書いたこと
RustでPDF解析ツールを作成するにあたって、PDFリファレンスからその仕様をまとめる。
(作成プログラムはPDF.jsを参考に実装予定)
PDFとは
PDF32000_2008 1. Introduction より抜粋して意訳
PDFは、ISO 32000によって規定されている電子ドキュメントを実現するためのファイルフォーマットである。
1993年から2007年のISO標準になるまでAdobeによって開発され、PDF 1.7がISO 32000版の基となって策定された。
各バージョンは後方包括的であるため、PDF1.7はPDF1.0から1.6の仕様をそのまま含んでいる。
PDFのCoreは、PostScriptページ記述言語 から切り離された高い水準の描画モデルであり、テキストやグラフィックの記述をデバイスや解像度から独立して表されている。
それによって紙媒体から電子フォーム、デジタル紙までをカバーすることができる。
PDFは以下の電子ドキュメントに求められる要求を満たしている。
-
デバイス、プラットフォーム、ソフトウェアから独立したドキュメントの保全
-
Webサイト、ワード、スプレッドシート、スキャナー画像、写真、グラフィックスなど多様なソースを1つのPDFドキュメントに結合する
-
電子署名
-
作成者に対するセキュリティとパーミッションの許可
-
障碍者へのコンテンツのアクセシビリティ
PDF構文
PDF構文は、大まかに4つのパートに分けて理解することができる。
- Objects
- File構造
- Document構造
- Content Stream
Objects
文字列、数字、配列、辞書、ストリーム、名前といったデータ型が定義されている。
PDFの解析にあたっては、字句解析を通してトークン化し、構文解析をかけることが必要となる。
PDF.js による相互参照テーブルの取得部分
const parser = new Parser({ // 構文解析器
lexer: new Lexer(stream), // 字句解析
xref: this,
allowStreams: true,
});
var obj = parser.getObj(); // オブジェクトの取得
if (isCmd(obj, "xref")) { // オブジェクトが相互参照テーブルであるかどうかを検証
// Parse end-of-file XRef
dict = this.processXRefTable(parser);
if (!this.topDict) {
this.topDict = dict;
}
名前型
「名前」型は、一般のプログラミング言語には馴染みのないデータ型ではあるが、const定数 に相当する。
名前データ型の定義
先頭に「/」をつける
/名前
プログラミング言語では以下に相当する。
const 名前 = "名前"
Examples
名前型と辞書データ型
例: 辞書データ型のキー値は必ず「名前」である必要がある
1917 0 obj
<</Type /Catalog % カタログ辞書を表す
/Pages 1915 0 R
/Dests 1916 0 R>>
endobj
/Type,/Catalog,/Pages,/Datesといった値が名前型
Document構造
参照: PDF32000_2008 7.7 Document Structure
PDF解析を実施すると、成果物としてドキュメントのオブジェクト階層を得ることが出来る。

indirect object
名前付きオブジェクト
これによって、他のオブジェクトから参照することが出来る。
また相互参照テーブルにファイルの先頭からのオフセット値が定義されているので、ランダムアクセスすることが可能となっている。
indirect objectの宣言
オブジェクト番号(n) 世代番号(g) obj
% 値
endobj
- オブジェクト番号: PDF内でユニークな値
- 世代番号: インクリメンタル更新する際に+1していく
名前付きオブジェクトへの参照方法
n g R
-
R: 名前が n g のオブジェクトへの参照
Examples
ページオブジェクトとMediaBoxの値への参照
31 0 obj
<<
/Type /Page
/Parent 387 0 R
/MediaBox 6026 0 R % MediaBoxの値は オブジェクト番号6026で定義されている
...
>>
...
6026 0 obj % オブジェクト番号6026
[ 0 0 612 792 ]
endobj
direct object
indirect object以外のObjectは全てdirect objectとなる。
ドキュメントのオブジェクト階層においては、トレーラー辞書のみがdirect objectとなる。
したがって、トレーラー辞書を解析するにはファイル構造で定義されたオブジェクトの配置戦略が必要となる。
カタログ辞書
ドキュメントのオブジェクト階層のRoot。
1 0 obj
<< /Type /Catalog % カタログ辞書であることを表す
/Pages 2 0 R % ページツリーノードのオブジェクト番号
/Outlins 3 0 R % アウトラインノードのオブジェクト番号
>>
endobj
ページツリーノード
各ページのオブジェクト番号が記載されている。
2 0 obj
<< /Type /Pages % ページツリーノードであることを表す
/Kids [ 4 0 R % ページ1のオブジェクト番号
10 0 R % ページ2のオブジェクト番号
24 0 R % ページ3のオブジェクト番号
]
/Count 3 % ページ数
>>
endobj
- /Kids: 各ページのオブジェクト番号を記載
ページオブジェクト
リソースが定義されているオブジェクト番号やその中身を表すコンテンツストリームのオブジェクト番号が定義されている。
4 0 obj
<< /Type /Page % ページオブジェクトであることを表す
/Parent 2 0 R % ページツリーのオブジェクト番号
/MediaBox [0 0 612 792] % ページの領域を表す
/Resources << /Font << /F3 7 0 R
/F5 9 0 R
/F7 11 0 R
>>
/ProcSet [/PDF]
>>
/Contents 12 0 R % コンテンツストリームのオブジェクト番号
/Thumb 14 0 R % サムネイル
...
>>
endobj
コンテンツストリームオブジェクト
ページを描画するための命令が記述されている。
12 0 obj
<< /Length 65
>>
stream
1. 0. 0. 1. 50. 700. cm % 現在位置を(50, 700)に移動
BT
/F0 36. Tf % 36ポイントの/F0フォントを選択
(Hello World!) Tj % 文字列 Hello World! を描画する
ET
ET
endstream
endobj
PDFファイル構造
参照: PDF32000_2008 7.5 File Structure
PDFファイル構造は、ファイル内にオブジェクトを配置するための戦略が定義されている。
これは互換性を伴いながら3つのパターンが存在し、成果物としてドキュメントの オブジェクト階層を得る ことができる。
| ファイル構造パターン | 概要 |
|---|---|
| 1. オブジェクト参照テーブルとトレーラー辞書によるPDF (version 1.0以降) | ランダムにオブジェクトを配置することができ、インクリメンタル更新ができる |
| 2. 単一オブジェクトストリームによるPDF (version 1.5以降) | PDFファイルの圧縮、暗号化 |
| 3. Web最適化されたPDF (version 1.2以降) | PDFファイルを先頭から解析することが出来る |
- 基本2,3は1の拡張
1. オブジェクト参照テーブルとトレーラー辞書によるPDF
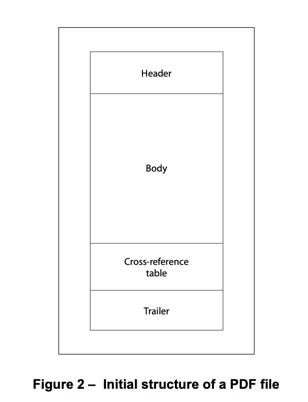
ファイルの先頭から5つのパートで構成されている
- ヘッダー
- バディ
- 相互参照テーブル
- トレーラー辞書
- startxref
例: 相互参照テーブルとトレーラー辞書によるPDF
%PDF-1.0 % ヘッダー
〓〓〓〓〓 % ASCII制御コードが埋め込まれる (バイナリファイルであることをFTPツールなどに判定させる)
1 0 obj % バディ
<< /Type /Catalog
/StructTreeRoot 3 0 R
...
>>
endobj
3 0 obj
...
endobj
...
xref % 相互参照テーブル
0 7
0000000003 65535 f
0000000017 00000 n
0000000081 00000 n
0000000000 00007 f
0000000331 00000 n
0000000409 00000 n
trailler % トレーラー辞書
<< /Size 100
/Root 1 0 R
/ID ...
>>
startxref
2664 % 相互参照テーブルのオフセット位置
%EOF
ヘッダー
PDFバージョンを記載
バディ
カタログ辞書、ページツリーといったオブジェクトを配置
相互参照テーブル
各indirect objectへアクセスするための表が定義されている
例: 相互参照テーブル
xref % 相互参照テーブル
0 7
0000000003 65535 f
0000000017 00000 n
0000000081 00000 n
0000000000 00007 f
0000000331 00000 n
0000000409 00000 n
xref キーワード
相互参照テーブルの開始を表す
先頭行
0 7
オブジェクト番号0から6のObjectsが定義されていることを表す
2行目以降
nnnnnnnnnn ggggg *n* eol
-
nnnnnnnnnnオブジェクトのオフセット(位置)を先頭からのbytes単位で表す -
ggggg5桁の世代番号 -
nin-use項目であることを表す識別子 -
ffree項目であることを表す識別子 -
eol行末を表す2文字。以下の制御文字が使用可SP CRSP LFCR LF
- 10桁のオフセット(
nnnnnnnnnn)と世代番号(gggg)は一文字のSPACEで区切る - free項目になる方法は2つある
- テーブルの最初の項目 (オブジェクト番号が0で、世代番号が必ず65,535)
- フリーオブジェクトのルートを表す
- 最後のフリーオブジェクトは必ず0にリンクする
- indirect objectを削除したとき、相互参照テーブルの項目にfreeマークを付ける
- 世代番号は、次に生成されるオブジェクト番号(現状のオブジェクト番号の最大値をインクリメントする)が与えられる
- テーブルの最初の項目 (オブジェクト番号が0で、世代番号が必ず65,535)
Examples
EXAMPLE オブジェクト番号3は削除され、その世代番号は次に生成されるオブジェクト番号を表す
xref
0 6 % 0から6つのobjectsを持つ
0000000003 65535 f % object number 0, free
0000000017 00000 n % object number 1, in-use
0000000081 00000 n % object number 2, in-use
0000000000 00007 f % object number 3, free, 最後なのでobject 0にリンクされる
0000000331 00000 n % object number 4, in-use
0000000409 00000 n % object number 5, in-use
EXAMPLE 4つのsubsectionをもつ相互参照テーブル
xref
0 1 % オブジェクト番号0の一つのエントリーを持つサブセクション
0000000000 65535 f
3 1 % オブジェクト番号3の一つのエントリーを持つサブセクション
0000025325 00000 n
23 2 % オブジェクト番号23,24の二つのエントリーを持つサブセクション
0000025518 00002 n
0000025635 00000 n
30 1
0000025777 00000 n
- 4つのsubsectionから構成され、トータルで5つの項目をもつ
- オブジェクト番号23は、再使用されている。世代番号が2であるため。
トレーラー辞書
参照: 7.5.5 File Trailer
カタログ辞書の在りかや圧縮、暗号化情報が記載されている。これを得ることに寄ってオブジェクト階層を構成することが出来る。
trailer
<<
/Size 11574
/Root 1917 0 R
/Info 1 0 R
/Prev 9766318
>>
-
/Root: カタログ辞書のオブジェクト番号
startxref
startxref行は、 トレーラー辞書のブラケット(<<...>>)の次に必ず配置され、%%EOFの間に相互参照テーブルのオフセット位置がバイト値で記載されている。
PDFの解析にあたっては、ファイルの最後から startxref キーワードの値を読み取って、相互参照テーブルにアクセスする。
PDF.jsによる該当コード
src/core/document.js
get startXRef() {
// `startxref`を前方検索によって探す
const step = 1024;
const startXRefLength = STARTXREF_SIGNATURE.length;
let found = false,
pos = stream.end; // ポジションを最終行に合わせる
while (!found && pos > 0) {
pos -= step - startXRefLength; // 最終行から1024バイトずつさかのぼっていく
if (pos < 0) {
pos = 0;
}
stream.pos = pos;
found = find(stream, STARTXREF_SIGNATURE, step, true); // startxrefキーワードを検索
}
2. 単一オブジェクトストリームによるPDF
参照: 7.5.7 Object Stream
PDF 1.5からstreamオブジェクト内に複数のindirect objectを格納することが出来る Object Stream が存在する。
これによってファイルそのものを暗号化やstreamデータ内の圧縮によるコンパクト化などが行うことが出来る。
またObject Streamを用いた場合、相互参照テーブルやトレーラー辞書の代わりに、相互参照ストリームを使用する。
Object Stream
15 0 obj
<< /Type /ObjStm % オブジェクトストリームを表す
/Length 1856
/N 3 % オブジェクト数
/First 24 % デコードされたstream内における最初のオブジェクトへのバイトオフセット
>>
strem
11 0 12 547 13 665 % オブジェクト番号とオフセット値が交互に定義されている
<< /Type /Font
...
>>
...
endstrem
endobj
...
-
11 0 12 547 13 665- オブジェクト番号11のオフセット値が0
- オブジェクト番号12のオフセット値が547
相互参照ストリーム
参照: 7.5.8 Cross-Refarence Stream
相互参照テーブルとトレーラー辞書に代わって、オブジェクトストリーム内のオブジェクトにアクセスするための情報を提供する。
streamオブジェクトで定義されている。
obj
<< /Type /XRef % 相互参照テーブルを表す
/DecodeParms
<</Columns 3
/Predictor 12
>>
/Filter /FlateDecode % ストリーム内のデータを復号するためのフィルター
/Index [200 5589] % オブジェクト番号200から5589個のオブジェクトをこのストリーム内に含む
/Length 112
/Size 5789
/W [1 2 1] % 相互参照テーブルの各フィールド値のサイズ値
>>
stream
...
- /XRef: このストリームがオブジェクト参照ストリームであることを表す
相互参照ストリームデータの中身
相互参照テーブルが定義されている。
stream
01 0E8A 0 % オブジェクト番号2、Type1(非圧縮,オフセット値,世代番号)
02 0002 00 % オブジェクト番号3、Type2(圧縮, 含まれているオブジェクトストリームのオブジェクト番号, ストリーム内のインデックス)
02 0002 01 % オブジェクト番号4、Type2(圧縮, 含まれているオブジェクトストリームのオブジェクト番号, ストリーム内のインデックス)
....
01 1323 0 % オブジェクト番号11、Type1(非圧縮, オフセット値, 世代番号)
endstream
相互参照テーブルの1項目は、3つのフィールドで構成されている。
フィールド1 フィールド2 フィールド3
-
フィールド1: Typeを指定する。Typeは3つ定義されている。(Type0, Type1, Typ2)
Type 0
| Field | Description |
|---|---|
| 1 | タイプを指定。00。この項目は相互参照テーブルのfに相当する |
| 2 | 開放されたオブジェクト番号 |
| 3 | このオブジェクト番号が再利用される際の世代番号 |
例
00 0003 01 % Type0 オブジェクト番号 再利用する際の世代番号
Type 1
| Field | Description |
|---|---|
| 1 | タイプを指定。01 。この項目は相互参照テーブルのnに相当する |
| 2 | オブジェクトへのオフセット値 |
| 3 | 世代番号。値は必ず0 |
例
01 0E8A 0 % Type1 ファイル先頭からのオフセット値 世代番号
Type 2
| Field | Description |
|---|---|
| 1 | タイプ指定。 02 。このオブジェクトはstream内に定義されたオブジェクトであることを表す |
| 2 | このオブジェクトが含まれているストリームオブジェクトのオブジェクト番号 |
| 3 | このオブジェクトのストリーム内のインデックス |
02 0002 00 % Type2 格納されているオブジェクトストリームのオブジェクト番号 ストリーム内のインデックス
3. Web最適化されたPDF (直線化PDF)
参照: Annex F Liniearized PDF
Web上に置かれたPDFを表示するビューアーのために、ページ順にページ単位でオブジェクトを配置したPDF。
またヒントテーブルが導入され、先頭からのアクセスが高速に行えるようになっている。
大きく2つのグループで構成され、1つめは、1ページ目と関連リソースおジェクトまたドキュメントカタログなどドキュメントの構造に関わるObjectがまとめられる。
2つめのグループには、ヒントテーブルと1ページ目以外のObjectsがページ順に配置される。(1ページ目に関連しない、共通リソースはそのあとに配置される)
これによって先頭からファイルを解析できるようになっている。
Web最適化されたPDFかどうかは、ヘッター行のあとに配置されるObjectを読み取ることで判定することができる。
%PDF-1.1
〓〓〓〓〓
43 0 obj % 直線化PDFオブジェクトを表す辞書がヘッダーのあとに配置される
<< /Linearized 1.0 % Version
/L 54567 % ファイルの大きさ
/H [475 598] % ヒントストリームへのオフセット値
/O 45 % 先頭ページのオブジェクト番号
/E 5437 % 先頭ページへのオフセット値
/N 11 % ページ数
/T 52785 % 相互参照テーブルまでのオフセット値
...
>>
endobj
注意として、Web最適化されたPDFをインクリメンタル更新した場合、再度Web最適化する必要がある。
(ヒントテーブルなどの仕様に関しては、別途まとめる予定)
PDF.jsは、相互参照テーブルを解析する段階で先に線形化PDFかどうかの判定を行っている。
get startXRef() {
const stream = this.stream;
let startXRef = 0;
// Web最適化されているかどうかの判定
if (this.linearization) {
// Web最適化されている場合は、ファイルの先頭から読み込んでいく
stream.reset();
if (find(stream, ENDOBJ_SIGNATURE)) {
startXRef = stream.pos + 6 - stream.start;
}
} else {
// Web最適化されていない場合は、ファイルの後方からstartxrefを検索する
const step = 1024;
const startXRefLength = STARTXREF_SIGNATURE.length;
let found = false,
まとめ
- PDFは、オブジェクト階層を表す
- PDFファイル構造は、PDFファイルからオブジェクト階層を生成するための戦略が定義されている
- オブジェクト階層のノード(indirect object)は、更にプリミティブなオブジェクト(文字列、数字、辞書、配列、ストリーム)によって構成されている
- PDFをWeb専用に最適化することが出来る