はじめに
『機械学習のエッセンス(http://isbn.sbcr.jp/93965/)』のPythonサンプルをJuliaで書き換えてみる。(第05章07サポートベクタマシン)の続きです。
k-Means法について
k-Meansのアルゴリズム
- 各点$x_i$に対してランダムにクラスタを割り振る
- 収束するまで以下を繰り返す。
- 各クラスタに割り当てられた点について重心を計算する。
- 各点について、上記で計算された重心からの距離を計算し、距離が一番近いクラスタに当て直す。
- 収束条件は、点のクラスタへの所属情報が変化しない場合、または所属情報の変化が一定の割合以下である場合というのを使う。
- 距離はユークリッド距離を採用する。
- $j$番目のクラスタに属する点のインデックスの集合を$I_j$とすると、アルゴリズム中で必要になるクラスタの重心$G_j$は次の式で表される。
G_j = \frac{1}{|I_j|}\sum_{i \in I_j}x_i
データ構造の説明
特徴量行列がXで与えられ、各点のクラスタへの所属がlabelsに入っているとする。
配列の作成
julia> X = [1 2; 2 3; 3 4; 4 5; 5 6; 6 7; 7 9]
7×2 Array{Int64,2}:
1 2
2 3
3 4
4 5
5 6
6 7
7 9
julia> labels = [0, 1, 2, 0, 1, 2, 0]
7-element Array{Int64,1}:
0
1
2
0
1
2
0
クラスタ0に関する点のみを取り出す
julia> X[labels .== 0, :]
3×2 Array{Int64,2}:
1 2
4 5
7 9
重心の計算
julia> using Statistics
julia> mean(X[labels .== 0, :], dims=1)
1×2 Array{Float64,2}:
4.0 5.33333
クラスタの中心
julia> cluster_centers = [1 1; 2 2; 3 3]
3×2 Array{Int64,2}:
1 1
2 2
3 3
距離の2乗
Pythonのサンプルでは3次元配列に変換していますが、Juliaでは配列の持ち方がPythonとは異なるため同じ方法は使えなさそうでした。代わりに、リスト内包表記で同じことができました。
julia> [sum((X[i, :] .- cluster_centers[j, :]).^2) for i in 1:size(X)[1], j in 1:size(cluster_centers)[1]]
7×3 Array{Int64,2}:
1 1 5
5 1 1
13 5 1
25 13 5
41 25 13
61 41 25
100 74 52
処理を分割した場合
これはPythonとは方法が違うので省略します。
クラスタ中心のインデックス番号
一旦、距離の2乗の結果を変数sに格納します。
julia> s = [sum((X[i, :] .- cluster_centers[j, :]).^2) for i in 1:size(X)[1], j in 1:size(cluster_centers)[1]]
7×3 Array{Int64,2}:
1 1 5
5 1 1
13 5 1
25 13 5
41 25 13
61 41 25
100 74 52
julia> argmin(s, dims=2)
7×1 Array{CartesianIndex{2},2}:
CartesianIndex(1, 1)
CartesianIndex(2, 2)
CartesianIndex(3, 3)
CartesianIndex(4, 3)
CartesianIndex(5, 3)
CartesianIndex(6, 3)
CartesianIndex(7, 3)
結果としては、CartesianIndexという多次元のインデックスが返ってきます。
https://docs.julialang.org/en/v1/base/arrays/index.html#Base.IteratorsMD.CartesianIndex
本と同じような列番号だけの取得は下記のようにしました。もっといい方法があるかもしれません。
julia> [x[2] for x in argmin(s, dims=2)]
7×1 Array{Int64,2}:
1
2
3
3
3
3
3
k-Meansの実装
module kmeans
using Random
using Statistics
using Base.Iterators
mutable struct KMeans
n_clusters
max_iter::Int
rng_::MersenneTwister
labels_
cluster_centers_
function KMeans(n_clusters)
rng = MersenneTwister(0)
new(n_clusters, 1000, rng, Nothing, Nothing)
end
end
function fit(obj::KMeans, X)
cycle = Iterators.cycle(collect(1:obj.n_clusters))
obj.labels_ = collect(Iterators.take(cycle,size(X)[1]))
shuffle!(obj.rng_, obj.labels_)
labels_prev = zeros(size(X)[1])
count = 0
obj.cluster_centers_ = zeros(obj.n_clusters, size(X)[2])
while (!all(obj.labels_ .== labels_prev) && count < obj.max_iter)
for i in 1:obj.n_clusters
XX = X[obj.labels_ .== i, :]
obj.cluster_centers_[i, :] = mean(XX, dims=1)
end
dist = [sum((X[i, :] .- obj.cluster_centers_[j, :]).^2)
for i in 1:size(X)[1], j in 1:size(obj.cluster_centers_)[1]]
labels_prev = obj.labels_
obj.labels_ = vec([x[2] for x in argmin(dist, dims=2)])
count += 1
end
end
function predict(obj::KMeans, X)
dist = [sum((X[i, :] .- obj.cluster_centers_[j, :]).^2)
for i in 1:size(X)[1], j in 1:size(obj.cluster_centers_)[1]]
labels = argmin(dist)
end
end
include("./kmeans.jl")
using .kmeans
using Random
using Plots
Random.seed!(0)
points1 = randn(50, 2)
points2 = randn(50, 2) .+ [5 0]
points3 = randn(50, 2) .+ [5 5]
points_noshuffle = vcat(points1, points2, points3)
points = points_noshuffle[shuffle(1:end), :]
model = kmeans.KMeans(3)
kmeans.fit(model, points)
p1 = points[model.labels_ .== 1, :]
p2 = points[model.labels_ .== 2, :]
p3 = points[model.labels_ .== 3, :]
scatter(p1[:, 1], p1[:, 2], color=:black, markershape=:+)
scatter!(p2[:, 1], p2[:, 2], color=:black, markershape=:star6)
scatter!(p3[:, 1], p3[:, 2], color=:black, markershape=:circle)
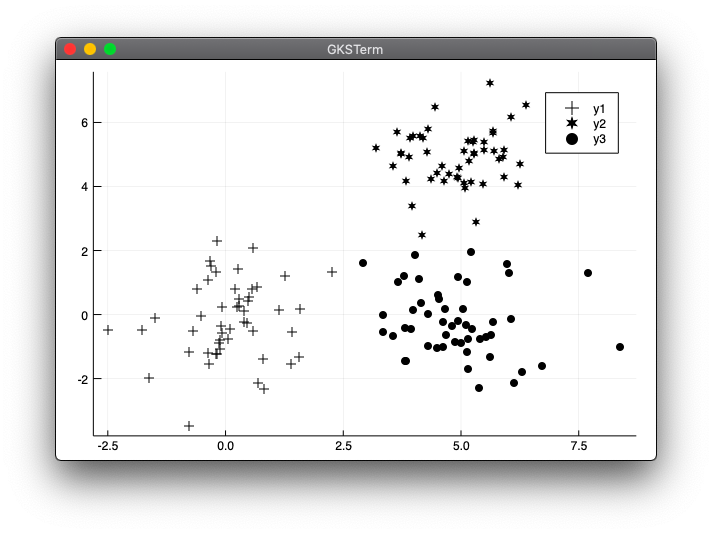
実行結果
julia> include("kmeans_tets1.jl")
補足
shuffle関数について
配列の内容をシャッフルする関数shuffleはJuliaにもありました。
https://docs.julialang.org/en/v1/stdlib/Random/index.html#Random.shuffle
Pythonのサンプルの場合、2次元配列で配列の配列なので、1次元配列の中身はそのままでシャッフルされます。行列に例えると列の値は保持したまま行だけシャッフルされる感じです。
しかしJuliaの場合、すべての値がシャッフルされてしまいました。
julia> a = [1 2; 3 4; 5 6]
3×2 Array{Int64,2}:
1 2
3 4
5 6
julia> using Random
julia> shuffle(a)
3×2 Array{Int64,2}:
4 5
1 2
3 6
そこで列だけ保持したままシャッフルするために下記のようにしました。
julia> a[shuffle(1:end), :]
3×2 Array{Int64,2}:
3 4
5 6
1 2
これは調べていたところ同じような質問がstackoverflowにあり参考にしました。
https://stackoverflow.com/questions/40804573/julia-how-to-shuffle-matrix