はじめに
クラウド歴3年、オンプレミス歴1年の女性システムエンジニア、yuinnです。
本記事では、ALB のヘルスチェックの基本的な仕組みから、2025年11月に発表された新機能である ヘルスチェックログ(Health Check Logs) まで、検証結果を交えながら詳しく解説します。
1. ヘルスチェックとは
ALB は、登録されたターゲット(Amazon EC2、IP アドレス、AWS Lambda など)が正常にリクエストを処理できる状態にあるかどうかを確認するために、定期的にリクエストを送信します。
この仕組みをヘルスチェックと呼びます。
ALB は、このヘルスチェックの結果に基づいて、ターゲットへトラフィックを振り分けるかどうかを判断します。
そのため、ヘルスチェックは可用性や負荷分散の品質に大きく関わる重要な機能です。
ターゲットには、主に以下のようなステータスが設定されます。
-
initial:登録直後 -
healthy:正常 -
unhealthy:異常 -
unused:未使用 -
draining:登録解除中
2. ヘルスチェックの主な設定項目
ヘルスチェックの挙動は、主に以下のパラメータによって制御されます。
なお、ターゲットタイプがインスタンスまたは IP アドレスなのか、Lambda なのかによって、一部のデフォルト値が異なるため注意が必要です。
| 設定項目 | 説明 | デフォルト値(インスタンス / IP タイプ) |
|---|---|---|
| HealthCheckIntervalSeconds | 各ターゲットに対してヘルスチェックを実施する間隔(5~300秒) | 30秒 |
| HealthCheckTimeoutSeconds | 応答が返らない場合に失敗と見なすまでの待機時間(2~120秒) | 5秒 |
| HealthyThresholdCount | 正常と判定するまでに必要な連続成功回数(2~10回) | 5回 |
| UnhealthyThresholdCount | 異常と判定するまでに必要な連続失敗回数(2~10回) | 2回 |
※ Lambda ターゲットの場合、HealthCheckTimeoutSeconds のデフォルト値は 30 秒です。
3. ヘルスチェックの判定メカニズム
ALB は単一のノードではなく、複数のノードによって構成されています。
そして、それぞれのノードが独立してヘルスチェックを実施しています。
たとえば、ヘルスチェック間隔を20秒に設定していたとしても、すべてのノードがまったく同じ時刻にヘルスチェックを行うわけではありません。
実際には、以下のようにずれたタイミングでチェックが行われることがあります。
- ノード1:12:00:00、12:00:20、12:00:40
- ノード2:12:00:10、12:00:30、12:00:50
このように、各ノードがそれぞれ独立してヘルスチェックを行っていることがポイントです。
判定の基準
Healthy 判定
ターゲットが正常と見なされるためには、少なくとも 1 つ以上のヘルスチェックに成功する必要があります。
Unhealthy 判定
ターゲットが異常と見なされるのは、すべての ALB ノードにおいて、設定されたしきい値(UnhealthyThresholdCount)の回数だけ連続で失敗した場合です。
つまり、1 台のノードだけが失敗している段階では、直ちにターゲット全体が異常と判定されるわけではありません。
異常判定までの所要時間
異常判定までに要する時間は、以下の要素に依存します。
- ヘルスチェックの間隔
- タイムアウト値
- 異常判定しきい値
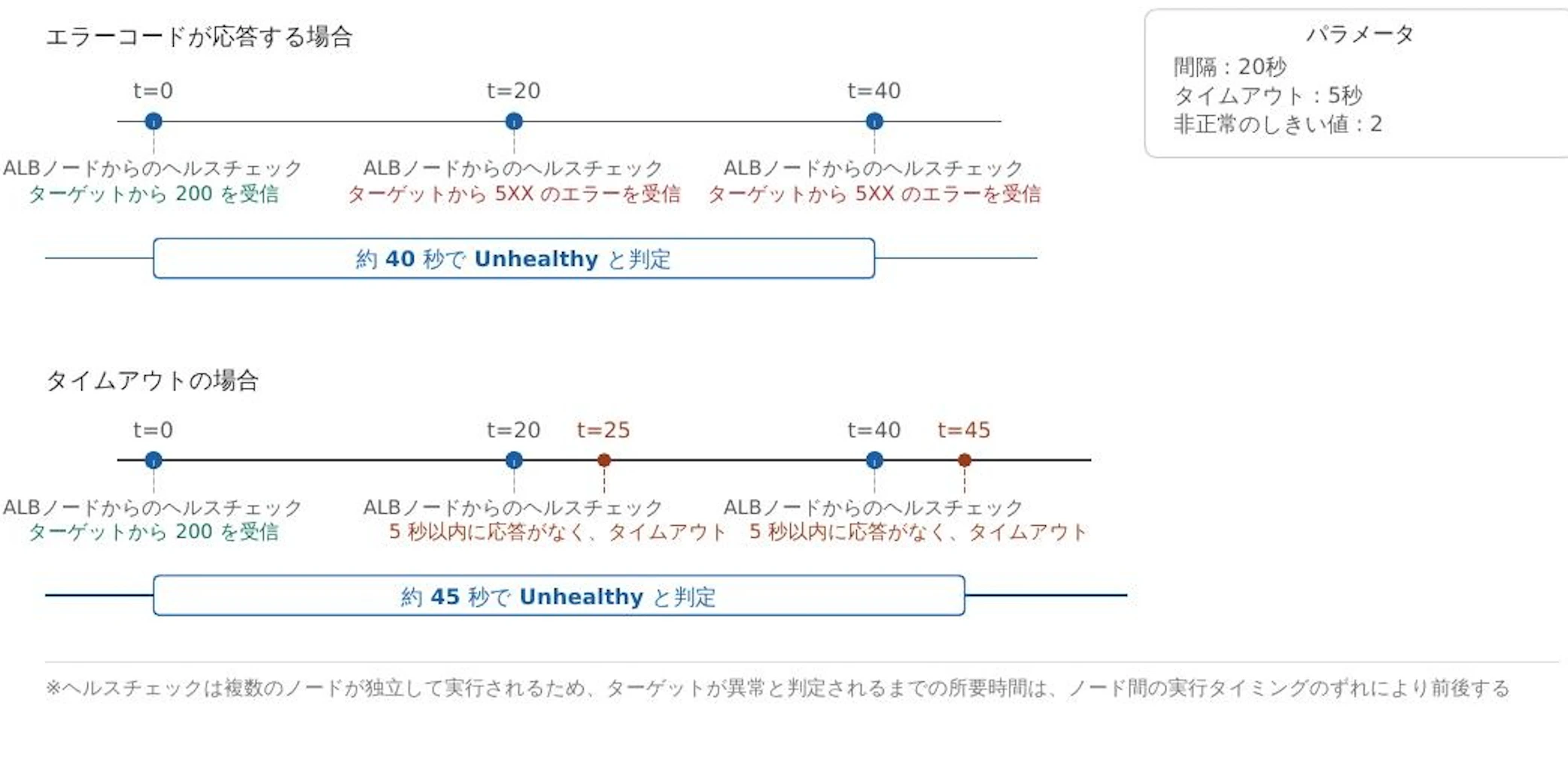
たとえば、以下の設定を例に考えます。
- 間隔:20秒
- タイムアウト:5秒
- 異常判定しきい値:2
この場合、異常判定までの所要時間は、下図のようなイメージになります。
4. 新機能:ヘルスチェックログ(Health Check Logs)
これまで、ALB のヘルスチェックがなぜ失敗したのかを詳しく把握するには、利用者側だけでは情報が足りず、AWS サポートへ確認しなければならない場面もありました。
たとえば、ヘルスチェックの失敗原因が以下のどちらなのかを切り分けるのは、必ずしも簡単ではありませんでした。
- タイムアウトによる失敗
- 想定していたステータスコードと一致しないことによる失敗
しかし、 ヘルスチェックログ(Health Check Logs) が利用できるようになったことで、これらの情報を利用者自身で確認できるようになりました。
そのため、トラブルシューティングや原因調査の効率が大きく向上します。
5. 実際に試してみる
前提として、Amazon EC2 の作成および関連するネットワーク設定は完了しているものとします。
① EC2 上で簡易 HTTP サーバを作成する
まず、80 番ポートで待ち受ける簡易 HTTP サーバを作成します。
今回の動作は以下のとおりです。
• /health → 即時 200
• /slow → 70秒後に 200
from http.server import BaseHTTPRequestHandler, HTTPServer
import time
class Handler(BaseHTTPRequestHandler):
def do_GET(self):
if self.path == "/health":
self.send_response(200)
self.end_headers()
self.wfile.write(b"ok")
return
if self.path == "/slow":
time.sleep(70)
self.send_response(200)
self.end_headers()
self.wfile.write(b"slow response")
return
self.send_response(404)
self.end_headers()
self.wfile.write(b"not found")
def log_message(self, format, *args):
return
HTTPServer(("0.0.0.0", 80), Handler).serve_forever()
(このコードは ChatGPT に生成してもらいました。ありがとう〜ChatGPT先生)
続いて、バックグラウンドでサーバを起動します。
[ec2-user@test-ec2 ~]$sudo nohup python3 /tmp/slow_server.py >/tmp/slow_server.log 2>&1 &
[1] 2027
[ec2-user@test-ec2 ~]$ ps -ef | grep slow_server.py | grep -v grep
root 2027 1266 0 09:25 pts/0 00:00:00 sudo nohup python3 /tmp/slow_server.py
root 2029 2027 0 09:25 pts/1 00:00:00 sudo nohup python3 /tmp/slow_server.py
root 2030 2029 0 09:25 pts/1 00:00:00 python3 /tmp/slow_server.py
[ec2-user@test-ec2 ~]$ curl http://127.0.0.1:80/health
ok
② Amazon S3 の設定
次に、ヘルスチェックログの出力先として利用する Amazon S3 バケットを設定します。
暗号化設定
暗号化オプションは、Amazon S3 マネージドキー(SSE-S3) を選択します。

バケットポリシー
バケットポリシーでは、ログ配信サービスに対して PutObject を許可します。
{
"Version":"2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "logdelivery.elasticloadbalancing.amazonaws.com"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::amzn-s3-demo-bucket/prefix/AWSLogs/123456789012/*"
}
]
}
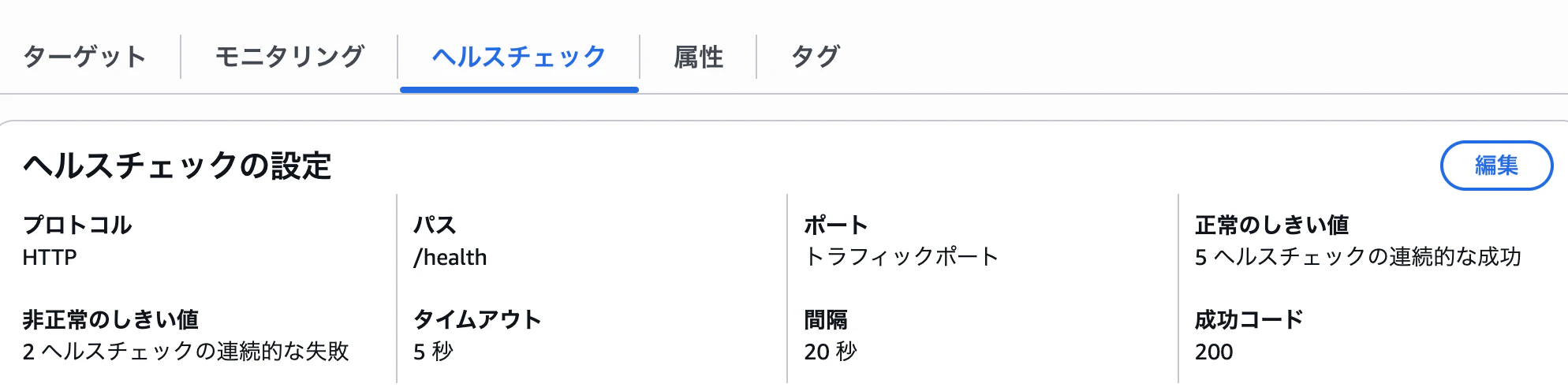
ターゲットグループのヘルスチェック設定
ターゲットグループのヘルスチェックパスを /health に設定します。
また、ヘルスチェック関連の設定値は以下のようにします。
- 間隔:20秒
- タイムアウト:5秒
- 異常判定しきい値:2
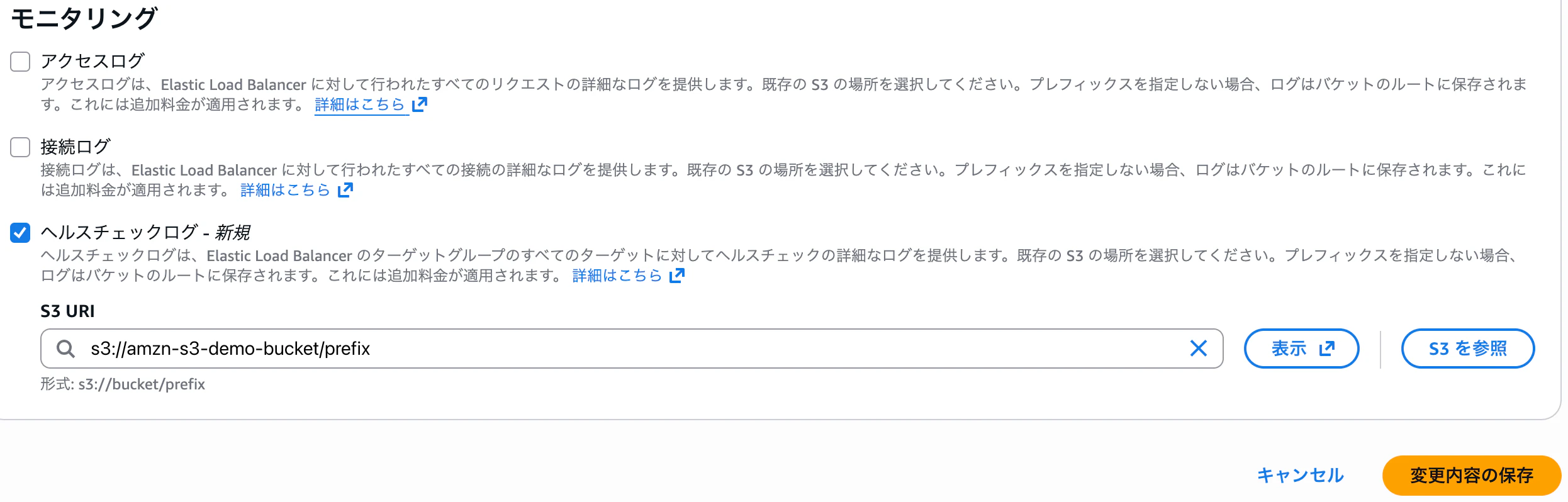
ヘルスチェックログの有効化
ヘルスチェックログは、対象の ALB の [属性] タブから設定できます。
対象の[ALB]>[属性]タブで、[編集] をクリック>[モニタリング]
ターゲットの登録
最後に、EC2 インスタンスをターゲットグループに登録します。
結果
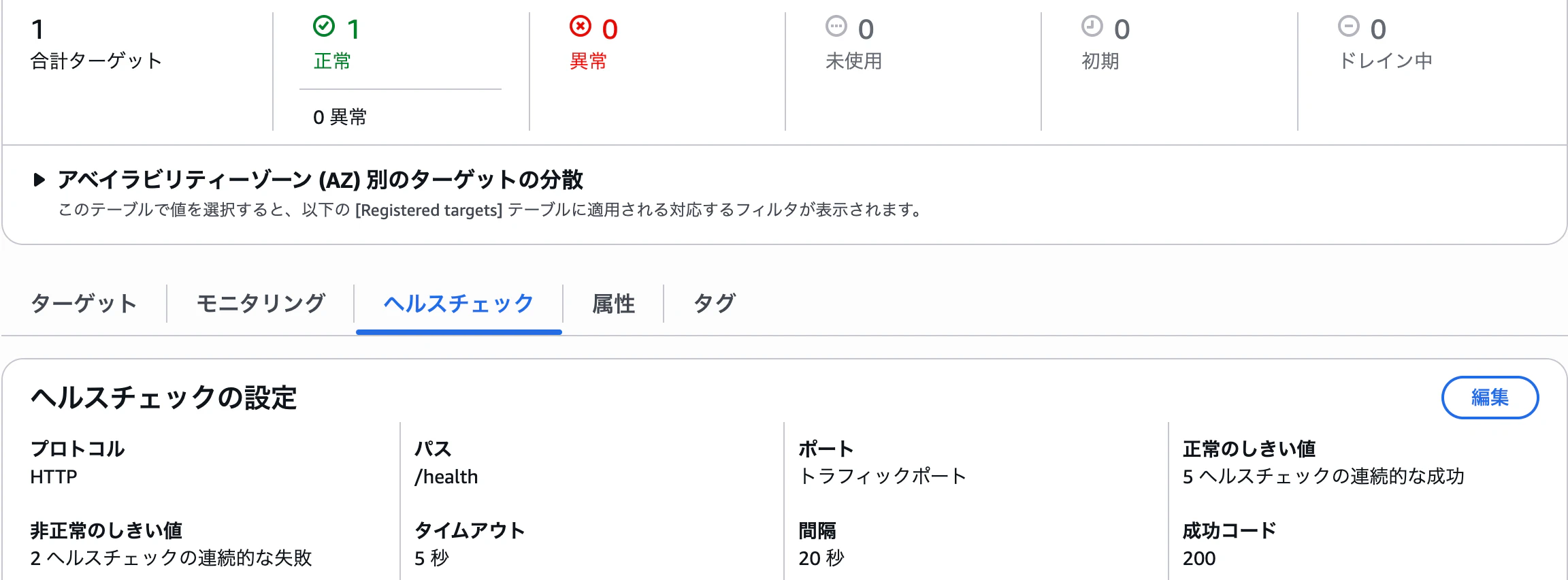
/health をヘルスチェックパスに設定した場合
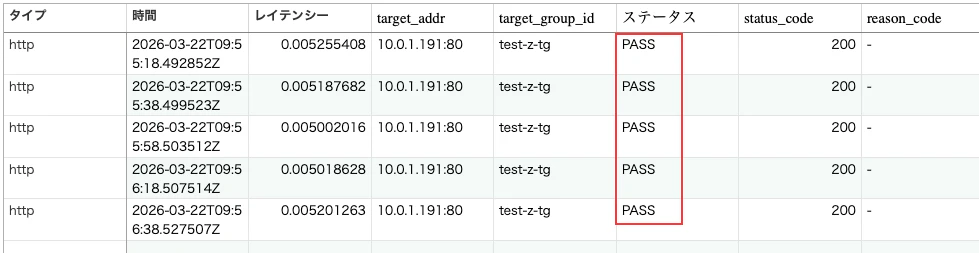
ターゲットグループのヘルスチェックパスを /health に設定した場合、HTTP サーバは /health に対して即時に 200 OK を返します。
そのため、ターゲットのヘルスステータスは Healthy となり、ヘルスチェックログでも status_code が PASS と記録されます。
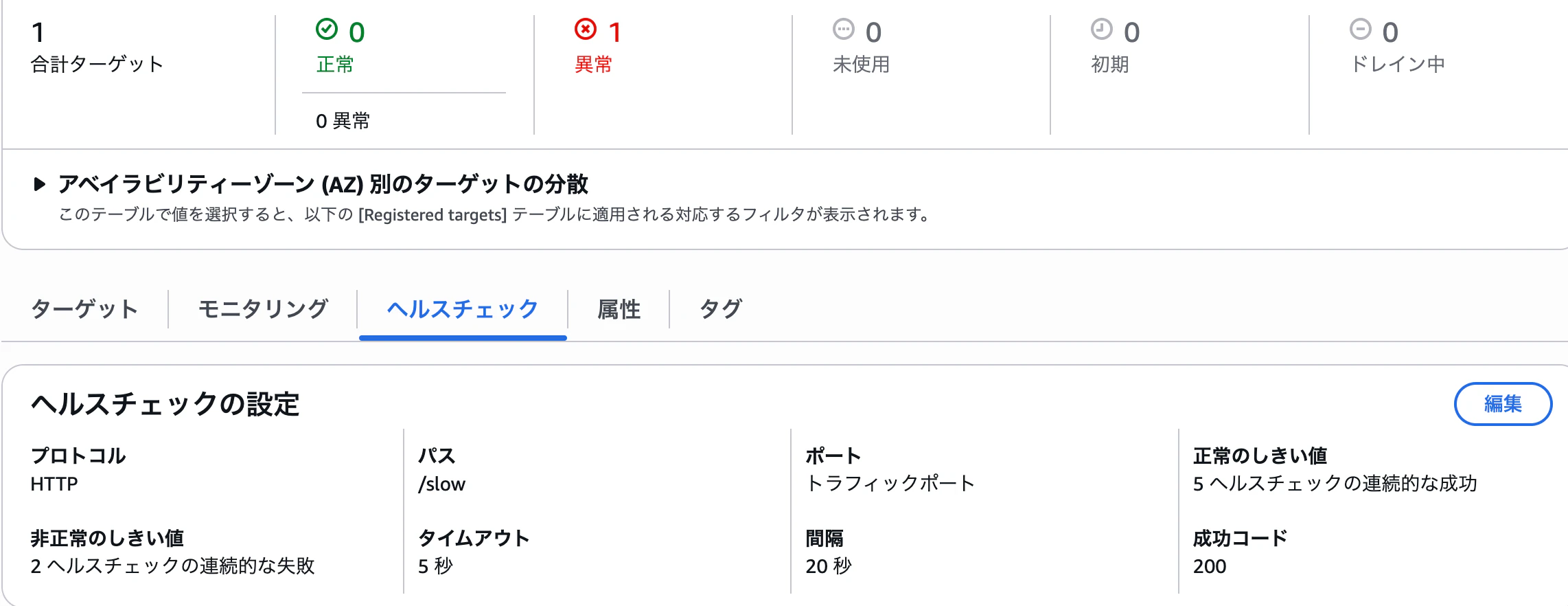
/slow をヘルスチェックパスに設定した場合
一方で、ターゲットグループのヘルスチェックパスを /slow に設定した場合、コード上では /slow にアクセスすると 70 秒後に 200 OK を返すようになっています。
しかし、ヘルスチェックのタイムアウトは 5 秒に設定されています。
Tレスポンス(70秒) > Tタイムアウト(5秒)
この場合、レスポンス時間がタイムアウト時間を上回っているため、毎回のヘルスチェックが失敗します。
さらに、異常判定しきい値を 2 に設定しているため、連続 2 回失敗した時点でターゲットは 異常 と判定されます。
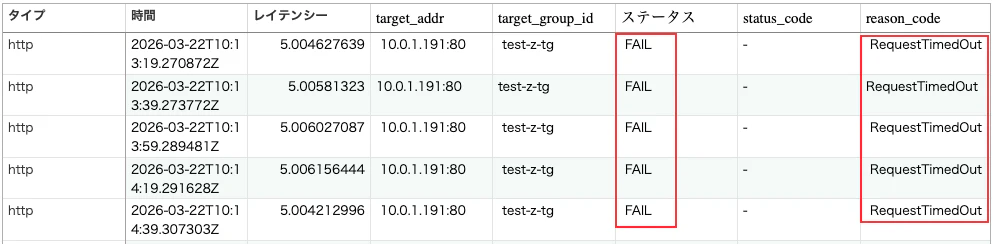
ヘルスチェックログを確認すると、以下のことが分かります。
-
latencyが 5 秒になっている -
reason_codeフィールドにRequestTimedOutが記録されている
このことから、ヘルスチェックに失敗した原因が タイムアウトである ことを確認できます。
※検証の過程で、1点気づいたことがあります。
ヘルスチェックパスを /health に設定している場合、本来であればターゲットは正常と判定され続けるはずです。
しかし、EC2 上で以下のコマンドを実行した後、ターゲットのステータスが Healthy から Unhealthy に変化しました。
curl -i http://127.0.0.1/slow
その原因は、今回のスクリプトで使用しているのが HTTPServer であるためです。
HTTPServer は シングルスレッド で動作するため、同時に処理できるリクエストは 1 つだけです。
そのため、/slow へのリクエストを処理している間、サーバは以下の処理によって 70 秒間ブロックされます。
time.sleep(70)
この間に ALB が GET /health を送信しても、プロセスはすでに /slow の処理で占有されているため、ヘルスチェックに応答することができません。
その結果、ヘルスチェックが連続して失敗し、ターゲットが異常と判定されました。
6.まとめ
- ALB のヘルスチェックは、各ノードによって独立して実施される
- タイムアウト時間を超えた時点で、そのヘルスチェックは失敗として扱われる
- ALB は複数ノードで動作しているため、異常判定までの時間には多少の前後があり得る
- ヘルスチェックログを利用することで、失敗原因を利用者自身で確認できる