こんにちは。
内容に誤りや誤字脱字がありましたら指摘していただけると幸いです。
ロス関数を3つ使って異常検知!「Skip-GANomaly」
今回紹介する論文は、「Skip-GANomaly: Skip Connected and Adversarially Trained Encoder-Decoder Anomaly Detection」(Publisher:IEEE[Submitted on 25 Jan 2019])です。
論文のコードはhttps://github.com/samet-akcay/skip-ganomaly#6-referenceにあります。
今回紹介するSkip-GANomalyは,「GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training」(ACCV 2018)のGeneratorにスキップ結合が加わった進化版です。
前半は、この論文の紹介をします。
後半では、TensorFlow KerasのSubclassing APIを用いた複数ロス関数を持つモデルの実装についてと論文の結果が再現出来るか試した結果を示しました。(殆ど再現しなかったのでコード精査中 (12/2時点))
本記事の流れ
0. 忙しい方へ
1. アーキテクチャの説明
・モデルの構成
・学習の手順
・Loss関数、目的関数について
・異常スコアの計算方法
2. 結果
3. 実装
・Subclassing APIの複数lossを持つモデルの実装方法
・実装の結果
4. 雑感
5. 参考
0.忙しい方へ
・ Generatorにスキップ結合付きオートエンコーダー , DiscriminatorにはDCGANの物を用いて敵対的に正常データのみを学習。
**・ 損失関数は3つ。**Generatorの出力、Discriminatorの畳み込み層の最終層と活性化関数の出力に適用。
・以前の画像異常検知SOTAモデルに対して定量的且つ定性的に優れた結果を出した。


1. アーキテクチャの説明
まず、Skip-GANomalyの全体の図を以下に示します。
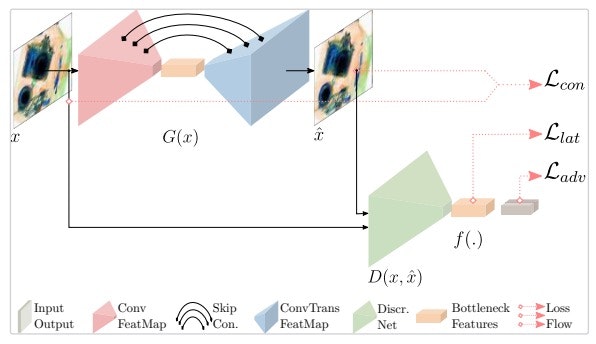
1.1 モデルの構成
主なモデルを構成しているネットワークは、Encoder×2とDecoder×1です。
今回は、EncoderとDecoderをつなげてスキップ結合を組み込んでGenerator(U-Netみたい)として使います。
残ったEncoderをDiscriminatorとして用い、GeneratorとDiscriminatorを敵対的に学習させます。
Lossを計算するポイントは、Generatorの出力と、Discriminatorの畳み込み層の最終層、そして全体の出力です。
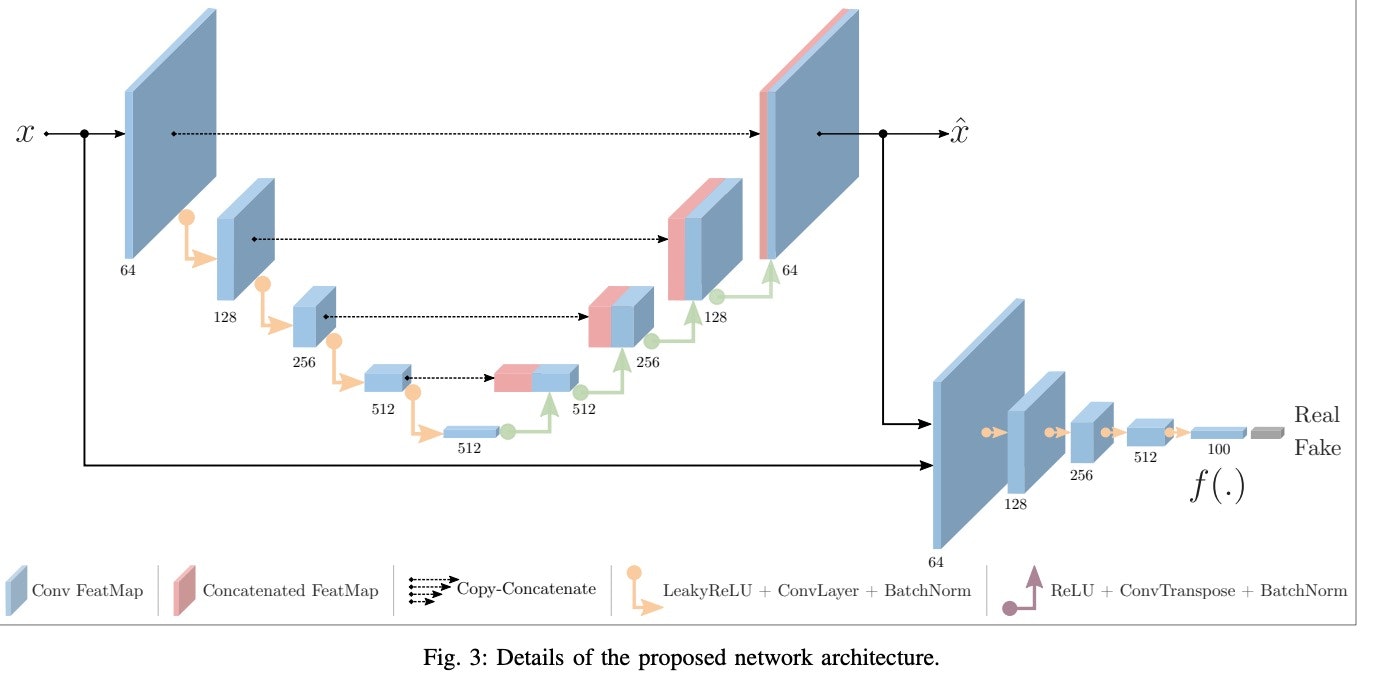
1.2 学習の手順
以下、$x$を元画像、1.1でのGeneratorをG、DiscriminatorをDとします。また、Dの畳み込み最終層の出力をf、活性化関数(sigmoid)の出力をoとします。
1, 正常データxをGに渡します。$x̂$ = G($x$)
2, xとx̂をDに渡します。f, o= D($x$,$\hat{x}$)
1.2.1 Loss関数、目的関数について
今回用いるLoss関数は、Adversarial Loss、Contextual Loss、Latent Lossの3つです。
図1にそれぞれ、$L_{adv}$、$L_{con}$、$L_{lat}$と表されています。
それぞれの式を説明した後に、最終的な目的関数を示します。
・ Adversarial Loss
Dの出力の(シグモイド関数の値)に対して計算するバイナリクロスエントロピーです。
参照ラベルは、(x,$\hat{x}$)に対して(1,0)です。次の式で表されます。
$
\begin{equation}
L_{adv} = \mathbb E_{x\sim p_x}[logD(x)]+{\mathbb E}_{x\sim p_x}[log(1-D(\hat{x}))] \tag{1}
\end{equation}
$
・ Contextual Loss
平均絶対誤差です。このLoss関数は$x$と$\hat{x}$に対して計算されます。要素ごとの差の絶対値です。
$
\begin{equation}
L_{con} = \mathbb E_{x \sim p}|x - \hat{x}|_1 \tag{2}
\end{equation}
$
・ Latent Loss
平均二条誤差です。これは**$x$と$\hat{x}$のそれぞれのDの畳み込み最終層の値に対して計算します**。
ここでlossを取るのは面白いなと思いました。
以下の式で$f$はDの畳み込み最終層の値です。
$
\begin{equation}
L_{lat} = \mathbb E_{x\sim p}|f(x) - f(\hat{x})|_2 \tag{3}
\end{equation}
$
・ 最終的な目的関数
このモデルでは以上3つのLoss関数を計算して以下の目的関数$L$を計算します。
$
\begin{equation}
L = \lambda_{adv}L_{adv} + \lambda_{con}L_{con} + \lambda_{lat}L_{lat} \tag{4}
\end{equation}
$
$\lambda_{adv}$、$\lambda_{con}$、$\lambda_{lat}$は重みです。
論文では、$\lambda_{adv} = 1$、$\lambda_{con} = 40$、$\lambda_{lat} = 1$としています。
1.3 異常スコアの計算方法
異常スコアは、推論時(テスト時)に計算されます。この値が高ければ異常となります。
異常スコア$A(\dot{x})$は次のように表せます。ただし、テストデータを$\dot{x}$とします。
$
\begin{equation}
A(\dot{x}) = \lambda R(\dot{x}) + (1 - \lambda)L\dot(x) \tag{5}
\end{equation}
$
$R$は(2)式の$L_{con}$、$L$は(3)式の$L_{lat}$と同じものです。
論文では、$\lambda = 0.9$としています。
これらの値をテストデータに対して計算した後、[0,1]に正規化します。
$\boldsymbol{A}$を各テストデータに対して計算された異常スコアが入っているベクトルとすると
$
\begin{equation}
\hat{A}(\dot{x}) = \frac{A(\dot{x}) - min(\boldsymbol{A})}{max(\boldsymbol{A}) - min(\boldsymbol{A})} \tag{6}
\end{equation}
$
と書けます。式(6)が最終的な異常スコアです。テスト時はこの値を基にAUCを計算します。
2. 結果
論文で用いられていたデータセットは、CIFAR-10 、UBA 、FFOBです。

UBAとFFOBは、X線写真のデータセットで拳銃やナイフなどの武器が入っているものなどが異常とされています。画像サイズは64×64×3です。
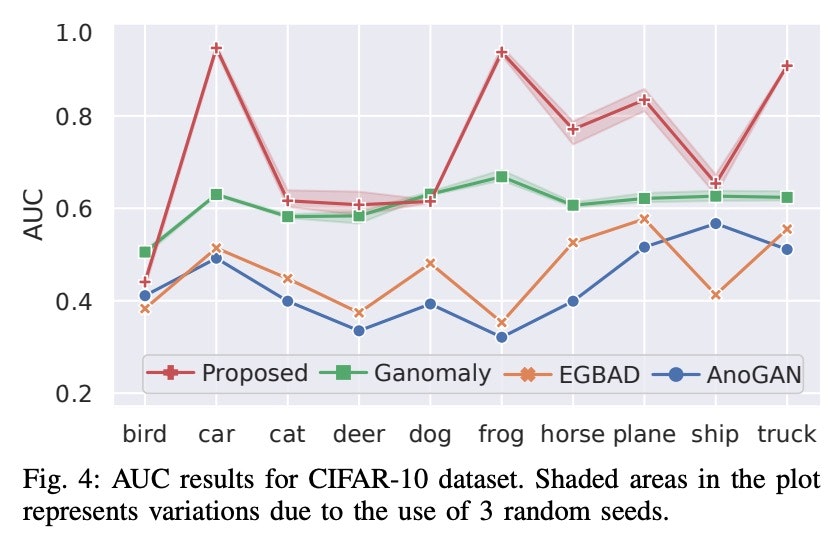
テスト結果です。 以下の値は、(6)式の異常スコアから一つのクラスを異常として判別することに対してのAUCスコアです。
CIFAR-10については、
UBAとFFOBについては、
となったそうです。
表からUBAとFFOBに対してでは圧倒的な威力を持っていることが分かります。
CIFAR-10に対してもbirdとdog以外で最高値です。
しかし、CIFAR-10についてのグラフを見ると異常とみなすクラスによって精度に大きなばらつきがあることが分かります。
そういう意味では、安定性は良くないようです。
3. 実装
この章の後半に示しますが、論文の結果の再現は完璧にはできませんでした。
コードを精査して良い結果が出次第、更新させていただきます。
自分の全体のコードはコードにあります。(コード点検中12/2時点)
この章ではまず、tensorflow.kerasのSubclassing APIで複数出力を持つモデルの定義の方法とコンパイルの方法について説明したいと思います。
その後、CIFAR-10についてのテスト結果を示します。
実装のモデル部分のコードを以下に載せます。 **今回、ロスを取るポイントはGeneratorとDiscriminatorの畳み込み最終層とsigmoid関数の出力です。**
まず、複数出力モデルの定義の方法について説明します。
結論、**「call関数の返り値をディクショナリとして定義する。」**です。
まずGeneratorは次のように定義できます。
class Encoder(tf.keras.models.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(filters = 64,kernel_size = 3,strides = 2)
self.conv2 = tf.keras.layers.Conv2D(filters = 128,kernel_size = 3,strides = 2)
self.conv3 = tf.keras.layers.Conv2D(filters = 256,kernel_size = 3,strides = 2)
self.conv4 = tf.keras.layers.Conv2D(filters = 512,kernel_size = 3,strides = 2)
self.conv5 = tf.keras.layers.Conv2D(filters = 512,kernel_size = 3,strides = 2)
self.bn1 = tf.keras.layers.BatchNormalization()
self.bn2 = tf.keras.layers.BatchNormalization()
self.bn3 = tf.keras.layers.BatchNormalization()
self.bn4 = tf.keras.layers.BatchNormalization()
self.bn5 = tf.keras.layers.BatchNormalization()
self.act1 = tf.keras.layers.LeakyReLU(alpha=0.2)
self.act2 = tf.keras.layers.LeakyReLU(alpha=0.2)
self.act3 = tf.keras.layers.LeakyReLU(alpha=0.2)
self.act4 = tf.keras.layers.LeakyReLU(alpha=0.2)
self.act5 = tf.keras.layers.LeakyReLU(alpha=0.2)
def call(self,x):
x = self.conv1(x)
x = self.bn1(x)
z1 = self.act1(x)
x = self.conv2(z1)
x = self.bn2(x)
z2 = self.act2(x)
x = self.conv3(z2)
x = self.bn3(x)
z3 = self.act3(x)
x = self.conv4(z3)
x = self.bn4(x)
z4 = self.act4(x)
x = self.conv5(z4)
x = self.bn5(x)
z5 = self.act5(x)
return z1 , z2 , z3 , z4 , z5
class Decoder(tf.keras.models.Model):
def __init__(self):
super().__init__()
self.deconv6 = tf.keras.layers.Conv2DTranspose(filters = 512,kernel_size = 3,strides = 2)
self.block6_bn = tf.keras.layers.BatchNormalization()
self.block6_act = tf.keras.layers.ReLU()
self.deconv7 = tf.keras.layers.Conv2DTranspose(filters = 256,kernel_size = 3,strides = 2)
self.block7_bn = tf.keras.layers.BatchNormalization()
self.block7_act = tf.keras.layers.ReLU()
self.deconv8 = tf.keras.layers.Conv2DTranspose(filters = 128,kernel_size = 3,strides = 2)
self.block8_bn = tf.keras.layers.BatchNormalization()
self.block8_act = tf.keras.layers.ReLU()
self.deconv9 = tf.keras.layers.Conv2DTranspose(filters = 64,kernel_size = 3,strides = 2)
self.block9_bn = tf.keras.layers.BatchNormalization()
self.block9_act = tf.keras.layers.ReLU()
self.deconv10 = tf.keras.layers.Conv2DTranspose(filters = 3,kernel_size = 4,strides = 2)
self.output_act = tf.keras.layers.Activation('tanh')
def call(self , z1 , z2 , z3 , z4 ,z5):
z6 = self.deconv6(z5)
z6 = self.block6_bn(z6)
z6 = self.block6_act(z6)
z6 = tf.keras.layers.concatenate([z4,z6], axis = 3)
z7 = self.deconv7(z6)
z7 = self.block7_bn(z7)
z7 = self.block7_act(z7)
z7 = tf.keras.layers.concatenate([z3, z7], axis = 3)
z8 = self.deconv8(z7)
z8 = self.block8_bn(z8)
z8 = self.block8_act(z8)
z8 = tf.keras.layers.concatenate([z2, z8], axis = 3)
z9 = self.deconv9(z8)
z9 = self.block9_bn(z9)
z9 = self.block9_act(z9)
z9 = tf.keras.layers.concatenate([z1, z9], axis = 3)
z10 = self.deconv10(z9)
g_output = self.output_act(z10)
return g_output
class Generator(tf.keras.models.Model):
def __init__(self,Encoder,Decoder):
super().__init__()
self.encoder = Encoder
self.decoder = Decoder
def call(self,x):
z1 , z2 , z3 , z4 , z5 = self.encoder(x)
y = self.decoder(z1 , z2 , z3 , z4 , z5)
return y
model_G = Generator(Encoder(),Decoder())
Decoderの活性化関数にはtanhを採用しています。
少し関係ない話ですが、画像生成モデルを学習させる際は、活性化関数の値域に合わせて学習データのピクセルを正規化するのが一般的(?)だと思います。例えば、sigmoidやsoftmaxを使う場合は0~1に、tanhを用いる場合は-1~1に正規化します。
次にDiscriminatorは、
class Discriminator(tf.keras.models.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(filters = 64,kernel_size = 3,strides = 2)
self.conv2 = tf.keras.layers.Conv2D(filters = 128,kernel_size = 3,strides = 2)
self.conv3 = tf.keras.layers.Conv2D(filters = 256,kernel_size = 3,strides = 2)
self.conv4 = tf.keras.layers.Conv2D(filters = 512,kernel_size = 3,strides = 2)
self.conv5 = tf.keras.layers.Conv2D(filters = 100,kernel_size = 3,strides = 2)
self.bn1 = tf.keras.layers.BatchNormalization()
self.bn2 = tf.keras.layers.BatchNormalization()
self.bn3 = tf.keras.layers.BatchNormalization()
self.bn4 = tf.keras.layers.BatchNormalization()
self.bn5 = tf.keras.layers.BatchNormalization()
self.act1 = tf.keras.layers.LeakyReLU(alpha=0.2)
self.act2 = tf.keras.layers.LeakyReLU(alpha=0.2)
self.act3 = tf.keras.layers.LeakyReLU(alpha=0.2)
self.act4 = tf.keras.layers.LeakyReLU(alpha=0.2)
self.act5 = tf.keras.layers.LeakyReLU(alpha=0.2)
self.flatten = tf.keras.layers.Flatten()
self.dense = tf.keras.layers.Dense(1,'sigmoid')
def call(self,x):
x = self.conv1(x)
x = self.bn1(x)
x = self.act1(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.act2(x)
x = self.conv3(x)
x = self.bn3(x)
x = self.act3(x)
x = self.conv4(x)
x = self.bn4(x)
x = self.act4(x)
final_conv = self.conv5(x)
x = self.bn5(final_conv)
x = self.act5(x)
x = self.flatten(x)
d_output = self.dense(x)
return {'final_conv' : final_conv , 'd_output' : d_output}
model_D = Discriminator()
と書けます。
DiscriminatorはDCGANのものと同じアーキテクチャを採用しているので、
・poolingの代わりに、strides = 2
・活性化関数には、ReLUではなくLeakyReLU
という特徴があります。
最後に、GeneratorとDiscriminatorを合わせて一つのモデルを定義しました。
class SkipGANomaly(tf.keras.models.Model):
def __init__(self , generator , discriminator):
super().__init__()
self.g = generator
self.d = discriminator
def call(self , x):
g_output = self.g(x)
D = self.d(g_output)
return {'g_output' : g_output , 'final_conv' : D['final_conv'] , 'd_output' : D['d_output']}
skipganomaly = SkipGANomaly(model_G , model_D)
これで、一つのモデルで3つの出力を持つモデルを定義できました。(煩雑ですみません。)
このように、定義するとGeneratorやDiscriminatorのどちらかのみを使いたい時に
model_G = skipganomaly.g
model_D = skipganomaly.d
というように書けます。
次に、コンパイルについてです。
skipganomaly.compile(optimizer = g_optim , losses = {'g_output' : 'mean_absolute_error' , 'final_conv' : 'mean_squared_error', 'd_output' : 'binary_crossentropy'} , \
loss_weights = {'g_output' : 1 , 'final_conv' : 40 , 'd_output' : 1} , metrics = ['acc'])
と実装することでモデルをコンパイルできます。
ディクショナリで出力とロス関数やロス関数の係数を指定するところが単一出力のモデルと異なるところです。
loss_weightsは(4)式を反映しています。
fitに関しても同様に学習データとラベルをディクショナリで指定することによって実装できます。(train_on_batchなども同様)
・ 実装の結果
実際に実装して得た結果を示します。(更新日12/2)
環境
Google Colaboratoryを用いました。(tensorflow2系、python 3.6.9 )
3.1 使用したデータセット
CIFAR-10を使用しました。
論文に合わせて64×64にリサイズして使用しました。
3.2 実験結果
CIFAR-10の10クラスすべてにおいてそれぞれ異常としたときの値を取りました。
epoch = 15 , batch size = 32で学習させました。
実装の結果を示します。


このような結果になりました。AnoGANとEGBADと比べて殆どのクラスで良いスコアを出せていますがGANomalyとSkip-GANomalyには大敗してしまっています。
原著のコードを見直して改善し次第更新します。
4. 雑感
Skip-GANomalyは、以前の画像異常検知モデルであるAnoGANやEGBADなどにAUCスコアで圧倒しています。
デメリットは、出力が複数あり実装が複雑になってしまうところとデータによって精度にばらつきがあるところかと思います。
早急に、コードを精査して再現したいと思います。
(はじめてこのモデルを見たとき、個人的にはGeneratorにスキップ結合を入れると画像の再構築が出来すぎてしまい逆にうまく行かなそうな気がしていましたが、そんなことはなかったです。)
5. 参考
・Skip-GANomaly: Skip Connected and Adversarially Trained Encoder-Decoder Anomaly Detection
今回の原著論文
・[GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training]
(https://arxiv.org/abs/1805.06725)
GANomalyの原著論文