前回の投稿(未読の方はぜひこちらからご覧ください!)ではSpot Oceanの基本機能に触れ、Spot Oceanがどのようにインスタンスコストを最適化するのかといったテーマで検証を行いました。
今回はそんなSpot Oceanをもっと賢く使うためのTipsということで、Virtual Node Groupsという機能にフォーカスを当ててみたいと思います。
Spot OceanはAWS/Azure/Google Cloudに対応していますが、本記事ではAWSをベースに記載しています。AWS以外をご利用の方は、適宜用語を読み替えてください。
本投稿の要約
- Virtual Node Groups(以下、VNG)はSpot Oceanの独自機能
- VNGによってSpot Oceanが動的に払い出すk8sノードを役割ごとにグループ分けすることができる
- VNGを分割することによって、VNGに閉じた範囲でインスタンスコストの最適化が行われる様になる
- VNGを分割することによって、VNGごとに個別のノード設定を持つことができる(最大/最小ノード数、使用するサブネット、セキュリティグループ、Spotインスタンスの利用有無など)
- 主に単一のk8sクラスタ内で特性の異なるノードやワークロードが混在するシチュエーションで便利に使えそう
- VNGはSpotコンソールまたはAPIで作成する
- 各VNGへのワークロードの払い出しはnodeSelector/nodeAffinityやtaint/tolerationsなどのk8s標準機能で制御する
Virtual Node Group(VNG)とは
一言でVNGを説明すると、Spot Oceanによって管理されるk8sクラスタ内のノードを役割ごとにグループ化する機能です。
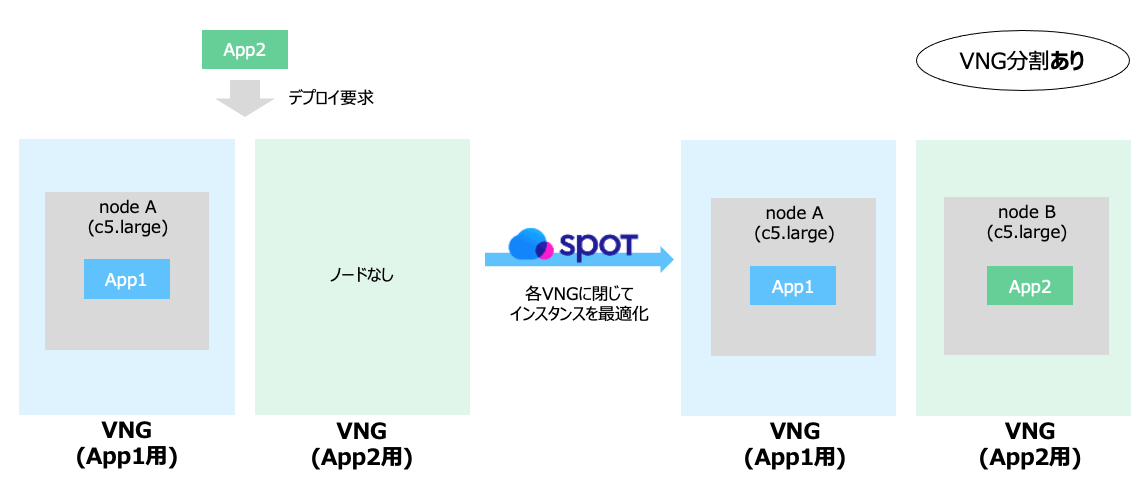
VNGを分割しない場合、Spot Oceanはクラスタ内の全てのワークロード(pod等)の必要リソースを合算し、最もコスト効率が良くなる様に動的にノード(=EC2などのクラウドインスタンス)を最適化します。
傾向としてはクラスタ内の各インスタンスサイズは大きく、インスタンス数は少なくなります。

一方でVNGを分割することで、Spot Oceanによるノード最適化の範囲を任意のノードグループ内に制限することができます(↑のVNG分割なしパターンの様にApp1用、App2用のそれぞれのVNGを跨いでインスタンスが統合されることはない)
傾向としてはクラスタ内の各インスタンスサイズは小さく、インスタンス数は多くなります。またこの傾向はVNGを分割するほど、強くなります。
VNGを分けるメリット
- VNGごとに異なるノード設定を持つことができる
- 接続するサブネット
- セキュリティグループ
- VNG内に払い出すノード数の上限/下限
- スケールダウンの無効化
- マシンのOS(Linux or Windows)
- マシン起動時に実行するスクリプト(Startup Script)
- Spot Oceanが自動購入するインスタンスタイプ
- Spotインスタンスの利用有無
- ヘッドルーム
- ノードごとにあらかじめ余剰リソースを確保するSpot Ocean独自の機能
- 特定のワークロードを予め別VNGに隔離しておくことで、インスタンスコストの最適化に伴うpodの再起動を抑止できる
- 前回の投稿の通り、Oceanクラスタではリソースの需要増減に伴い、podの削除->インスタンス構成最適化->新たなインスタンス上でpod再起動というサイクルが絶えず行われます。結果として、リソース需要がめまぐるしく増減するような環境ではクラスタ内のあらゆるpodが頻繁に再起動されるというシチュエーションも考えられます。
- こうした環境では例えば「リソース需要増減が顕著なpod群を配置するためのVNG」と「リソース需要が安定しているpod群を配置するためのVNG」という様にVNGを分割することで、リソース需要が安定しているpod群の再起動を極力抑制することができます
VNGを分けるデメリット
- VNGの設定内容、ワークロード(pod)の負荷状況、Spotインスタンスの価格推移、etcによってはSpot Oceanによるコスト削減効果が落ちる場合がある
- VNGを細かく分割するほど、小さいサイズのインスタンスが沢山できる傾向になる。インスタンスが増えるほどOSレイヤのオーバーヘッドやkubelet,daemonSet等によって消費されるマシンリソースの割合が増えることになるので、結果としてユーザが使えるリソースが減少する。
- ただしSpot Oceanで主に用いられるSpotインスタンスの価格自体が固定ではないため、必ずしも「VNGを分割した場合の方がコストパフォーマンスが悪くなる」とも言い切れない
ユースケース(VNGの分割例)
- アプリケーション単位で分ける(App1/App2/App3…)
- 環境単位で分ける(dev/test/prod…)
- ワークロードの特性で分ける(パフォーマンス要件、通信先、リソース需要の増減度合い…)
- インスタンスのハードウェア種別で分ける(CPUノード/GPUノード…)
VNGへのワークロードのスケジューリング方法
Spot OceanのVNGはあくまでノード最適化の範囲を論理的に分割するというのが主な機能になります。
一方でワークロード(pod等)をどのVNG上にデプロイするかという制御は、nodeSelector/nodeAffinityならびにtaint/tolerationsといったk8s標準の仕組みを活用することが前提となっています。
具体的には以下の流れで各VNGにpod等をスケジューリングできます
- SpotコンソールまたはAPI経由で、VNGごとに固有のlabelsならびにtaintsを付与する
- ワークロードにnodeSelector(またはnodeAffinity)とtolerationsを付与してデプロイ

使ってみた
本記事では、AWS上にEKSクラスタをデプロイして検証を行っていきます。
他のk8s環境(AKS,GKS等)では実際の設定内容と異なる場合があります。
テスト用VNGの作成
今回はテスト用に以下2つのVNGを作成します。VNGの作成はSpotコンソールまたはAPIのいずれかで実施できますが、今回はSpotコンソールを使用して設定してみます。
-
VNG1
- label
- app: demo1
- owner: netapp
- taint
- demo1-only: true
- 最大ノード数: 10
- label
-
VNG2
- label
- app: demo2
- owner: netapp
- taint
- demo2-only: true
- 最大ノード数: 20
- label
まずはSpotコンソールにログインし、画面左のメニューからOcean -> 対象のk8sクラスタを選択します。

クラスタの管理画面からVirtual Node Groupsタブに移動して、 + Create VNGをクリックします。
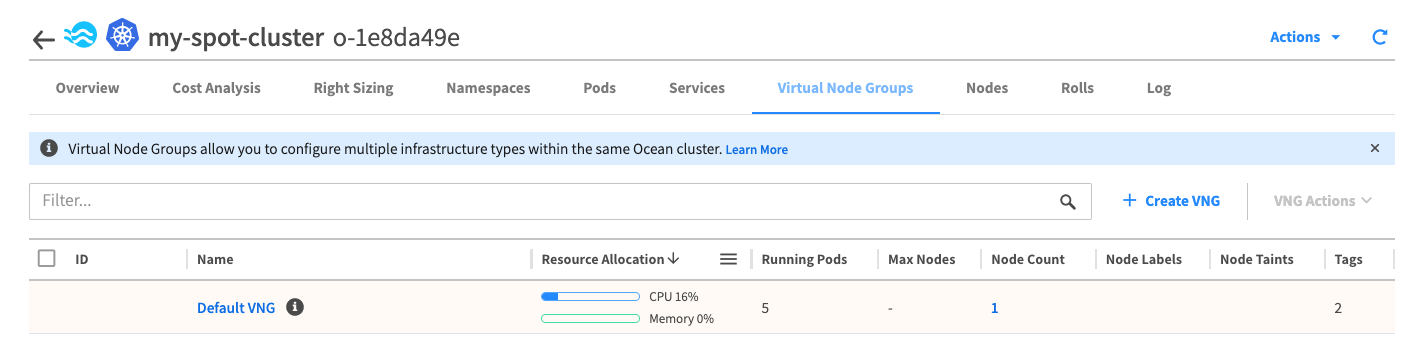
ちなみにOceanにk8sクラスタを追加した時点で、以下画像の様に「Default VNG」という名前のVNGが自動作成されています。
VNGの作成ウィザードに従って、設定値を入力します。
この際、「Taken from default VNG」と記載されている項目はこのウィザード上で明示的に設定値を上書きしない限り、先ほどの「Default VGN」から設定値が継承される仕様となっています。
今回は基本的に「Default VGN」の設定値を継承していく方針で、個別設定が必要な項目だけを入力していきます。

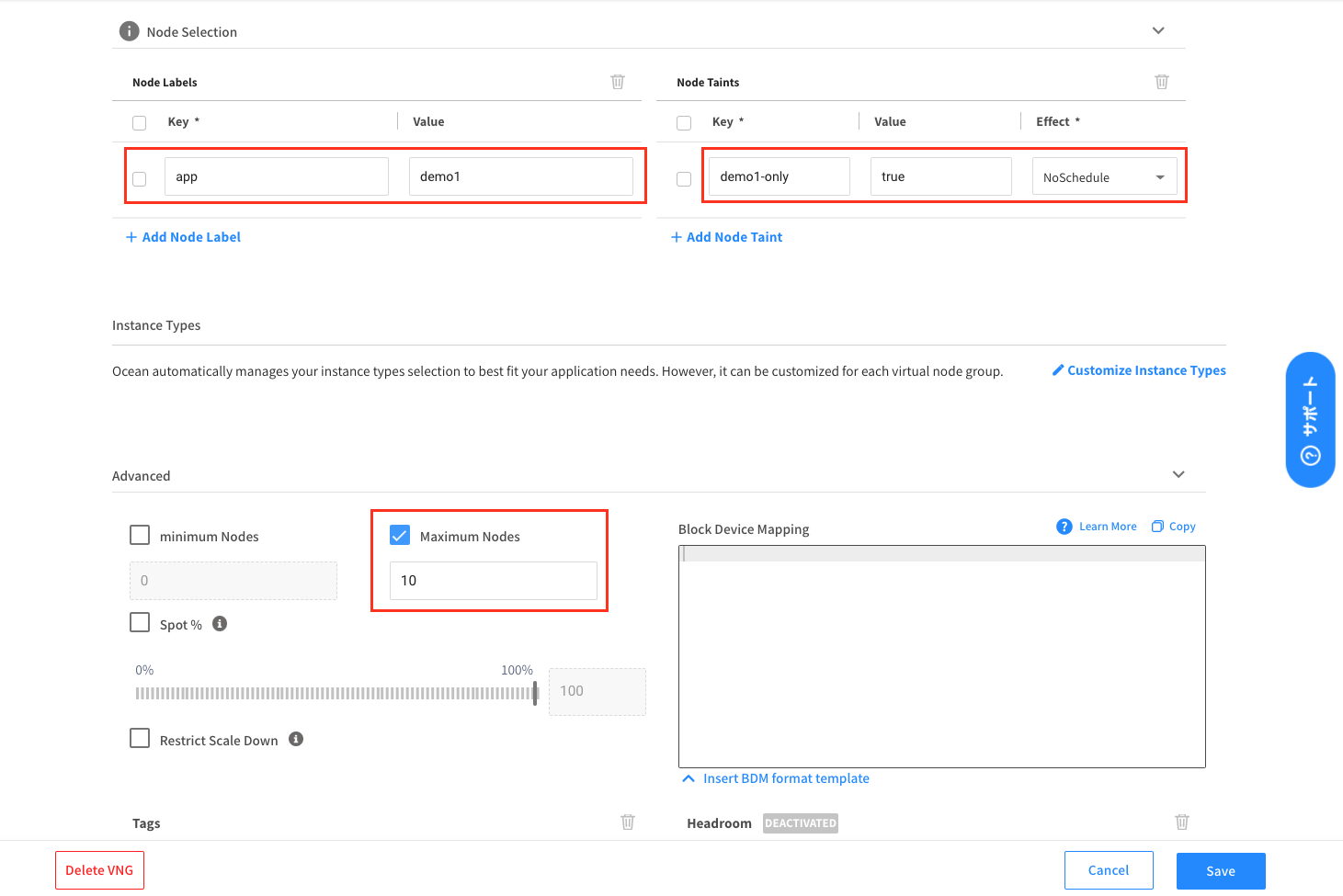
さらに下にスクロールして、ノードに設定するlabelとtaint、このVNG内に払い出せる最大ノード数を入力します。
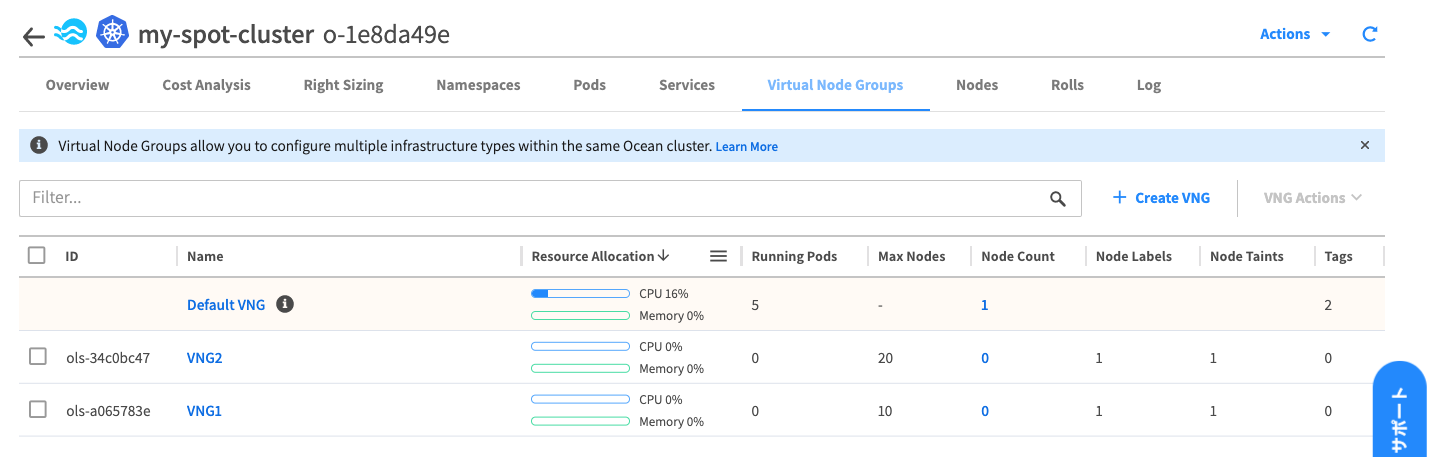
VNG2も同様の手順で作成すると以下の様な状態になりました。
現時点では各VNG上にワークロードを作成していないため、VNG1とVNG2のNode Countはゼロとなっています。
VNGへのワークロードのデプロイ
まずは"VNG1"に対してpodを払い出します。
VNG作成時に設定したlabelsとtaintを考慮して、マニフェストを以下の様に作成します。
# VNG1にpodを払い出すためのマニフェスト
apiVersion: v1
kind: Pod
metadata:
name: demo1
spec:
containers:
- name: nginx
image: nginx:latest
resources:
requests:
cpu: "1000m"
nodeSelector: # VNGの作成時に指定したノードのlabelsを指定
app: demo1
tolerations: # VNGの作成時に指定したノードのtaintに対応するtolerationsを指定
- key: "demo1-only"
operator: "Equal"
value: "true"
effect: "NoSchedule"
初期状態ではマニフェストで指定した条件(nodeSelectors)に合致するノードが1つもないため、podのステータスは一旦pendingになります。しかし数分待つことでSpot Oceanによりノードが動的に払い出され、最終的にpodは無事Runningに遷移します(Spot Oceanの基本動作)
# マニフェストの適用
$ kubectl apply -f pod-demo1.yaml
pod/demo1 created
# 初期時点では"app: demo1"というラベルを持つノードが存在しないため、podはPendingとなる
$ kubectl get node -l app=demo1
No resources found
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
demo1 0/1 Pending 0 6s
# そのまま数分待つとSpot Oceanにより"app: demo1"というラベルを持つノードが払い出される
$ kubectl get node -l app=demo1
NAME STATUS ROLES AGE VERSION
<VNG1のノード1台目> Ready <none> 43m v1.18.9-eks-d1db3c
# "app: demo1"というラベルを持つノード上にpodがスケジューリングされる
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
demo1 1/1 Running 0 21h 172.31.22.85 <VNG1のノード1台目> <none> <none>
Spotコンソールを見ると、VNG1のNode Countが0->1に増えています。
意図した通り、VNG1に対してpodを払い出すことができた様です。

同様にVNG2に対してもpodを払い出します。
# VNG1にpodを払い出すためのマニフェスト
apiVersion: v1
kind: Pod
metadata:
name: demo2
spec:
containers:
- name: nginx
image: nginx:latest
resources:
requests:
cpu: "1000m"
nodeSelector: # VNGの作成時に指定したノードのlabelsを指定
app: demo2
tolerations: # VNGの作成時に指定したノードのtaintに対応するtolerationsを指定
- key: "demo2-only"
operator: "Equal"
value: "true"
effect: "NoSchedule"
# マニフェストの適用
$ kubectl apply -f pod-demo1.yaml
pod/demo1 created
# Spot Oceanが"app=demo2"というラベルを持つノードを払い出し
$ kubectl get node -l app=demo2
NAME STATUS ROLES AGE VERSION
<VNG2のノード1台目> Ready <none> 82s v1.18.9-eks-d1db3c
# "app=demo2"というラベルを持つノード上にpodがスケジューリングされる
$ kubectl get pod demo2 -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
demo2 1/1 Running 0 21h 172.31.31.129 <VNG2のノード1台目> <none> <none>
Podの払い出しが完了し、VNG2のNode Countも0->1に増えました。

前回の投稿ではpodを複数作成した際、Spot Oceanが特定のインスタンスにクラスタ内の全てのpodをどんどん集約していく様子が見られました。
一方で今回はVNG1/VNG2にそれぞれpodをデプロイした後もそのような挙動は見られません。VNG1/VNG2にデプロイしたpod同士はそれぞれ別のノード上で稼働し続けています。
これがまさしくVNGを分割した際の挙動であり、Spot Oceanが各VNGに閉じた範囲でノードの最適化を行なっていることを示しています。
補足: VNG間の優先順位について
ここまでは各VNGを明示的に指定する様に、podのマニフェストにnodeSelectorsやtolerationsを設定してきました。一方で例えば以下の様なマニフェストでpodを作成するとどうなるでしょうか?
nodeSelectorにVNG1/VNG2で共通のラベル(owner=netapp)を指定し、tolerationsもVNG1/VNG2双方のtaintを受け入れる内容になっています。つまりこのpodはVNG1/VNG2のどちらにもスケジューリングされる可能性があります。
apiVersion: v1
kind: Pod
metadata:
name: demo3
spec:
containers:
- name: nginx
image: nginx:latest
resources:
requests:
cpu: "1000m"
nodeSelector: # VNG1/VNG2共通のlabelを指定
owner: "netapp"
tolerations: # VNG1/VNG2のtaintをどちらも受け入れる
- key: "demo1-only"
operator: "Equal"
value: "true"
effect: "NoSchedule"
- key: "demo2-only"
operator: "Equal"
value: "true"
effect: "NoSchedule"
結果としては、VNG2に作成されました。
# podの作成
$ kubectl apply -f pod-demo3.yaml
pod/demo3 created
# podの作成状況確認
# 今回作成したdemo3は"VNG2"上に作成されている
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
demo1 1/1 Running 0 21h 172.31.22.85 <VNG1のノード1台目> <none> <none>
demo2 1/1 Running 0 21h 172.31.31.129 <VNG2のノード1台目> <none> <none>
demo3 1/1 Running 0 7m11s 172.31.7.127 <VNG2のノード2台目> <none> <none>

k8sのスケジューラではノードのスコアリングによってpodをデプロイするノードを決定しますが、上記の挙動はまたそれとは異なるSpot Oceanの仕様によるものです。
Spot Oceanがpodをデプロイする際にどのVNGを使うかを決定するロジックはこちらのドキュメントに記載があります。
ざっくり意訳すると、
- nodeSelector, tolerations等によって対象のVNGが一つに絞り込める場合はそのVNGを使用する(今回でいうところのpod:demo1,demo2)
- 対象のVNGが1つに絞りきれない場合は以下の優先度で対象のVNGを選定する(今回でいうところのpod:demo3)
- VNG内にデプロイできる最大ノード数
- Spotインスタンスの利用率
- 利用できるAZの数
- 利用できるインスタンスタイプの数
今回は各VNGにデプロイできる最大ノード数は以下の様になっていました。
- VNG1: 10ノード
- VNG2: 20ノード
つまり上記項番1の最大ノード数の比較によってVNG2がより優先度の高いVNGとして選定されたという事になります。
おわり
VNGを作成せずに検証した前回投稿では、クラスタ内のpodがかなり目まぐるしくノード間を移動する(再起動する)なという印象を受けました。
Spot Oceanを使用してインスタンスコストを削減する上である程度は受け入れなくてはいけない部分ではあるのですが、実運用上はあまりダイナミックにpodが動かれ過ぎても困ってしまう、というのも正直なところではあると思います。
そうした場面で、今回投稿の様にVNGを活用してSpot Oceanの影響範囲を分割するというアプローチはきっと役立つかと思います。ぜひお試しください。
Spot Oceanに関する他の記事