初めての投稿になります。
お手柔らかにお願いします。
元データ
→https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia
※ 以下のラーニングは「教師あり学習」に相当します。
目的
自分自身の理解を深めるため 深層学習について良く知りたい、という人のため。参照先
Kaggle Notebook(旧Kernel)でディープラーニングを実装する。Kaggleの登録方法などは省略する。といってもアクセスすれば英語が読みさえすれば明快というか、登録ボタンなどを押せばいいだけなのだが。 さらにいえばJupitar Notebookと同じようなものです。Jupiter Notebookも知らない人向けにいえばPythonやRのコードを見栄えよく並べて簡単に実行できたりするオープンプラットフォーム(paiza.ioと似たもの)みたいなものです。アプリの説明
データセットは胸部のレントゲン写真です。そのデータから学習し、入力したデータ先の画像に対して平常の可能性(確率)と肺炎の可能性(確率)を棒グラフ化して可視化することがゴールです。そもそも深層学習とは何か/Introduction
人間の脳のシナプスやニューロンの働きを基に作られていると言われています。 シナプスを初めて通過した情報(電気信号)は通過するのに時間がかかりますがその時に刺激されて発生した電気信号はニューロンに貯蓄されます。そうして別の酷似した信号が来た時にシナプス(管)を通りやすくします。そうやって重複した情報の処理を速くすることで生き物の記憶、認識のシステムは稼働しています。この原理を利用します。まずレイヤー(層)について紹介します。
Introduction2:層
ハンバーガーをイメージしましょう。上と下の生地の一方を入力層、出力層とします。間の色々は中間層と呼びます。
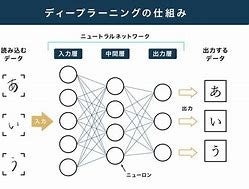
〇は中継地点で活性化関数から出力した数値にウエイトが掛けられバイアスが加算されます。
入力層の数と出力層の数はそろっている必要はありません。
こうした構造はニューロンネットワークと呼ばれます。
線は脳構造でいうシナプスで情報が伝っていくルートをさし、情報が伝っていくことを伝播(でんぱ)するといいます。
伝播の仕方として偏ることはありません。
Introduction3:活性化関数と損失関数
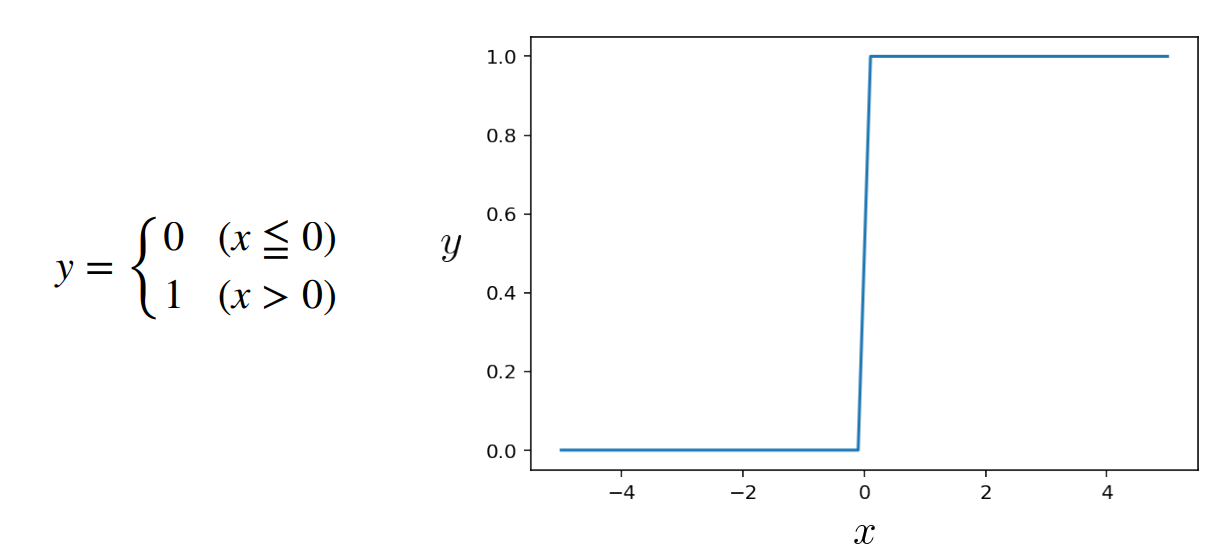
活性化関数:ニューロンの興奮/抑制状態を決める関数
例1 step関数
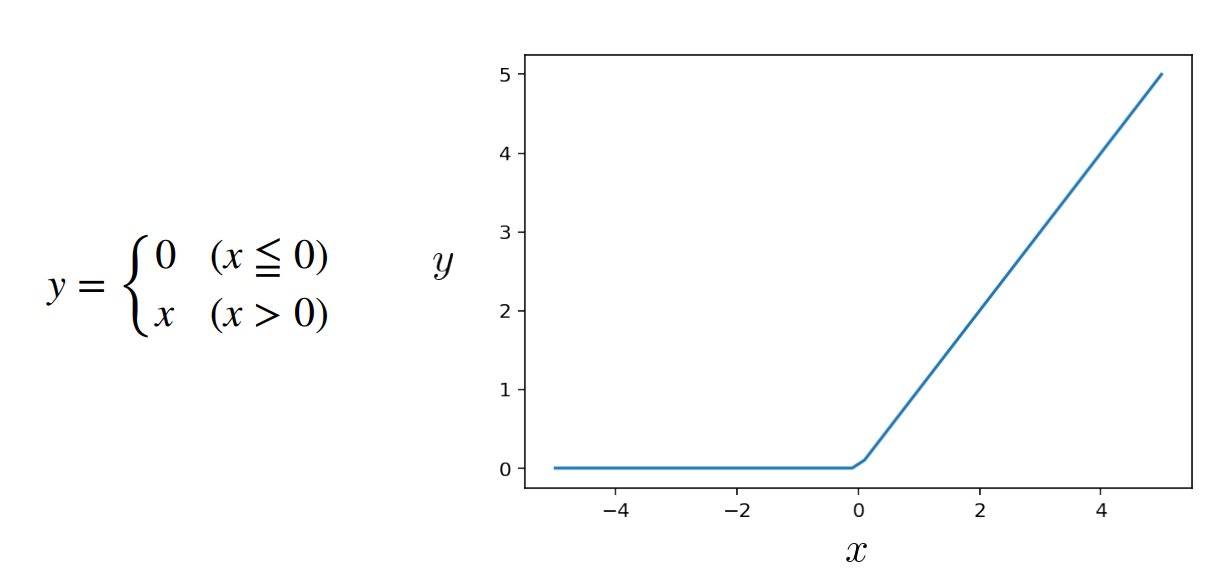
例2 ReLu関数
損失関数(Error、Loss):出力と正解の間の「誤差」を定義する関数
例 2乗和誤差関数
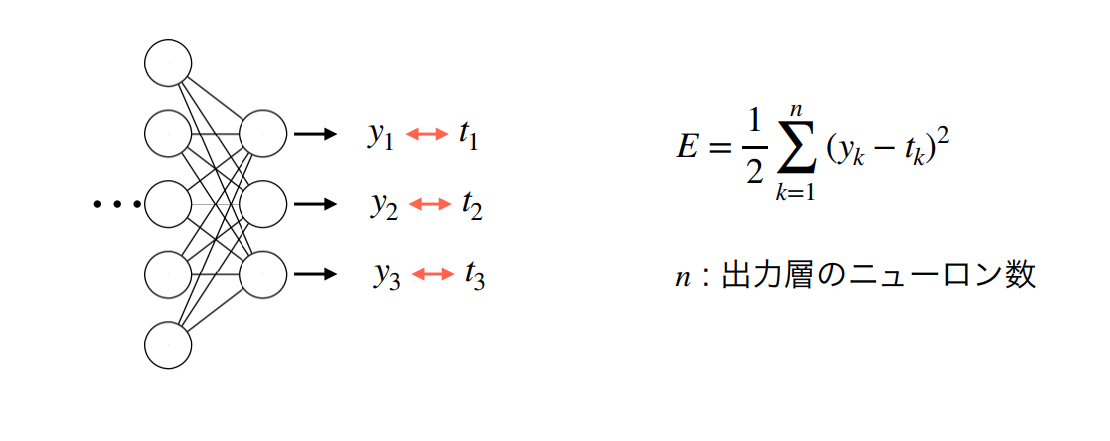
他 NNLoss, 交差エントロピー誤差関数、Adam関数
順伝播、逆伝播
上述のような伝播の仕方を順伝播といいます。一度出力した損失分からウエイト、重みを更新することを逆伝播といいます。経路を辿って後ろから関数を変換するわけですから逆伝播というわけです。その変換の仕方も1種類ではなく多種様々です。
最適化アルゴリズム
criterion(正規化)、optimizer(最適化)、scheduler(調節)の3つ
正規化とは値を0から1までに変換する。
最適化とはパラメータを調整し誤差を最小化しようとする
調節は最適化関数の中にある変数を変えていく。言い方を変えれば必要に応じて学習効率を変えていく、といっていい。(初学の段階では外してもよい)
最適化手法の例
確率的勾配降下法(SGD)

実際のコードに触れてみよう
インポート
import numpy as np
import pandas as pd
import torch
import os
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torch import nn,optim
from torchvision import transforms as T,datasets,models
from torchvision.utils import make_grid
from torch.utils.data import DataLoader
from collections import OrderedDict
from tqdm import tqdm
pd.options.plotting.backend = "plotly"
numpy, pandasは配列の計算をしやすくするPythonのライブラリ
matplotlibは画像を描画するライブラリでpyplotはそのメソッド
後の説明は省略するが transformsはTと略して用いることだけ強調しておく。
GPU
GPUとはディープラーニング、画像認識用のもっと早く計算できる演算装置のこと。
※デプロイする際にGPUだと不都合なこともある
def get_device(use_gpu):
if use_gpu and torch.cuda.is_available():
# これを有効にしないと、計算した勾配が毎回異なり、再現性が担保できない。
torch.backends.cudnn.deterministic = True
return torch.device("cuda")
else:
return torch.device("cpu")
# デバイスを選択する。
device = get_device(use_gpu=True)
ローディング
データはコンピュータ世界では全て数値で判断する。
特に画像データはRGB(色の3原色、Red, Green, Blue)を数値指定する(0 ~ 255, 255は2の8乗-1)
data_dir = "../input/chest-xray
pneumonia/chest_xray/chest_xray"
TEST = 'test'
TRAIN = 'train'
VAL ='val'
1行目はパス指定(Jupiter Notebookでのコード実行を想定)
それ以外はネーミング設定
def data_transforms(phase = None):
if phase == TRAIN:
data_T = T.Compose([
T.Resize(size = (256,256)),
T.RandomRotation(degrees = (-20,+20)),
T.CenterCrop(size=224),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])
])
elif phase == TEST or phase == VAL:
data_T = T.Compose([
T.Resize(size = (224,224)),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])
])
return data_T
trainset = datasets.ImageFolder(os.path.join(data_dir, TRAIN),transform = data_transforms(TRAIN))
testset = datasets.ImageFolder(os.path.join(data_dir, TEST),transform = data_transforms(TEST))
validset = datasets.ImageFolder(os.path.join(data_dir, VAL),transform = data_transforms(VAL))
class_names = trainset.classes
print(class_names)
print(trainset.class_to_idx)
冒頭の(from torchvision import transforms as T,datasets,models)からdatasetsメソッドを使い、「イメージとラベル」の「「組」」を出力するメソッド
T.Compose[...](transforms.Compose)はよく使われる。何をしているかといえば画像をコンピューターが変換できるように処理をする。
ここでデータ拡張をしている。後で解説する。
決まり文句に近いものでよく使われるので
前処理と称されることが多い。
大まかに言えば
訓練データかそうでないかで場合分け
各々
・サイズ設定(resize)
・切り抜き(crop)
・平均と分散(散らばりぐあい)で標準化
・テンソル化(pandas, numpyで画像データの数値配列操作をしやすくする、数学用語のテンソルと無理に結びつける必要はない)
再びネーミングづけ。validは検証を示す。
trainset = datasets.ImageFolder(os.path.join(data_dir, TRAIN),transform = data_transforms(TRAIN))
testset = datasets.ImageFolder(os.path.join(data_dir, TEST),transform = data_transforms(TEST))
validset = datasets.ImageFolder(os.path.join(data_dir, VAL),transform = data_transforms(VAL))
class_names = trainset.classes
print(class_names)
print(trainset.class_to_idx)
いったん話を元に戻す
訓練データ、検証データ、テストデータ
「訓練データ、検証データ」と「テストデータ」と捕らえていただきたい。
実用的に考えて実行ボタンをクリックするたびにゼロからスタートするのでは時間がかかりすぎる。またAIの仕組みは未知のデータに対し予め学習されたデータから推測を行うことである。
その学習用のデータを訓練データといい、テストデータはチェックをするデータである。今回は予め分けられている状態で扱うが、場合によっては7:3程度の割合で分けるところから実装を始めることもある。もちろん訓練データの方が多く、分け方はアトランダムである。
訓練データを元データをコピーするなどして元データ100%で学習させた場合、過学習といって「元データに適応しすぎたため、かえって応用しづらくなる」といわれる。
要はアニメの原理と同じで静止画を高速で見せられると動いてるように脳が錯覚するのと発想の根本は同じで人の認識とコンピュータ演算結果にギャップを利用する。アニメの作画が長時間ヌメヌメ動いてたら違和感がある。
テストデータはお膳立てが一通り終わった後に使用するスタンドアローンなものだが、検証データというのは学習効率の調整(schedular)を行うためのデータである。元データと大きく外れたものと是正するためのデータである
再びコードレビュー、データ拡張
データ拡張とは、学習不足を防ぐために簡単な操作でデータ量を増やすことである。
画像の回転、肉付けなどなど。長くなるのでここでは深く解説しない。
0はNormal, 1はPheumonia(肺炎を指す)
def plot_class_count(classes,name = None):
pd.DataFrame(classes,columns = [name]).groupby([classes]).size().plot(kind = 'bar',title = name).show()
def get_class_count(dataset,name = None):
classes = []
for _,label in dataset:
if label == 0:
classes.append(class_names[label])
elif label == 1:
classes.append(class_names[label])
return classes
trainset_class_count = get_class_count(trainset,name = 'trainset_classes_count')
plot_class_count(trainset_class_count,name = 'trainset_classes_count')
ラベリング。
※
size()はデータの型を出力する。
plot()はグラフ用にデータ化。
show()は実際に描画。
trainloader = DataLoader(trainset,batch_size = 16,shuffle = True)
validloader = DataLoader(validset,batch_size = 8,shuffle = True)
testloader = DataLoader(testset,batch_size = 8,shuffle = True)
Dataloaderは後述のバッチを作るメソッド。
shuffle= Trueで任意の順番でデータを取り出す(ロードする)
エポックとバッチ
バッチ(batch)
入力と正解のペア(ここではサンプルと呼ぶ)の集合
バッチごとに学習が行われる
「バッチサイズ」はバッチに含まれるサンプルの数
1エポック分の訓練データは、複数のバッチに分割される
エポック(epoch)
全ての訓練(学習)データを1回学習することを、1エポックと数える
1エポックで、訓練データを全て使い切る
バッチ学習とオンライン学習
バッチ学習
バッチサイズは訓練データの数に等しい
全ての訓練データを1度の学習で使い切る
欠点は学習が不正確になる。感覚的には途中まではサインカーブ(正弦曲線)の描画を学習しようとしたときに途中からパターンが違ったら対応できないよね...ってこと。
オンライン学習
バッチサイズは1で、1エポックの学習回数は訓練データの数に等しい
・欠点は逐一時間がかかる。感覚的にはfpsが低いのと同じ。
ミニバッチ学習
両者の良いとこどり。 訓練データを小さなサイズのバッチに分割し、バッチごとに学習する。
実際に描画
Dataloder:データセットからデータをバッチサイズ ごとにまとめて返す
def show_image(image,title = None,get_denormalize = False):
image = image.permute(1,2,0)
mean = torch.FloatTensor([0.485, 0.456, 0.406])
std = torch.FloatTensor([0.229, 0.224, 0.225])
image = image*std + mean
image = np.clip(image,0,1)
if get_denormalize == False:
plt.figure(figsize=[15, 15])
plt.imshow(image)
if title != None:
plt.title(title)
else :
return image
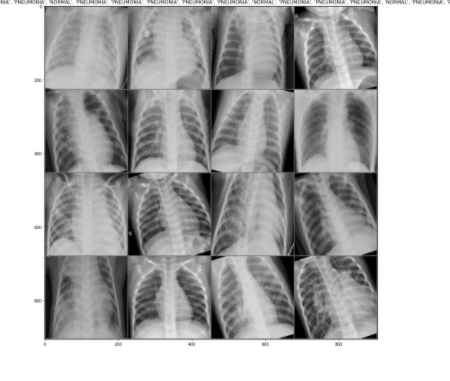
dataiter = iter(trainloader)
images,labels = dataiter.next()
out = make_grid(images,nrow=4)
show_image(out, title=[class_names[x] for x in labels])
iter(イテレータ)とはデータを取り出す道具のこと。meanは中心のこと。こうしておくと入力するデータ数値の扱いの見栄えが良くなる。
stdは偏差のこと。(偏差値 = 10 * STD + 50)
再びコードから離れる。CNNの説明
画像認識の実装部分としてscikitlearnを使って画像を学習するだとか、CNN、RNNだとか多様である。
まず画像の情報はいずれにせよRGBの情報を示す数値である。
ここではCNNの説明をする。
CNNは畳み込みニューラルネットワークという。
オーソドックスにいえば畳み込み→プーリング→全結合層(前と後ろで双方全てつながっている層)→出力
出力は各グループに分類される確率となる
畳み込みとプーリング
CNN = Covolutional Neural Network
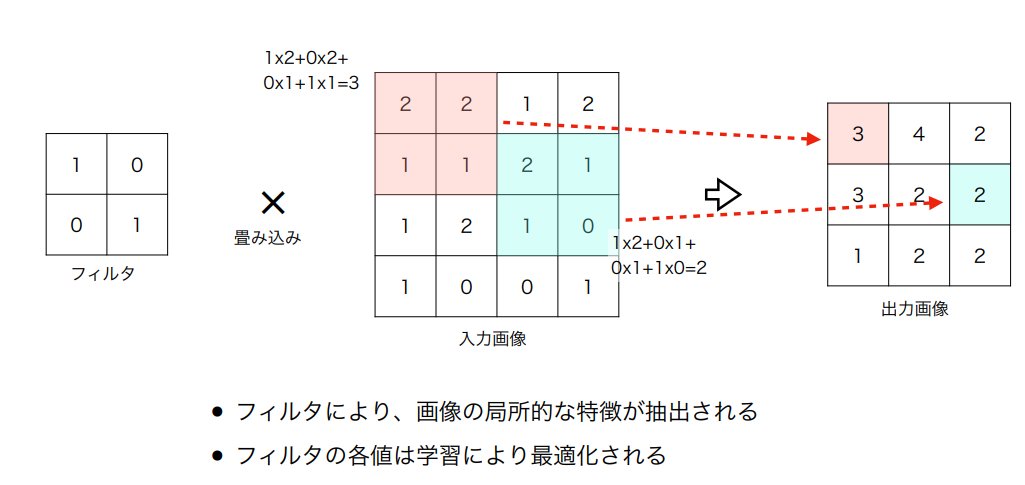
フィルタはコンピュータ用の虫眼鏡だと思えばいい。画像の中で拡大した領域上で大事な部分を抜き出す。
必然的に元の情報のピクセルは大きくなり「網目」は荒くなる。
vgg16
有名なCNNのモデルの一種。13層のCNN層と3層の全結合層からなる。
ファインチューニング
ファインチューニングとは、すでに学習されているモデル(重みが更新されている)を使用しつつ、必要に応じて、モデルに層を付け加えて学習を行うこと。処理が少なくて済むのが利点。下から2行目でフル結合層を付け加えますよ、の意。
model = models.vgg16()
for param in model.parameters():
param.requires_grad = False
classifier = nn.Sequential(OrderedDict([('fc1', nn.Linear(25088, 4096)),
('relu', nn.ReLU()),
('dropout',nn.Dropout(0.3)),
('fc2', nn.Linear(4096, 4096)),
('relu', nn.ReLU()),
('drop', nn.Dropout(0.3)),
('fc3', nn.Linear(4096, 2)),
('output', nn.LogSoftmax(dim = 1))]))
model.classifier = classifier
model.to(device)
※ドロップアウト
過学習を避けるためニューロンネットワークの途中であえてデータの取り捨てを行うこと。例えば3割の確率で情報を捨てる。確率なのだからエポックごとに同じ箇所でだけ消去されるというようなことはない。
※Linearの変数は例えば(4096, 2)であれば4096個のニューロンから2個のニューロンからなる層にデータが伝播しますよ。の意。
※classifierはclassifyの派生語、分類器などの訳語があてられる。
※nnはニューラルネットワークの略。冒頭のインポート参照。
※toはint型に変換しますよ...の意。(だったかな?)
お約束として最後にソフトマックス関数(活性化関数の一種)に入れて調節の仕上げをする。
他、プーリング
他、パディング(0で囲むこと)、プーリングなどあるが詳細は割愛する。
プーリング:画像の各領域を代表をする値(最大値など)を取り出して、出力画像にする
損失分を計算
Accuracyは正確さ
損失関数はライブラリの中のメソッドを使用。
.trainは訓練モード
.evalは評価モード、検証モード、といってもいい
topk関数
・確率の高い順位k番目まで出力する。今回は1番目のみ
エポックは15。predはpredictの意。予期する。
tqdmは白黒のバーを出力する。
深層学習における進捗状況や処理状況を表示させるときに便利で実行にかかるおおよその時間を知ることが出来る
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(),lr = 0.001)
schedular = optim.lr_scheduler.ReduceLROnPlateau(optimizer,factor = 0.1,patience = 5)
epochs = 30
valid_loss_min = np.Inf
def accuracy(y_pred,y_true):
y_pred = torch.exp(y_pred)
top_p,top_class = y_pred.topk(1,dim = 1)
equals = top_class == y_true.view(*top_class.shape)
return torch.mean(equals.type(torch.FloatTensor))
for i in range(epochs):
train_loss = 0.0
valid_loss = 0.0
train_acc = 0.0
valid_acc = 0.0
model.train()
for images,labels in tqdm(trainloader):
images = images.to(device)
labels = labels.to(device)
ps = model(images)
loss = criterion(ps,labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc += accuracy(ps,labels)
train_loss += loss.item()
avg_train_acc = train_acc / len(trainloader)
avg_train_loss = train_loss / len(trainloader)
model.eval()
with torch.no_grad():
for images,labels in tqdm(validloader):
images = images.to(device)
labels = labels.to(device)
ps = model(images)
loss = criterion(ps,labels)
valid_acc += accuracy(ps,labels)
valid_loss += loss.item()
avg_valid_acc = valid_acc / len(validloader)
avg_valid_loss = valid_loss / len(validloader)
schedular.step(avg_valid_loss)
if avg_valid_loss <= valid_loss_min:
print('Validation loss decreased ({:.6f} --> {:.6f}). Saving model ...'.format(valid_loss_min,avg_valid_loss))
torch.save({
'epoch' : i,
'model_state_dict' : model.state_dict(),
'optimizer_state_dict' : optimizer.state_dict(),
'valid_loss_min' : avg_valid_loss
},'Pneumonia_model.pt')
valid_loss_min = avg_valid_loss
print("Epoch : {} Train Loss : {:.6f} Train Acc : {:.6f}".format(i+1,avg_train_loss,avg_train_acc))
print("Epoch : {} Valid Loss : {:.6f} Valid Acc : {:.6f}".format(i+1,avg_valid_loss,avg_valid_acc))
復習:クラス名(ライブラリ名).~ はライブラリの中の~というメソッドを呼び起こす、という意味。
ここが深層学習の肝で、前半は
1エポックごとに1画像に対して
1.勾配をゼロ
2.逆伝播
3.ステップ関数(上記参照)
4. 正確度、損失度を足していく
をfor文の中で繰り返す、という意味。
for文を抜けた後で損失と正確度、各々の平均(長さで割る)を出力する。
※torch.no_gradはテンソルの勾配の計算を不可にする。メモリの消費を減らすことができる。
検証データでデータの是正をする。
検証データは後で解説するグラフ化ともあわせ訓練データによる学習モデルが正確かどうか判断する材料です。
訓練データと有効データのノイズのグラフが似た形に慣ればなるほど学習は上手くいっている、ということになります。
state_dict()は更新
損失のエポックごとの平均が段々0に近づいていく。
ハイパーパラメーターは自動更新されない「定数」の様なものである。重みは自動更新されるのでハイパーパラメーターではない。
上のコードで検証データで扱い始めたがif文以降は最小値
テストセット結果
真新しいデータで正確度をチェックする。
record_test_acc = []
record_test_loss = []
model.eval()
test_loss = 0
test_acc = 0
record_test_loss = []
for images,labels in testloader:
images = images.to(device)
labels = labels.to(device)
pred = model(images)
loss = criterion(pred,labels)
test_loss += loss.item()
test_acc += accuracy(pred,labels)
record_test_acc.append(test_acc)
record_test_loss.append(test_loss)
avg_test_loss = test_loss/len(testloader)
avg_test_acc = test_acc/len(testloader)
print("Test Loss : {:.6f} Test Acc : {:.6f}".format(avg_test_loss,avg_test_acc))
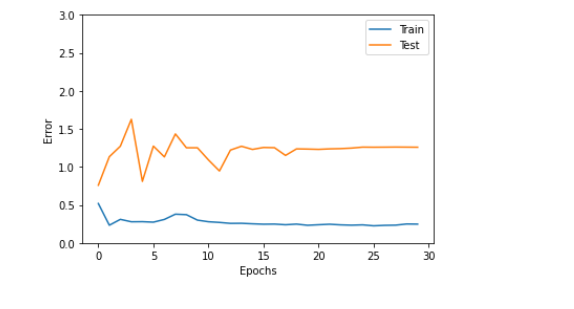
グラフ化
plt.plot(range(len(record_train_loss)), record_train_loss, label="Train")
plt.plot(range(len(record_valid_loss)), record_valid_loss, label="Test")
plt.legend()
plt.ylim(0,3.0)
plt.xlabel("Epochs")
plt.ylabel("Error")
plt.show()
L = len(record_train_acc)
plt.plot(range(len(record_train_acc)), record_train_acc, label="Train")
plt.plot(range(len(record_valid_acc)), record_valid_acc, label="Test")
plt.legend()
plt.ylim(0.5,1.1)
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.show()
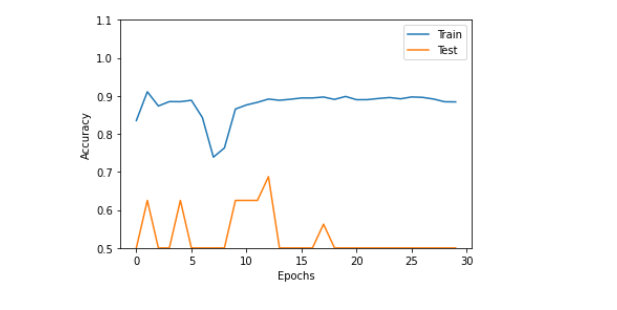
横軸はEpoch数です。
・・・・はい。察知の通り、これは上手くいっていない例です。
ハイパーパラメータ、バッチ数、学習率などを更新する必要があります。
下に最後の追記として正しいデータを入れる予定です。
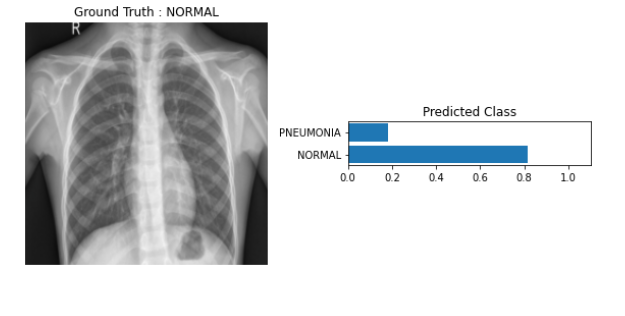
classifier(分類器)
def view_classify(img,ps,label):
class_name = ['NORMAL', 'PNEUMONIA']
classes = np.array(class_name)
ps = ps.cpu().data.numpy().squeeze()
img = show_image(img,get_denormalize = True)
fig, (ax1, ax2) = plt.subplots(figsize=(8,12), ncols=2)
ax1.imshow(img)
ax1.set_title('Ground Truth : {}'.format(class_name[label]))
ax1.axis('off')
ax2.barh(classes, ps)
ax2.set_aspect(0.1)
ax2.set_yticks(classes)
ax2.set_yticklabels(classes)
ax2.set_title('Predicted Class')
ax2.set_xlim(0, 1.1)
plt.tight_layout()
return None
ax =axel 軸、plt = plot
Example
image,label = testset[0]
ps = torch.exp(model(image.to(device).unsqueeze(0)))
view_classify(image,ps,label)
出力結果(学習に使っていない、テストデータを使っている)
終