関。関連。関連といえばレコメンドですね。
というわけで今回はレコメンドエンジンに利用できそうな技術を紹介します。
MF系アルゴリズムの動的スコア計算
リブセンスでは以前から機械学習を用いたレコメンドエンジンを開発・運用しています。
ユースケースによりけりですが、最近ではMatrix Factorization(MF)系のアルゴリズムの利用が盛んです。
Non-negative matrix factorization - Wikipedia
MFでは生成したユーザ・アイテムのベクトルの内積としてレコメンドのスコアを求めますが、ユーザやアイテムの数が多い場合、全てのユーザ×アイテムの組合せについてスコアを事前計算すると保持するデータサイズが非常に大きくなってしまいます。
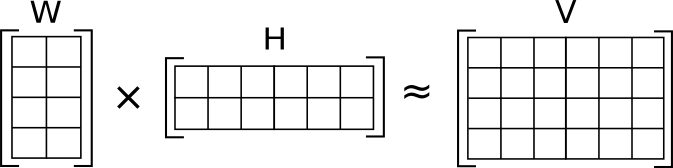
このような場合はユーザ・アイテムのベクトルを別個に保持し、入力に応じて動的にスコア計算とソートを行ってレコメンド結果を返す必要があります。
具体的には以下のような処理で計算を行います。
- 入力としてユーザのベクトル $\mathbf{w} \in W$ が与えられる
- 各アイテムのベクトル $\mathbf{h} \in H^t$ に対してスコア $s = \mathbf{w} \cdot \mathbf{h}$ を計算する
- 出力として $s$ が大きい順に上位 $n$ 件のアイテムを返す
ここには全アイテムに対する内積の計算と、その結果値によるソートという計算量の大きい処理が含まれます。
これをWeb APIのような低いレイテンシを求められるシステムで実現するのは簡単ではありません。
高速ベクトル計算ライブラリfaiss
Facebook Researchが開発している faiss は、このようなベクトル計算を高速に実行できるライブラリです。
faissを利用すれば予めメモリ上にベクトルの集合(行列)をインデックスしておき、入力として与えられたベクトルに対して瞬時にスコア計算・ソートを実行できます。
このようなライブラリは他にもありますが、faissは以下のような特徴をもっています。
- GPUサポートによる高速化
- Voronoi分割による時間計算量の削減
- 次元圧縮による空間計算量の削減
これらのおかげでfaissはベクトル数が数億〜十億程度のユースケースにも耐えられるスケーラビリティを持つようです(もちろんメモリは必要ですが)。
スコア計算方法としてはL2ノルムと内積に対応しているため、検索エンジンやレコメンド、特にword2vecやitem2vecなどの分散表現やLDAなどのトピックモデルを利用するケースで便利そうです。
faissそのものについては以下の記事で詳しく解説されているので、興味のある方は読まれることをお薦めします。
GPU対応の最近傍探索(類似検索)ライブラリ Faiss - Qiita
Pythonからfaissを利用して簡単なレコメンドAPIを作ってみる
faissにはSwigによるPythonインタフェースが付属しており、Pythonから簡単に利用することができます。
以下ではこれを利用してMovieLensデータセットを題材にごく単純なAPIを作ってみます。
MovieLensは小さなデータセットなのでfaissを使うのは明らかにオーバースペックですが、より大きなデータで利用する際の参考になるかと思います。
なお下記のコードはまとめて yubessy/example-faiss-recommender-api に置いています。
faissのビルド部分はDocker化してあるので、下記コマンドで簡単に試せるはずです。
$ git clone https://github.com/yubessy/faiss-recommender-api-example.git
$ cd faiss-recommender-api-example
$ docker build -t faiss-recommender-api-example . # 時間がかかるので注意
$ docker run -d -p 5000:5000 faiss-recommender-api-example
$ curl localhost:5000/user/1
NMFによる行列の因子分解
まずはユーザ・アイテムの特徴ベクトルを生成します。
以下ではMovieLensの評価データを sklearn.decomposition.NMF を使ってユーザ・映画の特徴ベクトルに分解しています。
import numpy
from scipy.sparse import coo_matrix
from sklearn.decomposition import NMF
# MovieLens の ratings.csv のロード
#
# userId, movieId, rating, timestamp
# 1, 31, 2.5, 1260759144
# 1, 1029, 3.0, 1260759179
# :, :, :, :
# 2, 10, 4.0, 835355493
# :, :, :, :
#
ratings = numpy.loadtxt(
'ratings.csv',
delimiter=',',
skiprows=1,
usecols=(0, 1, 2),
dtype=[('userId', 'i8'), ('movieId', 'i8'), ('rating', 'f8')],
)
users = sorted(numpy.unique(ratings['userId']))
movies = sorted(numpy.unique(ratings['movieId']))
# オリジナルのID <-> 行列のi,jに使うの変換用のdict
# あとでAPIを作るときに使う
user_id2i = {id: i for i, id in enumerate(users)}
movie_id2i = {id: i for i, id in enumerate(movies)}
movie_i2id = {i: id for i, id in enumerate(movies)}
# NMFの入力として使えるよう評価データを疎行列形式に変換
rating_mat = coo_matrix(
(ratings['rating'], (map(user_id2i.get, ratings['userId']),
map(movie_id2i.get, ratings['movieId'])))
)
# NMFによる行列分解でユーザ・映画の特徴ベクトルを生成
# 特にパラメータ調整はしていない
model = NMF(n_components=10, init='random', random_state=0)
user_mat = model.fit_transform(rating_mat)
movie_mat = model.components_.T
faissによるベクトルのインデキシング
NMFにより生成したユーザ・アイテムの特徴ベクトルのインデックスを作成します。
NMFの場合は内積によってスコアを算出するため IndexFlatIP を利用する必要があります。
import faiss
# インデックスの作成
# 引数はベクトルの次元数
# 今回はexampleのためシンプルな内積計算を利用
# 最適化が必要な場合は IndexIVFFlast や IndexIDF100 を用いる
movie_index = faiss.IndexFlatIP(10)
# インデックスにベクトルを追加
movie_index.add(movie_mat.astype('float32'))
Web APIの作成
ここまでで作ったインデックスを利用して、結果をJSONで返すAPIを作成します。
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/user/<int:user_id>')
def users(user_id):
# ユーザIDを行列の列番号に変換し、ユーザの特徴ベクトルを取得
user_i = user_id2i[user_id]
user_vec = user_mat[user_i].astype('float32')
# ユーザの特徴ベクトルとインデックスされたアイテムの特徴ベクトルの内積を計算し、スコア上位の結果を取得
# index.search は特徴ベクトルを複数与えるような使い方に対応しているため、入出力が行列になる
scores, indices = movie_index.search(numpy.array([user_vec]), 10)
# 結果を整形してJSONで返す
movie_scores = zip(indices[0], scores[0])
return jsonify(
movies=[
{
"id": int(movie_i2id[i]),
"score": float(s),
}
for i, s in movie_scores
],
)
app.run(host="0.0.0.0", port=5000)
アプリケーションの起動
APIを起動します。最初にNMFによる行列分解を行うので多少の時間がかかります。
$ python main.py
以下のようにAPIを叩いてユーザへのおすすめ映画のIDとスコア返ってくれば成功です。
$ curl localhost:5000/users/1 | jq .
{
"movies": [
{
"id": 123,
"score": 2.34567
},
{
"id": 123,
"score": 2.34567
},
...
]
}
さいごに
この記事ではfaissを使って動的にスコアを算出するレコメンドAPIを作る方法を簡単に紹介しました。
今回は時間がなかったので割愛しましたが、faissの真価は前述の最適化による高速化で発揮されるため、機会があればベンチマークも取ってみたいと思います。