結論
フィールド名一覧を取得する1には、dataclasses.fields を使いましょう。
from typing import ClassVar
from dataclasses import dataclass, fields
@dataclass
class MyDataClass:
x: int
y: str
default_val: str = "hoge"
classvar_any = 10
classvar_annotated: ClassVar[int] = "fuga"
all_field_names = [field.name for field in fields(MyDataClass)]
# => ['x', 'y', 'default_val']
Field オブジェクトとして一覧が得られるので .name でアクセスします。
生成AIに「Pythonでdataclassのフィールド名一覧を取得する方法は?」と質問すると結構な確率で __dataclass_fields__ を使うよう回答してくる2のですが、これは公式に用意されたインターフェースではなく3、また dataclasses.fields と微妙に挙動の違いがあり意図しない動作の元になるため、使わない方が良いです。
生成AIの回答例:
より高級なモデルほど __dataclass_fields__ への"こだわり"が薄れていく傾向にあります4。
Google の AI 要約
がっつり __dataclass_fields__ の使用を勧めてくる(回による)
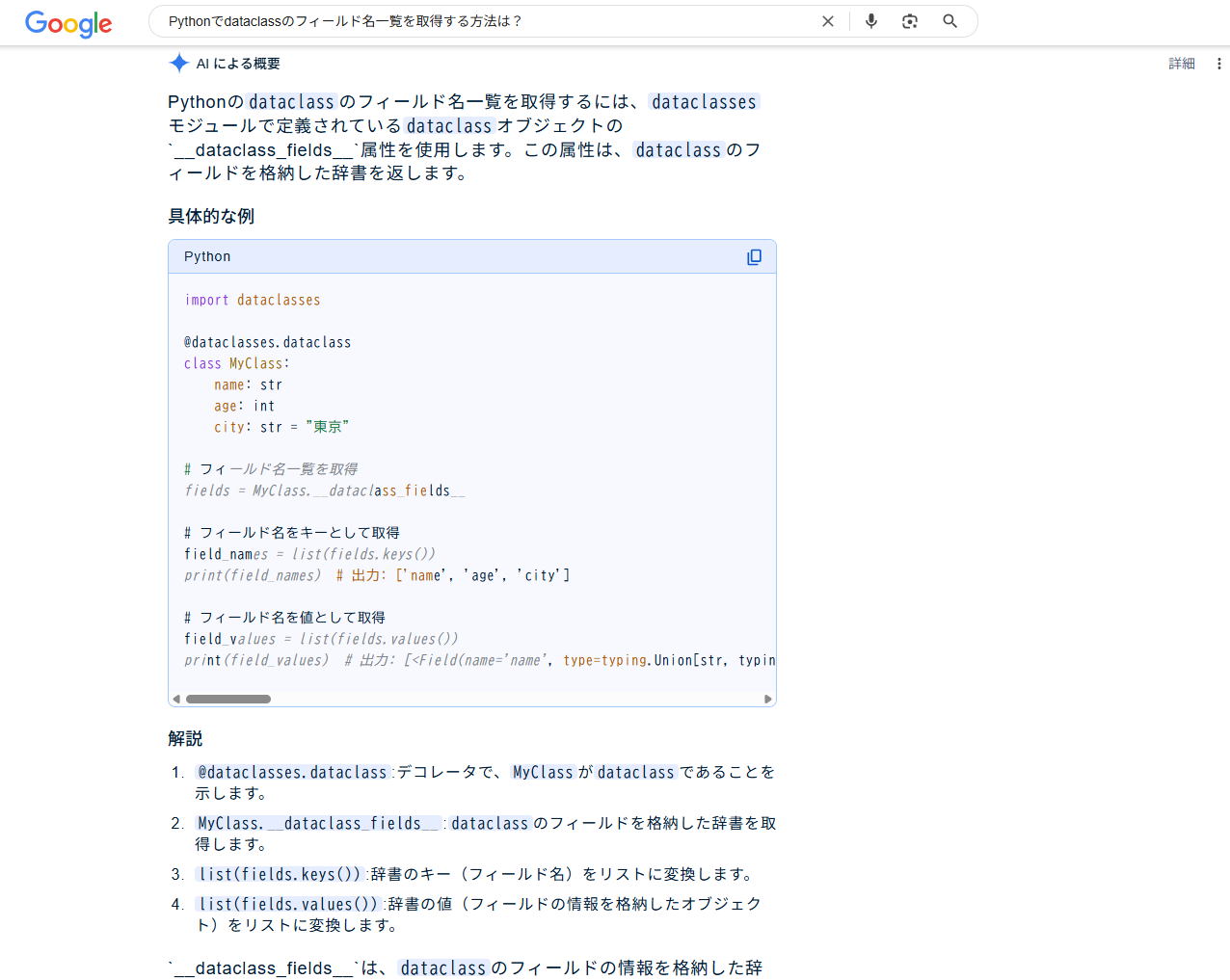

ChatGPT (o4-mini)
dataclasses.fields と __dataclass_fields__ の二択を提示
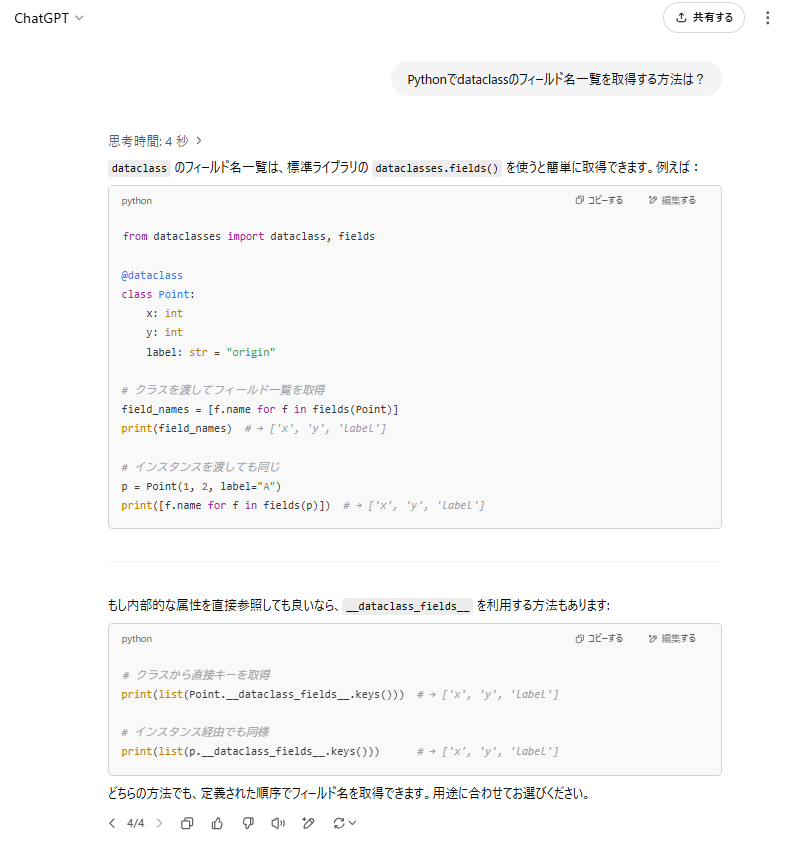
ChatGPT (4o)
サブの選択肢として __dataclass_fields__ も提示(どちらの方法でも同じというのは誤り)
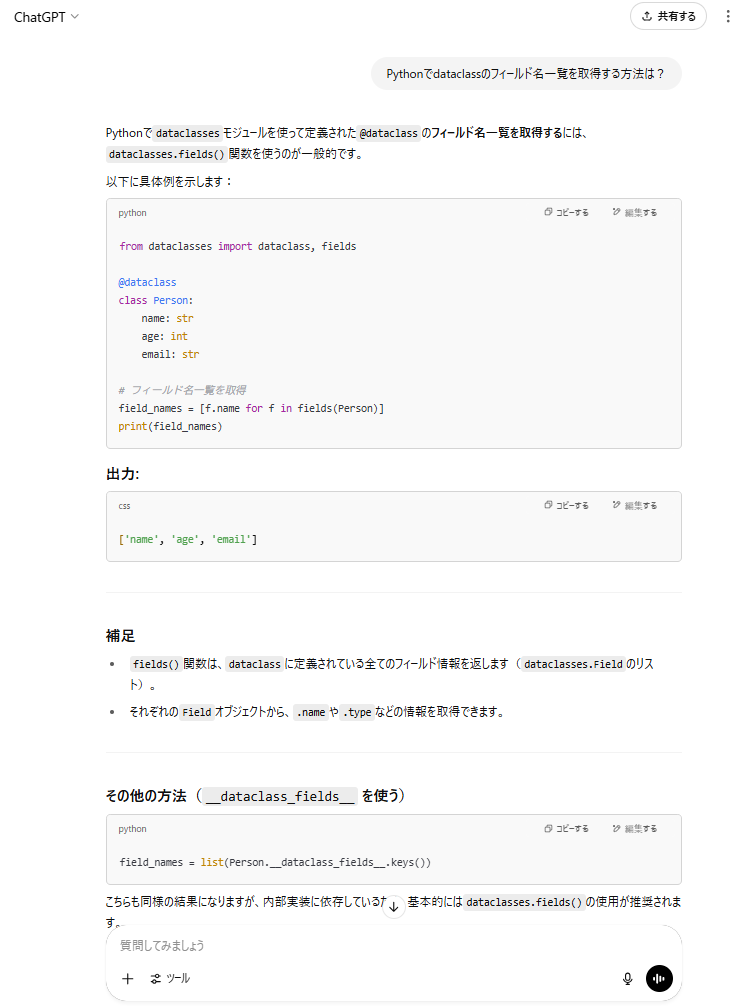
Gemini (2.5 Flush)
__dataclass_fields__ への言及なし
挙動の差
__dataclass_fields__ は「型アノテーションをつけたクラス変数」が除外されません。
型アノテーションの有無で挙動が変わるというのはデータ構造として望ましくないので、型アノテーションあり・なしの両方とも除外される dataclass.fields の方が"正常な"挙動といっていいでしょう。
>>> fields(MyDataClass)
(Field(name='x',type=<class 'int'>,default=<dataclasses._MISSING_TYPE object at 0x7f8138fa9e80>,default_factory=<dataclasses._MISSING_TYPE object at 0x7f8138fa9e80>,init=True,repr=True,hash=None,compare=True,metadata=mappingproxy({}),kw_only=False,_field_type=_FIELD), Field(name='y',type=<class 'str'>,default=<dataclasses._MISSING_TYPE object at 0x7f8138fa9e80>,default_factory=<dataclasses._MISSING_TYPE object at 0x7f8138fa9e80>,init=True,repr=True,hash=None,compare=True,metadata=mappingproxy({}),kw_only=False,_field_type=_FIELD), Field(name='default_val',type=<class 'str'>,default='hoge',default_factory=<dataclasses._MISSING_TYPE object at 0x7f8138fa9e80>,init=True,repr=True,hash=None,compare=True,metadata=mappingproxy({}),kw_only=False,_field_type=_FIELD))
>>> [field.name for field in fields(MyDataClass)]
['x', 'y', 'default_val']
>>>
>>> MyDataClass.__dataclass_fields__
{'x': Field(name='x',type=<class 'int'>,default=<dataclasses._MISSING_TYPE object at 0x7f8138fa9e80>,default_factory=<dataclasses._MISSING_TYPE object at 0x7f8138fa9e80>,init=True,repr=True,hash=None,compare=True,metadata=mappingproxy({}),kw_only=False,_field_type=_FIELD), 'y': Field(name='y',type=<class 'str'>,default=<dataclasses._MISSING_TYPE object at 0x7f8138fa9e80>,default_factory=<dataclasses._MISSING_TYPE object at 0x7f8138fa9e80>,init=True,repr=True,hash=None,compare=True,metadata=mappingproxy({}),kw_only=False,_field_type=_FIELD), 'default_val': Field(name='default_val',type=<class 'str'>,default='hoge',default_factory=<dataclasses._MISSING_TYPE object at 0x7f8138fa9e80>,init=True,repr=True,hash=None,compare=True,metadata=mappingproxy({}),kw_only=False,_field_type=_FIELD), 'classvar_annotated': Field(name='classvar_annotated',type=typing.ClassVar[int],default='fuga',default_factory=<dataclasses._MISSING_TYPE object at 0x7f8138fa9e80>,init=True,repr=True,hash=None,compare=True,metadata=mappingproxy({}),kw_only=<dataclasses._MISSING_TYPE object at 0x7f8138fa9e80>,_field_type=_FIELD_CLASSVAR)}
>>> MyDataClass.__dataclass_fields__.keys()
dict_keys(['x', 'y', 'default_val', 'classvar_annotated'])
いかにも dataclass.fields と等価な dunder(特殊メソッド)のような命名の割に中身が違うというのがちょっとした罠ですね。実際には __dataclass_fields__ はアノテーションがついている変数をまとめて保持しておくだけの一時変数であり、fields ではさらに if f._field_type is _FIELD というフィルターでフィールド変数以外を除外する処理が追加されています。