BigQuery の AWS Glue フェデレーションデータセットを試してみた
はじめに
この記事は 2024年6月27日に行われた color is【クラウドLT大会vol.9】の発表内容をもとに作成しております。
BigQuery の AWS Glue フェデレーションデータセットとは
2024年4月30日に、BigQuery の AWS Glue フェデレーションデータセットが GA になりました。
これは BigQuery Omni の機能の一つです。
BigQuery Omni は BigQuery のコンソール画面から Amazon S3, Azure Blob Storage のデータに BigQuery のクエリを実行できる機能で、AWS, Azure のデータを動かさずに BigQuery での分析で扱うことができます。今回の GA でアクセスできる対象に AWS Glue の Data Catalog が追加されました。
これを使うことで AWS Glue の Data Catalog に登録されているデータソースのデータに BigQuery のクエリを実行できる、つまり一つの設定で AWS の様々なデータベース・ストレージサービスのデータにアクセスできます。
【2024/7/9 修正】 上記内容について、この GA により、「AWS Glue の Data Catalog に登録されている Amazon S3 のデータに BigQuery のクエリを実行できる」が正しいことがわかりましたので修正しました。
この記事では AWS Glue フェデレーションデータセットの検証と使ってみた感想をまとめています。
ちなみに以前 BigQuery Omni を使って Azure Blob Storage のデータにクエリを実行する検証記事を作成しています。よかったらこちらも見てください。
事前調査
AWS Glue Data Catalog フェデレーションデータセット特有の制限はなく、BigQuery Omni の制限が適用されます。
対応リージョン
BigQuery Omni が対応しているリージョンに AWS Glue Data Catalog が存在している必要があります。
2024年6月時点で対応リージョンは6リージョンで、東京リージョンはありません。
料金やエディションなど
2024年6月時点で BigQuery Omni を使えるのはオンデマンド利用、もしくは Enterprise エディションのみとなっています。
また Omni を使うリージョンや契約期間(Enterprise エディションのみ)によっても料金が異なってくるので、料金サイトや見積もりサイトなどで事前計算しておくと安心です。
設定方法
2024年6月時点、日本語ドキュメントはプレビュー時点の内容になっていたため、英語ドキュメントをもとに設定しております。
(プレビュー時点での内容でも設定方法は変わらないと思いますが、GA 後のドキュメントはコンソールからの設定方法の記述があります)
ちなみに AWS の us-east-1 に AWS Glue Data Catalog を作成しました。
AWS IAM ポリシーとロールの作成
AWS IAM より接続したい AWS Glue Data Catalog のアクセス権限を持つポリシーを作成します。
ポリシーは以下のように設定し、他の項目は任意の値で作成しました。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:GetTable",
"glue:GetTables",
"glue:GetPartition",
"s3:ListBucket",
"s3:GetObject"
],
"Resource": [
"arn:aws:glue:us-east-1:<アカウントID>:catalog",
"arn:aws:glue:us-east-1:<アカウントID>:database/<DB名>",
"arn:aws:glue:us-east-1:<アカウントID>:table/<DB名>/*",
"arn:aws:s3:::<バケット名>",
"arn:aws:s3:::<バケット名>/*"
]
}
]
}
続いて IAM ロールを作成します。
ロール作成では、信頼されたエンティティを選択 で以下のように設定します。
- 信頼されたエンティティタイプ` : ウェブアイデンティティ
- アイデンティティプロバイダー : Google
- Audience : 後工程で正しい値を入力するので、作成時は
00000と入力
許可を追加 では先ほど作ったポリシーを選択し、その他の項目は任意の値を指定してロールを作成します。
BigQuery 外部接続設定の作成
作成した AWS IAM ロールを使って、BigQuery 外部接続設定を作成します。
BigQuery の「エクスプローラ」の「︙」から「+追加」ボタンを選択します。
追加パネル内の「一般的なソース」で「外部データソースへの接続」を選択します。
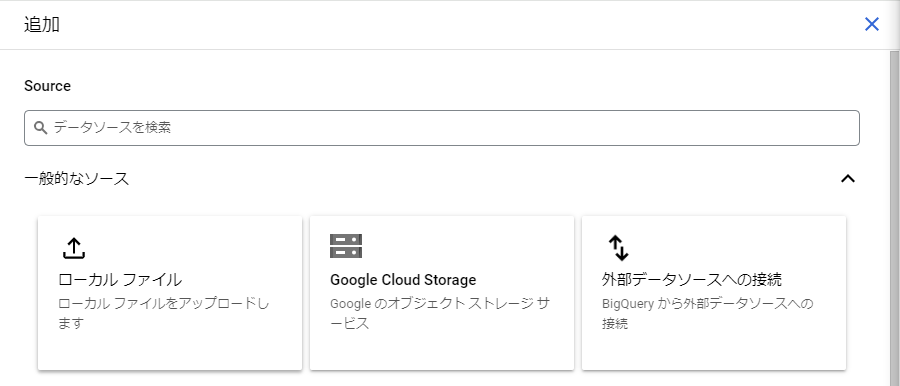
外部データソースパネルにて、以下のように設定します。
- 接続タイプ : AWS 上の BigLake(BigQuery Omni 経由)
- リージョン : AWS Glue Data Catalog が存在するリージョン、
aws-<リージョン名>の形式(今回はaws-us-east1) - AWS ロール ID : 作成したロールの ARN、
arn:aws:iam::<アカウントID>:role/<ロール名>の形式
その他の項目は任意の値を指定して作成します。
作成後、外部接続情報を見ると、BigQuery Google ID に数字が表示されています。
おそらく、この数字を持つサービスアカウントが AWS IAM ロールを引き受ける(AssumeRole)しているのだと思います。
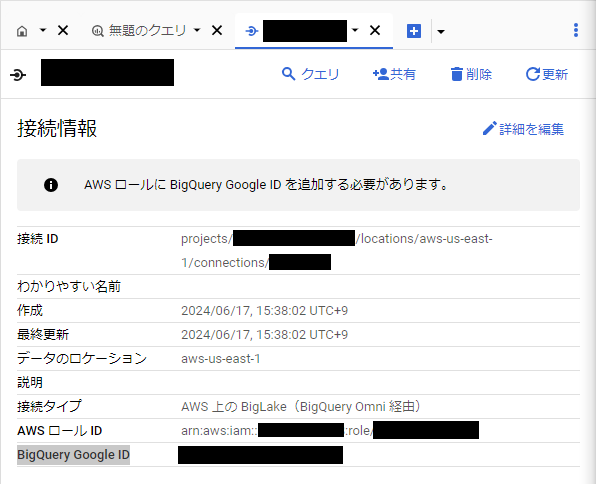
AWS IAM に戻り、BigQuery Google ID の数字の値を AWS IAM ロールの信頼関係に追加します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "accounts.google.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"accounts.google.com:aud": "<BigQuery Google ID>"
}
}
}
]
}
また、AWS IAM ロールの最大セッション時間を12時間に設定します。これ以下の値だと、データセット作成時にエラーが発生します。
フェデレーションデータセットの作成
作成した外部設定を使ってフェデレーションデータセットを作成します。
BigQuery の「エクスプローラ」内のプロジェクト名横の「︙」から「データセットの作成」を選択します。
「データセットを作成する」パネルにて、以下のように設定します。
- ロケーションタイプ : リージョン
- リージョン : 外部データソース作成時に指定したリージョン(今回は
aws-us-east1) - 外部データセット : 「外部データセットへのリンク」にチェックを入れる
- 外部データセットの種類 : AWS Glue
- 外部ソース : 接続したい AWS Glue Data Catalog DB の ARN、
aws-glue://arn:aws:glue:us-east-1:<アカウントID>:database/<DB名>の形式 - 接続ID : 作成した外部接続情報のID、おそらく自動で入力される、
<AWSのリージョン>.<外部接続情報のID>の形式
データセットを作成すると、自動的にテーブルも表示されます。
フェデレーションデータセットの詳細
フェデレーションデータセットは標準と同じようにデータセット一覧に表示されます。アイコンだけ少し異なります。
データセット詳細で接続している AWS Glue Data Catalog のデータベースを確認することができます。(画像の上から2つ目)
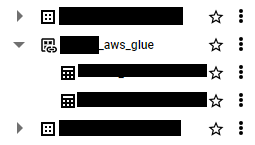
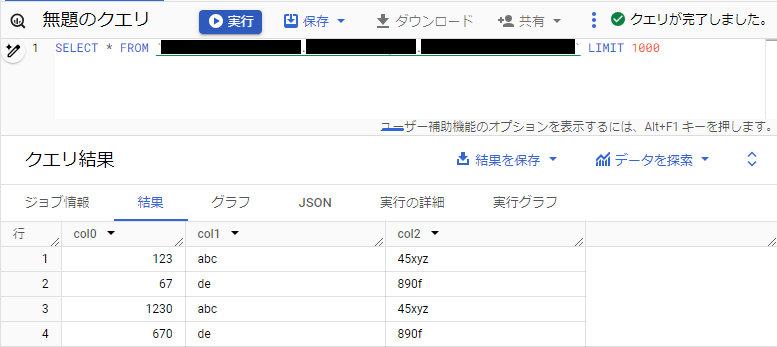
テーブル詳細では詳細タブにて接続しているデータソースを確認できます。Amazon S3 は s3://<バケット名>/*(外部リンク付き)形式で表示されました。
Amazon S3 のテーブルについては、BigQuery 標準テーブルと同じようにクエリを実行できました。
以上です。
誰かの参考になれば幸いです。