ゴールデンウィークから作っていたものが一段落ついたので、そのときに調べたことのまとめです。
概要
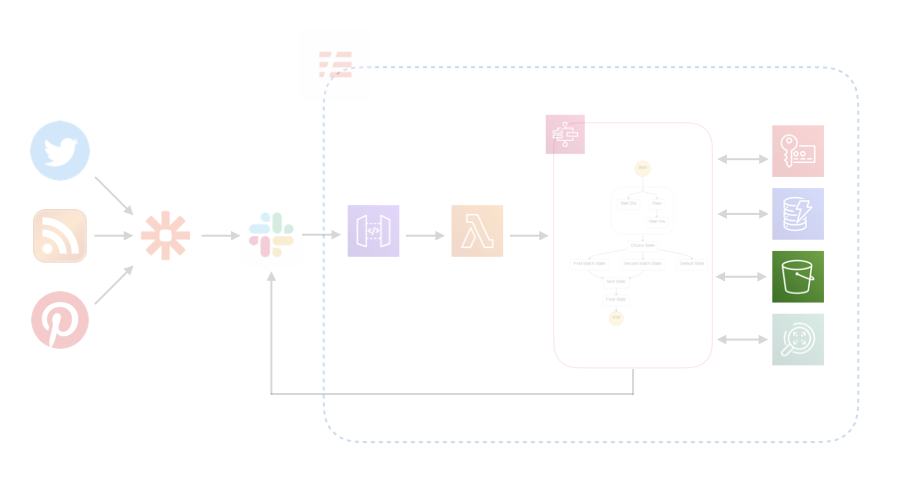
Twitter, RSS, Pinterestから流れてくる情報をSlackに集約し、Lambdaで加工してS3に保存します。その後、ログをSlackに流します。LambdaではPythonを使いました。
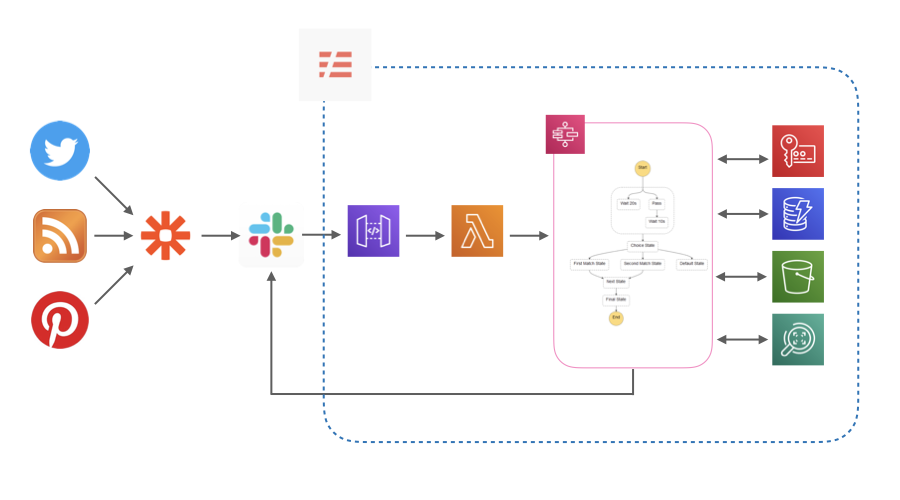
詳細
Zapierで情報をSlackに集約する
Zapierというサービスを使いました。Zapというものを設定してWebサービスを連携させることができます。連携できるサービスは、たとえば、TwitterやPinterest, Instagram, Tumblrなどのソーシャルメディア、Trello, Asana, Github, Googleの各種サービスなど、たくさんあって捗ります。
Freeプランでは5つのZapを設定でき、1ヶ月に100タスク実行することができます。今回の利用目的だと1ヶ月100タスクはちょっと少ないのでStarterにしました。
Zapの作り方
Make a Zap!から、たとえばTwitterを選択して、
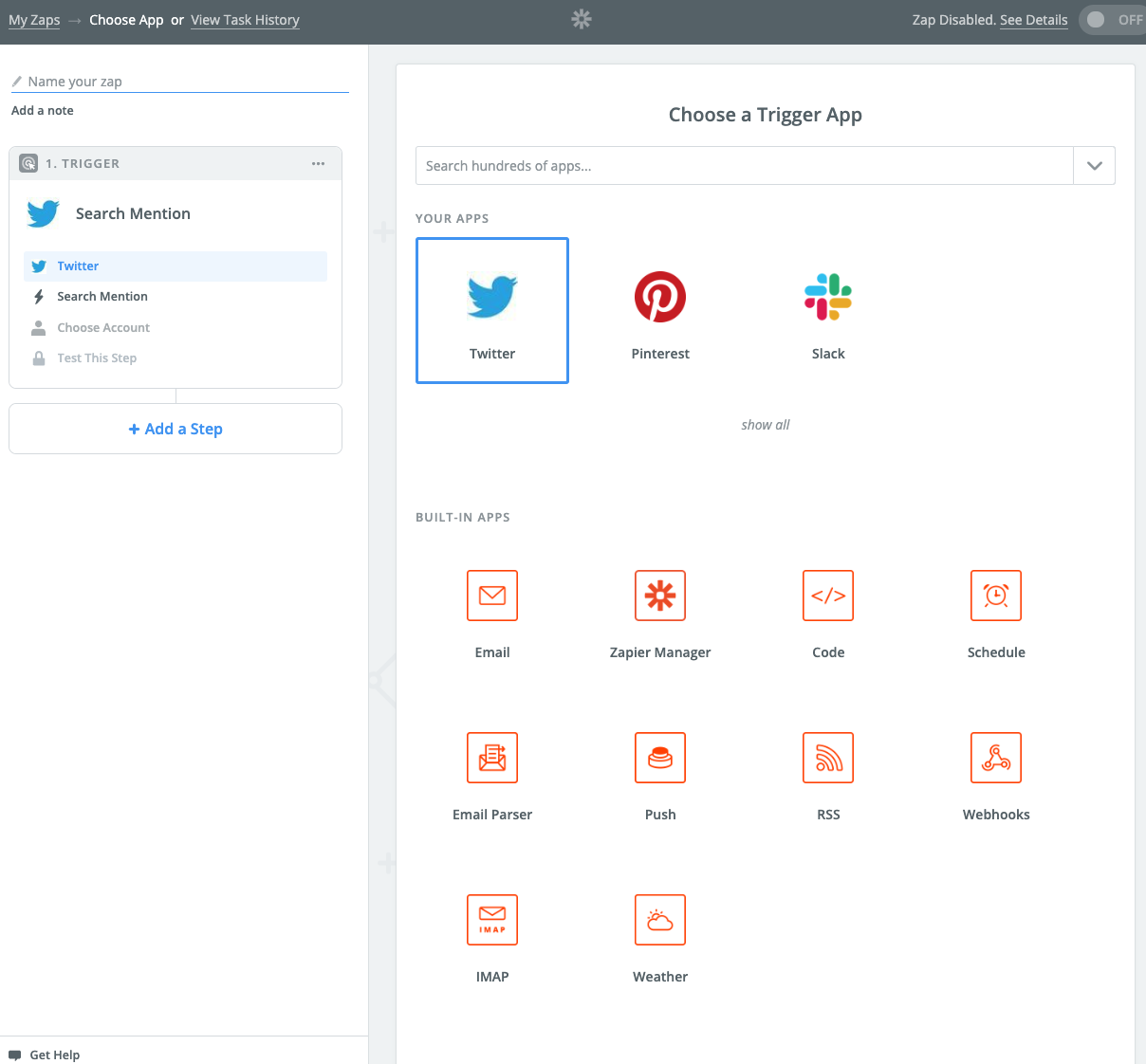
自分のツイートをトリガーに設定。
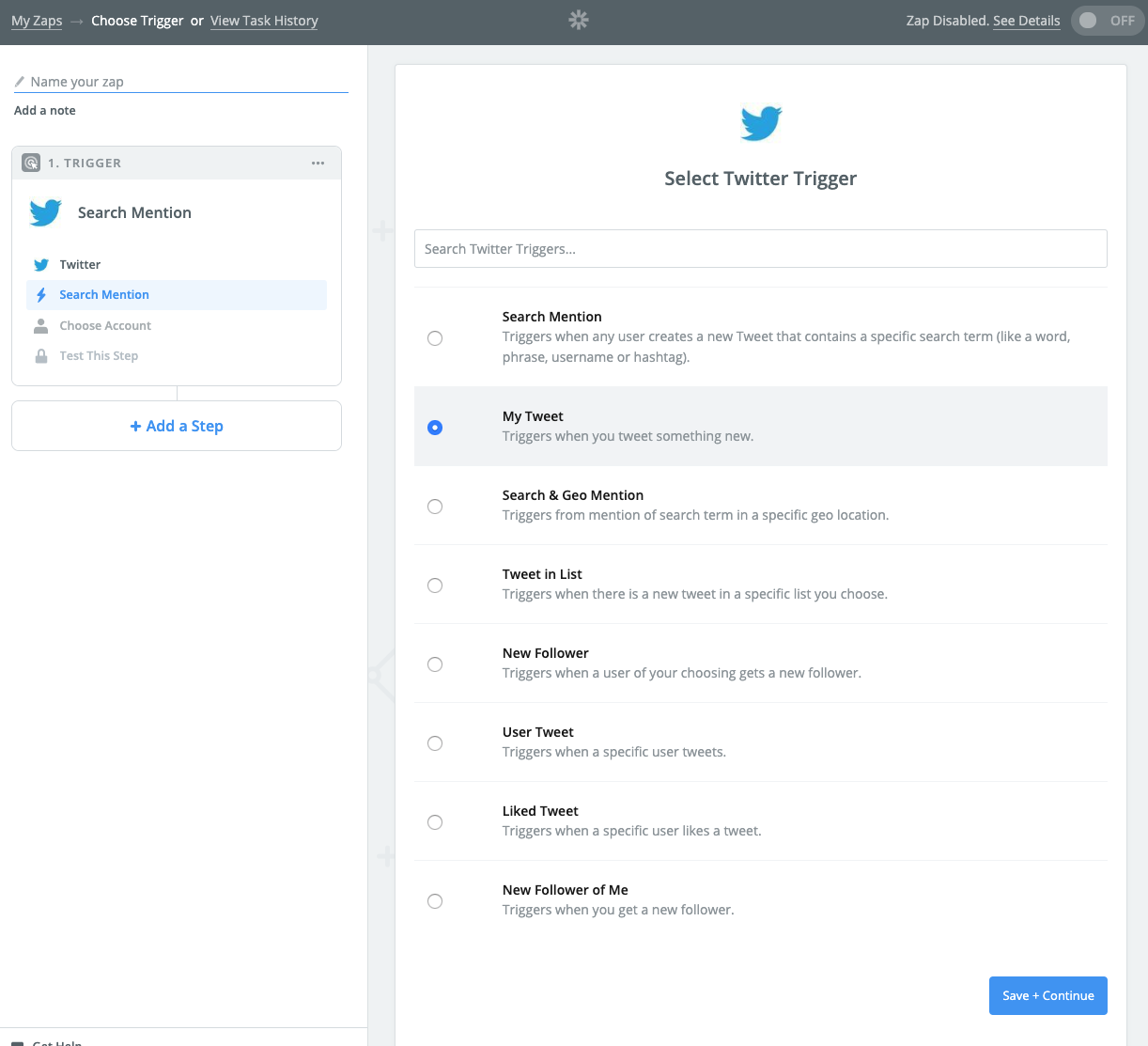
Twitterアカウントを登録して、
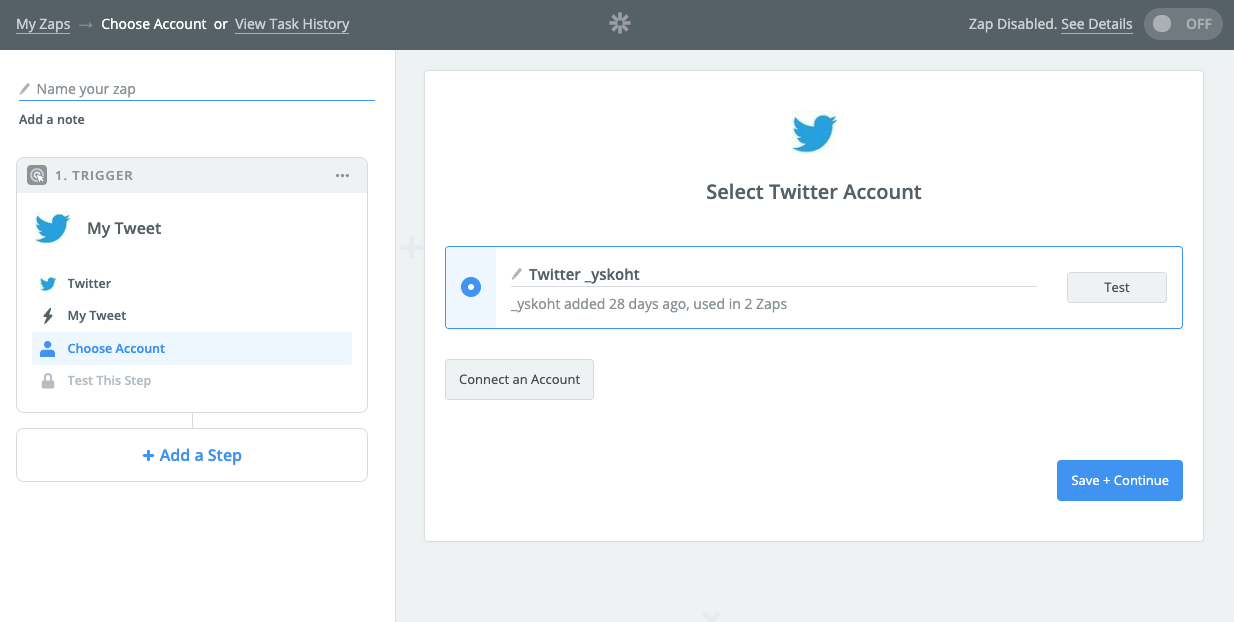
テストに使うツイートを設定しておきます。
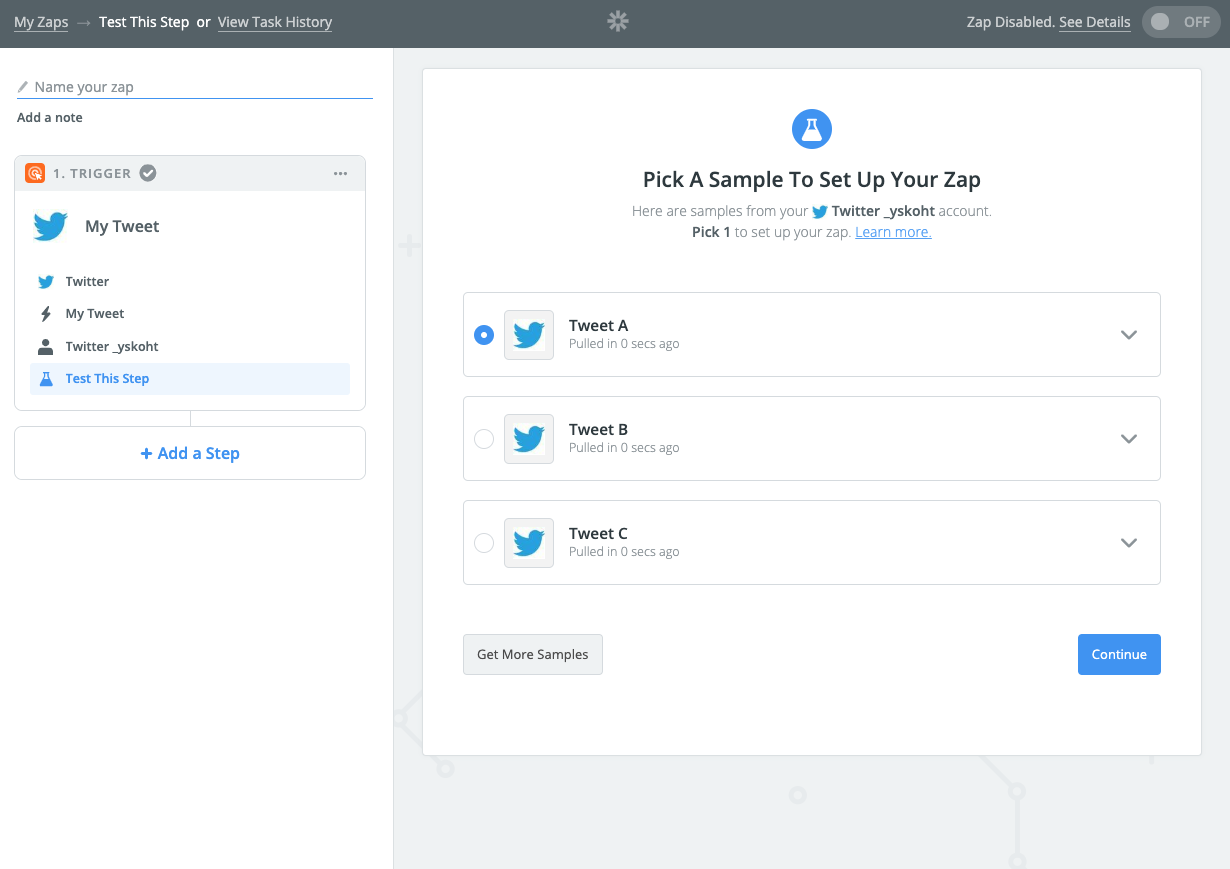
2つめのステップにActionを選択して、Slackを登録。
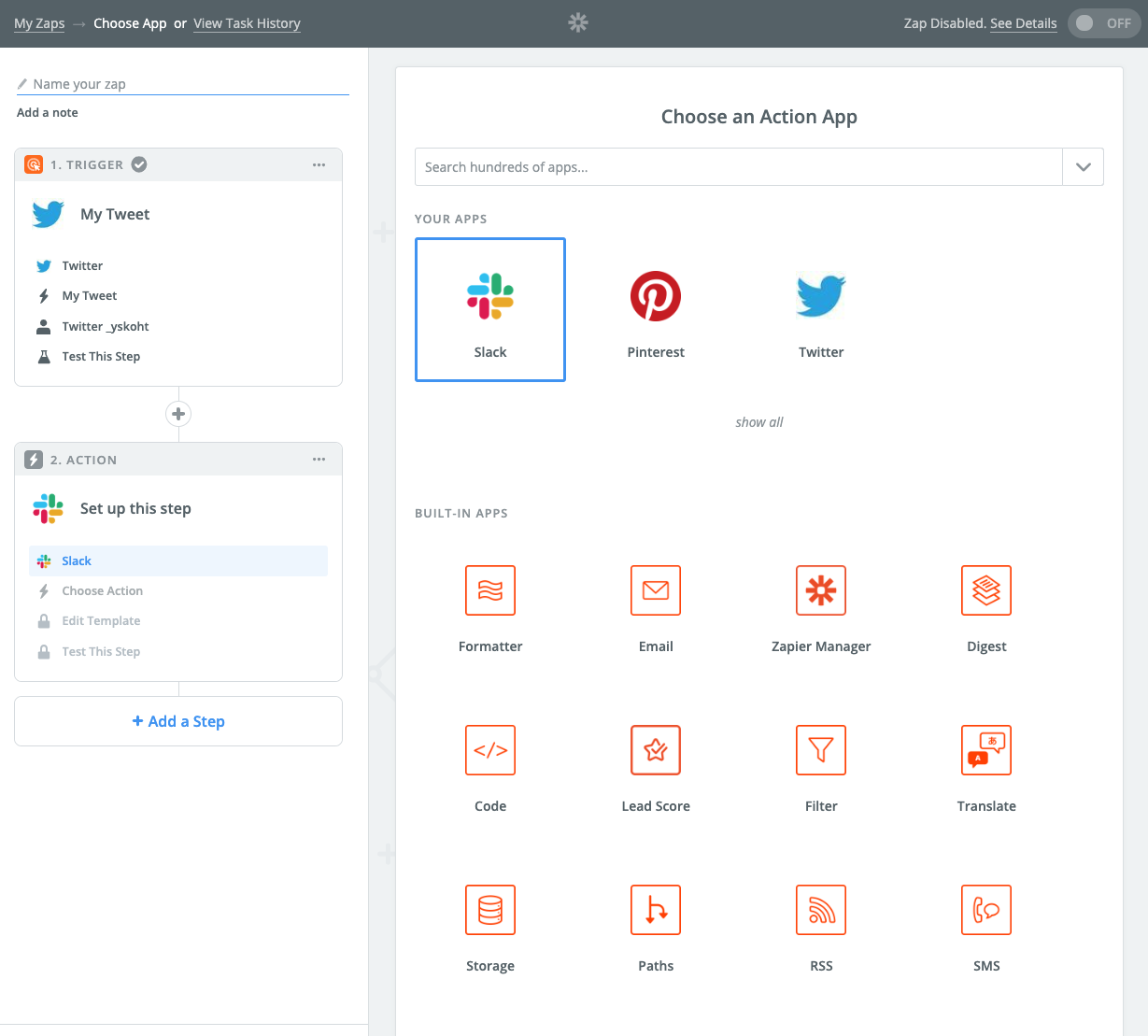
チャンネルにメッセージを送信するように設定
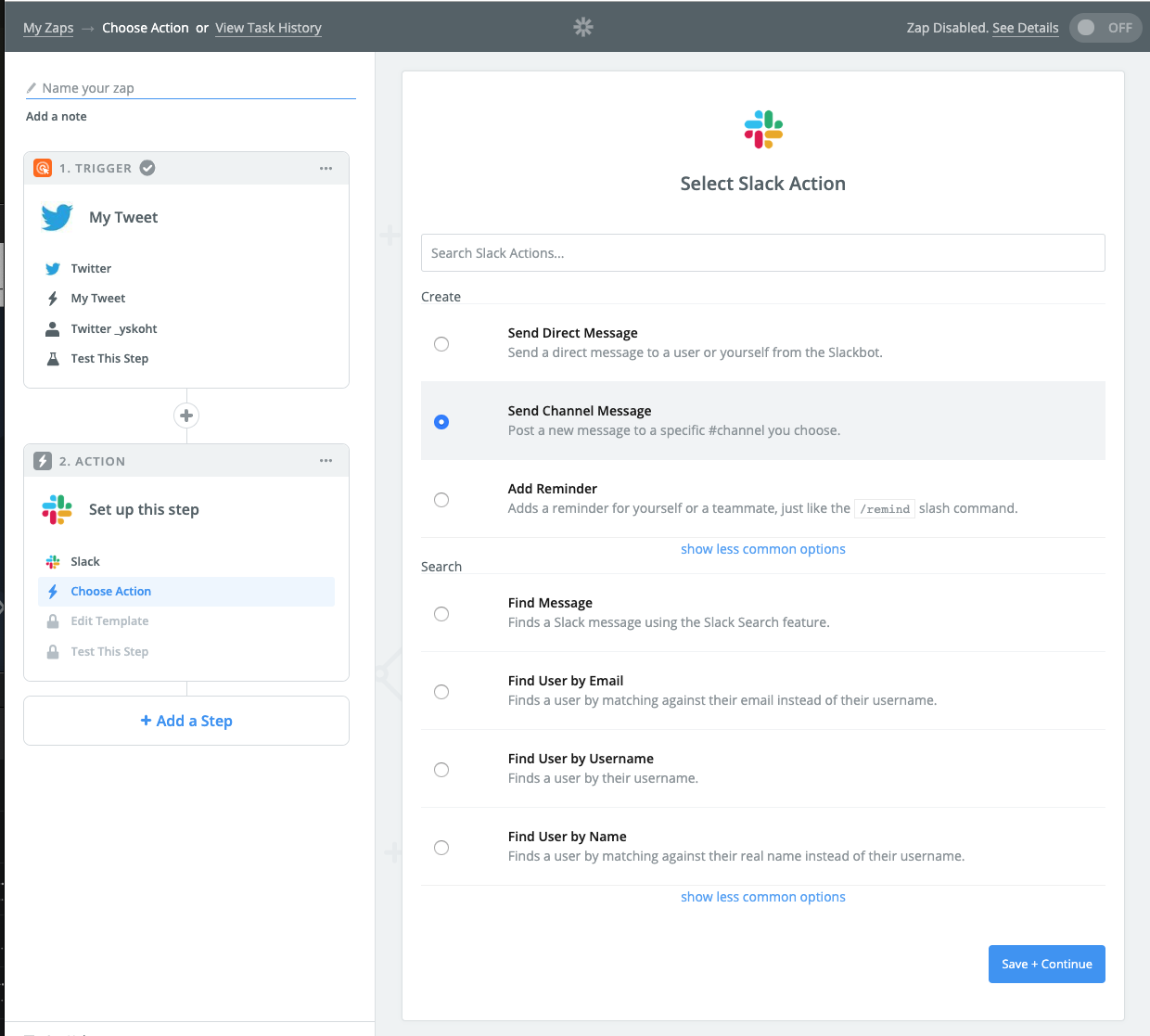
Slackアカウントを登録して、
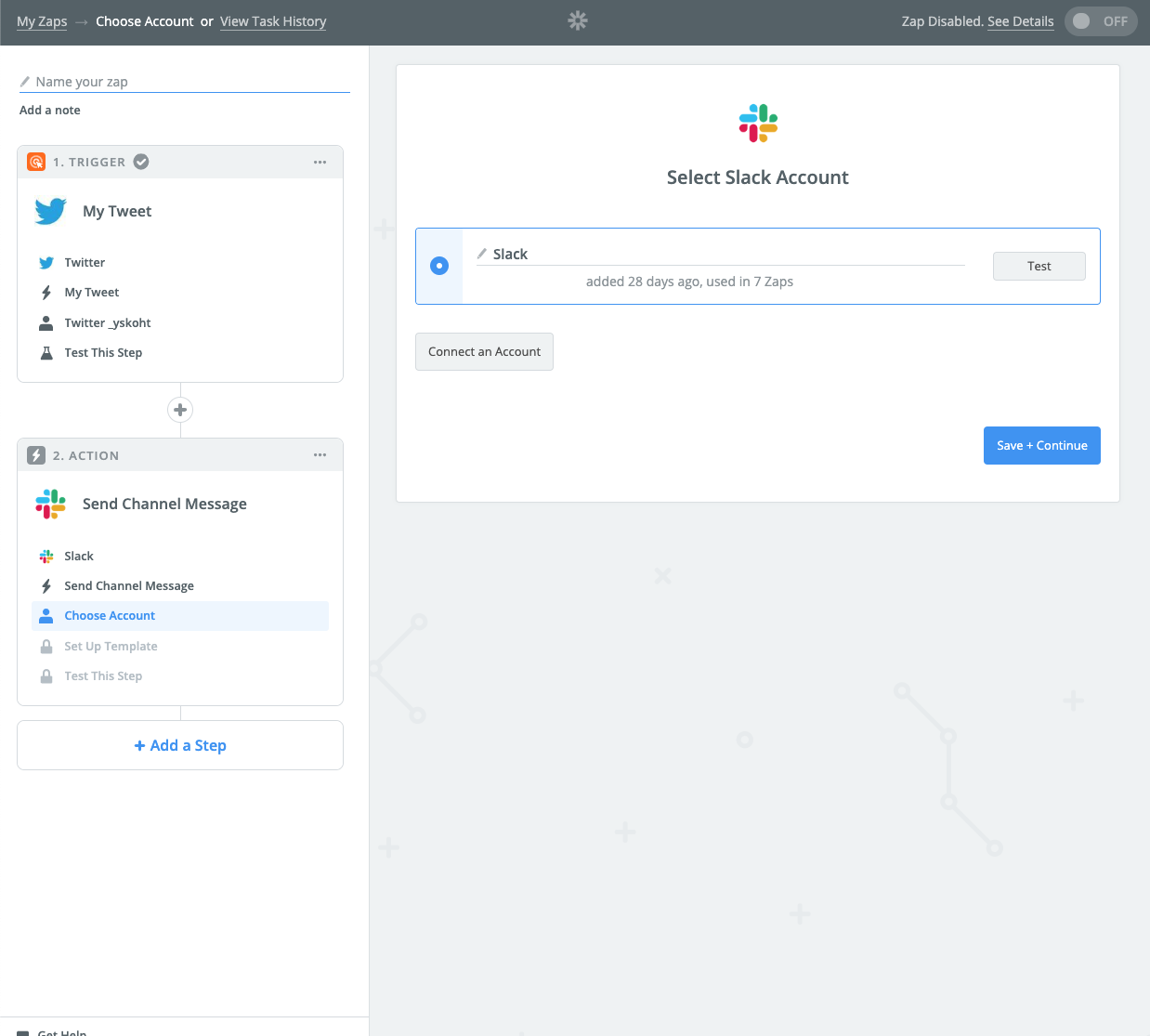
Slackにどんなメッセージを送るのかを決めます。たとえば#generalにツイートのurlを送るように設定。
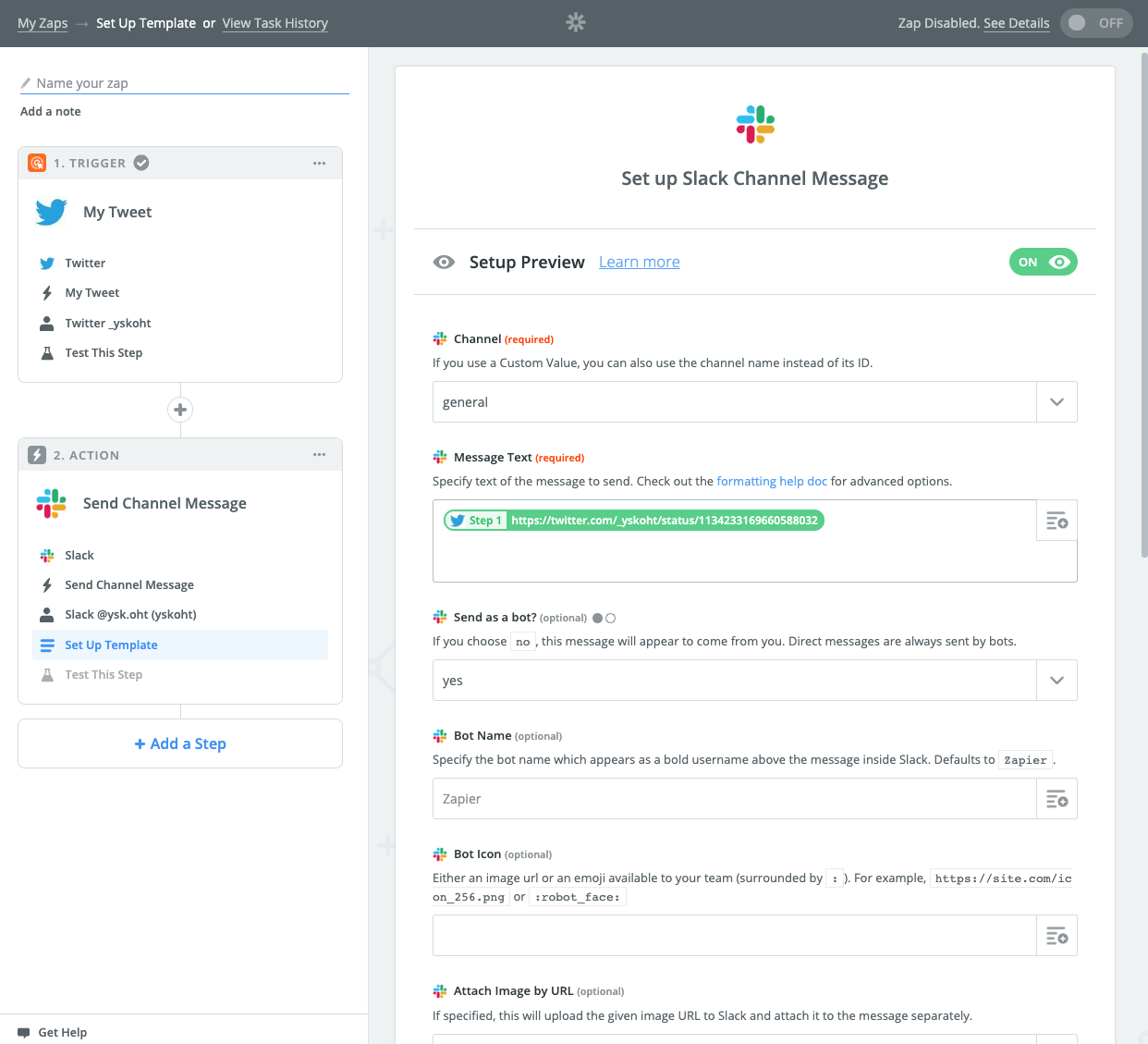
最後にテストして登録したSlackワークスペースの#generalにテストツイートのurlが送信されれば完了です。
SlackからLambdaを起動する
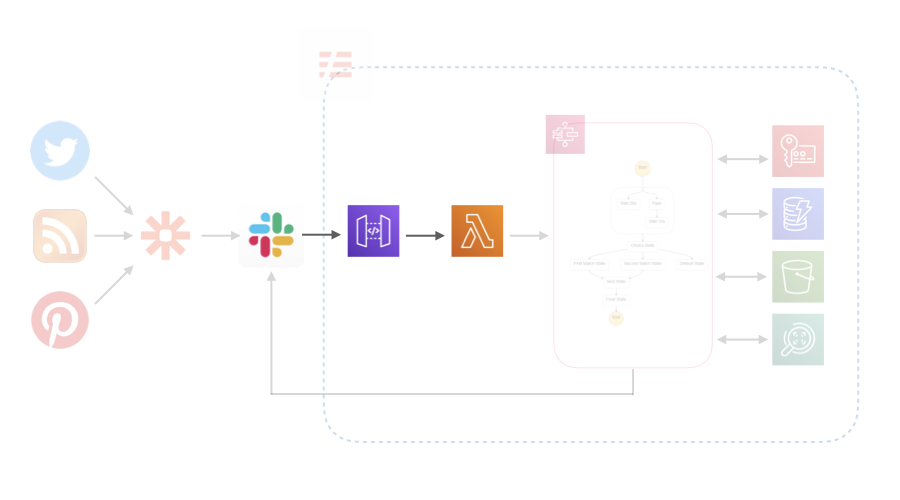
調べてみるととOutgoing WebHooksを使っている記事が多いようなんですが、API Gatewayでマッピングテンプレートを設定する必要があり、serverlessからのデプロイがうまくいかなかったのでやめました。代わりにSlack Appを使いました。
API Gatewayから直接Step Functionsを起動しすることもできますが、challengeを返すのと、verification tokenの確認だけ前段のLambdaで行っています。
def check_challenge(body):
if body.get('type') == 'url_verification':
return {
'statusCode': 200,
'headers': {},
'body': json.dumps({'challenge': body.get('challenge')}),
'isBase64Encoded': False,
}
return None
def check_token(body):
if body.get('token') != SLACK_APP_VERIFICATION_TOKEN:
raise UnauthorizedError
Lambdaプロキシ統合を使っている場合にLambdaのレスポンスの形式は以下。
LambdaからStep Functionsの起動する
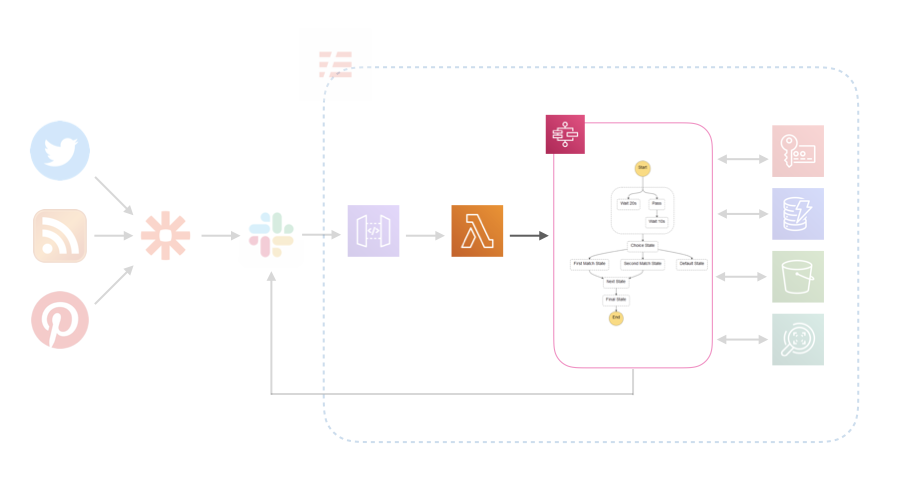
stepfunctions = boto3.client('stepfunctions')
def execute_stepfunction(params):
stepfunctions.start_execution(
**{
'input': json.dumps(params),
'stateMachineArn': STEPFUNCTION_ARN,
}
)
AWSで使ったサービス
Lambda
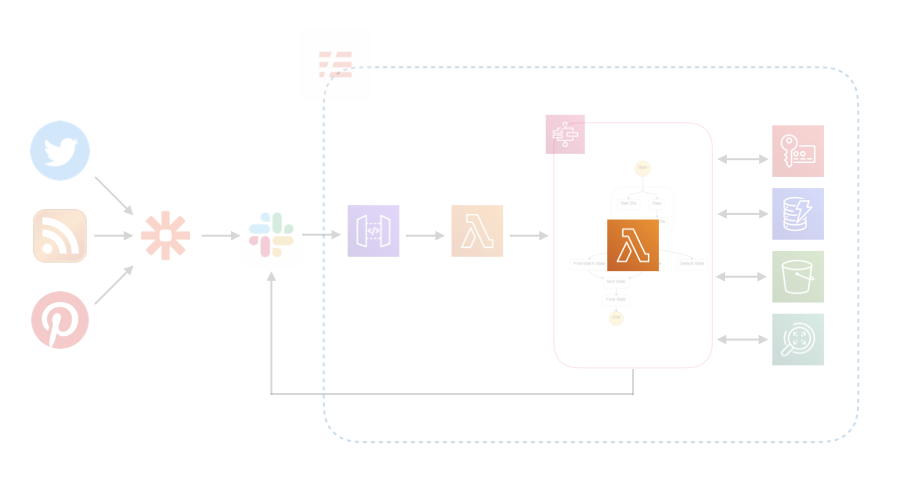
共通のコードはLayerに作成します。
requirements.pyというのをLayerに作っておいて、各ディレクトリのsite-packagesにパスが通るようにしました。
import inspect
import os
import sys
sys.path.append(os.path.join(os.path.dirname(__file__), 'site-packages'))
stack = inspect.stack()[1:]
ms = [inspect.getmodule(_[0]) for _ in stack]
m = next((m for m in ms if m), None)
if m:
path = os.path.dirname(m.__file__)
if path not in sys.path:
sys.path.append(path)
sys.path.append(os.path.join(path, 'site-packages'))
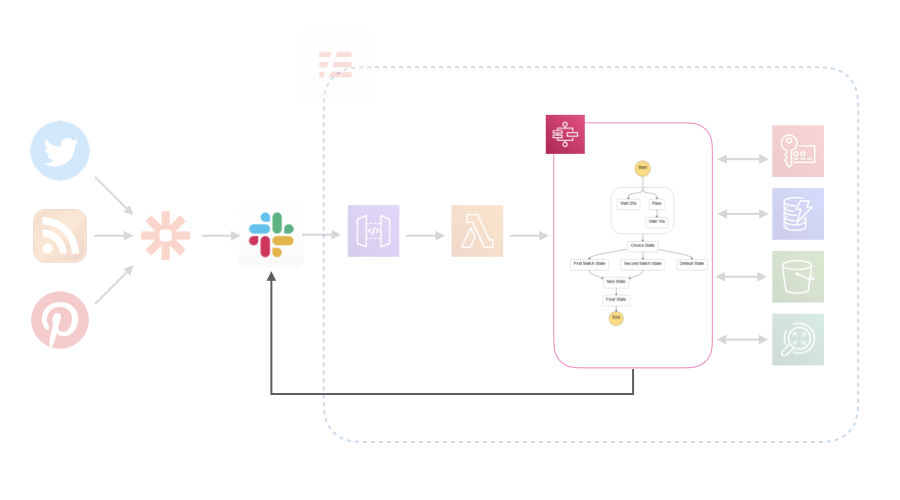
Step Functions
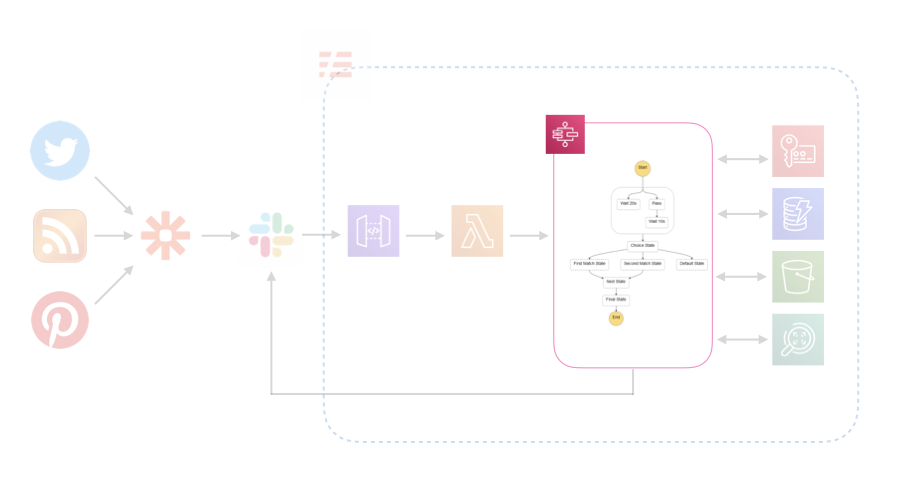
Parallelで下のようなStateを作ると、出力が2つ出てくる。
"ParallelState": {
"Type": "Parallel",
"Next": "NextState",
"Branches": [
{
"StartAt": "Branch1",
"States": {
"Branch1": {
"Type": "Task",
"Resource": "ARN1",
"InputPath": "$",
"ResultPath": "$.branch1Result",
"OutputPath": "$",
"End": true
}
}
},
{
"StartAt": "Branch2",
"States": {
"Branch2": {
"Type": "Task",
"Resource": "ARN2",
"InputPath": "$",
"ResultPath": "$.branch2Result",
"OutputPath": "$",
"End": true
}
}
}
]
}
[
{
"input": "hoge",
"branch1Result": {
"result": "branch1"
}
},
{
"input": "hoge",
"branch2Result": {
"result": "branch2"
}
}
]
この結果を1つにマージしたかったので、Parallelの後に入力をマージするだけのLambdaを1つ追加しました。もっとよい方法があるのかもしれない。
def merge(params):
results = {}
for p in params:
results.update(p)
return result
Key Management Service (KMS)
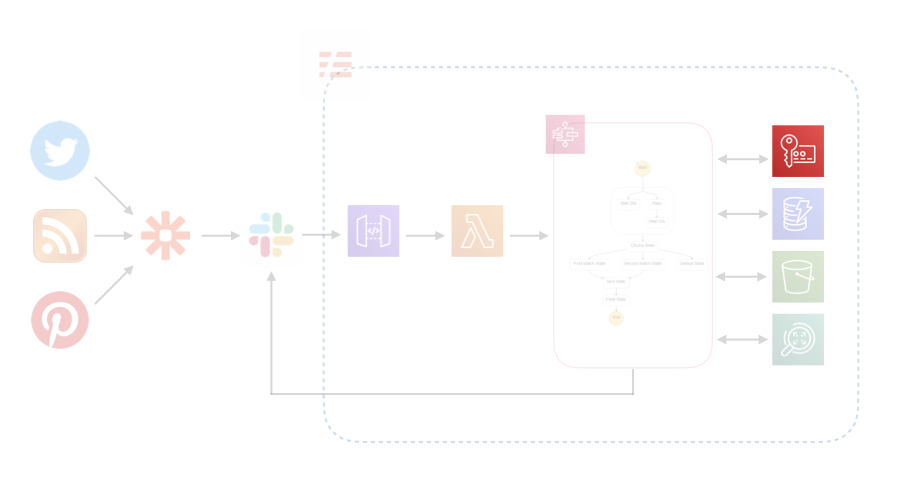
Slackのverification tokenやincoming WebHookのURLなどはKMSで暗号化してLambdaの環境変数に設定しました。
def get_env(key, kms_client=None):
env = os.environ[key]
if kms_client:
env = kms_client.decrypt(
CiphertextBlob=b64decode(os.environ[key])
)['Plaintext'].decode()
return env
kms = boto3.client('kms')
VERIFICATION_TOKEN = get_env('VERIFICATION_TOKEN', kms)
DynamoDB
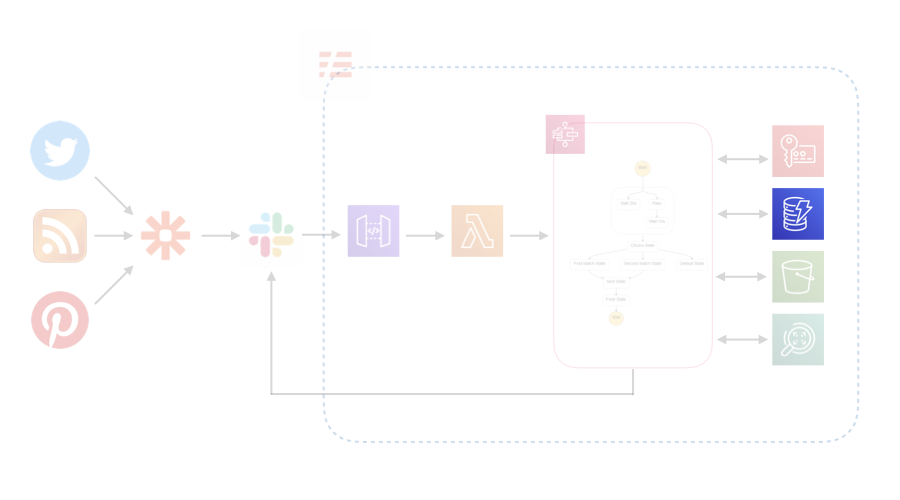
処理したサイト等はキャッシュしておき、2回目は処理しないようにしたかったので、キャッシュをDynamoDBに保存します。
今回はput_itemとget_itemしか使いませんでした。
dynamodb = boto3.resource('dynamodb')
DYNAMODB_TABLE_NAME = get_env('DYNAMODB_TABLE_NAME')
dynamodb_table = dynamodb.Table(DYNAMODB_TABLE_NAME)
def put_item(url, result):
dynamodb_table.put_item(
Item={
"id": url,
"result": result,
}
)
def get_item(url):
r = dynamodb_table.get_item(
Key={"id": url}
)
return r.get('Item')
S3
requestでダウンロードした画像をs3に保存
import requests
def download_image_and_save_to_s3(img_url, key):
r = request.get(img_url)
bucket.put_object(
Key=key,
Body=r.content
)
s3から画像を取得
def get_image_from_s3(bucket, key):
name = os.path.basename(key)
obj = bucket.Object(key).get()
buffer = io.BytesIO(obj.get('Body').read())
return name, buffer
pillowの画像をpngでをs3に保存
import io
def save_image_to_s3_as_png(image, bucket, key):
image_buffer = io.BytesIO()
image.save(image_buffer, 'PNG')
image_buffer.seek(0)
return bucket.put_object(
Key=key,
Body=image_buffer.read()
)
Rekognition
顔の検出
rekognition_client = boto3.client('rekognition')
def detect_faces(bucket_name, key):
return rekognition_client.detect_faces(
Image={
'S3Object': {
'Bucket': bucket_name,
'Name': key
}
},
Attributes=['ALL']
)
顔の比較
rekognition_client = boto3.client('rekognition')
def compare_faces(bucket_name, key):
return rekognition_client.compare_faces(
SourceImage={
'S3Object': {
'Bucket': S3_BUCKET_NAME,
'Name': SOURCE_IMAGE_NAME,
}
},
TargetImage={
'S3Object': {
'Bucket': bucket_name,
'Name': key,
}
},
SimilarityThreshold=80
)
Slackのチャンネルにメッセージを送信
Serverlessでデプロイ
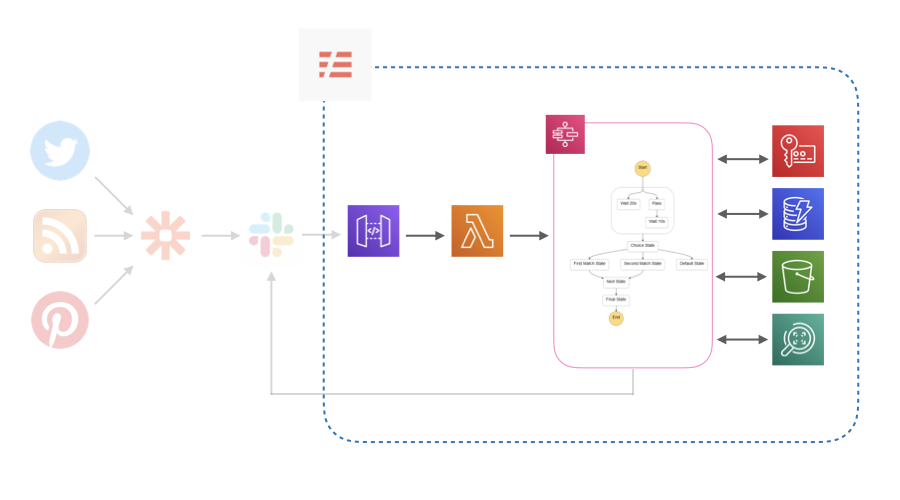
やりたいこと
ディレクトリ構成
|--functions
| |--function1
| | |--function1.py
| |--function2
| | |--function2.py
| | |--requirements.txt
| | |--site-packages
|--layers
| |--requirements
| | |--python
| | | |--requirements.py
| |--lib
| | |--python
| | | |--lib.py
| | | |--requirements.txt
|--serverless.yml
functionsの各ディレクトリの下にrequirements.txtがあればpipし、site-packagesを作ってLambdaにアップロードしたい。ライブラリがOSに依存しているとLambda環境では動かないのでlambci/lambda - Docker Hub上でpipしてsite-packagesを作成する。layerも同様。
UnitedIncome/serverless-python-requirementsとかcfchou/serverless-python-individuallyで出来そうだなと思ってやってみたんですが、うまくいかなかったので自分でプラグインを書きました。
serverless-python-package
./serverless_plugins/serverless-python-packageに配置して↓のような感じでymlを書くとsls deploy時にfunctionsとlayersの各ディレクトリでrequirements.txtがあればpipしてsite-packagesを作ります。dockerize: trueが設定されていればdockerを使います。
plugins:
- serverless-python-package
custom:
pythonPackage:
dockerize: false
provider:
name: aws
runtime: python3.7
stage: dev
package:
individually: true
layers:
requirements:
path: layers/requirements
compatibleRuntimes:
- python3.7
retain: false
lib:
path: layers/lib
compatibleRuntimes:
- python3.7
retain: false
functions:
function1:
name: ${self:provider.stage}-function1
handler: functions/function1/function1.lambda_handler
layers:
- {Ref: RequirementsLambdaLayer}
- {Ref: LibLambdaLayer}
package:
exclude:
- '**/*'
include:
- functions/function1/**
function2:
name: ${self:provider.stage}-function2
handler: functions/function2/function2.lambda_handler
layers:
- {Ref: RequirementsLambdaLayer}
- {Ref: LibLambdaLayer}
package:
exclude:
- '**/*'
include:
- functions/detect_faces/**
pythonPackage:
dockerize: true
serverless-step-functions
StepFunctionsをserverlessでデプロイするために、serverless-step-functionsを使いました。