このブログは?
下記のブログでご紹介した OCI に閉じたAI駆動開発環境(Cline + LiteLLM + OCI Generative AI + Oracle Database MCP サーバー)にひと工夫加えて、OCI Generative AI の AIモデルと AIエージェント Cline の能力をフルに発揮させる方法についてご紹介しています。
上記ブログでご紹介している構成に登場する OSS の LiteLLM は、OpenAI、Anthropic、Google Vertex AI、Amazon Bedrock、Azure OpenAI, OCI Generative AI など、さまざまな大規模言語モデル(LLM)の APIサービスに OpenAI 互換インターフェースによるアクセスを提供する SDK と Proxy(ゲートウェイ)です。Cline で、OCI Generative AI サービスの AIモデルを利用する際には必須となる OSS です。
LiteLLM そのものは下記のブログでご紹介しています。
AIエージェントは、ユーザーとの対話、LLによる思考(Reasoning)、ツールの呼び出しを繰り返すことで膨大なコンテキスト(LLMへの入力情報)を扱う必要があります。
AIエージェントは、このような長大なコンテキストを効率よく扱うためのさまざまなコンテキスト・エンジニアリングの仕組みを実装していますが、そもそも AIモデルが扱えるコンテキスト長が短いと AIエージェントの能力を発揮することができません。このコンテキスト長は、AIモデル毎に決まっています。しかし、上記の構成のようにLiteLLMを経由する際に、AIモデル自体が持つコンテキスト長の情報がAIエージェントに正しく伝わらず、AIエージェントが、コンテキスト長を安全サイドの小さな値を仮定してしまうことがあります。
そこで、このブログでは、LiteLLM に AIエージェントに対して正しいコンテキスト長を伝えるよう設定する方法をご紹介しています。
また、LiteLLM Proxy を使われている方で LiteLLM Proxy から返される model_info の情報(コンテキスト長、出力長、入出力の合計長、コスト関連のパラメータ、サポートされる機能やパラメータ)が間違っていたり欠落していて困っている方にもお役に立てる内容です。
このブログで解決する課題
LiteLLM Proxy は、AI Provider の API 応答から AIモデルの様々な情報を取得して、/model/info エンドポイント(デフォルト URLは、http://localhost:4000/v1/model/info )で提供しています。
例えば、OCI Generative AI サービスの xai.grok-4-fast-reasoning モデルの場合、コンテキスト長に関して以下のような情報が返ってきます。
"max_tokens": null,
"max_input_tokens": null,
"max_output_tokens": null
model info の全体を見る
{
"data": [
{
"model_name": "xai.grok-4-fast-reasoning",
"litellm_params": {
"use_in_pass_through": false,
"use_litellm_proxy": false,
"merge_reasoning_content_in_choices": false,
"model": "oci/xai.grok-4-fast-reasoning"
},
"model_info": {
"id": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"db_model": false,
"key": "oci/xai.grok-4-fast-reasoning",
"max_tokens": null,
"max_input_tokens": null,
"max_output_tokens": null,
"input_cost_per_token": 0,
"input_cost_per_token_flex": null,
"input_cost_per_token_priority": null,
"cache_creation_input_token_cost": null,
"cache_creation_input_token_cost_above_200k_tokens": null,
"cache_read_input_token_cost": null,
"cache_read_input_token_cost_above_200k_tokens": null,
"cache_read_input_token_cost_flex": null,
"cache_read_input_token_cost_priority": null,
"cache_creation_input_token_cost_above_1hr": null,
"input_cost_per_character": null,
"input_cost_per_token_above_128k_tokens": null,
"input_cost_per_token_above_200k_tokens": null,
"input_cost_per_query": null,
"input_cost_per_second": null,
"input_cost_per_audio_token": null,
"input_cost_per_token_batches": null,
"output_cost_per_token_batches": null,
"output_cost_per_token": 0,
"output_cost_per_token_flex": null,
"output_cost_per_token_priority": null,
"output_cost_per_audio_token": null,
"output_cost_per_character": null,
"output_cost_per_reasoning_token": null,
"output_cost_per_token_above_128k_tokens": null,
"output_cost_per_character_above_128k_tokens": null,
"output_cost_per_token_above_200k_tokens": null,
"output_cost_per_second": null,
"output_cost_per_video_per_second": null,
"output_cost_per_image": null,
"output_cost_per_image_token": null,
"output_vector_size": null,
"citation_cost_per_token": null,
"tiered_pricing": null,
"litellm_provider": "oci",
"mode": null,
"supports_system_messages": null,
"supports_response_schema": null,
"supports_vision": null,
"supports_function_calling": null,
"supports_tool_choice": null,
"supports_assistant_prefill": null,
"supports_prompt_caching": null,
"supports_audio_input": null,
"supports_audio_output": null,
"supports_pdf_input": null,
"supports_embedding_image_input": null,
"supports_native_streaming": null,
"supports_web_search": null,
"supports_url_context": null,
"supports_reasoning": null,
"supports_computer_use": null,
"search_context_cost_per_query": null,
"tpm": null,
"rpm": null,
"ocr_cost_per_page": null,
"annotation_cost_per_page": null,
"supported_openai_params": [
"stream",
"max_tokens",
"max_completion_tokens",
"temperature",
"tools",
"frequency_penalty",
"logprobs",
"logit_bias",
"n",
"presence_penalty",
"seed",
"stop",
"tool_choice",
"top_p"
]
}
}
]
}
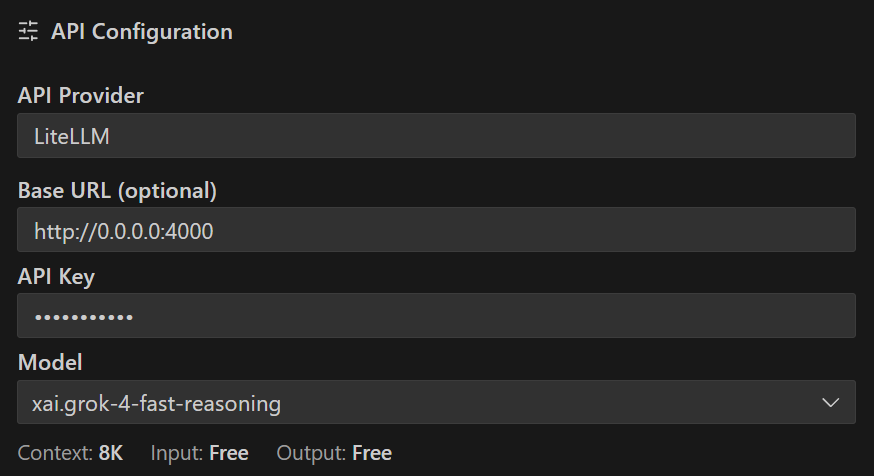
この状態を、コード開発エージェントの Cline から見ると下もスクリーンショットのように "Context" が 8K と認識されていまいます。Cline は、API Provider からコンテキスト長の情報を得られない場合、安全サイドで 8Kトークンと見なす仕様となっているようです。
コード開発エージェントに限らず、AIエージェントでは、ユーザーとの対話履歴、AIモデルによる思考(Reasoning)の履歴、ツールの呼び出しの履歴や Todoリストを維持することで目的を見失わずに処理を継続することができます。そのため、これらの情報を AIモデル へ入力する際のデータ長の上限となるコンテキスト長はとても重要なパラメータです。また、これが小さすぎると AI エージェントは本来の能力を発揮することができません。
そこで、AIエージェント、ここでは、Cline に使用するAIモデルの正確なコンテキスト長を知らせる必要があります。
model_info 情報欠落の解決方法
LiteLLM の構成ファイル(config.yaml)で、model_info の情報を上書きすることができます。
下記は、上の例の OCI Generative AI サービスの xai.grok-4-fast-reasoning モデルの場合に max_tokens(入力トークン数+出力トークン数に上限が定義されている場合はこれを指定)を設定した config.yaml です。
litellm_settings:
telemetry: False
return_response_headers: True
redact_messages_in_exceptions: True
general_settings:
master_key: "os.environ/LITELLM_MASTER_KEY"
disable_spend_logs: False
oci_base_params: &oci_auth
oci_user: "os.environ/OCI_USER"
oci_fingerprint: "os.environ/OCI_FINGERPRINT"
oci_tenancy: "os.environ/OCI_TENANCY"
oci_key_file: "os.environ/OCI_KEY_FILE"
oci_compartment_id: "os.environ/OCI_COMPARTMENT_ID"
oci_region: "us-chicago-1"
drop_params: True
model_list:
- model_name: xai.grok-4-fast-reasoning
litellm_params:
model: oci/xai.grok-4-fast-reasoning
model_info:
max_tokens: 2000000
なお、Google Gemini のように最大入力トークン数に個別の上限が定義されている場合は、max_input_tokensを、最大出力トークン数に個別の上限が定義されている場合は、max_output_tokensを設定します。
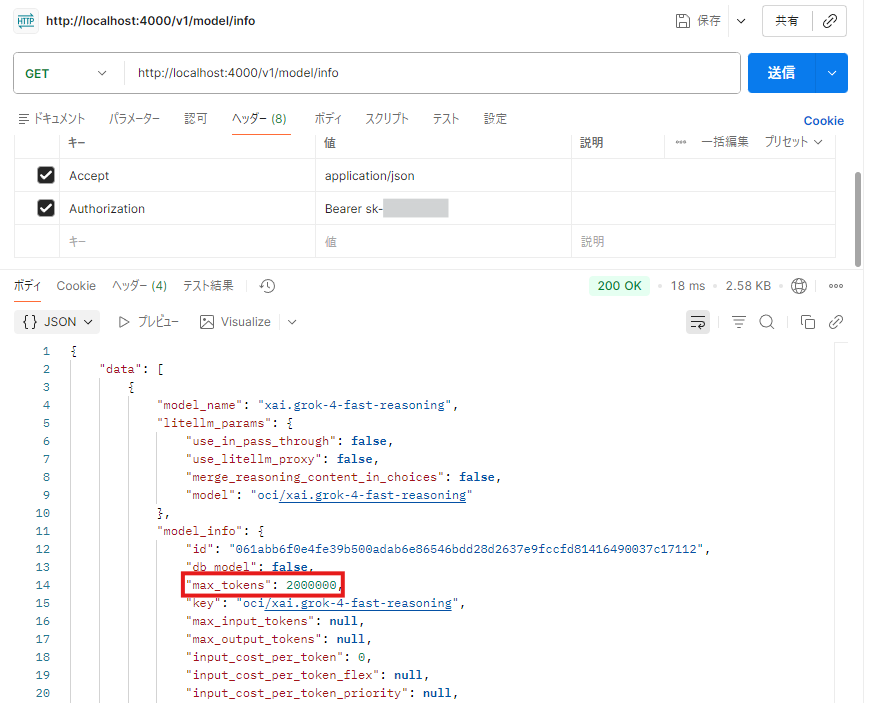
上記の config.yaml を使って、LiteLLM Proxy を立ち上げて、/model/info エンドポイントを GET した際の Postman のスクリーンショットは以下のようになります。max_tokens に 2000000 がセットされているのがわかります。
この場合に Cline の AI Configuration で認識されるコンテキスト長も下記スクリーンショットのとおり 2M となりました。
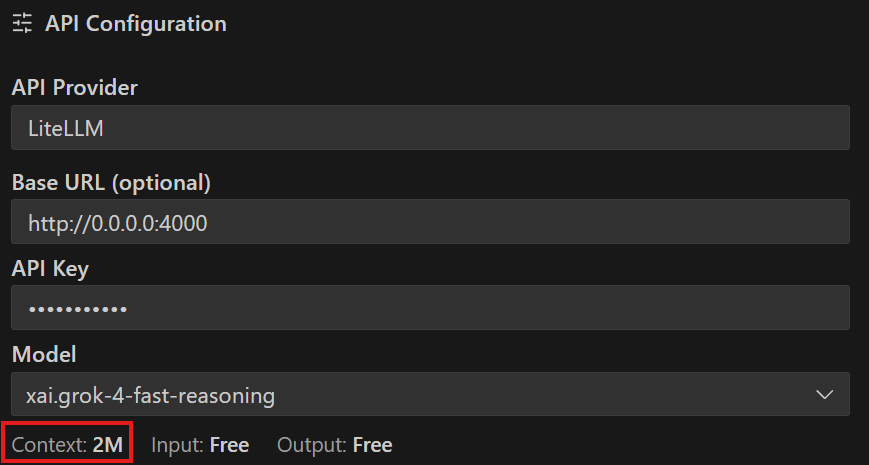
これで、Cline と AIモデル(今回の例は、OCI Generative AI サービスの xai.grok-4-fast-reasoning モデル)の能力をフルに発揮してもらえるようになりました。
OCI Generative AI サービス用LiteLLM構成ファイル(config.yaml)のサンプル
このサンプルは、2025年12月24日時点で、OCI Generative AI サービスで提供されていて、LiteLLM から利用可能なモデルを網羅しています。リージョンは、gpt-oss は、シカゴと大阪、それ以外は、シカゴです。他のリージョンを使われる場合は適宜書き換えてください。
[2026/1/23 更新] このサンプルは、2026年1月23日時点で、OCI Generative AI サービスのオンデマンドサービスで提供されていて、LiteLLM から利用可能なモデルを網羅しています。リージョンは、gemini-2.5-pro、gemini-2.5-flash、gpt-oss 、cohere.command-a は、シカゴと大阪、それ以外は、シカゴです。他のリージョンを使われる場合は適宜書き換えてください。2026/1/23 に追加された新モデルは、xai.grok-4-1-fast-reasoning と xai.grok-4-1-fast-non-reasoning です。
litellm_settings:
telemetry: False
return_response_headers: True
redact_messages_in_exceptions: True
general_settings:
master_key: "os.environ/LITELLM_MASTER_KEY"
disable_spend_logs: False
oci_base_params: &oci_auth
oci_user: "os.environ/OCI_USER"
oci_fingerprint: "os.environ/OCI_FINGERPRINT"
oci_tenancy: "os.environ/OCI_TENANCY"
oci_key_file: "os.environ/OCI_KEY_FILE"
oci_compartment_id: "os.environ/OCI_COMPARTMENT_ID"
drop_params: True
oci_chicago_params: &oci_chicago
<<: *oci_auth
oci_region: "us-chicago-1"
oci_osaka_params: &oci_osaka
<<: *oci_auth
oci_region: "ap-osaka-1"
model_list:
- model_name: google.gemini-2.5-pro(ap-osaka-1)
litellm_params:
<<: *oci_osaka
model: oci/google.gemini-2.5-pro
model_info:
max_input_tokens: 1048576
max_output_tokens: 65536
- model_name: google.gemini-2.5-flash(ap-osaka-1)
litellm_params:
<<: *oci_osaka
model: oci/google.gemini-2.5-flash
model_info:
max_input_tokens: 1048576
max_output_tokens: 65536
- model_name: google.gemini-2.5-pro(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/google.gemini-2.5-pro
model_info:
max_input_tokens: 1048576
max_output_tokens: 65536
- model_name: google.gemini-2.5-flash(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/google.gemini-2.5-flash
model_info:
max_input_tokens: 1048576
max_output_tokens: 65536
- model_name: google.gemini-2.5-flash-lite(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/google.gemini-2.5-flash-lite
model_info:
max_input_tokens: 1048576
max_output_tokens: 65536
- model_name: meta.llama-4-maverick-17b-128e-instruct-fp8(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/meta.llama-4-maverick-17b-128e-instruct-fp8
model_info:
max_output_tokens: 4000
max_tokens: 512000
- model_name: meta.llama-4-scout-17b-16e-instruct(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/meta.llama-4-scout-17b-16e-instruct
model_info:
max_output_tokens: 4000
max_tokens: 192000
- model_name: meta.llama-3.3-70b-instruct(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/meta.llama-3.3-70b-instruct
model_info:
max_output_tokens: 4000
max_tokens: 128000
- model_name: meta.llama-3.2-90b-vision-instruct(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/meta.llama-3.2-90b-vision-instruct
model_info:
max_output_tokens: 4000
max_tokens: 128000
- model_name: openai.gpt-oss-120b(ap-osaka-1)
litellm_params:
<<: *oci_osaka
model: oci/openai.gpt-oss-120b
model_info:
max_tokens: 128000
- model_name: openai.gpt-oss-20b(ap-osaka-1)
litellm_params:
<<: *oci_osaka
model: oci/openai.gpt-oss-20b
model_info:
max_tokens: 128000
- model_name: openai.gpt-oss-120b(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/openai.gpt-oss-120b
model_info:
max_tokens: 128000
- model_name: openai.gpt-oss-20b(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/openai.gpt-oss-20b
model_info:
max_tokens: 128000
- model_name: xai.grok-code-fast-1(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/xai.grok-code-fast-1
model_info:
max_tokens: 256000
- model_name: xai.grok-4-1-fast-reasoning(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/xai.grok-4-1-fast-reasoning
model_info:
max_tokens: 2000000
- model_name: xai.grok-4-1-fast-non-reasoning(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/xai.grok-4-1-fast-non-reasoning
model_info:
max_tokens: 2000000
- model_name: xai.grok-4-fast-reasoning(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/xai.grok-4-fast-reasoning
model_info:
max_tokens: 2000000
- model_name: xai.grok-4-fast-non-reasoning(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/xai.grok-4-fast-non-reasoning
model_info:
max_tokens: 2000000
- model_name: xai.grok-4(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/xai.grok-4
model_info:
max_tokens: 128000
- model_name: xai.grok-3(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/xai.grok-3
model_info:
max_tokens: 131072
- model_name: xai.grok-3-fast(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/xai.grok-3-fast
model_info:
max_tokens: 131072
- model_name: xai.grok-3-mini(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/xai.grok-3-mini
model_info:
max_tokens: 131072
- model_name: xai.grok-3-mini-fast(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/xai.grok-3-mini-fast
model_info:
max_tokens: 131072
- model_name: cohere.command-a-03-2025(ap-osaka-1)
litellm_params:
<<: *oci_osaka
model: oci/cohere.command-a-03-2025
- model_name: cohere.command-a-03-2025(us-chicago-1)
litellm_params:
<<: *oci_chicago
model: oci/cohere.command-a-03-2025
OCI Generative AI サービス関連パラメータ補足
上記の構成ファイルの例では、OCI Generative AI サービス関連パラメータを環境変数で定義しています。
- OCI_USER(OCIユーザーのOCID)
- OCI_FINGERPRINT(OCI APIキーのフィンガープリント)
- OCI_TENANCY(OCI テナンシのOCID)
- OCI_KEY_FILE(OCI APIキーのキーファイルのパス名)
- OCI_COMPARTMENT_ID(OCI コンパートメントのOCID)
また、LiteLLMのマスターキーも環境変数で設定しています。
- LITELLM_MASTER_KEY
上記の例の config.yaml で、LiteLLM Proxy を起動する際には、上記の環境変数を設定してください。
えっと、あとがきです
OCI Generative AI のモデルで Cline と最も相性が良いのは xai.grok-4-fast-reasoning という気がします(2025年クリスマス時点)。
更新履歴
| 日時 | 更新内容 |
|---|---|
| 2025年12月25日 | 「このブログは?」の前文を書きなおし |
| 2025年12月25日 | 「OCI Generative AI サービス用LiteLLM構成ファイル(config.yaml)のサンプル」に cohere.command-a-03-2025 を追加 |