企業である。"
"独自の触覚センサー技術を強みに、製造業・物流向けの協働ロボットを開発している。",
"同社の画像認識AIは製造ラインに組み込まれ、微細な傷や変形をリアルタイムで検出する。"
"不良品検出率は99.7%を達成し、自動車部品工場を中心に累計800ライン以上で稼働している。",
"AIロボティクスを得意とするこの企業は音声AIインターフェースも開発しており、工場の騒音環境下でもロボットに"
"音声指示を出せるシステムを実用化した。従来のタッチパネル操作比で作業効率が40%向上した。",
"同社の予測分析プラットフォームは、製造設備のセンサーデータから72時間以内に故障が起きる確率を推測する。"
"導入工場では計画外停止が85%減少し、設備稼働率が15ポイント向上した。",
"この大阪のメーカーは欧州市場への本格進出を計画しており、ミュンヘンに研究開発拠点を設立した。"
"現地の自動車メーカー3社との共同開発契約を締結し、2026年からの量産供給を目指している。",
],
},
{
"title": "翠嶺データサイエンス",
"chunks": [
"翠嶺データサイエンス株式会社は2018年に福岡で設立された先端データ分析企業である。"
"気象データと衛星画像を組み合わせた独自の予測プラットフォームを運営している。",
"同社の画像認識AIは衛星画像を解析し、農作物の病害を早期に検出するサービスを提供している。"
"高い検出精度が評価され九州や北海道を中心に契約面積が10万ヘクタールを超え、被害額を年間20億円削減した。",
"この企業の予測分析プラットフォームは、従来手法より72時間先の降水予測精度を15ポイント向上させた。"
"保険会社や物流企業など、天候に事業が左右される業界で幅広く導入されている。",
"同社は音声AIを応用した防災システムも展開しており、自治体の防災無線を多言語に"
"自動翻訳してリアルタイムの音声配信を実現している。外国人住民の避難率が導入前の2倍に改善した。",
"この福岡の企業は社員の約7割がリモートワークで勤務しており、那覇と仙台に"
"サテライトオフィスを構えている。地方発テック企業の新しい働き方モデルとして注目されている。",
],
},
{
"title": "暁光システムズ",
"chunks": [
"暁光システムズ株式会社は2016年に名古屋で設立された自動車向けAI企業である。"
"自動運転とコネクテッドカー技術を軸に、次世代モビリティ基盤の構築を進めている。"
"近年は、AIロボティクス全般へ事業領域を広げている。",
"同社のAI予測分析プラットフォームは、交通量データとカメラ映像を統合し渋滞を30分前に予測する。"
"名古屋市の実証実験では通勤時間帯の渋滞長が平均22%短縮された。物流の改善による経済効果も期待されている。",
"この企業の画像認識AIは車載カメラの映像から歩行者・自転車・障害物を識別し、"
"悪天候下でも検出精度98.5%を維持する。国内外の自動車メーカー5社に技術供与している。",
"同社は音声AIアシスタントをカーナビに統合し、運転中のハンズフリー操作を可能にした。"
"方言や高齢者の不明瞭な発話にも対応し、音声認識精度は業界最高水準の97%を記録している。",
"この名古屋の企業は累計資金調達額が350億円を超え、ユニコーン企業として評価されている。"
"2025年に東証グロース市場への上場を申請中である。",
],
},
{
"title": "紫雲インテリジェンス",
"chunks": [
"紫雲インテリジェンス株式会社は2017年に京都で創業した文化・観光DXを専門とするAI企業である。"
"寺社仏閣や伝統工芸品のデジタルアーカイブ構築を主力事業としている。",
"同社の音声AIガイドシステムは、観光客の質問に12言語でリアルタイム応答する。"
"京都市内の主要観光地30か所に導入され、外国人観光客の満足度が35%向上した。",
"この企業の予測分析プラットフォームは、観光客の流動データから混雑を予測し最適な周遊ルートを提案する。"
"導入地域では特定スポットへの集中が緩和され、周辺商店街の売上が18%増加した。",
"同社の画像認識AIは文化財の劣化状態を高精細画像から自動評価する。"
"目視点検と比較して微細な亀裂の検出率が3倍に向上し、修復計画の策定期間を半減させた。",
"この京都の企業は文化庁との連携協定を締結しており、国宝・重要文化財のデジタル保存事業で"
"中核的な役割を担っている。保存対象は全国1500件を超える。",
],
},
{
"title": "碧海テックラボ",
"chunks": [
"碧海テックラボ株式会社は2014年に横浜で設立された港湾・物流特化型のAI企業である。"
"コンテナターミナルの自動化と国際物流の効率化をミッションに掲げている。",
"同社の予測分析プラットフォームは、船舶の入港スケジュールと荷役能力を最適化する。"
"横浜港での試験運用ではコンテナ滞留時間が40%短縮され、年間処理能力が12%向上した。",
"この企業の音声AIシステムは、多国籍の港湾作業員がヘッドセットを通じて"
"作業指示を母国語で受けられるリアルタイム翻訳機能を備えている。作業ミスが半減した。",
"同社の画像認識AIはクレーンカメラの映像からコンテナの損傷やシール番号を自動で読み取る。"
"従来の手作業による確認と比べ処理速度が8倍に向上し、人的ミスもほぼゼロになった。",
"この横浜の企業はシンガポール港湾局とも技術提携を結んでおり、"
"アジア太平洋地域5港への展開を2027年までに完了する計画である。",
],
},
{
"title": "銀河アナリティクス",
"chunks": [
"銀河アナリティクス株式会社は2019年に仙台で設立された防災・インフラ分野のAI企業である。"
"東日本大震災の経験を原点に、災害被害を最小化するテクノロジーの開発に取り組んでいる。",
"同社の画像認識AIシステムはドローン空撮画像を解析し、橋梁やトンネルのコンクリート劣化を自動検出する。"
"従来の点検員による目視調査と比較して、検出精度が25%向上しコストは3分の1に削減された。",
"この企業の音声AIは災害時に自治体の緊急放送を自動で文字起こしし、SNSとアプリへ即時配信する。"
"聴覚障害者や外国人住民への情報到達率が従来比で4倍に改善した。",
"同社の予測分析プラットフォームは、河川水位センサーとレーダー雨量計を統合し"
"氾濫リスクをリアルタイムで評価する。警報発令の判断時間を平均45分短縮した。",
"この仙台の企業は国土交通省のインフラDXモデル事業に採択されており、"
"全国8地方整備局への技術展開が進行中である。",
],
},
{
"title": "朱鷺AIソリューションズ",
"chunks": [
"朱鷺AIソリューションズ株式会社は2020年に新潟で設立された農業・食品産業向けAI企業である。"
"米どころ新潟の農業課題をテクノロジーで解決することを創業理念としている。",
"同社の音声AIシステムは、農業機械のオペレーターが走行中に音声で作業記録を入力できる。"
"手書き日誌からの移行により記録精度が向上し、1日あたりの事務作業時間が平均45分短縮された。",
"この企業の予測分析プラットフォームは、土壌センサーと気象データを組み合わせて"
"最適な施肥タイミングを予測する。新潟県農業試験センターの推計では、収量が平均15%向上し、肥料コストが20%削減された。",
"同社の画像認識AIは食品加工ラインに導入され、米粒の等級判定や異物混入検査を自動化している。"
"高い検出精度を維持しながら毎秒3000粒の検査速度を実現し、大手米卸3社の精米工場で稼働中である。",
"この新潟のAI企業は地元の農業協同組合と包括連携協定を結んでおり、"
"スマート農業の普及拠点として県内50か所の実証農園を運営している。",
],
},
{
"title": "風雅コンピューティング",
"chunks": [
"風雅コンピューティング株式会社は2013年に広島で設立された教育・人材開発分野のAI企業である。"
"個別最適化学習と企業研修DXを二本柱に事業を展開している。",
"同社の予測分析プラットフォームは、学習者の回答パターンと所要時間から理解度を推定し、"
"最適な出題順序を生成する。導入校では全国模試の平均偏差値が3.2ポイント向上した。",
"この企業の画像認識AIは、手書きの数式や図形をリアルタイムで認識しデジタル変換する。"
"タブレット学習教材に組み込まれ、全国800校で約25万人の生徒が利用している。",
"同社の音声AIチューターは、英語スピーキング練習で発音・イントネーションを即座に評価する。"
"ネイティブ講師によるマンツーマン指導と同等の学習効果が臨床研究で確認された。",
"この広島の企業は全国の教育委員会120か所と契約しており、"
"公教育におけるAI導入実績で国内最多を誇る。文部科学省の教育DX推進委員も務めている。",
],
},
{
"title": "黄金データワークス",
"chunks": [
"黄金データワークス株式会社は2011年に金沢で創業した金融・保険業界向けAI企業である。"
"リスク評価と不正検知を専門とし、地方銀行から大手保険会社まで幅広い顧客基盤を持つ。",
"同社の音声AIは、コールセンターの通話をリアルタイム解析し顧客の不満や解約兆候を検出する。"
"導入企業では顧客離反率が18%低下し、アップセル成功率が25%向上した。",
"この企業の画像認識AIは、保険金請求時に提出される事故写真から損傷の程度を自動査定する。"
"査定処理時間が従来の5日間から平均4時間に短縮され、検出精度の高さと相まって顧客満足度が大幅に改善した。",
"同社の予測分析プラットフォームは、取引データのパターンから不正送金をリアルタイム検知する。"
"導入金融機関では不正取引の検出率が従来システム比で40%向上し、誤検知率は半減した。",
"この金沢の企業は金融庁のフィンテック実証実験に3年連続で採択されており、"
"規制対応AIの分野で国内随一の知見を蓄積している。",
],
},
]
QUERIES = [
{
"query": "星風テクノロジーズの画像認識AI技術はどこで使われている?",
"expected_doc": "星風テクノロジーズ",
"expected_chunk_idx": 3,
"note": "10社すべてが画像認識AIを持つ。社名コンテキストなしでは10件の画像認識AIチャンクが競合(ノイズ)",
},
{
"query": "蒼月ロボティクスの予測分析サービスは何を予測していますか?",
"expected_doc": "蒼月ロボティクス",
"expected_chunk_idx": 3,
"note": "10社すべてが予測分析を持つ。社名コンテキストなしでは10件の予測分析チャンクが競合(ノイズ)",
},
{
"query": "翠嶺データサイエンスの音声AI技術はどのような成果を上げていますか?",
"expected_doc": "翠嶺データサイエンス",
"expected_chunk_idx": 3,
"note": "10社すべてが音声AIを持つ。社名コンテキストなしでは10件の音声AIチャンクが競合(ノイズ)",
},
{
"query": "暁光システムズの画像認識AIの検出精度",
"expected_doc": "暁光システムズ",
"expected_chunk_idx": 2,
"note": "10社すべてが画像認識AIを持つ。社名コンテキストなしでは10件の画像認識AIチャンクが競合(ノイズ)",
},
{
"query": "碧海テックラボの音声AIシステムの特徴",
"expected_doc": "碧海テックラボ",
"expected_chunk_idx": 2,
"note": "10社すべてが音声AIを持つ。社名コンテキストなしでは10件の音声AIチャンクが競合(ノイズ)",
},
{
"query": "京都のAI企業のAI予測分析の経済効果",
"expected_doc": "紫雲インテリジェンス",
"expected_chunk_idx": 2,
"note": "地理的手がかり+予測分析。10社すべてが予測分析AIを持つ。地理コンテキストなしでは10件の予測分析AIチャンクが競合(ノイズ)",
},
{
"query": "新潟で設立されたAI企業である朱鷺AIソリューションズの画像認識AIは何の自動化に使われていますか?",
"expected_doc": "朱鷺AIソリューションズ",
"expected_chunk_idx": 3,
"note": "地理的手がかり+画像認識AI。10社すべてが画像認識AIを持つ。地理コンテキストなしでは10件の画像認識AIチャンクが競合(ノイズ)",
},
{
"query": "広島のAI企業の音声AIの学習効果",
"expected_doc": "風雅コンピューティング",
"expected_chunk_idx": 3,
"note": "音声AI×教育は風雅のみだが、地理コンテキストなしでは10件の音声AIチャンクが全て候補になる",
},
{
"query": "金沢のAI企業の予測分析プラットフォームの不正検知性能",
"expected_doc": "黄金データワークス",
"expected_chunk_idx": 3,
"note": "10社すべてが予測分析AIを持つ。地理コンテキストなしでは10件の予測分析AIチャンクが競合(ノイズ)。ただし、不正検知は、黄金データワークスのチャンク3に固有(従来手法でも特定しやすい)",
},
{
"query": "蒼月ロボティクスの画像認識AIの不良品検出率",
"expected_doc": "蒼月ロボティクス",
"expected_chunk_idx": 1,
"note": "10社すべてが画像認識AIを持つが、不良品検出率は、蒼月ロボティクスのチャンク1に固有(従来手法でも特定しやすい)",
},
]
# ============================================================================
# 2. モデル読み込み
# ============================================================================
def load_models():
"""通常版と文脈対応版の両モデルを読み込む"""
from sentence_transformers import SentenceTransformer
from transformers import AutoModel
from transformers.utils import logging as hf_logging
print("=" * 60)
print("モデルを読み込み中...")
print("=" * 60)
prev_verbosity = hf_logging.get_verbosity()
hf_logging.set_verbosity_error()
try:
print("\n[1/2] pplx-embed-v1-0.6B (通常版: クエリ用 & 従来手法比較用)...")
# 通常版は SentenceTransformer 経由で encode() を提供する
model_std = SentenceTransformer(
"perplexity-ai/pplx-embed-v1-0.6B",
trust_remote_code=True,
)
print(" → 完了")
print("[2/2] pplx-embed-context-v1-0.6B (文脈対応版: 遅延チャンキング用)...")
model_ctx = AutoModel.from_pretrained(
"perplexity-ai/pplx-embed-context-v1-0.6B",
trust_remote_code=True,
)
print(" → 完了\n")
finally:
hf_logging.set_verbosity(prev_verbosity)
return model_std, model_ctx
# ============================================================================
# 3. エンベディング生成
# ============================================================================
def build_chunk_index(documents):
"""チャンクの一覧とメタデータを構築"""
chunk_texts = []
chunk_meta = []
for doc in documents:
for i, chunk in enumerate(doc["chunks"]):
chunk_texts.append(chunk)
chunk_meta.append({
"doc_title": doc["title"],
"chunk_idx": i,
"text_preview": chunk[:50] + "...",
})
return chunk_texts, chunk_meta
def embed_naive(model_std, chunk_texts):
"""従来手法方式: 各チャンクを個別にエンコード"""
print(" 従来手法方式でエンベディング生成中...")
embeddings = model_std.encode(chunk_texts)
print(f" → shape: ({len(embeddings)}, {embeddings.shape[1]})")
return embeddings
def embed_late_chunking(model_ctx, documents):
"""遅延チャンキング方式: 文書単位でチャンクをグループ化してエンコード"""
print(" 遅延チャンキング方式でエンベディング生成中...")
doc_chunks = [doc["chunks"] for doc in documents]
# model_ctx.encode() は文書ごとの numpy 配列のリストを返す
# embeddings[i].shape = (num_chunks_in_doc_i, 1024)
doc_embeddings = model_ctx.encode(doc_chunks)
# 全チャンクを1つの配列に結合
all_embeddings = np.concatenate(doc_embeddings, axis=0)
print(f" → shape: {all_embeddings.shape}")
return all_embeddings
def embed_queries(model_std, queries):
"""クエリを通常版モデルでエンコード(両方式共通)"""
print(" クエリをエンコード中...")
query_texts = [q["query"] for q in queries]
embeddings = model_std.encode(query_texts)
print(f" → shape: ({len(embeddings)}, {embeddings.shape[1]})")
return embeddings
# ============================================================================
# 4. 検索と比較
# ============================================================================
def search(query_emb, chunk_embs, chunk_meta, top_k=5):
"""コサイン類似度で上位K件を返す"""
# query_emb: (1, dim), chunk_embs: (N, dim)
sims = cosine_similarity(query_emb.reshape(1, -1), chunk_embs)[0]
top_indices = np.argsort(sims)[::-1][:top_k]
results = []
for idx in top_indices:
results.append({
"rank": len(results) + 1,
"score": float(sims[idx]),
"doc_title": chunk_meta[idx]["doc_title"],
"chunk_idx": chunk_meta[idx]["chunk_idx"],
"text_preview": chunk_meta[idx]["text_preview"],
})
return results
def run_comparison(query_embs, naive_embs, late_embs, chunk_meta, queries):
"""全クエリについて両方式の検索結果を比較"""
print("\n" + "=" * 80)
print("検索結果の比較")
print("=" * 80)
comparison_data = []
for i, q in enumerate(queries):
print(f"\n{'─' * 80}")
print(f"Q{i+1}: {q['query']}")
print(f" 期待チャンク: {q['expected_doc']} チャンク{q['expected_chunk_idx']}")
print(f" ポイント: {q.get('note', '(なし)')}")
print(f"{'─' * 80}")
naive_results = search(query_embs[i], naive_embs, chunk_meta, top_k=3)
late_results = search(query_embs[i], late_embs, chunk_meta, top_k=3)
print(" 従来手法 Top3:")
for r in naive_results:
line = f"#{r['rank']} {r['doc_title']}[{r['chunk_idx']}] (score: {r['score']:.4f})"
if r["doc_title"] == q["expected_doc"] and r["chunk_idx"] == q["expected_chunk_idx"]:
line = f"**{line}**"
print(f" - {line}")
print(" 遅延チャンキング Top3:")
for r in late_results:
line = f"#{r['rank']} {r['doc_title']}[{r['chunk_idx']}] (score: {r['score']:.4f})"
if r["doc_title"] == q["expected_doc"] and r["chunk_idx"] == q["expected_chunk_idx"]:
line = f"**{line}**"
print(f" - {line}")
# 正解チャンクの順位とスコアを記録
def find_expected(results, q):
for r in results:
if r["doc_title"] == q["expected_doc"] and r["chunk_idx"] == q["expected_chunk_idx"]:
return r["rank"], r["score"]
return None, None
n_rank, n_score = find_expected(naive_results, q)
l_rank, l_score = find_expected(late_results, q)
comparison_data.append({
"query": q["query"],
"expected_doc": q["expected_doc"],
"expected_chunk_idx": q["expected_chunk_idx"],
"note": q.get("note", ""),
"naive_rank": n_rank,
"naive_score": n_score,
"late_rank": l_rank,
"late_score": l_score,
"naive_top3": naive_results,
"late_top3": late_results,
})
status_n = f"#{n_rank} (スコア: {n_score:.4f})" if n_rank else "上位3件に入らず"
status_l = f"#{l_rank} (スコア: {l_score:.4f})" if l_rank else "上位3件に入らず"
print(f"\n → 正解チャンクの順位: 従来手法={status_n} / 遅延CK={status_l}")
return comparison_data
# ============================================================================
# 5. 可視化
# ============================================================================
def plot_comparison(comparison_data, save_path="comparison_chart.png"):
"""比較結果を棒グラフで可視化"""
try:
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
try:
import japanize_matplotlib # noqa: F401
except ImportError:
plt.rcParams["font.family"] = ["Noto Sans CJK JP", "IPAGothic", "sans-serif"]
except ImportError:
print("\n[INFO] matplotlib がインストールされていないため、グラフ出力をスキップします。")
return
labels = [f"Q{i+1}" for i in range(len(comparison_data))]
naive_scores = [d["naive_score"] or 0 for d in comparison_data]
late_scores = [d["late_score"] or 0 for d in comparison_data]
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
bars1 = ax.bar(x - width / 2, naive_scores, width, label="従来手法", color="#FF6B6B", alpha=0.8)
bars2 = ax.bar(x + width / 2, late_scores, width, label="遅延チャンキング", color="#4ECDC4", alpha=0.8)
ax.set_xlabel("クエリ")
ax.set_ylabel("コサイン類似度(正解チャンクのスコア)")
ax.set_title("従来手法 vs 遅延チャンキング: 正解チャンクの類似度スコア比較")
ax.set_xticks(x)
ax.set_xticklabels(labels)
ax.legend()
ax.set_ylim(0, 1.0)
# スコアラベル
for bar in bars1:
h = bar.get_height()
if h > 0:
ax.annotate(f"{h:.3f}", xy=(bar.get_x() + bar.get_width() / 2, h),
xytext=(0, 3), textcoords="offset points", ha="center", fontsize=9)
for bar in bars2:
h = bar.get_height()
if h > 0:
ax.annotate(f"{h:.3f}", xy=(bar.get_x() + bar.get_width() / 2, h),
xytext=(0, 3), textcoords="offset points", ha="center", fontsize=9)
plt.tight_layout()
plt.savefig(save_path, dpi=150)
print(f"\n[INFO] グラフを保存しました: {save_path}")
# ============================================================================
# 6. サマリー出力
# ============================================================================
def print_summary(comparison_data):
"""結果のサマリーを出力"""
print("\n" + "=" * 80)
print("サマリー")
print("=" * 80)
for i, d in enumerate(comparison_data, start=1):
n_str = f"{d['naive_score']:.4f}" if d["naive_score"] is not None else "圏外"
l_str = f"{d['late_score']:.4f}" if d["late_score"] is not None else "圏外"
if d["naive_score"] and d["late_score"]:
diff = d["late_score"] - d["naive_score"]
diff_str = f"{'+' if diff >= 0 else ''}{diff:.4f}"
else:
diff_str = "—"
print(f"- Q{i}: {d['query']}")
print(f" - 従来手法: {n_str}")
print(f" - 遅延CK: {l_str}")
print(f" - 改善: {diff_str}")
print("=" * 80)
# ============================================================================
# 7. Markdown レポート出力
# ============================================================================
def write_markdown_report(comparison_data, save_path="comparison_report.md"):
"""比較結果を読みやすい Markdown で保存"""
def md_escape(text):
"""Markdown テーブル内で崩れやすい文字を最小限エスケープ"""
return str(text).replace("|", "\\|").replace("\n", " ")
def fmt_rank_score(rank, score):
if rank is not None and score is not None:
return f"#{rank} ({score:.4f})"
return "上位3件外"
def fmt_diff(naive_score, late_score):
if naive_score is not None and late_score is not None:
diff = late_score - naive_score
return f"{'+' if diff >= 0 else ''}{diff:.4f}"
return "—"
lines = []
lines.append("# 遅延チャンキング比較レポート")
lines.append("")
lines.append(f"- 生成日時: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
lines.append(f"- クエリ数: {len(comparison_data)}")
lines.append("")
lines.append("## サマリー")
lines.append("")
lines.append("| Q | クエリ | 正解チャンク | 従来手法(正解) | 遅延チャンキング(正解) | 改善量 |")
lines.append("| --- | --- | --- | --- | --- | --- |")
for i, d in enumerate(comparison_data, start=1):
naive_str = fmt_rank_score(d["naive_rank"], d["naive_score"])
late_str = fmt_rank_score(d["late_rank"], d["late_score"])
diff_str = fmt_diff(d["naive_score"], d["late_score"])
expected_str = f"{d['expected_doc']}[{d['expected_chunk_idx']}]"
lines.append(
f"| Q{i} | {md_escape(d['query'])} | {md_escape(expected_str)} | "
f"{md_escape(naive_str)} | {md_escape(late_str)} | {diff_str} |"
)
lines.append("")
for i, d in enumerate(comparison_data, start=1):
diff_str = fmt_diff(d["naive_score"], d["late_score"])
lines.append(f"### Q{i}")
lines.append("")
lines.append(f"- クエリ: {md_escape(d['query'])}")
lines.append(f"- 正解チャンク: `{d['expected_doc']}[{d['expected_chunk_idx']}]`")
if d["note"]:
lines.append(f"- ポイント: {md_escape(d['note'])}")
lines.append(f"- 従来手法(正解チャンク): {fmt_rank_score(d['naive_rank'], d['naive_score'])}")
lines.append(f"- 遅延チャンキング(正解チャンク): {fmt_rank_score(d['late_rank'], d['late_score'])}")
lines.append(f"- 改善量: {diff_str}")
lines.append("")
lines.append("#### 従来手法 Top3")
lines.append("")
lines.append("| Rank | ドキュメント[chunk] | Score | 正解 |")
lines.append("| --- | --- | --- | --- |")
for r in d["naive_top3"]:
is_expected = r["doc_title"] == d["expected_doc"] and r["chunk_idx"] == d["expected_chunk_idx"]
expected_mark = "✓" if is_expected else ""
lines.append(
f"| #{r['rank']} | {md_escape(r['doc_title'])}[{r['chunk_idx']}] | {r['score']:.4f} | {expected_mark} |"
)
lines.append("")
lines.append("#### 遅延チャンキング Top3")
lines.append("")
lines.append("| Rank | ドキュメント[chunk] | Score | 正解 |")
lines.append("| --- | --- | --- | --- |")
for r in d["late_top3"]:
is_expected = r["doc_title"] == d["expected_doc"] and r["chunk_idx"] == d["expected_chunk_idx"]
expected_mark = "✓" if is_expected else ""
lines.append(
f"| #{r['rank']} | {md_escape(r['doc_title'])}[{r['chunk_idx']}] | {r['score']:.4f} | {expected_mark} |"
)
lines.append("")
with open(save_path, "w", encoding="utf-8") as f:
f.write("\n".join(lines))
print(f"[INFO] Markdown レポートを保存しました: {save_path}")
# ============================================================================
# 8. メイン
# ============================================================================
def main():
print("""
╔══════════════════════════════════════════════════════════════╗
║ pplx-embed-context-v1-0.6B 遅延チャンキング デモ ║
║ 従来手法 vs Late Chunking ベクトル検索精度比較 ║
╚══════════════════════════════════════════════════════════════╝
""")
# --- モデル読み込み ---
model_std, model_ctx = load_models()
# --- チャンクインデックス構築 ---
chunk_texts, chunk_meta = build_chunk_index(DOCUMENTS)
print(f"チャンク総数: {len(chunk_texts)}")
for i, m in enumerate(chunk_meta):
print(f" [{i:2d}] {m['doc_title']:10} チャンク{m['chunk_idx']}: {m['text_preview']}")
# --- エンベディング生成 ---
print("\n" + "=" * 60)
print("エンベディング生成")
print("=" * 60)
naive_embs = embed_naive(model_std, chunk_texts)
late_embs = embed_late_chunking(model_ctx, DOCUMENTS)
query_embs = embed_queries(model_std, QUERIES)
# --- 検索比較 ---
comparison_data = run_comparison(query_embs, naive_embs, late_embs, chunk_meta, QUERIES)
# --- 可視化 ---
plot_comparison(comparison_data)
# --- サマリー ---
print_summary(comparison_data)
write_markdown_report(comparison_data)
if __name__ == "__main__":
main()
API版 pplx-embed-context-v1-0.6B/4B 遅延チャンキングテストコード
"""
=============================================================================
pplx-embed-context-v1-0.6B/4B 遅延チャンキング デモ(API版)
=============================================================================
Perplexity API を使用する軽量版。ローカルにモデルをダウンロードする必要がない。
■ 必要パッケージ:
uv pip install requests numpy scikit-learn python-dotenv
■ 実行前に:
.env に以下を設定:
PERPLEXITY_API_KEY="your-api-key-here"
(または環境変数 PERPLEXITY_API_KEY でも可)
■ 実行:
python demo_late_chunking_api.py
"""
import os
import base64
from datetime import datetime
import requests
import numpy as np
from dotenv import load_dotenv
from sklearn.metrics.pairwise import cosine_similarity
load_dotenv()
API_KEY = os.environ.get("PERPLEXITY_API_KEY", "")
BASE_URL = "https://api.perplexity.ai/v1"
ENCODING_FORMAT = "base64_int8"
if not API_KEY:
print("⚠️ PERPLEXITY_API_KEY が見つかりません。")
print(" .env に PERPLEXITY_API_KEY='pplx-...' を設定するか、")
print(" 環境変数 PERPLEXITY_API_KEY を設定してください。")
exit(1)
HEADERS = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
# ============================================================================
# サンプルデータ(ローカル版と同一)
# ============================================================================
DOCUMENTS = [
{
"title": "星風テクノロジーズ",
"chunks": [
"星風テクノロジーズ株式会社は2015年に札幌で設立されたスタートアップである。研究開発費は売上高の45%に達しており、業界平均の約3倍である。"
"研究員の約6割が博士号を保有し、論文発表数は国内スタートアップでトップクラスである。",
"この札幌の企業は、音声認識AIと自然言語処理AIを中核技術とし、医療・介護分野向けのソリューションを提供している。",
"同社の音声AIシステムは、高齢者の発話パターンから健康状態の変化を検知する。"
"全国200以上の介護施設に導入され、緊急搬送件数が平均30%減少した。",
"この企業は画像認識AI分野にも進出しており、内視鏡画像からポリープを自動検出する"
"診断支援システムを開発した。国内21の大学病院に導入されている。",
"同社の予測分析サービスは、電子カルテデータをもとに患者の再入院リスクを推定する。"
"予測精度は92%に達し、医療費削減への貢献が評価されている。",
],
},
{
"title": "蒼月ロボティクス",
"chunks": [
"蒼月ロボティクス株式会社は2012年に大阪で創業した先端企業である。"
"独自の触覚センサー技術を強みに、製造業・物流向けの協働ロボットを開発している。",
"同社の画像認識AIは製造ラインに組み込まれ、微細な傷や変形をリアルタイムで検出する。"
"不良品検出率は99.7%を達成し、自動車部品工場を中心に累計800ライン以上で稼働している。",
"AIロボティクスを得意とするこの企業は音声AIインターフェースも開発しており、工場の騒音環境下でもロボットに"
"音声指示を出せるシステムを実用化した。従来のタッチパネル操作比で作業効率が40%向上した。",
"同社の予測分析プラットフォームは、製造設備のセンサーデータから72時間以内に故障が起きる確率を推測する。"
"導入工場では計画外停止が85%減少し、設備稼働率が15ポイント向上した。",
"この大阪のメーカーは欧州市場への本格進出を計画しており、ミュンヘンに研究開発拠点を設立した。"
"現地の自動車メーカー3社との共同開発契約を締結し、2026年からの量産供給を目指している。",
],
},
{
"title": "翠嶺データサイエンス",
"chunks": [
"翠嶺データサイエンス株式会社は2018年に福岡で設立された先端データ分析企業である。"
"気象データと衛星画像を組み合わせた独自の予測プラットフォームを運営している。",
"同社の画像認識AIは衛星画像を解析し、農作物の病害を早期に検出するサービスを提供している。"
"高い検出精度が評価され九州や北海道を中心に契約面積が10万ヘクタールを超え、被害額を年間20億円削減した。",
"この企業の予測分析プラットフォームは、従来手法より72時間先の降水予測精度を15ポイント向上させた。"
"保険会社や物流企業など、天候に事業が左右される業界で幅広く導入されている。",
"同社は音声AIを応用した防災システムも展開しており、自治体の防災無線を多言語に"
"自動翻訳してリアルタイムの音声配信を実現している。外国人住民の避難率が導入前の2倍に改善した。",
"この福岡の企業は社員の約7割がリモートワークで勤務しており、那覇と仙台に"
"サテライトオフィスを構えている。地方発テック企業の新しい働き方モデルとして注目されている。",
],
},
{
"title": "暁光システムズ",
"chunks": [
"暁光システムズ株式会社は2016年に名古屋で設立された自動車向けAI企業である。"
"自動運転とコネクテッドカー技術を軸に、次世代モビリティ基盤の構築を進めている。"
"近年は、AIロボティクス全般へ事業領域を広げている。",
"同社のAI予測分析プラットフォームは、交通量データとカメラ映像を統合し渋滞を30分前に予測する。"
"名古屋市の実証実験では通勤時間帯の渋滞長が平均22%短縮された。物流の改善による経済効果も期待されている。",
"この企業の画像認識AIは車載カメラの映像から歩行者・自転車・障害物を識別し、"
"悪天候下でも検出精度98.5%を維持する。国内外の自動車メーカー5社に技術供与している。",
"同社は音声AIアシスタントをカーナビに統合し、運転中のハンズフリー操作を可能にした。"
"方言や高齢者の不明瞭な発話にも対応し、音声認識精度は業界最高水準の97%を記録している。",
"この名古屋の企業は累計資金調達額が350億円を超え、ユニコーン企業として評価されている。"
"2025年に東証グロース市場への上場を申請中である。",
],
},
{
"title": "紫雲インテリジェンス",
"chunks": [
"紫雲インテリジェンス株式会社は2017年に京都で創業した文化・観光DXを専門とするAI企業である。"
"寺社仏閣や伝統工芸品のデジタルアーカイブ構築を主力事業としている。",
"同社の音声AIガイドシステムは、観光客の質問に12言語でリアルタイム応答する。"
"京都市内の主要観光地30か所に導入され、外国人観光客の満足度が35%向上した。",
"この企業の予測分析プラットフォームは、観光客の流動データから混雑を予測し最適な周遊ルートを提案する。"
"導入地域では特定スポットへの集中が緩和され、周辺商店街の売上が18%増加した。",
"同社の画像認識AIは文化財の劣化状態を高精細画像から自動評価する。"
"目視点検と比較して微細な亀裂の検出率が3倍に向上し、修復計画の策定期間を半減させた。",
"この京都の企業は文化庁との連携協定を締結しており、国宝・重要文化財のデジタル保存事業で"
"中核的な役割を担っている。保存対象は全国1500件を超える。",
],
},
{
"title": "碧海テックラボ",
"chunks": [
"碧海テックラボ株式会社は2014年に横浜で設立された港湾・物流特化型のAI企業である。"
"コンテナターミナルの自動化と国際物流の効率化をミッションに掲げている。",
"同社の予測分析プラットフォームは、船舶の入港スケジュールと荷役能力を最適化する。"
"横浜港での試験運用ではコンテナ滞留時間が40%短縮され、年間処理能力が12%向上した。",
"この企業の音声AIシステムは、多国籍の港湾作業員がヘッドセットを通じて"
"作業指示を母国語で受けられるリアルタイム翻訳機能を備えている。作業ミスが半減した。",
"同社の画像認識AIはクレーンカメラの映像からコンテナの損傷やシール番号を自動で読み取る。"
"従来の手作業による確認と比べ処理速度が8倍に向上し、人的ミスもほぼゼロになった。",
"この横浜の企業はシンガポール港湾局とも技術提携を結んでおり、"
"アジア太平洋地域5港への展開を2027年までに完了する計画である。",
],
},
{
"title": "銀河アナリティクス",
"chunks": [
"銀河アナリティクス株式会社は2019年に仙台で設立された防災・インフラ分野のAI企業である。"
"東日本大震災の経験を原点に、災害被害を最小化するテクノロジーの開発に取り組んでいる。",
"同社の画像認識AIシステムはドローン空撮画像を解析し、橋梁やトンネルのコンクリート劣化を自動検出する。"
"従来の点検員による目視調査と比較して、検出精度が25%向上しコストは3分の1に削減された。",
"この企業の音声AIは災害時に自治体の緊急放送を自動で文字起こしし、SNSとアプリへ即時配信する。"
"聴覚障害者や外国人住民への情報到達率が従来比で4倍に改善した。",
"同社の予測分析プラットフォームは、河川水位センサーとレーダー雨量計を統合し"
"氾濫リスクをリアルタイムで評価する。警報発令の判断時間を平均45分短縮した。",
"この仙台の企業は国土交通省のインフラDXモデル事業に採択されており、"
"全国8地方整備局への技術展開が進行中である。",
],
},
{
"title": "朱鷺AIソリューションズ",
"chunks": [
"朱鷺AIソリューションズ株式会社は2020年に新潟で設立された農業・食品産業向けAI企業である。"
"米どころ新潟の農業課題をテクノロジーで解決することを創業理念としている。",
"同社の音声AIシステムは、農業機械のオペレーターが走行中に音声で作業記録を入力できる。"
"手書き日誌からの移行により記録精度が向上し、1日あたりの事務作業時間が平均45分短縮された。",
"この企業の予測分析プラットフォームは、土壌センサーと気象データを組み合わせて"
"最適な施肥タイミングを予測する。新潟県農業試験センターの推計では、収量が平均15%向上し、肥料コストが20%削減された。",
"同社の画像認識AIは食品加工ラインに導入され、米粒の等級判定や異物混入検査を自動化している。"
"高い検出精度を維持しながら毎秒3000粒の検査速度を実現し、大手米卸3社の精米工場で稼働中である。",
"この新潟のAI企業は地元の農業協同組合と包括連携協定を結んでおり、"
"スマート農業の普及拠点として県内50か所の実証農園を運営している。",
],
},
{
"title": "風雅コンピューティング",
"chunks": [
"風雅コンピューティング株式会社は2013年に広島で設立された教育・人材開発分野のAI企業である。"
"個別最適化学習と企業研修DXを二本柱に事業を展開している。",
"同社の予測分析プラットフォームは、学習者の回答パターンと所要時間から理解度を推定し、"
"最適な出題順序を生成する。導入校では全国模試の平均偏差値が3.2ポイント向上した。",
"この企業の画像認識AIは、手書きの数式や図形をリアルタイムで認識しデジタル変換する。"
"タブレット学習教材に組み込まれ、全国800校で約25万人の生徒が利用している。",
"同社の音声AIチューターは、英語スピーキング練習で発音・イントネーションを即座に評価する。"
"ネイティブ講師によるマンツーマン指導と同等の学習効果が臨床研究で確認された。",
"この広島の企業は全国の教育委員会120か所と契約しており、"
"公教育におけるAI導入実績で国内最多を誇る。文部科学省の教育DX推進委員も務めている。",
],
},
{
"title": "黄金データワークス",
"chunks": [
"黄金データワークス株式会社は2011年に金沢で創業した金融・保険業界向けAI企業である。"
"リスク評価と不正検知を専門とし、地方銀行から大手保険会社まで幅広い顧客基盤を持つ。",
"同社の音声AIは、コールセンターの通話をリアルタイム解析し顧客の不満や解約兆候を検出する。"
"導入企業では顧客離反率が18%低下し、アップセル成功率が25%向上した。",
"この企業の画像認識AIは、保険金請求時に提出される事故写真から損傷の程度を自動査定する。"
"査定処理時間が従来の5日間から平均4時間に短縮され、検出精度の高さと相まって顧客満足度が大幅に改善した。",
"同社の予測分析プラットフォームは、取引データのパターンから不正送金をリアルタイム検知する。"
"導入金融機関では不正取引の検出率が従来システム比で40%向上し、誤検知率は半減した。",
"この金沢の企業は金融庁のフィンテック実証実験に3年連続で採択されており、"
"規制対応AIの分野で国内随一の知見を蓄積している。",
],
},
]
QUERIES = [
{
"query": "星風テクノロジーズの画像認識AI技術はどこで使われている?",
"expected_doc": "星風テクノロジーズ",
"expected_chunk_idx": 3,
"note": "10社すべてが画像認識AIを持つ。社名コンテキストなしでは10件の画像認識AIチャンクが競合(ノイズ)",
},
{
"query": "蒼月ロボティクスの予測分析サービスは何を予測していますか?",
"expected_doc": "蒼月ロボティクス",
"expected_chunk_idx": 3,
"note": "10社すべてが予測分析を持つ。社名コンテキストなしでは10件の予測分析チャンクが競合(ノイズ)",
},
{
"query": "翠嶺データサイエンスの音声AI技術はどのような成果を上げていますか?",
"expected_doc": "翠嶺データサイエンス",
"expected_chunk_idx": 3,
"note": "10社すべてが音声AIを持つ。社名コンテキストなしでは10件の音声AIチャンクが競合(ノイズ)",
},
{
"query": "暁光システムズの画像認識AIの検出精度",
"expected_doc": "暁光システムズ",
"expected_chunk_idx": 2,
"note": "10社すべてが画像認識AIを持つ。社名コンテキストなしでは10件の画像認識AIチャンクが競合(ノイズ)",
},
{
"query": "碧海テックラボの音声AIシステムの特徴",
"expected_doc": "碧海テックラボ",
"expected_chunk_idx": 2,
"note": "10社すべてが音声AIを持つ。社名コンテキストなしでは10件の音声AIチャンクが競合(ノイズ)",
},
{
"query": "京都のAI企業のAI予測分析の経済効果",
"expected_doc": "紫雲インテリジェンス",
"expected_chunk_idx": 2,
"note": "地理的手がかり+予測分析。10社すべてが予測分析AIを持つ。地理コンテキストなしでは10件の予測分析AIチャンクが競合(ノイズ)",
},
{
"query": "新潟で設立されたAI企業である朱鷺AIソリューションズの画像認識AIは何の自動化に使われていますか?",
"expected_doc": "朱鷺AIソリューションズ",
"expected_chunk_idx": 3,
"note": "地理的手がかり+画像認識AI。10社すべてが画像認識AIを持つ。地理コンテキストなしでは10件の画像認識AIチャンクが競合(ノイズ)",
},
{
"query": "広島のAI企業の音声AIの学習効果",
"expected_doc": "風雅コンピューティング",
"expected_chunk_idx": 3,
"note": "音声AI×教育は風雅のみだが、地理コンテキストなしでは10件の音声AIチャンクが全て候補になる",
},
{
"query": "金沢のAI企業の予測分析プラットフォームの不正検知性能",
"expected_doc": "黄金データワークス",
"expected_chunk_idx": 3,
"note": "10社すべてが予測分析AIを持つ。地理コンテキストなしでは10件の予測分析AIチャンクが競合(ノイズ)。ただし、不正検知は、黄金データワークスのチャンク3に固有(従来手法でも特定しやすい)",
},
{
"query": "蒼月ロボティクスの画像認識AIの不良品検出率",
"expected_doc": "蒼月ロボティクス",
"expected_chunk_idx": 1,
"note": "10社すべてが画像認識AIを持つが、不良品検出率は、蒼月ロボティクスのチャンク1に固有(従来手法でも特定しやすい)",
},
]
# ============================================================================
# API 呼び出し
# ============================================================================
def _to_float_vector(embedding) -> np.ndarray:
"""API の embedding を float32 ベクトルに正規化する。"""
if isinstance(embedding, list):
return np.asarray(embedding, dtype=np.float32)
if isinstance(embedding, str):
decoded = base64.b64decode(embedding)
if ENCODING_FORMAT == "base64_int8":
return np.frombuffer(decoded, dtype=np.int8).astype(np.float32)
if ENCODING_FORMAT == "base64_binary":
return np.frombuffer(decoded, dtype=np.float32)
raise ValueError(f"Unsupported encoding format: {ENCODING_FORMAT}")
raise TypeError(f"Unsupported embedding type: {type(embedding)}")
def embed_standard(texts: list[str]) -> np.ndarray:
"""通常版エンベディング API(クエリ & ナイーブ用)"""
resp = requests.post(
f"{BASE_URL}/embeddings",
headers=HEADERS,
json={
"input": texts,
"model": "pplx-embed-v1-4b", # pplx-embed-v1-0.6b, pplx-embed-v1-4b
"encoding_format": ENCODING_FORMAT,
},
)
resp.raise_for_status()
data = resp.json()["data"]
# API はオブジェクトのリストを返す。index でソートして embedding を取り出す
data.sort(key=lambda x: x["index"])
return np.vstack([_to_float_vector(d["embedding"]) for d in data]).astype(np.float32)
def embed_contextualized(doc_chunks: list[list[str]]) -> np.ndarray:
"""文脈対応版エンベディング API(遅延チャンキング用)"""
resp = requests.post(
f"{BASE_URL}/contextualizedembeddings",
headers=HEADERS,
json={
"input": doc_chunks,
"model": "pplx-embed-context-v1-4b", # pplx-embed-context-v1-0.6b, pplx-embed-context-v1-4b
"encoding_format": ENCODING_FORMAT,
},
)
resp.raise_for_status()
data = resp.json()["data"]
data.sort(key=lambda x: x["index"])
# API 形式は実装差分があり、文書ごとの埋め込みは
# - data[i]["embedding"] (list)
# - data[i]["data"] (各チャンク dict の list)
# のどちらでも処理できるようにする。
all_embs = []
for doc_data in data:
if "embedding" in doc_data:
chunk_payloads = doc_data["embedding"]
for chunk_emb in chunk_payloads:
all_embs.append(_to_float_vector(chunk_emb))
continue
if "data" in doc_data:
chunk_items = doc_data["data"]
chunk_items.sort(key=lambda x: x["index"])
for item in chunk_items:
all_embs.append(_to_float_vector(item["embedding"]))
continue
raise KeyError("Unexpected contextualized embedding payload: missing 'embedding' and 'data'")
return np.vstack(all_embs).astype(np.float32)
# ============================================================================
# 比較・可視化・レポート
# ============================================================================
def build_chunk_index(documents):
"""全ドキュメントをフラットなチャンク配列へ変換"""
chunk_texts = []
chunk_meta = []
for doc in documents:
title = doc["title"]
for i, chunk in enumerate(doc["chunks"]):
chunk_texts.append(chunk)
chunk_meta.append({
"doc_title": title,
"chunk_idx": i,
"text_preview": chunk[:60].replace("\n", " "),
})
return chunk_texts, chunk_meta
def find_rank_and_score(results, expected_doc, expected_chunk_idx):
"""Top3 結果から正解チャンクの順位とスコアを返す"""
for r in results:
if r["doc_title"] == expected_doc and r["chunk_idx"] == expected_chunk_idx:
return r["rank"], r["score"]
return None, None
def format_topk(results):
return [
f"#{r['rank']}: {r['doc_title']}[{r['chunk_idx']}] ({r['score']:.4f})"
for r in results
]
def run_comparison(query_embs, naive_embs, late_embs, chunk_meta, queries):
"""従来手法と遅延チャンキングの検索結果を比較"""
comparison_data = []
print("\n" + "=" * 80)
print("検索結果の比較")
print("=" * 80)
for i, q in enumerate(queries):
print(f"\n{'─' * 80}")
print(f"Q{i+1}: {q['query']}")
print(f" 期待チャンク: {q['expected_doc']} チャンク{q['expected_chunk_idx']}")
print(f" ポイント: {q.get('note', '(なし)')}")
print(f"{'─' * 80}")
naive_sims = cosine_similarity(query_embs[i:i+1], naive_embs)[0]
late_sims = cosine_similarity(query_embs[i:i+1], late_embs)[0]
naive_top_idx = np.argsort(naive_sims)[::-1][:3]
late_top_idx = np.argsort(late_sims)[::-1][:3]
naive_results = [
{
"rank": rank,
"doc_title": chunk_meta[idx]["doc_title"],
"chunk_idx": chunk_meta[idx]["chunk_idx"],
"score": float(naive_sims[idx]),
}
for rank, idx in enumerate(naive_top_idx, start=1)
]
late_results = [
{
"rank": rank,
"doc_title": chunk_meta[idx]["doc_title"],
"chunk_idx": chunk_meta[idx]["chunk_idx"],
"score": float(late_sims[idx]),
}
for rank, idx in enumerate(late_top_idx, start=1)
]
print(" 従来手法 Top3:")
for line in format_topk(naive_results):
print(f" - {line}")
print(" 遅延チャンキング Top3:")
for line in format_topk(late_results):
print(f" - {line}")
n_rank, n_score = find_rank_and_score(
naive_results,
q["expected_doc"],
q["expected_chunk_idx"],
)
l_rank, l_score = find_rank_and_score(
late_results,
q["expected_doc"],
q["expected_chunk_idx"],
)
comparison_data.append({
"query": q["query"],
"expected_doc": q["expected_doc"],
"expected_chunk_idx": q["expected_chunk_idx"],
"note": q.get("note", ""),
"naive_rank": n_rank,
"naive_score": n_score,
"late_rank": l_rank,
"late_score": l_score,
"naive_top3": naive_results,
"late_top3": late_results,
})
status_n = f"#{n_rank} (スコア: {n_score:.4f})" if n_rank else "上位3件に入らず"
status_l = f"#{l_rank} (スコア: {l_score:.4f})" if l_rank else "上位3件に入らず"
print(f"\n → 正解チャンクの順位: 従来手法={status_n} / 遅延CK={status_l}")
return comparison_data
def plot_comparison(comparison_data, save_path="comparison_chart_api.png"):
"""比較結果を棒グラフで可視化"""
try:
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
try:
import japanize_matplotlib # noqa: F401
except ImportError:
plt.rcParams["font.family"] = ["Noto Sans CJK JP", "IPAGothic", "sans-serif"]
except ImportError:
print("\n[INFO] matplotlib がインストールされていないため、グラフ出力をスキップします。")
return
labels = [f"Q{i+1}" for i in range(len(comparison_data))]
naive_scores = [d["naive_score"] or 0 for d in comparison_data]
late_scores = [d["late_score"] or 0 for d in comparison_data]
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
bars1 = ax.bar(x - width / 2, naive_scores, width, label="従来手法", color="#FF6B6B", alpha=0.8)
bars2 = ax.bar(x + width / 2, late_scores, width, label="遅延チャンキング", color="#4ECDC4", alpha=0.8)
ax.set_xlabel("クエリ")
ax.set_ylabel("コサイン類似度(正解チャンクのスコア)")
ax.set_title("従来手法 vs 遅延チャンキング: 正解チャンクの類似度スコア比較")
ax.set_xticks(x)
ax.set_xticklabels(labels)
ax.legend()
ax.set_ylim(0, 1.0)
for bar in bars1:
h = bar.get_height()
if h > 0:
ax.annotate(
f"{h:.3f}",
xy=(bar.get_x() + bar.get_width() / 2, h),
xytext=(0, 3),
textcoords="offset points",
ha="center",
fontsize=9,
)
for bar in bars2:
h = bar.get_height()
if h > 0:
ax.annotate(
f"{h:.3f}",
xy=(bar.get_x() + bar.get_width() / 2, h),
xytext=(0, 3),
textcoords="offset points",
ha="center",
fontsize=9,
)
plt.tight_layout()
plt.savefig(save_path, dpi=150)
print(f"\n[INFO] グラフを保存しました: {save_path}")
def print_summary(comparison_data):
"""結果のサマリーを出力"""
print("\n" + "=" * 80)
print("サマリー")
print("=" * 80)
for i, d in enumerate(comparison_data, start=1):
n_str = f"{d['naive_score']:.4f}" if d["naive_score"] is not None else "圏外"
l_str = f"{d['late_score']:.4f}" if d["late_score"] is not None else "圏外"
if d["naive_score"] is not None and d["late_score"] is not None:
diff = d["late_score"] - d["naive_score"]
diff_str = f"{'+' if diff >= 0 else ''}{diff:.4f}"
else:
diff_str = "—"
print(f"- Q{i}: {d['query']}")
print(f" - 従来手法: {n_str}")
print(f" - 遅延CK: {l_str}")
print(f" - 改善: {diff_str}")
print("=" * 80)
def write_markdown_report(comparison_data, save_path="comparison_report_api.md"):
"""比較結果を読みやすい Markdown で保存"""
def md_escape(text):
return str(text).replace("|", "\\|").replace("\n", " ")
def fmt_rank_score(rank, score):
if rank is not None and score is not None:
return f"#{rank} ({score:.4f})"
return "上位3件外"
def fmt_diff(naive_score, late_score):
if naive_score is not None and late_score is not None:
diff = late_score - naive_score
return f"{'+' if diff >= 0 else ''}{diff:.4f}"
return "—"
lines = []
lines.append("# 遅延チャンキング比較レポート(API版)")
lines.append("")
lines.append(f"- 生成日時: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
lines.append(f"- クエリ数: {len(comparison_data)}")
lines.append("")
lines.append("## サマリー")
lines.append("")
lines.append("| Q | クエリ | 正解チャンク | 従来手法(正解) | 遅延チャンキング(正解) | 改善量 |")
lines.append("| --- | --- | --- | --- | --- | --- |")
for i, d in enumerate(comparison_data, start=1):
naive_str = fmt_rank_score(d["naive_rank"], d["naive_score"])
late_str = fmt_rank_score(d["late_rank"], d["late_score"])
diff_str = fmt_diff(d["naive_score"], d["late_score"])
expected_str = f"{d['expected_doc']}[{d['expected_chunk_idx']}]"
lines.append(
f"| Q{i} | {md_escape(d['query'])} | {md_escape(expected_str)} | "
f"{md_escape(naive_str)} | {md_escape(late_str)} | {diff_str} |"
)
lines.append("")
for i, d in enumerate(comparison_data, start=1):
diff_str = fmt_diff(d["naive_score"], d["late_score"])
lines.append(f"### Q{i}")
lines.append("")
lines.append(f"- クエリ: {md_escape(d['query'])}")
lines.append(f"- 正解チャンク: `{d['expected_doc']}[{d['expected_chunk_idx']}]`")
if d["note"]:
lines.append(f"- ポイント: {md_escape(d['note'])}")
lines.append(f"- 従来手法(正解チャンク): {fmt_rank_score(d['naive_rank'], d['naive_score'])}")
lines.append(f"- 遅延チャンキング(正解チャンク): {fmt_rank_score(d['late_rank'], d['late_score'])}")
lines.append(f"- 改善量: {diff_str}")
lines.append("")
lines.append("#### 従来手法 Top3")
lines.append("")
lines.append("| Rank | ドキュメント[chunk] | Score | 正解 |")
lines.append("| --- | --- | --- | --- |")
for r in d["naive_top3"]:
is_expected = r["doc_title"] == d["expected_doc"] and r["chunk_idx"] == d["expected_chunk_idx"]
expected_mark = "✓" if is_expected else ""
lines.append(
f"| #{r['rank']} | {md_escape(r['doc_title'])}[{r['chunk_idx']}] | {r['score']:.4f} | {expected_mark} |"
)
lines.append("")
lines.append("#### 遅延チャンキング Top3")
lines.append("")
lines.append("| Rank | ドキュメント[chunk] | Score | 正解 |")
lines.append("| --- | --- | --- | --- |")
for r in d["late_top3"]:
is_expected = r["doc_title"] == d["expected_doc"] and r["chunk_idx"] == d["expected_chunk_idx"]
expected_mark = "✓" if is_expected else ""
lines.append(
f"| #{r['rank']} | {md_escape(r['doc_title'])}[{r['chunk_idx']}] | {r['score']:.4f} | {expected_mark} |"
)
lines.append("")
with open(save_path, "w", encoding="utf-8") as f:
f.write("\n".join(lines))
print(f"[INFO] Markdown レポートを保存しました: {save_path}")
# ============================================================================
# メイン
# ============================================================================
def main():
print("""
╔══════════════════════════════════════════════════════════════╗
║ pplx-embed-context-v1-0.6B 遅延チャンキング デモ(API版) ║
║ 従来手法 vs Late Chunking ベクトル検索精度比較 ║
╚══════════════════════════════════════════════════════════════╝
""")
chunk_texts, chunk_meta = build_chunk_index(DOCUMENTS)
print(f"チャンク総数: {len(chunk_texts)}")
for i, m in enumerate(chunk_meta):
print(f" [{i:2d}] {m['doc_title']:10} チャンク{m['chunk_idx']}: {m['text_preview']}")
print("\n" + "=" * 60)
print("エンベディング生成")
print("=" * 60)
print("\n[1/3] ナイーブ方式でエンベディング生成中...")
naive_embs = embed_standard(chunk_texts)
print(f" → shape: {naive_embs.shape}")
print("[2/3] 遅延チャンキング方式でエンベディング生成中...")
doc_chunks = [doc["chunks"] for doc in DOCUMENTS]
late_embs = embed_contextualized(doc_chunks)
print(f" → shape: {late_embs.shape}")
print("[3/3] クエリをエンコード中...")
query_texts = [q["query"] for q in QUERIES]
query_embs = embed_standard(query_texts)
print(f" → shape: {query_embs.shape}")
comparison_data = run_comparison(query_embs, naive_embs, late_embs, chunk_meta, QUERIES)
plot_comparison(comparison_data)
print_summary(comparison_data)
write_markdown_report(comparison_data)
if __name__ == "__main__":
main()
Appendix-2 モデル概要
pplx-embed ファミリーとは
Perplexity AI が 2026年2月にリリースしたテキスト埋め込みモデルファミリーです。Qwen3 をベースに、拡散ベース継続事前学習(diffusion-based continued pretraining)でデコーダを双方向エンコーダに変換し、全注意(full bidirectional attention)によるトークン表現を実現しています。
以下では、これらの技術用語について簡単に説明します。
拡散ベース継続事前学習とは
通常の LLM は左から右への一方向(因果)マスクで事前学習されています。この「因果デコーダ」を埋め込みモデルとして使うには、全方向の文脈を見られるようにする必要があります。拡散ベース継続事前学習では、テキストにランダムにノイズマスクを適用し、マスクされた部分を復元するタスクで追加学習を行います。このプロセスを通じて、モデルは左右両方向の文脈を同時に参照する能力を獲得します。つまり、もともと「左から右にだけ読む」モデルを「全体を見渡して読む」モデルに変換する手法です。
デコーダから双方向エンコーダへの変換
GPT 系の LLM はデコーダ(Decoder)アーキテクチャを採用しており、ある位置のトークンはそれより左側のトークンしか参照できません。これは文章を生成するタスクには適していますが、埋め込みの生成ではテキスト全体の意味を捉える必要があるため、右側の文脈も参照できることが望ましいです。上述の拡散ベース継続事前学習により、因果マスクを外して全方向のアテンションを有効にした双方向エンコーダ(Bidirectional Encoder)へと変換しています。BERT のように文の全体を双方向に読める構造になるイメージです。
全注意(Full Bidirectional Attention)とは
通常のデコーダ LLM では、各トークンはそれより前のトークンにしかアテンションを向けられません(因果アテンション)。全注意では、この制約を取り払い、すべてのトークンが入力系列中のすべてのトークンに対してアテンションを計算します。これにより、文中のどの位置にあるトークンも文書全体の文脈を反映した表現を得ることができます。
tanh ベース Mean Pooling とは
Transformer の出力は各トークンに対応するベクトルの系列です。これを1つの固定長ベクトル(埋め込み)にまとめるために Mean Pooling(平均プーリング)を使います。pplx-embed では、この Mean Pooling の前に tanh 関数を適用しています。tanh は出力を -1 から +1 の範囲に収めるため、INT8 量子化(-128 ~ +127 の整数への変換)と相性が良く、量子化時の情報損失を最小限に抑えることができます。
ストレートスルー勾配推定とは
INT8 量子化では連続値を離散的な整数に丸めますが、丸め操作は微分不可能であるため、そのままでは勾配を計算できず逆伝播ができません。ストレートスルー勾配推定(Straight-Through Estimator, STE)は、順伝播では丸め操作をそのまま行い、逆伝播では丸め操作を恒等関数とみなして勾配をそのまま通過させる手法です。これにより、「学習時から量子化を前提とした最適化」が可能になり、推論時に別途量子化を行うよりも高い精度を維持できます。
モデルスペック一覧
| 項目 | pplx-embed-v1 | pplx-embed-context-v1 |
|---|---|---|
| 用途 | 標準的な密ベクトル検索・クエリ埋め込み | 文書文脈を考慮したチャンク埋め込み(遅延チャンキング) |
| パラメータ | 0.6B / 4B | 0.6B / 4B |
| 埋め込み次元 | 0.6B → 1024, 4B → 2560 | 0.6B → 1024, 4B → 2560 |
| コンテキスト長 | 32K トークン | 32K トークン |
| 量子化 | INT8 / Binary(最大32倍圧縮) | INT8 / Binary(最大32倍圧縮) |
| ライセンス | MIT | MIT |
| 入力形式 | 文字列のリスト | 文書ごとにチャンクをグループ化したリストのリスト |
主な特徴
pplx-embed ファミリーにはいくつかの注目すべき特徴があります。
まず、インストラクションプレフィックスが不要です。多くの埋め込みモデルでは "query: " や "passage: " 等のプレフィックスを付与する必要がありますが、pplx-embed ではプレフィックスなしでそのままテキストを渡すことができます。ベンチマーク上は 2〜3% の差がありますが、運用上のプロンプト管理コストを排除できるメリットがあります。
次に、ネイティブ INT8 量子化に対応しています。上述の tanh ベース Mean Pooling とストレートスルー勾配推定により、学習時から INT8 量子化を前提として訓練されています。推論時にも INT8 で出力されるため、追加の量子化処理が不要です。
さらに、4B モデルでは Matryoshka 次元削減に対応しています。2560 次元から 512 次元等への次元削減が可能で、品質と速度のトレードオフを柔軟に調整できます。
ベンチマーク性能
| ベンチマーク | pplx-embed-v1-4B (INT8) | pplx-embed-context-v1-4B (INT8) | 参考 |
|---|---|---|---|
| MTEB (Multilingual, v2) nDCG@10 | 69.66% | — | Qwen3-Embedding-4B: 69.60%, gemini-embedding-001: 67.71% |
| ConTEB nDCG@10 | — | 81.96% | voyage-context-3: 79.45%, Anthropic Contextual: 72.4% |
| ConTEB nDCG@10 (0.6B) | — | 76.53% | — |
特にコンテキスト対応の ConTEB ベンチマークでは、pplx-embed-context-v1-4B が 81.96% で既存手法を大きく上回っています。
訓練パイプライン概要
pplx-embed の訓練は以下の 5 ステージで構成されています。
- 拡散ベース継続事前学習 ー Qwen3 の因果デコーダを双方向エンコーダに変換
- ペア訓練 ー InfoNCE 損失とバッチ内負例で基礎的な意味整合を確立(英語→多言語の段階的学習)
- 文脈訓練 ー チャンクレベルの意味を文書レベルのコンテキストと結びつける。シーケンス内・バッチ内のコントラストをチャンク・文書の両レベルで組み合わせた二重損失を使用し、pplx-embed-context-v1 を生成
- トリプレット訓練 ー マイニングされたハードネガティブで類似文書間の境界を精緻化
- SLERP マージ ー 文脈チェックポイントとトリプレットチェックポイントを球面線形補間で統合し、pplx-embed-v1 を生成
参考資料
- pplx-embed: State-of-the-Art Embedding Models for Web-Scale Retrieval(Perplexity 公式研究記事)
- Perplexity Embeddings API ドキュメント
- Contextualized Embeddings API ドキュメント
- Günther, M., Mohr, I., Wang, B., & Xiao, H. (2024). Late Chunking: Contextual Chunk Embeddings Using Long-Context Embedding Models. arXiv:2409.04701. 論文 / GitHub / Jina AI ブログ
- perplexity-ai/pplx-embed-v1-0.6b(Hugging Face)
- perplexity-ai/pplx-embed-context-v1-0.6b(Hugging Face)
- perplexity-ai/pplx-embed-v1-4b(Hugging Face)
- perplexity-ai/pplx-embed-context-v1-4b(Hugging Face)