この記事が向いている人
- ローカルLLMとチャットしたけど遅いと感じる
- これからローカルLLMを作ってみたいと思っている
- LLMで会話だけじゃなくていろんなことがしたい
この記事が向かない人
- LLMの用途はチャットのみ
- すでにvLLMやTensorRT-LLMを使っている
はじめに
ローカルLLMを初めて自分のPCに構築していざリクエストを投げたとき、こう思いませんでしたか?
「遅くね?」
テキストの流れる速度が遅い。スループット(tokens/sec)が一桁~せいぜい数十程度。
GeminiやChatGPTの高速なレスポンスに慣れてると遅く見えてしまうことでしょう。
商用サービスでは超高級GPUとはいえ激重モデルを使ってるし、ユーザーも多い。
自分ひとりで軽量なモデルを独占できるなら爆速なはず。
こんなに遅いのにCPUやGPU、VRAM使用率は限界に達している。
こんなんじゃ1リクエストが限界でマルチエージェントなんて夢のまた夢。
そう思った方は自分以外にもいると思ってます。
違うんです。
まだ本気を出していないだけなんです。
1リクエストだけで本気は出せない
まずはこちらをご覧ください。

LM Studioのチャット画面で1リクエストだけしたときのスループットがこんな感じです。
4.45 tokens/secしか出てません。
一方こちらはどうでしょうか。

vLLMでサーバーを立てて、128種類の異なるシステムプロンプトのLLMにユーザープロンプトを同時に投げたものを弾幕表示してみました。
どちらもLlama3.3-70B 4bit量子化モデル(厳密には結構違う)を同じPCで動作させています。
要するに、並列化できるポテンシャルがまだあるということです。
なぜ遅いのか
LLMの処理は、すごく大雑把にいうと
VRAMに読み込んだモデルパラメータをすべてGPUコアに運ぶ作業
の繰り返しです。
1トークン出力するたびに、VRAMに展開したモデルデータを1から読み込みなおす処理が発生しています。
LLMに重要なPCスペックはGPUコアよりもメモリ帯域幅
とよく言われますが、VRAMとGPUコアをつなぐメモリ帯域幅が広いほど高速にデータが転送できるため、スループットに直結するわけです。
あなたがAIチャットで1文字出るのが遅いなーと思っている一方、GPUは「1文字出すためだけにモデルデータ数十GBを転送し続けている」のが実状です。
1リクエストから複数リクエストへ
最初、LM Studioとのチャットで思ったほどスループットが出ず、エンジンとの相性のせいにしてvLLMだと早いという話だけを聞き、インストール方法をGeminiに聞いたところ、
次は並列でどこまでスループットが伸びるかを試してみるかい?
と、やたらとGeminiに評価実験を勧められました。
普通に考えたら「並列化したらスループットは落ちる」ものだと思うんですが、なぜ「伸びる」と言ったのか?
半信半疑で提案されたベンチマークスクリプトを回したところ、次のような結果に。
※このときの使用モデルはopenai/gpt-oss-120b
--- Testing Concurrency: 1 ---
Total Time: 2.85s
Total Tokens: 100
Aggregate Throughput: 35.04 tokens/sec
--- Testing Concurrency: 4 ---
Total Time: 3.40s
Total Tokens: 400
Aggregate Throughput: 117.66 tokens/sec
--- Testing Concurrency: 8 ---
Total Time: 3.79s
Total Tokens: 800
Aggregate Throughput: 211.31 tokens/sec
--- Testing Concurrency: 16 ---
Total Time: 4.24s
Total Tokens: 1600
Aggregate Throughput: 376.93 tokens/sec
--- Testing Concurrency: 32 ---
Total Time: 5.42s
Total Tokens: 3200
Aggregate Throughput: 590.56 tokens/sec
--- Testing Concurrency: 64 ---
Total Time: 7.18s
Total Tokens: 6400
Aggregate Throughput: 891.02 tokens/sec
--- Testing Concurrency: 128 ---
Total Time: 10.17s
Total Tokens: 12800
Aggregate Throughput: 1258.76 tokens/sec
128並列で1258tokens/secとかいう見たこともない数字が。
トータルの時間が128倍になるどころか3.5倍にしかなりませんでした。
もちろんこれは「すべてのリクエスト分の出力トークン数の合計」を時間で割っているので、1リクエストあたりのスループットは1/3.5倍になります。
でも仮に1リクエストの処理に全力を出していたら、128並列時はスループットが1/128になるか、リクエストの順番次第で127人分待たされるかのどちらかになるはずです。
なぜ並列化できる余力があるのか
メモリ帯域幅がデータ転送でボトルネックな一方、GPUコアは掛け算と足し算しかしないので一瞬で計算が終わります。
GPU使用率が限界に達しているように見えても、実は計算しているのではなくデータを待っているだけなのです。
vLLMは並列リクエストを前提として、VRAMからのモデルデータを使いまわすことで転送量を減らし、GPUコアの待ちを減らす設計になっているのです。
Continuous Batching
1リクエストだけだと遊びがちなGPUコアを遊ばせない仕組み。
リクエストごとに同じモデルデータを使った計算ができるようにタイミング調整して、モデルデータの転送量を減らす。
結果的に少ないデータ転送量で同時にリクエストを処理できてスループットが増える。
PagedAttention
Continuous Batchingを使って並列化することで増えるKVキャッシュを効率よく捌く仕組み。
どのLLMエンジンを使えばいいのか?
vLLMが並列化に強いというのはわかりました。
でもさらにTensorRT-LLMという、使用するGPUに合わせてチューニングする並列特化のエンジンもあったりします。
どれがいいのか比較実験をしてみました。
評価パラメータ
- スループット(Tokens/sec)
1秒あたりに出力されるトークン数。
大きいほど良い。 - TFTT(秒)
リクエストから最初の1トークン目が出力されるまでの時間
小さいほど良い。
実験環境
-
使用PC
GIGABYTE AI TOP ATOM(DGX Spark互換機)
メモリ帯域幅 273GB/s
GPU GB10(Blackwell) 1PFLOPS -
OS
Ubuntu 24.04.3 LTS -
評価モデル
LLama3.3-70B 4bit量子化
| エンジン | モデル |
|---|---|
| LM Studio | meta/llama-3.3-70b(Q4_K_M) |
| vLLM TensorRT-LLM |
nvidia/Llama-3.3-70B-Instruct-FP4 |
同じLlama-3.3 70B 4bit量子化モデルですが、量子化のコンセプトが異なるので公平とは言えません。
NVFP4はハードウェアネイティブな4bit浮動小数点演算をすることでバッチ処理の高速化、GGUF(Q4_K_M)は量子化ブロックごとの統計的な重み最適化を行って単一リクエストの計算特化をしています。
比較エンジン
-
LM Studio 0.4.2
max concurrent predictionを4 → 128 - vLLM 25.12
-
TensorRT-LLM 1.2.0 rc6
max_batch_size 128
結果
いずれもmax_tokens=100、入力コンテキスト長=100としています。
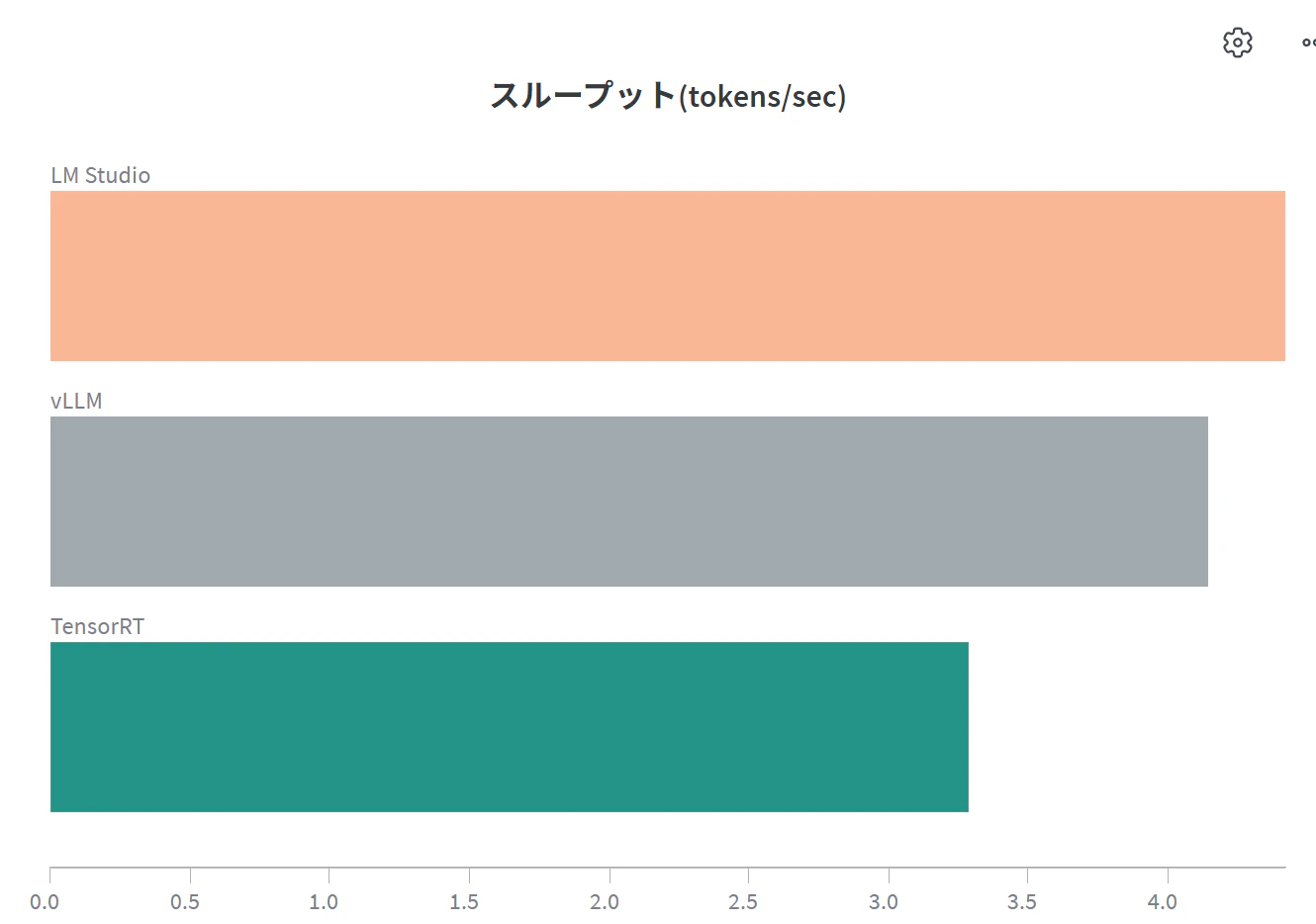
1リクエスト時のスループット比較
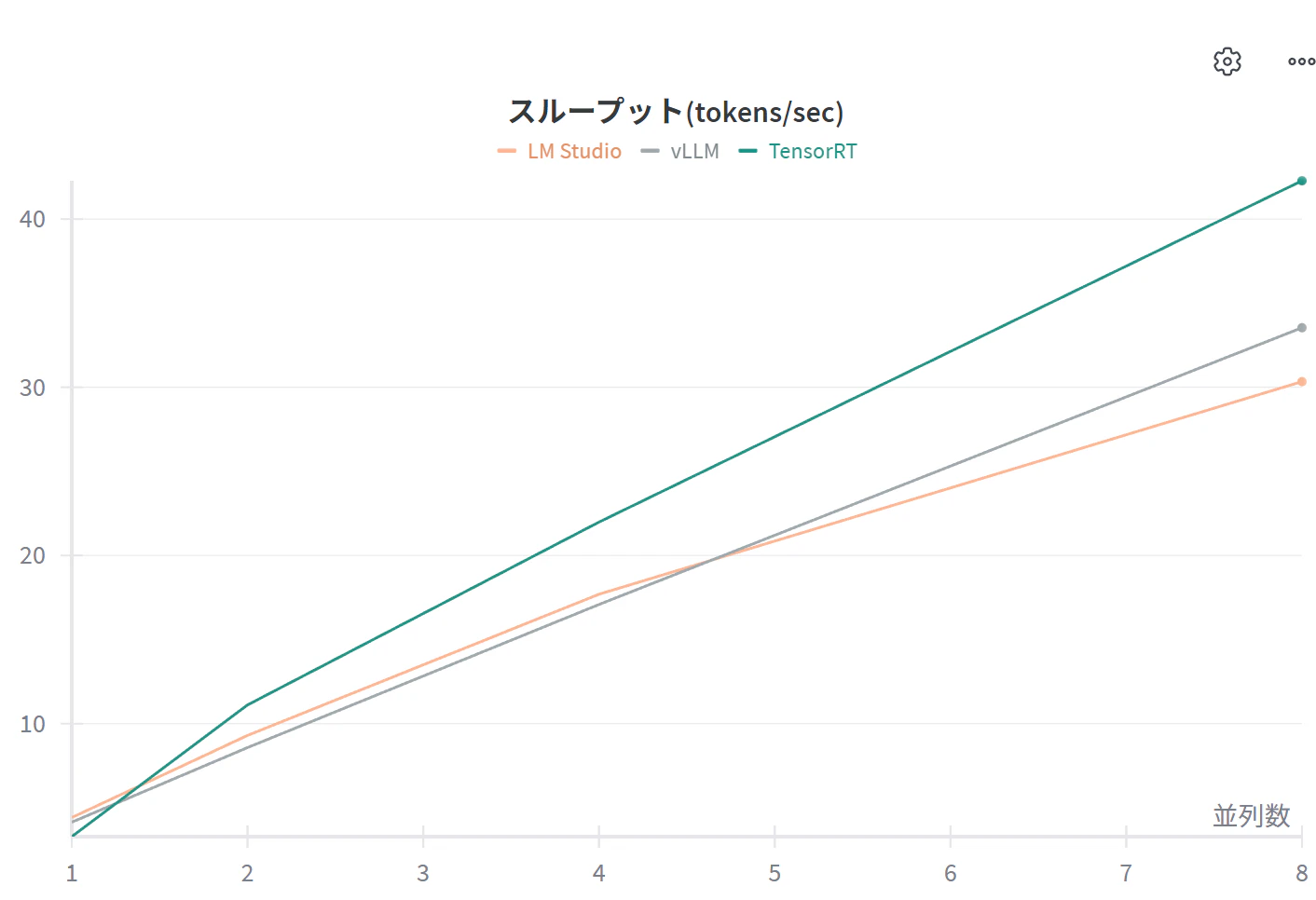
8リクエストまでのスループット比較
128リクエストまでのスループット比較

スループット比較詳細(tokens/sec)
| 並列数 | LM Studio | vLLM | TensorRT |
|---|---|---|---|
| 1 | 4.4 | 4.1 | 3.3 |
| 2 | 9.3 | 8.6 | 11.1 |
| 4 | 17.7 | 17.1 | 22.0 |
| 8 | 30.3 | 33.5 | 42.3 |
| 16 | 58.3 | 65.4 | 82.8 |
| 32 | 102.5 | 120.1 | 160.0 |
| 48 | 141.9 | 172.7 | 232.9 |
| 64 | 168.8 | 226.1 | 302.3 |
| 96 | 203.9 | 318.0 | 432.3 |
| 128 | 214.0 | 396.8 | 541.9 |
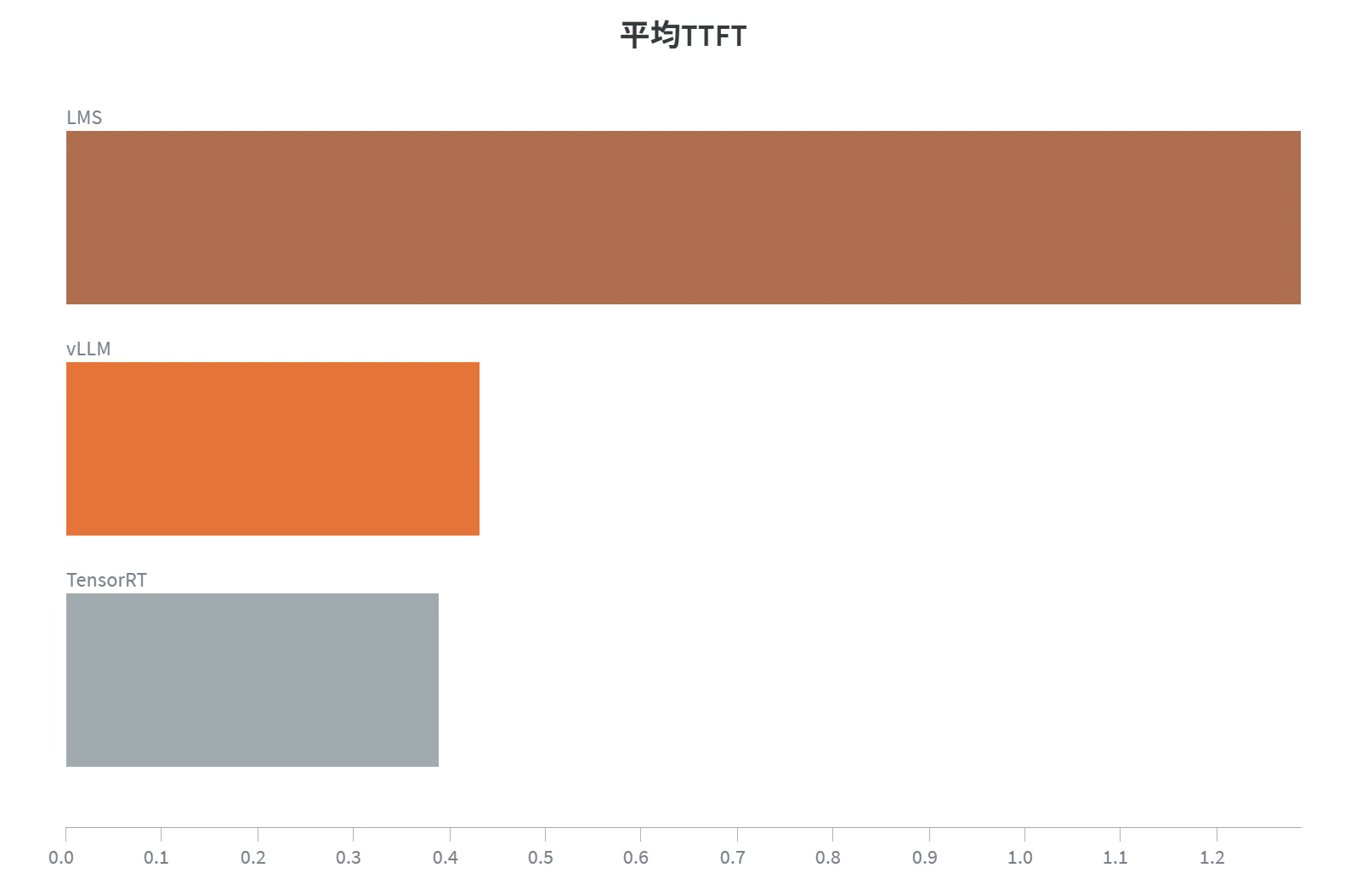
1リクエスト時のTTFT比較
8リクエストまでのTTFT比較

128リクエストまでのTTFT比較
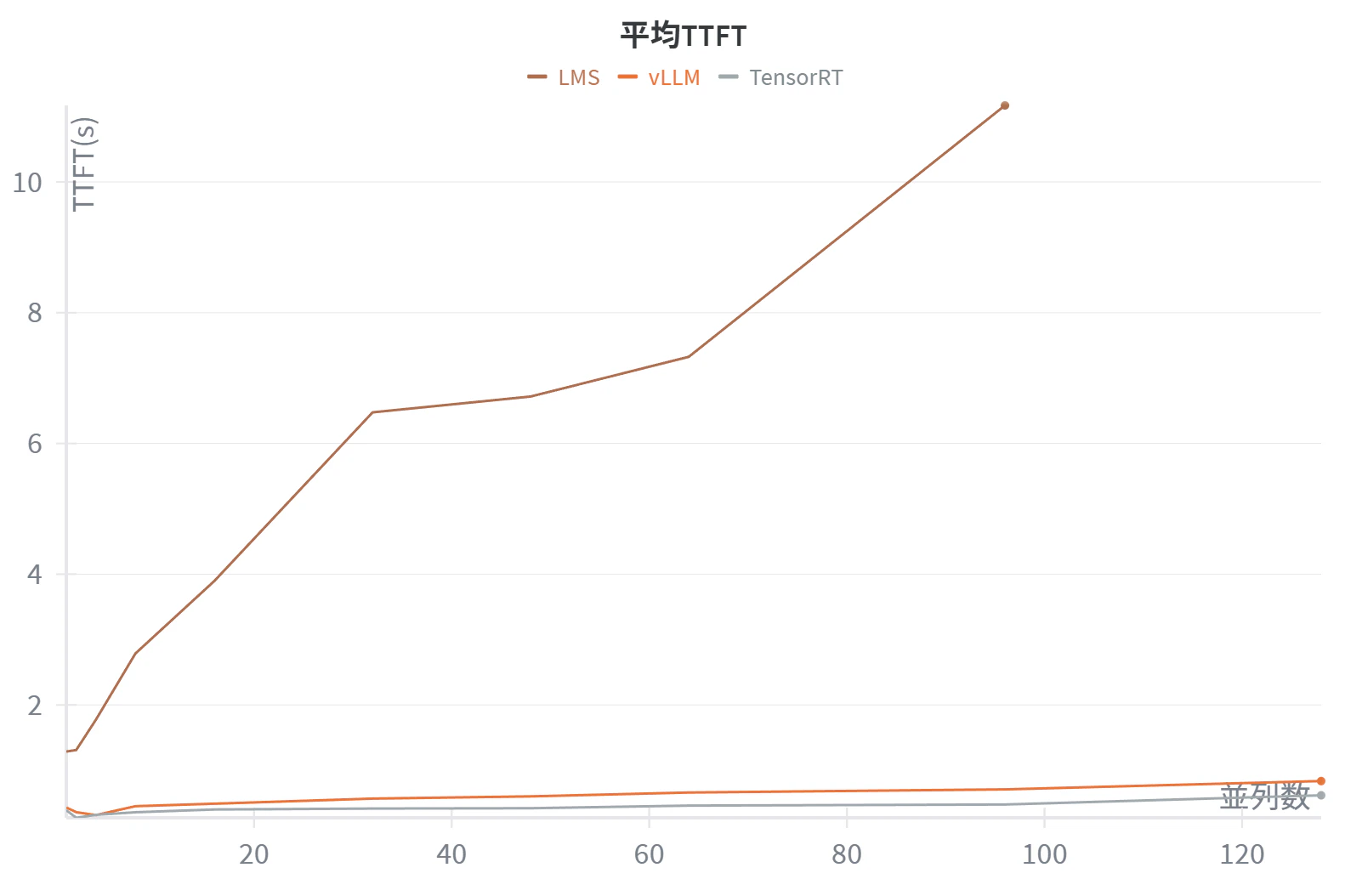
TTFT比較詳細(秒)
| 並列数 | LM Studio | vLLM | TensorRT |
|---|---|---|---|
| 1 | 1.29 | 0.43 | 0.39 |
| 2 | 1.31 | 0.36 | 0.27 |
| 4 | 1.78 | 0.31 | 0.32 |
| 8 | 2.79 | 0.45 | 0.36 |
| 16 | 3.90 | 0.49 | 0.40 |
| 32 | 6.48 | 0.57 | 0.41 |
| 48 | 6.72 | 0.60 | 0.42 |
| 64 | 7.33 | 0.66 | 0.46 |
| 96 | 11.17 | 0.71 | 0.48 |
| 128 | - | 0.84 | 0.62 |
平均レイテンシ(出力し終わるまでの待ち時間)比較
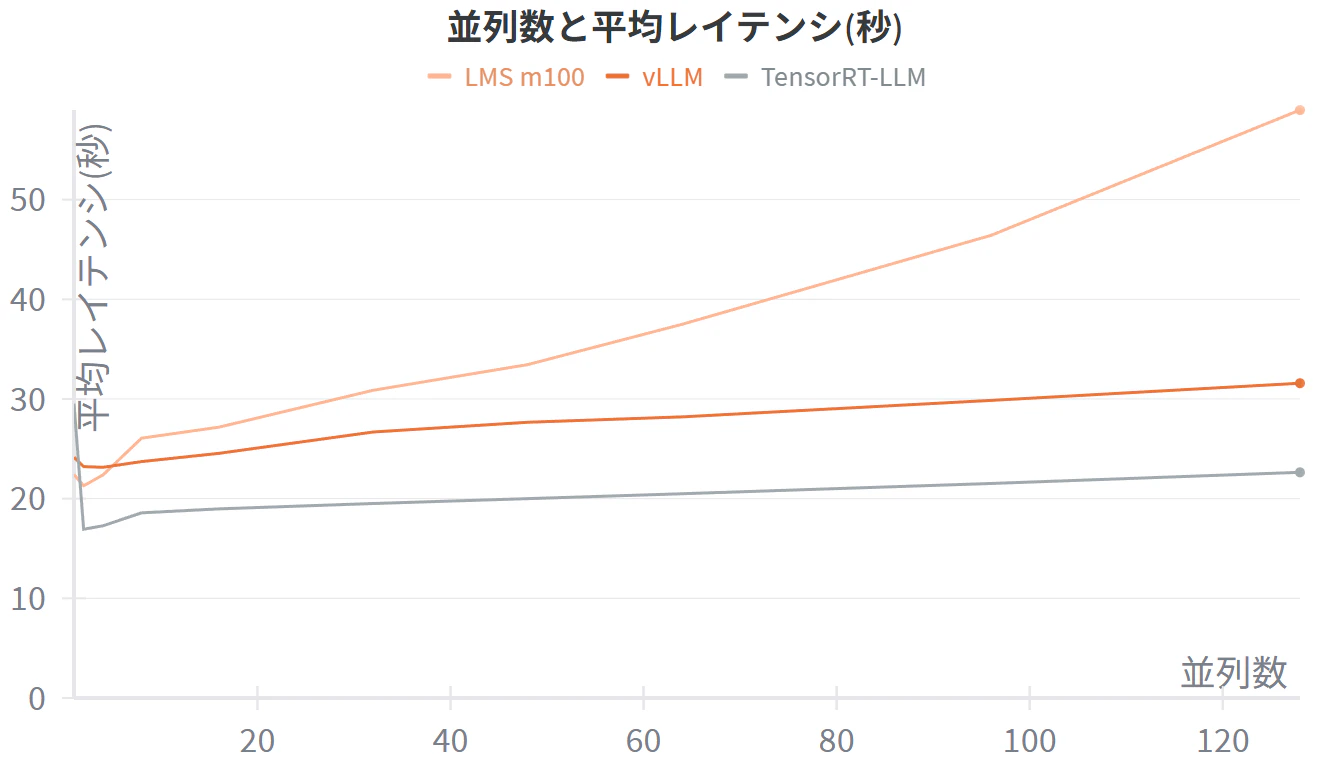
平均レイテンシ比較詳細(秒)
| 並列数 | LM Studio | vLLM | TensorRT |
|---|---|---|---|
| 1 | 22.4 | 24.1 | 29.5 |
| 2 | 21.3 | 23.2 | 16.9 |
| 4 | 22.4 | 23.1 | 17.3 |
| 8 | 26.1 | 23.7 | 18.6 |
| 16 | 27.2 | 24.5 | 19.0 |
| 32 | 30.9 | 26.7 | 19.5 |
| 48 | 33.4 | 27.7 | 20.0 |
| 64 | 37.5 | 28.2 | 20.5 |
| 96 | 46.4 | 29.9 | 21.5 |
| 128 | 59.0 | 31.6 | 22.6 |
入力コンテキスト長を変えたときの比較
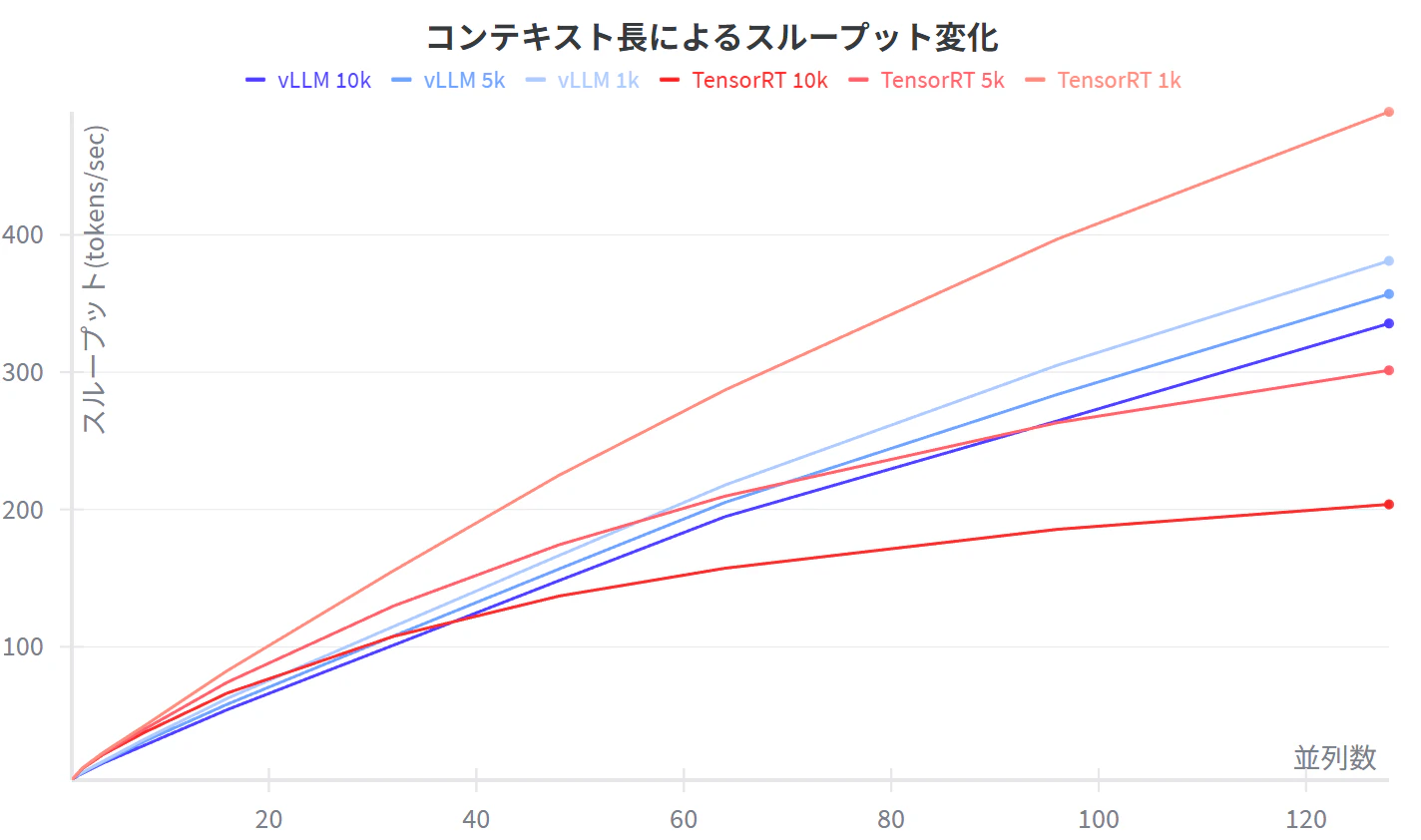
入力コンテキスト長によるスループット比較(tokens/sec)
| 並列数 | vLLM 10K | vLLM 5k | vLLM 1k | TensorRT 10k | TensorRT 5k | TensorRT 1k | |
|---|---|---|---|---|---|---|---|
| 1 | 3.5 | 3.6 | 4.1 | 2.9 | 3.1 | 3.3 | |
| 2 | 7.8 | 8.2 | 8.5 | 11.2 | 11.4 | 11.6 | |
| 4 | 15.3 | 16.0 | 16.6 | 21.5 | 22.2 | 22.9 | |
| 8 | 28.3 | 31.1 | 32.7 | 37.6 | 40.0 | 42.5 | |
| 16 | 54.3 | 58.2 | 62.4 | 66.3 | 74.2 | 82.7 | |
| 32 | 101.1 | 107.8 | 114.7 | 107.6 | 129.7 | 155.4 | |
| 48 | 148.3 | 156.7 | 166.6 | 137.0 | 174.4 | 225.1 | |
| 64 | 194.8 | 205.2 | 217.9 | 157.2 | 209.7 | 287.1 | |
| 96 | 264.5 | 283.7 | 305.0 | 185.5 | 263.2 | 396.8 | |
| 128 | 335.5 | 356.9 | 381.1 | 203.7 | 301.3 | 489.7 |
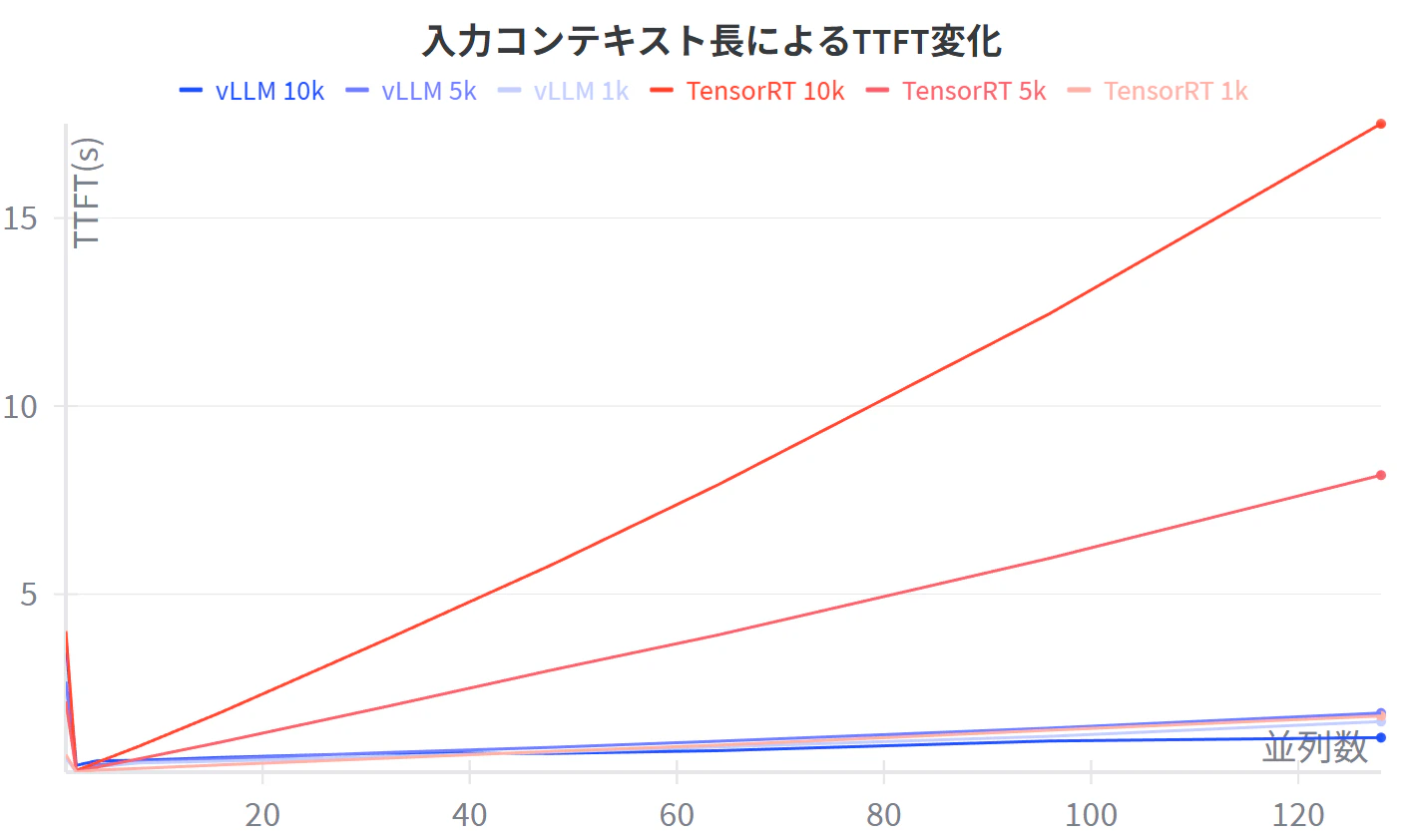
入力コンテキスト長によるTTFT比較(秒)
| 並列数 | vLLM 10k | vLLM 5k | vLLM 1k | TensorRT 10k | TensorRT 5k | TensorRT 1k | |
|---|---|---|---|---|---|---|---|
| 1 | 3.77 | 2.67 | 0.65 | 4.02 | 2.15 | 0.73 | |
| 2 | 0.45 | 0.30 | 0.27 | 0.31 | 0.29 | 0.27 | |
| 4 | 0.57 | 0.47 | 0.41 | 0.53 | 0.40 | 0.32 | |
| 8 | 0.58 | 0.55 | 0.51 | 0.95 | 0.62 | 0.37 | |
| 16 | 0.66 | 0.63 | 0.56 | 1.86 | 1.07 | 0.46 | |
| 32 | 0.78 | 0.79 | 0.69 | 3.80 | 2.02 | 0.64 | |
| 48 | 0.77 | 0.93 | 0.80 | 5.79 | 2.99 | 0.82 | |
| 64 | 0.84 | 1.09 | 0.94 | 7.91 | 3.92 | 0.99 | |
| 96 | 1.10 | 1.44 | 1.22 | 12.46 | 5.96 | 1.38 | |
| 128 | 1.19 | 1.84 | 1.61 | 17.51 | 8.16 | 1.76 |
実験結果から見える各エンジンの特徴
LM Studio
- 一人でチャットするだけなら最も早い
- 1リクエスト時でもTFTTは遅め。その分スループットが早い
- デフォルトの4を超えて並列して使うのはまだおすすめしない
(並列化できるようになったばかりなので今後に期待)
vLLM
- リクエストが1人でも128人でもバランスよく捌ける、スループットの安定さ
- コンテキスト長が大きくなってもスループット、TTFTが落ちにくい
- パラメータが変動しても動作する安定感を求める人向け
TensorRT-LLM
- 並列数1だけやたら遅い。なんなら無駄に2回送った方が早い
- 入力コンテキスト長が小さいときは早かったが大きくなるとTTFTが増えてスループットが落ちやすい
- 並列使用かつ小コンテキスト長に特化するならこれ
- GPUとの相性(新しめのNVIDIA製向け)もあるかもしれない
おわりに
今回128並列までを試していますが、グラフの傾き的にまだスループットが伸びるはず。すなわちこれでもまだ全力を出していない状態です。
並列特化エンジンはマルチユーザーを想定してのものかと思いますが、並列思考するAIと考えるとマルチエージェントをはじめいろんな用途が思いつきそうです。
「自分だけのAI」を欲してローカルLLMに手を出してがっかりした皆様、ぜひ「自分だけの数百人のAI」をお試しください。