AWSのS3にあるJsonファイルを読んで、GCPのBigQueryへ出力するサンプルを書いてみました。
つまり、AWSの世界からDataflowを使ってGCPの世界へデータ変換をしつつ転送するやり方です。
まだまだ情報が出回っていないapacheBeamですので、世のため人のため自分のために、頑張って書いてみたいと思います。
なお、本記事の対象環境は「Java8版のBeam2.6.0」です。
ビルドツールはmavenを利用しています。
beam2.3.0からS3のサポートが開始
今年2018年2月にbeam2.3.0がリリースされ、そのバージョンからS3の入出力がサポートされました。
それ以前でも、カスタムソースやカスタムシンクと呼ばれる、いわば「ユーザ実装の仕組み」によりユーザの責任でS3の入出力処理を個別実装すれば対応可能ではありました。
しかし2018年現在は、ユーザ実装不要でS3の入出力が可能となっています。
本記事は、beam2.3.0以降のバージョンの書き方のご紹介になります。1
dataflowでS3を読み込むモチベーション
昨今、マルチクラウドなどと呼ばれる、複数ベンダのパブリッククラウドを組み合わせて利用する会社さんが増えてきたようです。
背景に、パブリッククラウドベンダにより得手不得手により「AクラウドのX製品とBクラウドのY製品を使いたい」というニーズが発生するケースが増えた、というのがあるのだと思われます。
例えば、以下のような状況です。
| GCP | ○ | BigQueryが圧倒的。メンテナンスが楽で、安い、速い。クエリも書きやすい。 |
| × | GCP全体的にアクセスコントロールが弱く、日本人が大好きな接続元IP制御もほとんどできない。2 | |
| AWS | ○ | アクセスコントロールだけでなく、パブリッククラウドとして色々なニーズがカバーできる。 |
| × | 割高。Reshiftは運用がちょっと面倒。Athenaもちょっと使いにくい? |
このような状況から、
- データレイクにはS3を利用して、データは全てS3に集める。
- しかしデータ分析はGCPを中心に置いた方がコストも安いし、便利なツールが多い。
というように、両者を相互利用することでバランスを取りたい、などの欲求が出てきたりします。
(正しい判断かどうかは置いておくとして)
しかしながら、以上のような背景があったとしても
S3からGCPへコピーするだけならDataflowは少し大げさですし、面倒です。
S3からGCSへコピーするだけならgsutilやStorageTransferServiceなどが使え、それらを利用すれば簡単です。
では、DataflowでS3からBigQueryへデータ転送すると何が嬉しいのか。
私が考えたのは、AWSのLambdaからDataflowをキックして、サーバレスのファンクションとサーバレスの並列分散バッチを組み合わせることで、VMを使わず面倒なネットワーク設計も回避して「イベント駆動で時間無制限なデータ転送、ついでにデータ変換もやる」を成し遂げたい。
こんなモチベーションでDataflowによるS3→BiqQueryを検証してみました。
※クラウド間のネットワーク転送はストレージサービスによる保管費用と比べ大分高いので、リトライが多く発生する場合には素直にGCSにデータコピー後にGCSからBigQueryへ取り込んだ方が良いという判断もあるかと思います。この点に注意です。
LambdaからDataflowをキックする記事もそのうち暇を見つけて書こうかと思います。
beamでS3を読み込む際のつまずきポイント
恐らくApacheBeamのライブラリ体系を熟知されている人は躓かないのかもしれませんが、私は見事に躓きました。
私は初め、S3を読み込むための専用のIOクラスが用意されているのかと何も疑わず思い込んでいました。
つまり、BigQueryIOのようにS3IO的なものがあるはずだと。
ところがどっこい、実際はGCSから読み込むときと同じTextIOを使うだけでOKということのようでした。
これに気づくのにたぶん、ググってググって30分くらいかかりました。(…とまぁ時間自体は大してかかってませんが、心の動揺はそれなりに大きかったような)
なので実際は、パイプラインの実装としては普通にPipeline.create()してから、
TextIOでReadするだけ。
ここだけみると、まるで普通にGCSからデータを読んでいるように書くこととなります。
パイプライン箇所だけコードを抜粋すると以下のような感じになります。
Pipeline p = Pipeline.create(options);
p
.apply("ReadLines", TextIO.read().from(options.getInputFile())) // ←普通にGCSから読んでるようにしか見えないがこれでGCSでもS3でも読めちゃう!
.apply(ParDo.of(new DoFn<String, TableRow>() {
// :
// (StringからTableRowへの変換処理書いて)
// :
}))
.apply("WriteBigQuery",
BigQueryIO.writeTableRows()
.to("test02." + options.getTableName())
.withSchema(tableSchema)
.withCreateDisposition(BigQueryIO.Write.CreateDisposition.CREATE_IF_NEEDED)
.withWriteDisposition(BigQueryIO.Write.WriteDisposition.WRITE_TRUNCATE)
);
p.run();
AWSクレデンシャルは?
次に、S3から読み込ますのにAWSクレデンシャルはどうするのか?という疑問があるかと思います。
が、そこは普通に専用のoptionsが用意されていて、そいつにクレデンシャル情報をセットすれば良いということとなります。
AwsOptionsというOptionsを利用すればOK。
OptionsのsetAwsCredentialsProviderメソッドでクレデンシャルを指定する。
他にリージョンやエンドポイントなど、AWSお得意のいつもの情報達(?)を入れ、TextIOに指定するパスを「S3://xxx」とすればS3から読むし、「gs://xxx」とすればGCSから読む、とあとは良しなにうまいことやってくれるという寸法、となります。
以上、だいぶ簡単ですね!!
ここまでである程度Beamをやっている方なら大体できるかと思いますが、以下もう少し詳しく説明します。
実装手順
何かしらのDataflow(またはBeam)のソースを準備
まず母体となるDataflowまたはBeamのソースを準備します。
Beamの公式チュートリアルである「WordCount」であれば、以下のページにあります。
https://beam.apache.org/get-started/quickstart-java/
pomファイルにS3用のライブラリを追加
まず、通常のGCP向けのBeamライブラリには当然S3のTextIOができません。
そのため、S3のTextIOができるようにするためのライブラリを追加する必要があります。
MavenリポジトリでBeamとかAwsとかで検索すると、以下がヒットしました。
<!-- https://mvnrepository.com/artifact/org.apache.beam/beam-sdks-java-io-amazon-web-services -->
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-io-amazon-web-services</artifactId>
<version>2.6.0</version>
</dependency>
これをpom.xmlに追加してパイプラインを実行すると以下のエラーがでました。
Connected to the target VM, address: '127.0.0.1:38783', transport: 'socket'
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/http/conn/socket/ConnectionSocketFactory
at com.amazonaws.http.apache.client.impl.ApacheHttpClientFactory.<init>(ApacheHttpClientFactory.java:41)
at com.amazonaws.http.AmazonHttpClient.<clinit>(AmazonHttpClient.java:149)
at com.amazonaws.AmazonWebServiceClient.<init>(AmazonWebServiceClient.java:175)
at com.amazonaws.services.s3.AmazonS3Client.<init>(AmazonS3Client.java:644)
at com.amazonaws.services.s3.AmazonS3Builder$1.apply(AmazonS3Builder.java:35)
at com.amazonaws.services.s3.AmazonS3Builder$1.apply(AmazonS3Builder.java:32)
at com.amazonaws.services.s3.AmazonS3ClientBuilder.build(AmazonS3ClientBuilder.java:64)
at com.amazonaws.services.s3.AmazonS3ClientBuilder.build(AmazonS3ClientBuilder.java:28)
at com.amazonaws.client.builder.AwsSyncClientBuilder.build(AwsSyncClientBuilder.java:46)
at org.apache.beam.sdk.io.aws.s3.S3FileSystem.buildAmazonS3Client(S3FileSystem.java:128)
at org.apache.beam.sdk.io.aws.s3.S3FileSystem.<init>(S3FileSystem.java:108)
at org.apache.beam.sdk.io.aws.s3.S3FileSystemRegistrar.fromOptions(S3FileSystemRegistrar.java:39)
at org.apache.beam.sdk.io.FileSystems.verifySchemesAreUnique(FileSystems.java:492)
at org.apache.beam.sdk.io.FileSystems.setDefaultPipelineOptions(FileSystems.java:482)
at org.apache.beam.sdk.PipelineRunner.fromOptions(PipelineRunner.java:47)
at org.apache.beam.sdk.Pipeline.create(Pipeline.java:145)
at org.apache.beam.examples.WordCount.runWordCount(WordCount.java:155)
at org.apache.beam.examples.WordCount.main(WordCount.java:252)
Caused by: java.lang.ClassNotFoundException: org.apache.http.conn.socket.ConnectionSocketFactory
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 18 more
Disconnected from the target VM, address: '127.0.0.1:38783', transport: 'socket'
Process finished with exit code 1
つまり、ConnectionSocketFactoryなるクラスが見つからないと。
裏で使われているのでしょうか。
Mavenリポジトリで検索すると以下がヒットしたので、そちらもPOMのdependencyに追加します。
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.6</version>
</dependency>
追加が必要なDependencyは上記2つでOKでした。
追加したら、当たり前ですがライブラリをインポートし直してください。
options定義の修正
前述のとおり、オプションに、AwsOptionsを利用します。
通常はPipelineOptionsをextendsしてoptionsを定義するかと思います。
これをAwsOptionsをextendsするようにすれば、Options定義としては最低要件を満たします。
getter/setter定義はアプリケーションの作り次第で好き勝手にやれば良いと思いますが、
例えば以下のように実装します。
(beamチュートリアルのWordCountを無理矢理S3->BigQueryに変えたので、クラス名などに名残りがあったりするのはご愛嬌、ということで)
public interface WordCountOptions extends AwsOptions {
@Description("ここに入力データのS3のパスを入れる。JSONLやCSVなどTextIOで処理可能な形式で")
@Default.String("s3://s3-to-bq-sample/data/*")
String getInputFile();
void setInputFile(String value);
@Description("ここに出力先のBigQueryテーブル名を指定")
@Required
String getTableName();
void setTableName(String value);
}
AWSクレデンシャルをoptionsに指定する
定義したoptionsのsetAwsCredentialsProvider()メソッドでクレデンシャルを指定します。
※この例では、環境変数「accesskey」「secretkey」からクレデンシャルを取得するようにしています。
皆さんも、クレデンシャルをPublicなGithubなどに上げないように気をつけましょう。
public static void main(String[] args) {
WordCountOptions options =
PipelineOptionsFactory.fromArgs(args).withValidation().as(WordCountOptions.class);
options.setAwsCredentialsProvider(new AWSStaticCredentialsProvider(new BasicAWSCredentials(System.getenv("accesskey"), System.getenv("secretkey"))));
// optionsの準備ができたので、パイプライン実行をする
runWordCount(options);
}
ちなみに以前、DataflowテンプレートのValueProviderを使って、AWSクレデンシャルを動的指定3できないか、
を模索したのですが、結局できなそう、という結論に達しました。
→もし、「できた!」という方がいらっしゃいましたら、情報をお待ちしております。今度そんな記事も書いてみようかな。。
TextIOを使ってパイプライン処理を実装
S3をTextIOで読み取る準備はできましたので、あとはパイプラインを書いてあげればOKです。上にもサンプル載せましたが、ここにも書いておきます。
ちなみにざっくり仕様としては、
- 入力:「col1, col2, col3, col4」の計4フィールドを持ったJSONL形式を想定
- 出力:そのままのフィールドでBigQueryテーブルへ出力
となっております。
static void runWordCount(WordCountOptions options) {
Pipeline p = Pipeline.create(options);
// BigQueryのテーブルスキーマ定義
TableFieldSchema [] fields = {
new TableFieldSchema().setName("col1").setType("STRING"),
new TableFieldSchema().setName("col2").setType("INTEGER"),
new TableFieldSchema().setName("col3").setType("INTEGER"),
new TableFieldSchema().setName("col4").setType("INTEGER")
};
TableSchema tableSchema = new TableSchema().setFields(Arrays.asList(fields));
// パイプライン定義
p
// はじめにTextIOにより、S3やGCSからJSONL形式のファイルを読み取る
.apply("ReadLines", TextIO.read().from(options.getInputFile()))
// JSONからBigQueryのテーブル形式へデータ変換する
.apply(ParDo.of(new DoFn<String, TableRow>() {
@ProcessElement
public void processElement(@Element String element, OutputReceiver<TableRow> receiver) {
JSONObject elementJson = new JSONObject(element);
String [] columns = {"col1", "col2", "col3", "col4"};
TableRow tableRow = new TableRow();
Arrays.stream(columns).forEach(column -> {
switch(column) {
case "col1":
try{
String valStr = elementJson.getString(column);
tableRow.put(column, valStr);
}catch(Exception e) {
// 手抜きすまぬ
}
break;
default:
try{
int valInt = elementJson.getInt(column);
tableRow.put(column, valInt);
}catch(Exception e) {
// 手抜きすまぬ
}
}
});
receiver.output(tableRow);
}
}))
// BigQueryへの出力(test02というデータセットに出力しているので、適宜環境に合わせる必要があります。その他パラメータも然り)
.apply("WriteBigQuery",
BigQueryIO.writeTableRows()
.to("test02." + options.getTableName())
.withSchema(tableSchema)
.withCreateDisposition(BigQueryIO.Write.CreateDisposition.CREATE_IF_NEEDED)
.withWriteDisposition(BigQueryIO.Write.WriteDisposition.WRITE_TRUNCATE)
);
// パイプライン実行(非同期実行)
p.run();
// p.run().waitUntilFinish(); // 同期実行したい場合
}
S3ファイルとBigQueryデータセットを準備して実行
あとは、S3にファイルを配置して、BigQueryへあらかじめ出力先のデータセットを作っておき、
実行するだけです。
ただし、awsOptions独自の必須パラメータがあり、「--awsRegion」を指定する必要があるようです。
指定しないと以下のエラーがでました。
Connected to the target VM, address: '127.0.0.1:46806', transport: 'socket'
Disconnected from the target VM, address: '127.0.0.1:46806', transport: 'socket'
Exception in thread "main" java.lang.IllegalArgumentException: Missing required value for [--awsRegion, "AWS region used by the AWS client"].
at org.apache.beam.repackaged.beam_sdks_java_core.com.google.common.base.Preconditions.checkArgument(Preconditions.java:383)
at org.apache.beam.sdk.options.PipelineOptionsValidator.validate(PipelineOptionsValidator.java:90)
at org.apache.beam.sdk.options.PipelineOptionsValidator.validateCli(PipelineOptionsValidator.java:62)
at org.apache.beam.sdk.options.PipelineOptionsFactory$Builder.as(PipelineOptionsFactory.java:313)
at org.apache.beam.examples.WordCount.main(WordCount.java:250)
Process finished with exit code 1
とうわけで、起動オプションに例えば「--awsRegion=us-east-2」などを指定します。(S3のデータを置いたリージョンを指定する)
すると、以下のようなパイプラインが実行され、晴れてBigQueryへテーブルが出力されます。
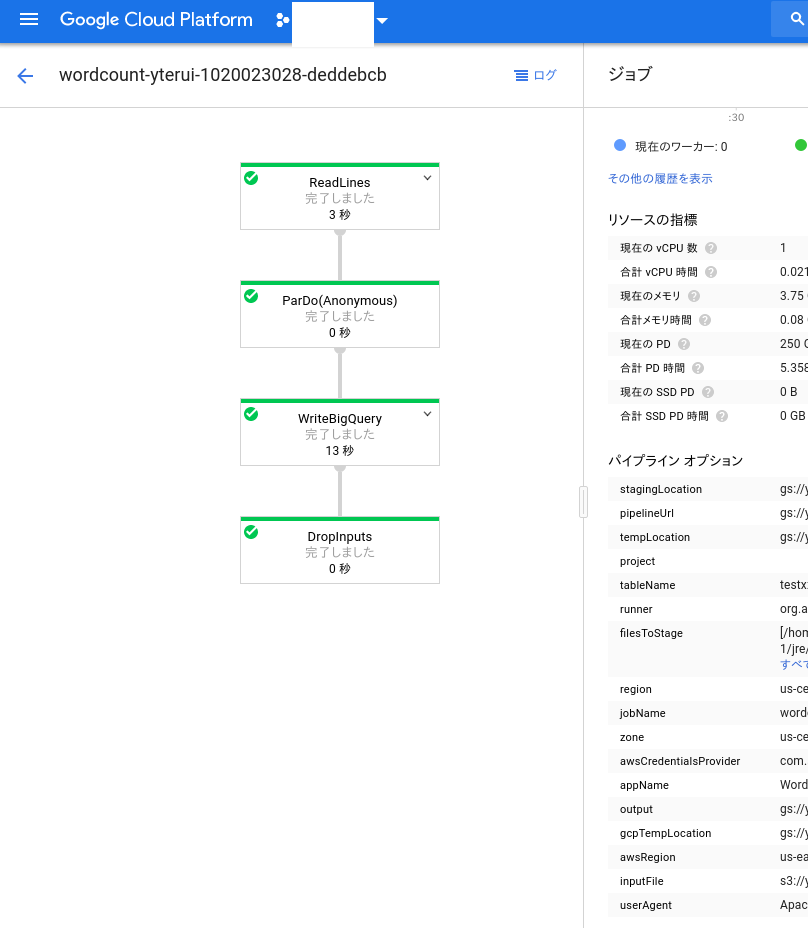
おわりに
以上、Dataflow(apache beam)からS3のデータを読み込む手順をご紹介いたしました。
並列分散処理というとapache sparkなどを真っ先にイメージされると思いますが、GCPではDataflowが非常に便利です。
実装方法に少々癖がありますが、安く手軽に並列処理が実装でき、かつフルマネージドなサービスですので、使い勝手が非常に良いと思います。
今後も、AWSとGCPをデータが行き来するようなシステム構成をとる会社さんが出てくるかと思いますが、本記事のような構成も参考にして頂けると非常に嬉しいです。
そして、Dataflowがもっと流行ると更に嬉しいです。