はじめに
昨今、特定のクラウドベンダーやデータウェアハウス製品への「ベンダーロックイン」を回避し、データレイクをオープンに管理できる「Apache Iceberg」を採用するケースが急速に増えています。
しかし、いざIcebergを導入しようとすると、「複雑なコーディング」や「高度なパイプライン設計」といった実装の壁にぶつかり、導入スピードが停滞してしまうケースも少なくありません。
そこで本記事では、Informatica IDMCが提供する CDIR (Cloud Data Ingestion and Replication) を活用した解決策をご紹介します。CDIRを使えば、専門的なスクリプト作成は一切不要。数千テーブル規模の大量データであっても、わずか数分の設定だけでSnowflake管理のIcebergテーブルへと自動ロードする環境が整います。
「ロックインのない次世代データ基盤を最短ルートで構築したい」――
そんなニーズに応える、CDIRの実力と具体的な実装手順を詳しく解説していきます。
概要
Apache Icebergとは
Apache Icebergは、巨大なデータセットに対してデータウェアハウスのような高性能な操作を実現するために設計された、オープンなテーブルフォーマットです。
従来のデータレイク(単なるファイルの集まり)と比較して、以下の強力な特徴を持っています。
- スキーマ進化:テーブルを再作成することなく、列の追加や名前変更が可能
- パーティション進化:物理的なフォルダ構成を気にせず、クエリ最適化のためのパーティションを柔軟に変更
- タイムトラベル:スナップショット管理により、過去の特定時点のデータを参照可能
- 高い相互運用性:Snowflakeだけでなく、Databricksや Amazon Athenaなど、複数のエンジンから同一のデータを直接参照できるため、ベンダーロックインを回避できます
IDMC CDIRとは
CDIR(Cloud Data Ingestion and Replication)は、InformaticaがIDMC(Intelligent Data Management Cloud)上で提供する、大量データロードのためのサービスです。
大規模かつ低レイテンシなデータの移動を、数ステップのウィザード形式で簡単に実現します。
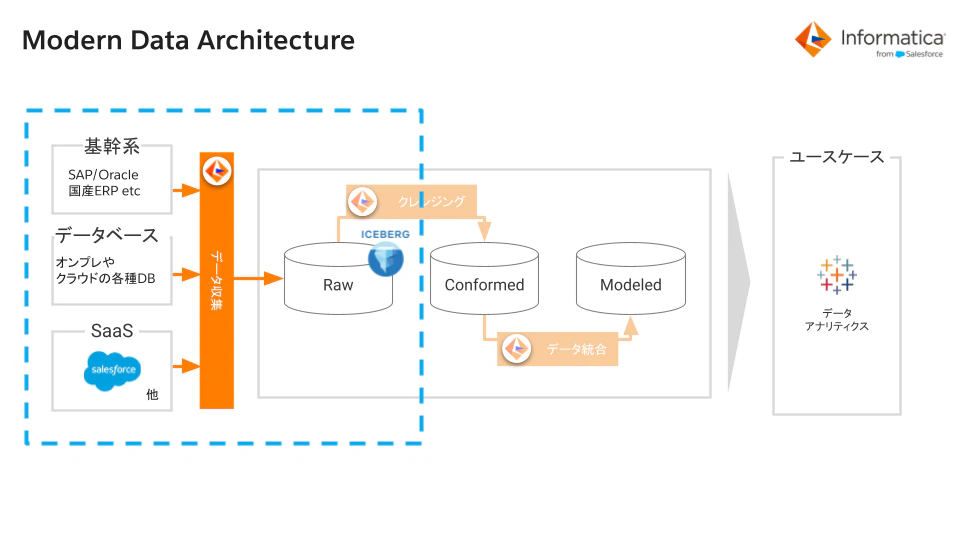
DEMOの構成
今回の記事では、Snowflake管理のIcebergをCDIRのターゲットとして指定します。
CDIRを使うことで、組織内の大量な業務データを効率的にIcebergテーブル化できることを確認していきます。
事前準備
SnowflakeとGoogle Cloudの接続
Snowflake管理のIcebergテーブルを利用するには、実際のデータを保存するための外部ストレージが必要です。
今回はGoogle Cloud Storage (GCS)をストレージとして採用し、Snowflakeがアクセスできるように「外部ボリューム(External Volume)」を設定します。
- Google Cloud側:Iceberg用バケットを作成し、Snowflakeへのアクセス権限を付与
- Snowflake側:バケットの情報を定義した「外部ボリューム」オブジェクトを作成
外部ストレージは、Snowflakeアカウントが存在するクラウドサービスおよびリージョンと一致している必要があります。
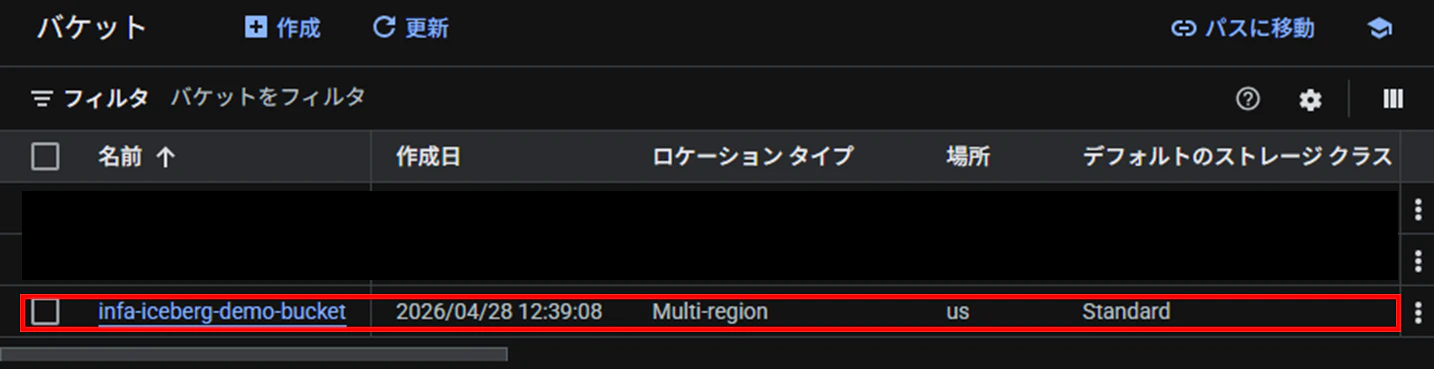
バケット作成(Google Cloud)
Google CloudのCloud StorageにIceberg用のバケットを作成します。
外部ボリュームの作成(Snowflake)
作成したバケットを指定して、Snowflake上に外部ボリュームを作成します。
CREATE EXTERNAL VOLUME <External_Volume_Name>
STORAGE_LOCATIONS =
(
(
NAME = '<Storage_Location_Name>'
STORAGE_PROVIDER = 'GCS'
STORAGE_BASE_URL = '<Storage_Base_URL>'
)
);
サービスアカウント情報の取得(Snowflake)
サービスアカウント情報を取得します。
DESC EXTERNAL VOLUME <External_Volume_Name>;
property_valueの出力から「STORAGE_GCP_SERVICE_ACCOUNT」の値を記録します。
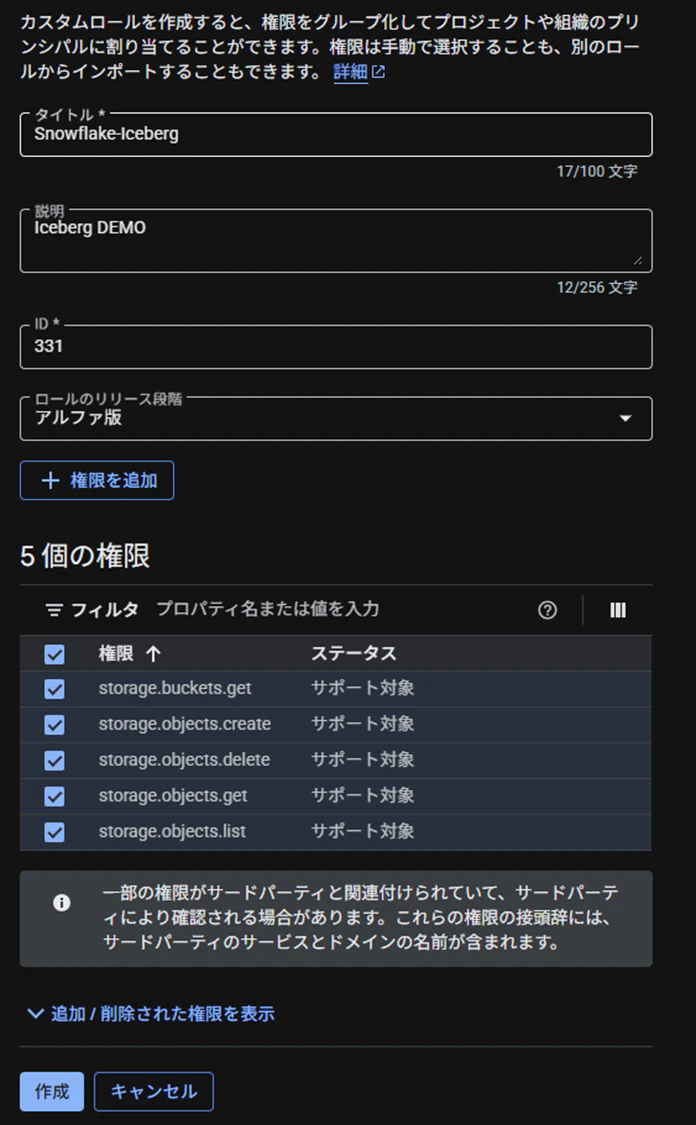
IAMロールの作成(Google Cloud)
Cloud Storage権限を有するIAMロールを作成します。
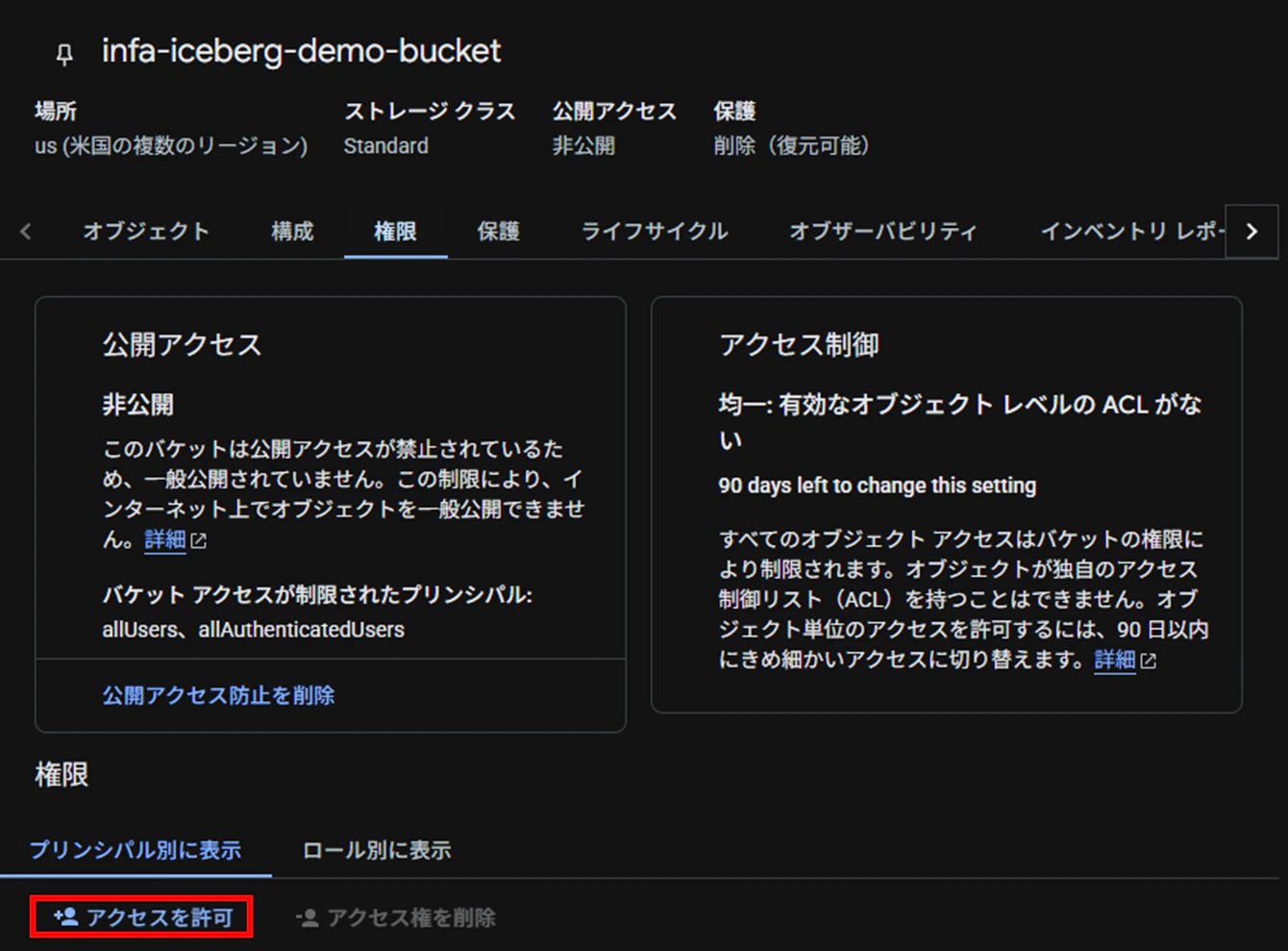
サービスアカウント権限の付与(Google Cloud)
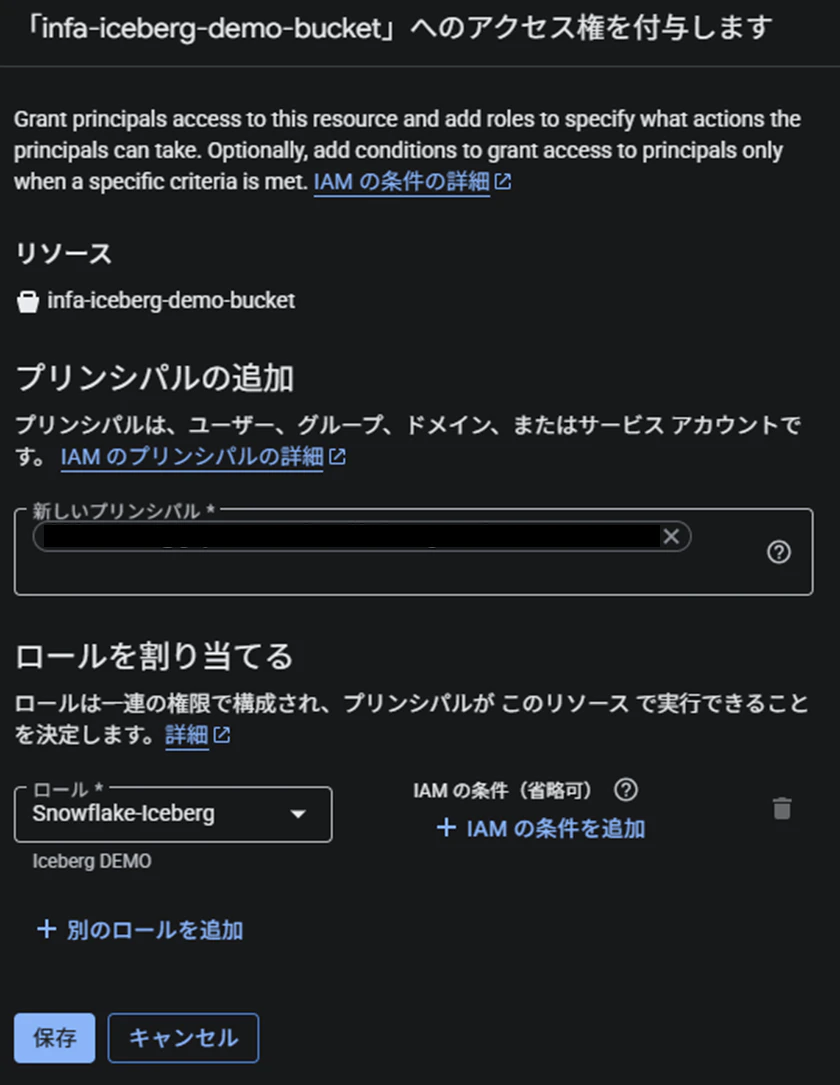
Iceberg用バケットの権限を開き、「アクセスの許可」を選択します。
先ほど記録した「STORAGE_GCP_SERVICE_ACCOUNT」の値を、新しいプリンシパルに追加します。
先ほど作成したIAMロールを割り当てます。
ストレージへのアクセステスト
以下のSQLを実行し、ストレージへのアクセスが可能なことを確認します。
SELECT SYSTEM$VERIFY_EXTERNAL_VOLUME('<External_Volume_Name>');
「"success":true」となっていればokです。
IDMC接続用設定(Snowflake)
以下の手順を参考に、IDMC接続用の設定をします。
-- 1. ロールの作成
CREATE ROLE <Role>;
-- 2. ユーザーの作成
CREATE USER <User_Name> PASSWORD = '<Password>';
-- 3. ロールをユーザーに付与
GRANT ROLE <Role> TO USER <User_Name>;
-- 4. デフォルトロールの設定
ALTER USER <User_Name> SET DEFAULT_ROLE = <Role>;
-- 5. RSA公開鍵の設定
ALTER USER <User_Name> SET RSA_PUBLIC_KEY = '<Public_key>';
-- 6. データベースの作成
CREATE DATABASE <Database_Name>;
-- 7. スキーマの作成
CREATE SCHEMA <Database_Name>.<Schema_Name>;
-- 8. ウェアハウスの使用権限を付与
GRANT USAGE ON WAREHOUSE <Warehouse_Name> TO ROLE <Role>;
-- 9. データベースの使用権限を付与
GRANT USAGE ON DATABASE <Database_Name> TO ROLE <Role>;
-- 10. スキーマの使用権限を付与
GRANT USAGE ON SCHEMA <Database_Name>.<Schema_Name> TO ROLE <Role>;
-- 11. スキーマ内のオブジェクト作成権限を付与
GRANT CREATE STREAM, CREATE VIEW, CREATE TABLE, CREATE ICEBERG TABLE
ON SCHEMA <Database_Name>.<Schema_Name>
TO ROLE <Role>;
-- 12. 今後作成されるすべてのテーブルへのSELECT/INSERT/DELETE権限を付与
GRANT SELECT, INSERT, DELETE
ON FUTURE TABLES IN SCHEMA <Database_Name>.<Schema_Name>
TO ROLE <Role>;
-- 13. 外部ボリュームの使用権限を付与
GRANT USAGE ON EXTERNAL VOLUME <External_Volume_Name> TO ROLE <Role>;
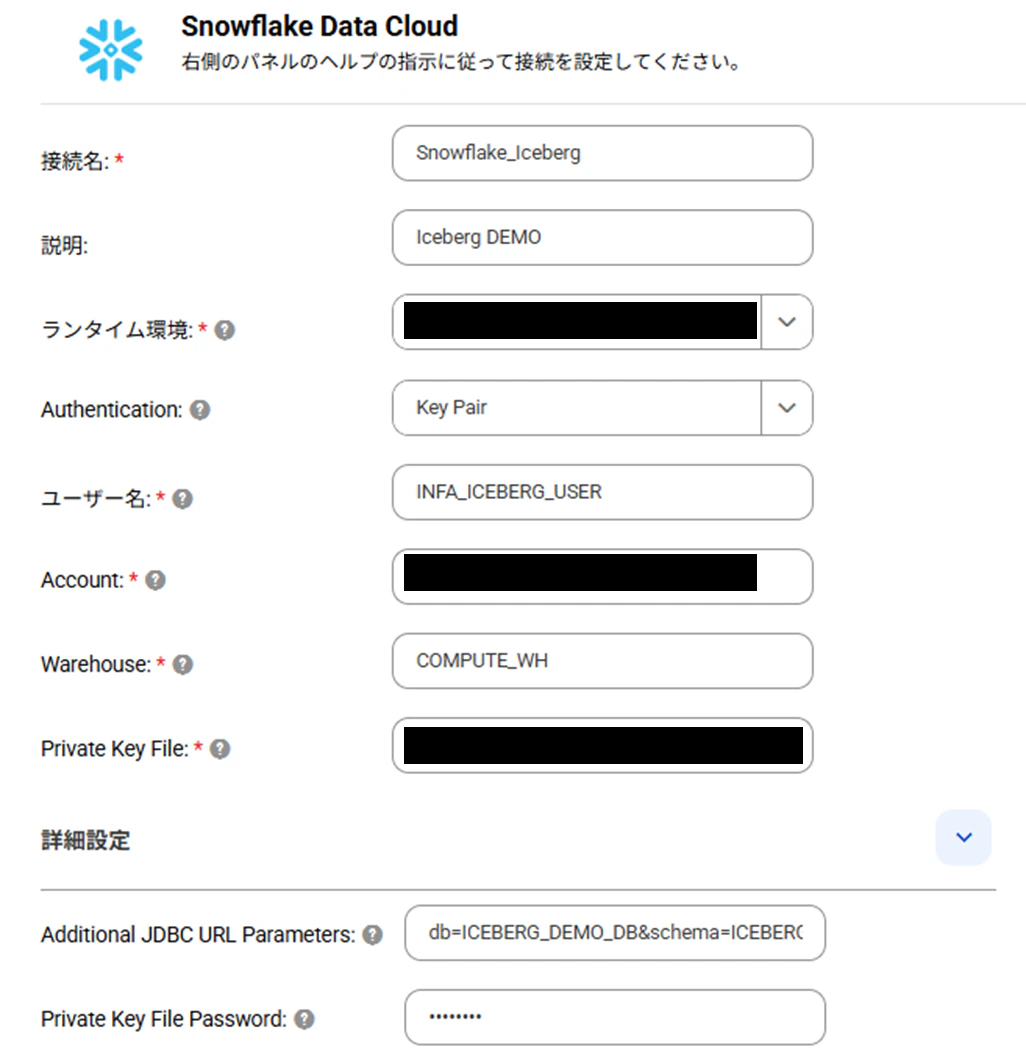
接続定義作成(IDMC)
IDMCにログインし、Snowflake用の接続定義を作成します。
実装
データベース取り込みタスク作成
CDIR-Databaseで、PostgreSQLからSnowflakeへのデータベース取り込みタスクを作成します。
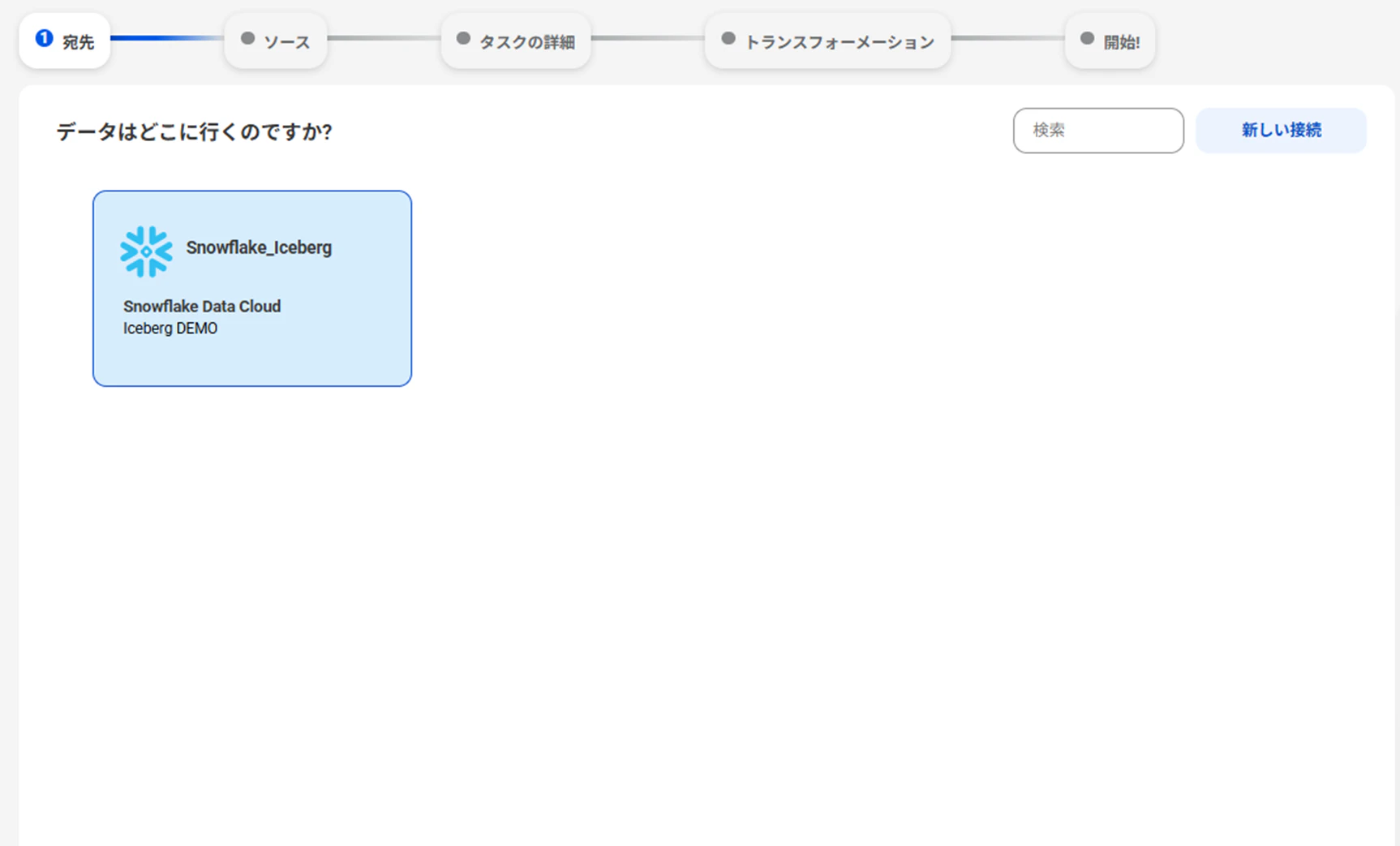
宛先
Snowflakeをターゲットに指定します。
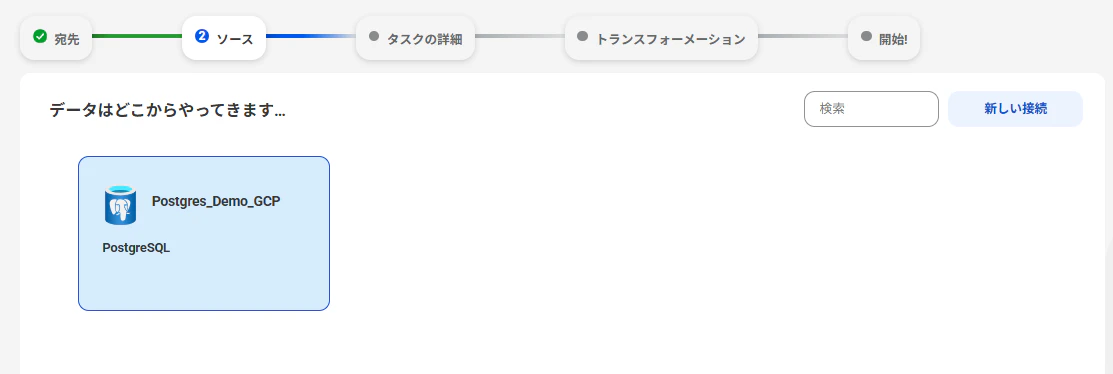
ソース
今回はPostgreSQLをソースに指定しています。
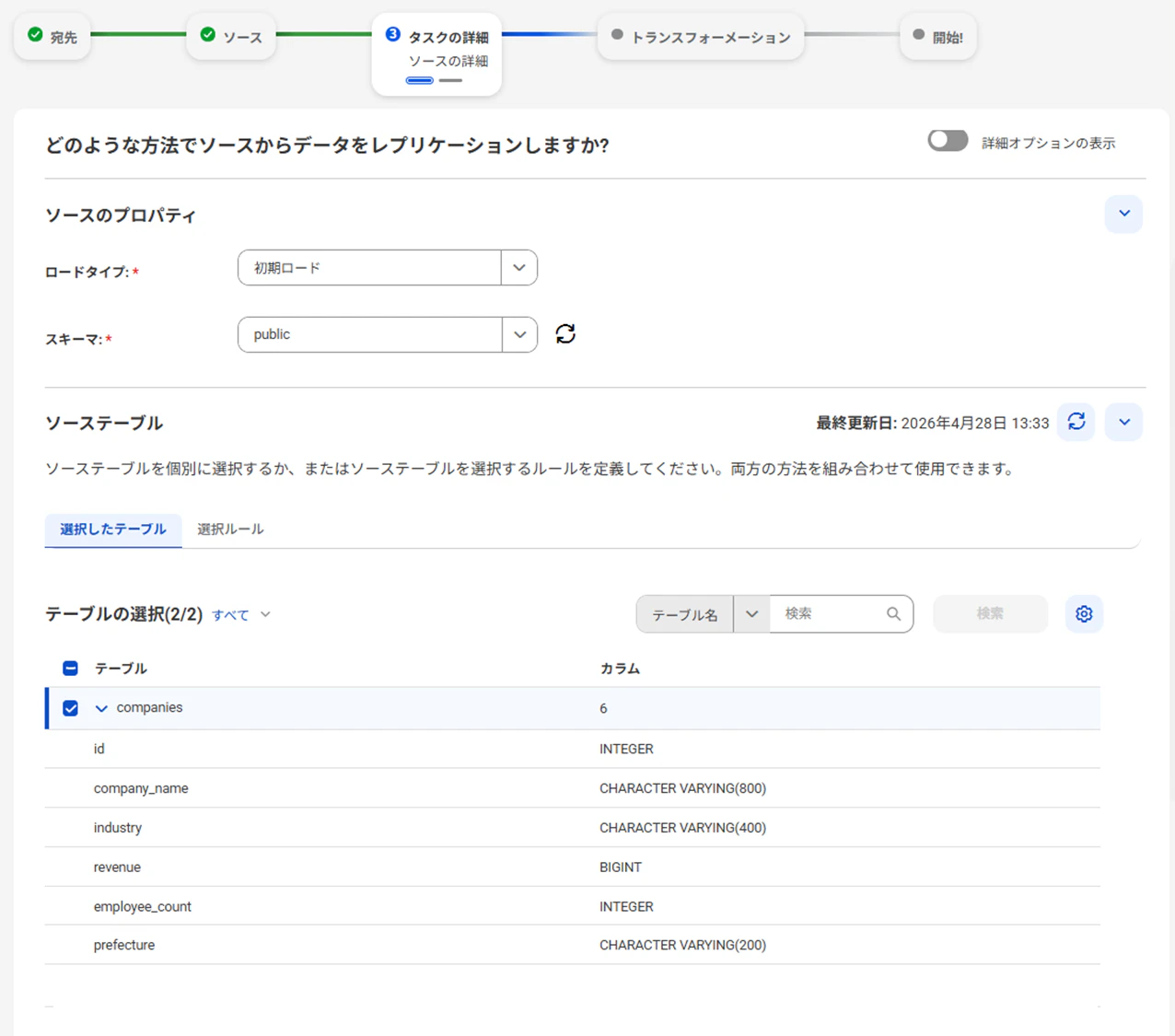
タスクの詳細(ソースの詳細)
連携対象のテーブルを選択します。
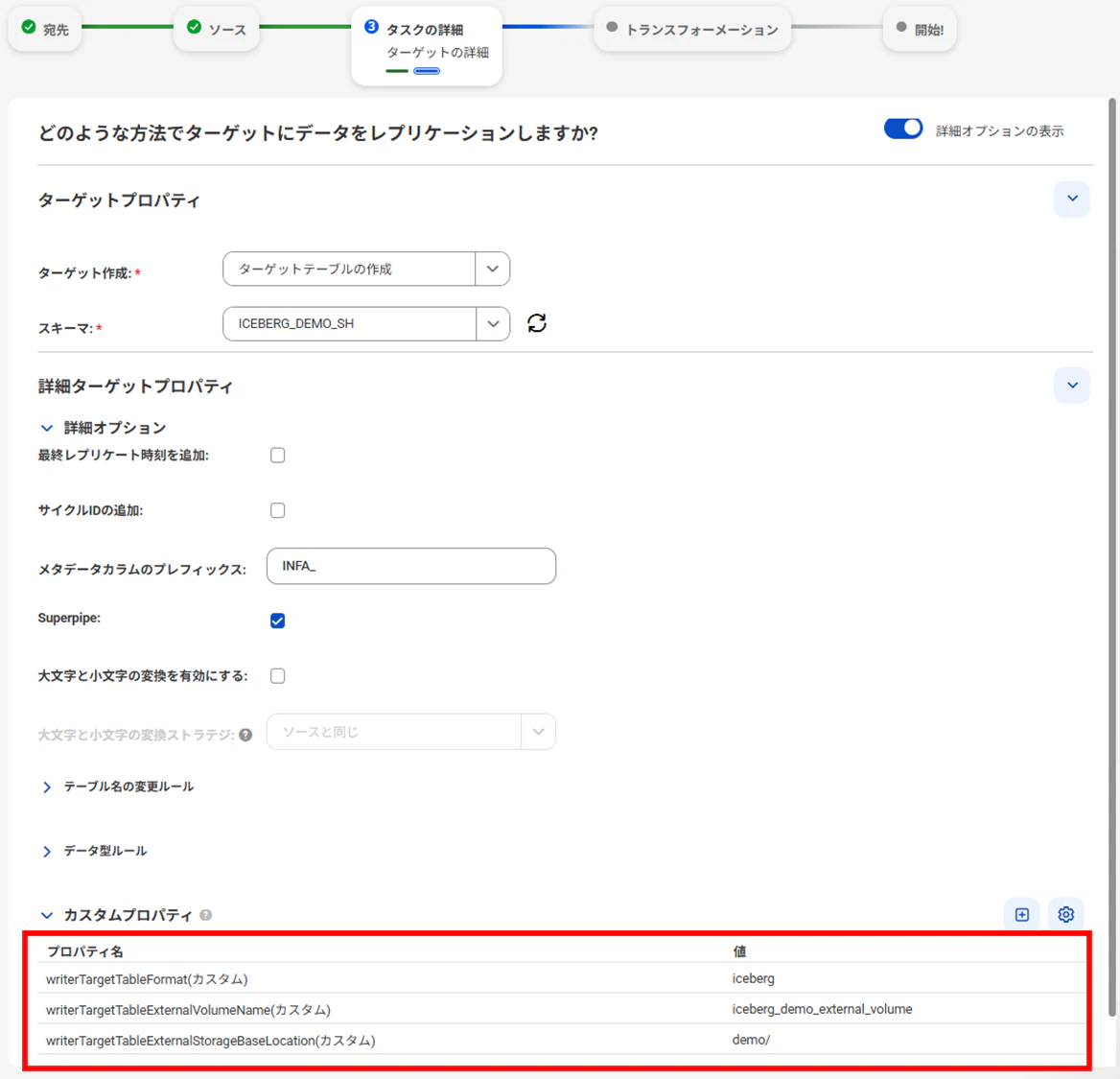
タスクの詳細(ターゲットの詳細)
今回、最も重要な設定です。
Icebergテーブルとしてロードするため、3つのカスタムプロパティを設定します。
| プロパティ名 | 設定内容の説明 | 設定値 |
|---|---|---|
writerTargetTableFormat |
ターゲットテーブルのフォーマットをIcebergに指定します。 | iceberg |
writerTargetTableExternalVolumeName |
Snowflake上で定義した「外部ボリューム」の名前を指定します。 | (作成した外部ボリューム名) |
writerTargetTableExternalStorageBaseLocation |
外部ストレージ(GCS等)内の保存先ディレクトリを指定します。 | (任意のパス/フォルダ名) |
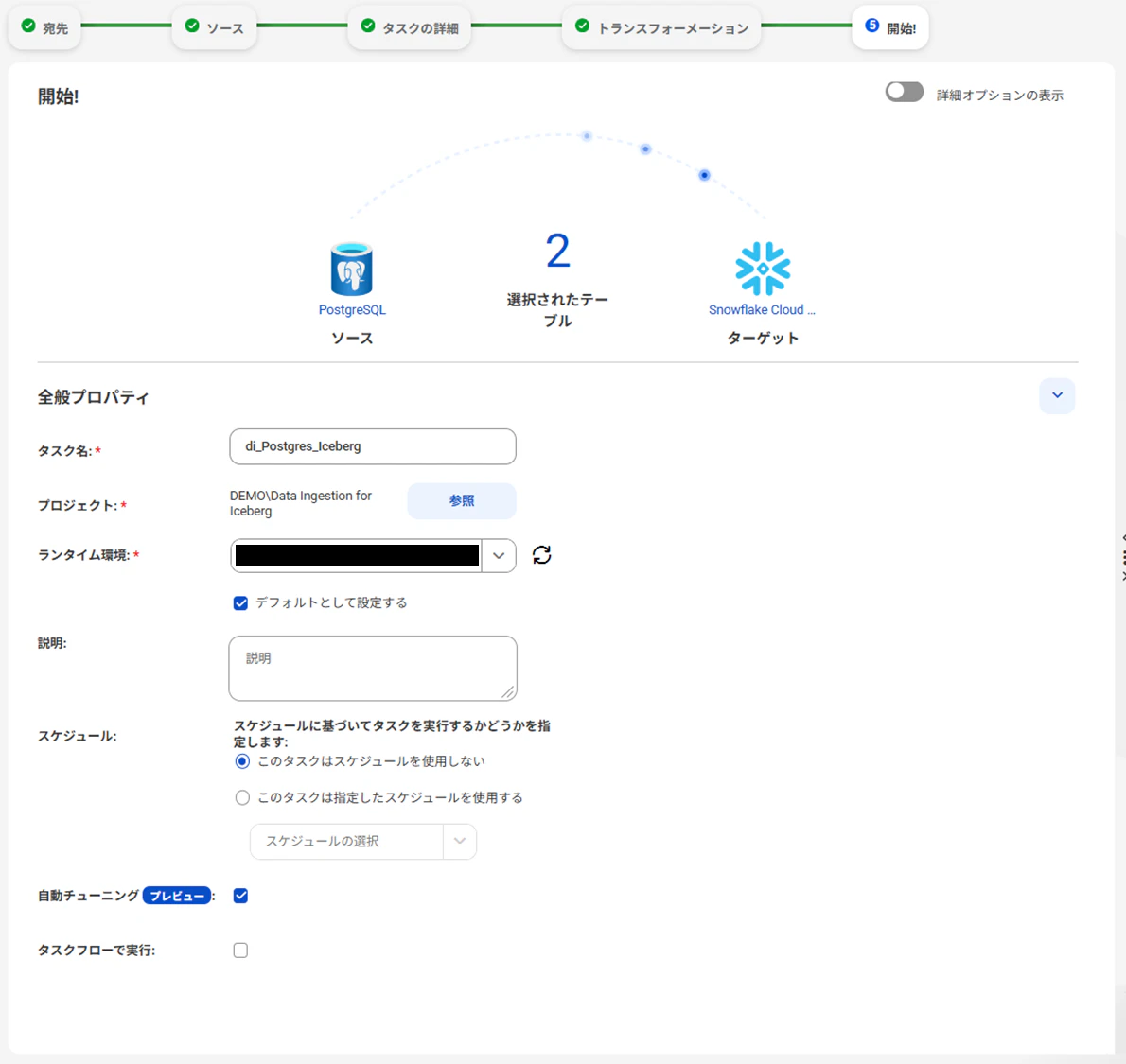
開始設定
タスク名やプロジェクトを設定し、保存します。
DEMO
では、実際に起動してみましょう。
デプロイ
データベース取り込みタスクを「デプロイ」します。
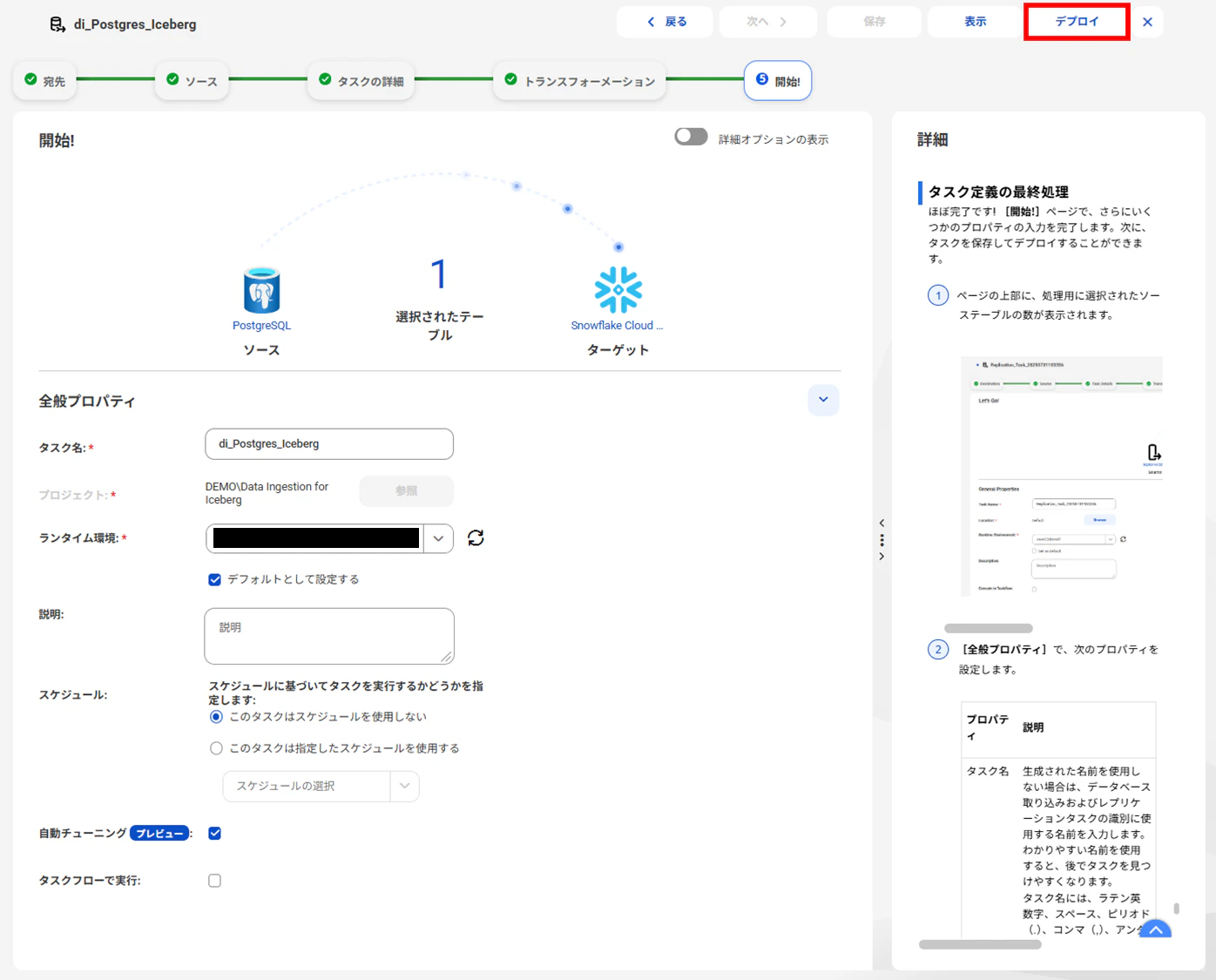
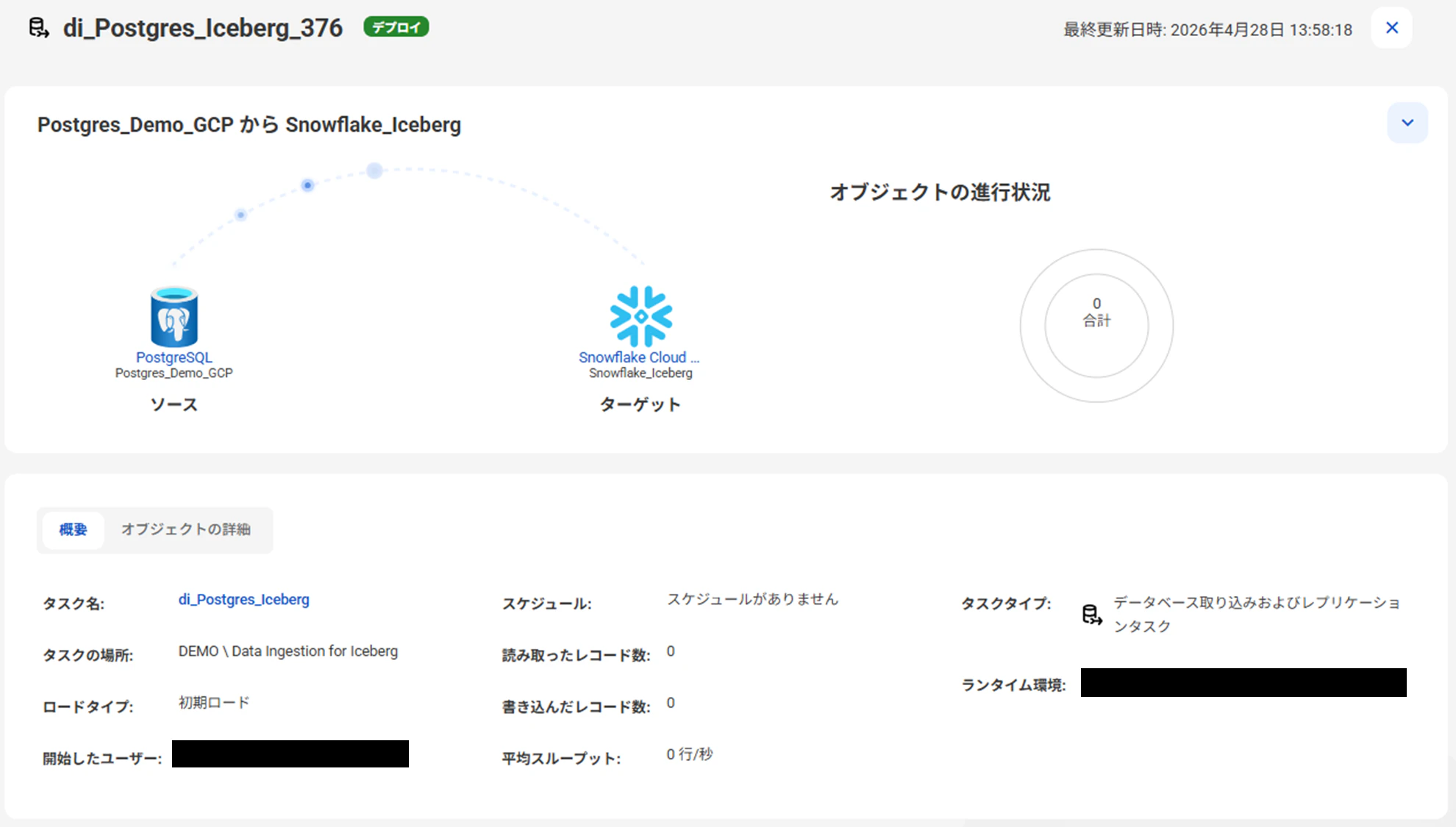
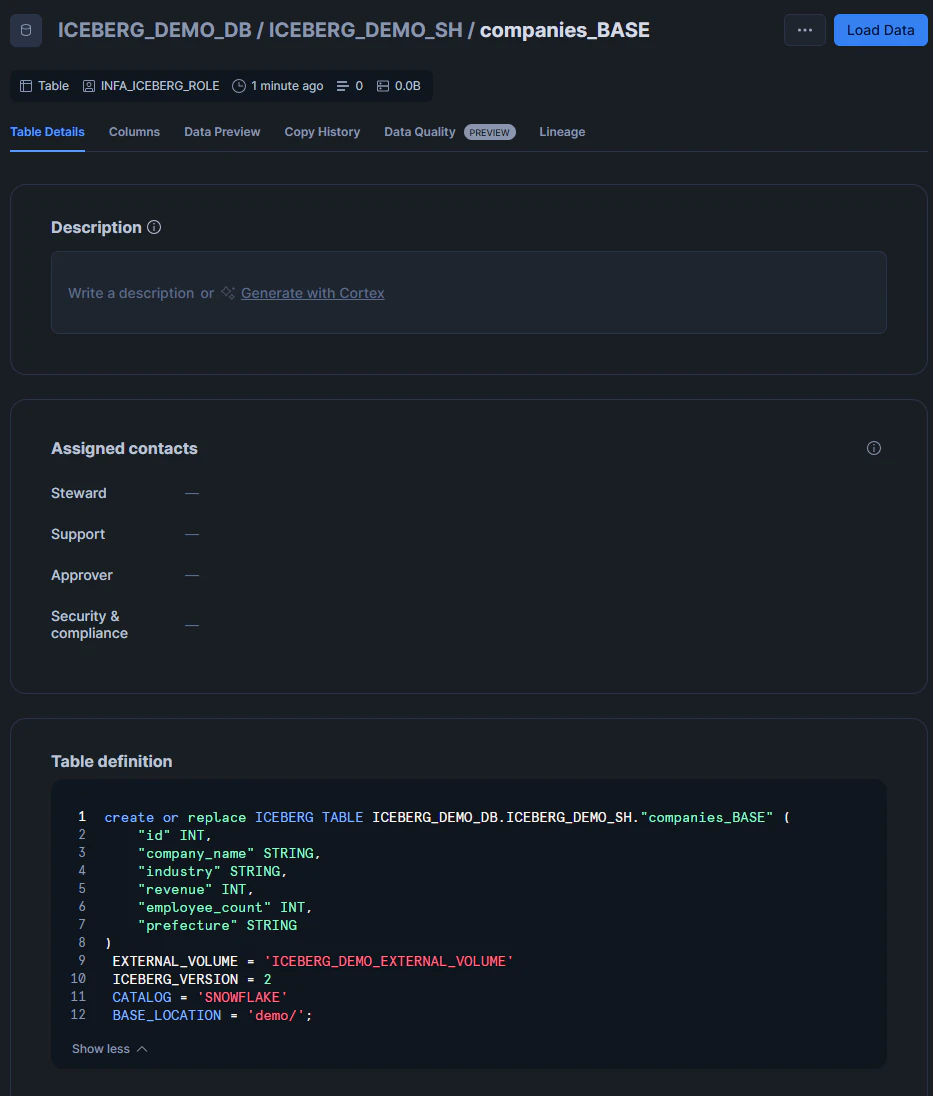
デプロイすると、ソースオブジェクトのスキーマを読み取り、ターゲットオブジェクトにテーブルが自動生成されます。
実行
データベース取り込みタスクを「実行」します。
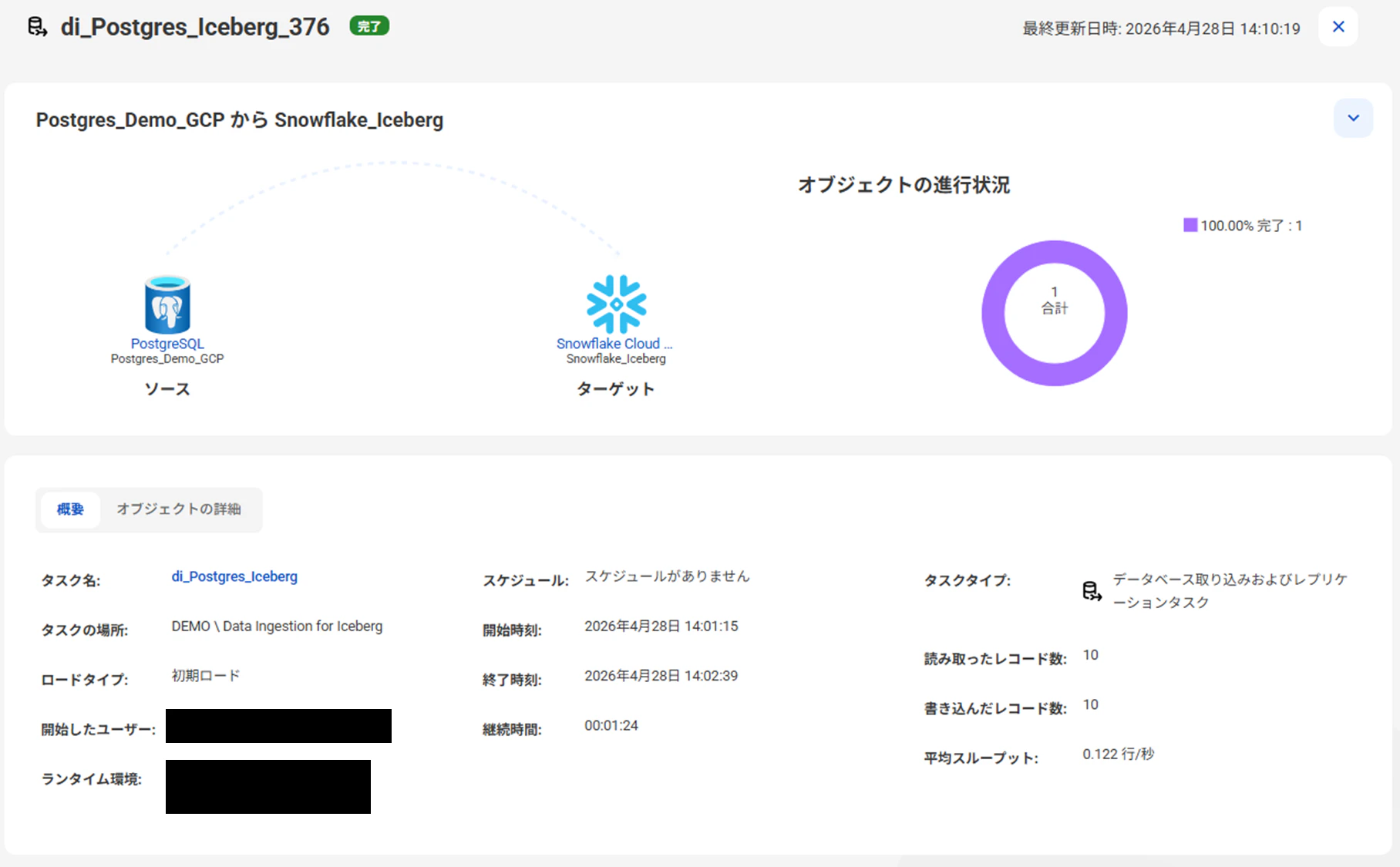
実行が成功し、PostgreSQL内のレコードがSnowflakeにロードされました。
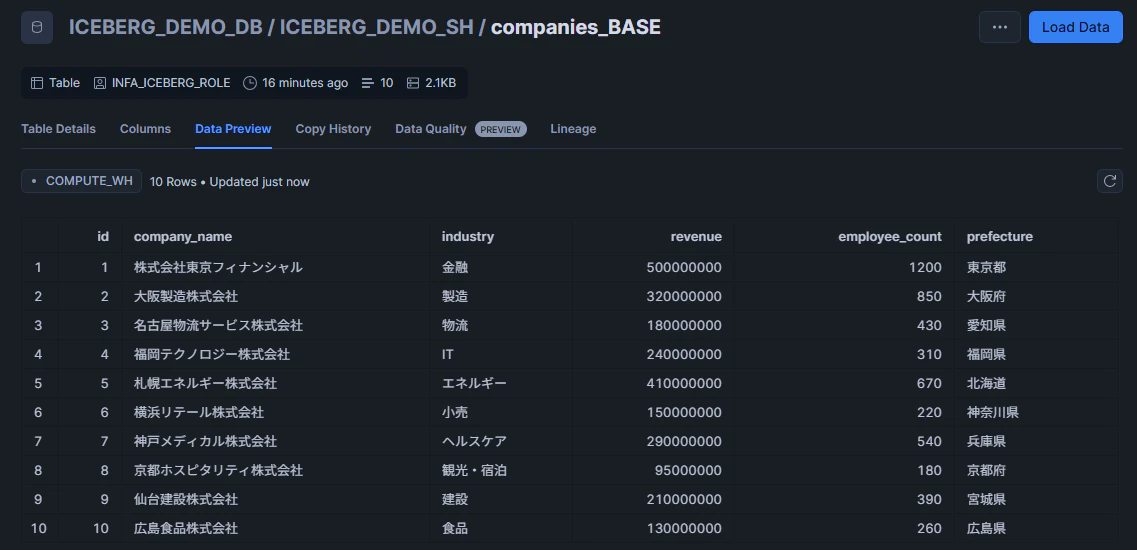
結果確認
Snowflakeでは、デプロイで作られたテーブルに10行のレコードが追加されています。
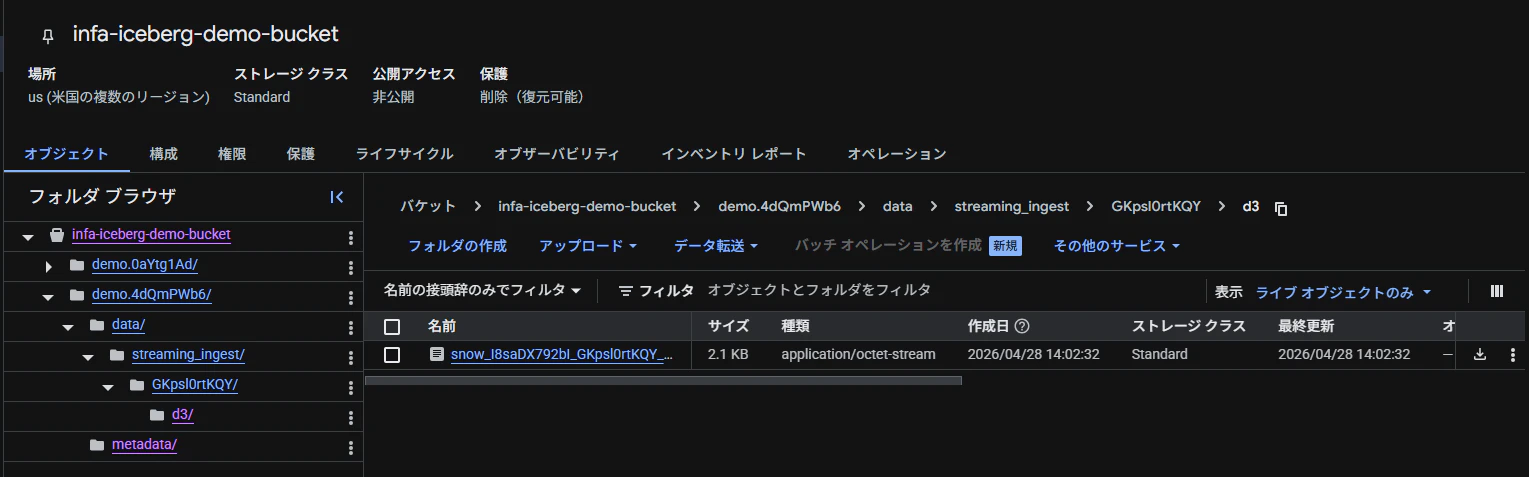
Icebergの保存先であるGoogle Cloud Storageでは、
Iceberg形式のフォルダ階層が生成され、Parquetファイルにデータが格納されています。
おわりに
今回は、CDIR(Cloud Data Ingestion and Replication)を用いて、Snowflake管理のIcebergテーブルへシームレスにデータを同期する手法を解説しました。
通常、Icebergのようなオープンフォーマットへのデータ変換やロードには、複雑なコーディングや高度なパイプライン設計が求められます。しかし、IDMCのCDIRを活用すれば、専門的なスキル不要で数千テーブル規模の大量ロードを数分でセットアップできるため、Snowflake管理のIcebergによる「次世代データレイクハウス」を最短ルートで実現可能です。
データレイクハウスの構築による運用コスト削減や、ベンダーロックインを回避したデータ基盤戦略を検討されている方は、ぜひCDIRによる「Icebergへの自動ロード」を体感してみてください。
参考