CVPR2026で面白そうなものを紹介するヤツです。
今回はINSIDS3という(追加)学習不要の1-shot Segmentationモデルになります。
INSID3: Training-Free In-Context Segmentation with DINOv3
Cuttano et al. — CVPR 2026 Oral
論文 / プロジェクトページ / コード
はじめに
「この犬をセグメントして」と伝えるとき、人間は参照例を1枚見るだけで即座に理解できます。コンピュータビジョンでこれを実現するのが In-Context Segmentation(文脈内セグメンテーション) です。
従来の最先端手法は DINOv2 + SAM の組み合わせに頼っており、複数モデルの協調が前提でした。INSID3 はその常識を覆します。単一の凍結 DINOv3 バックボーンだけで、参照画像1枚から任意の対象を高精度にセグメントできるのです。
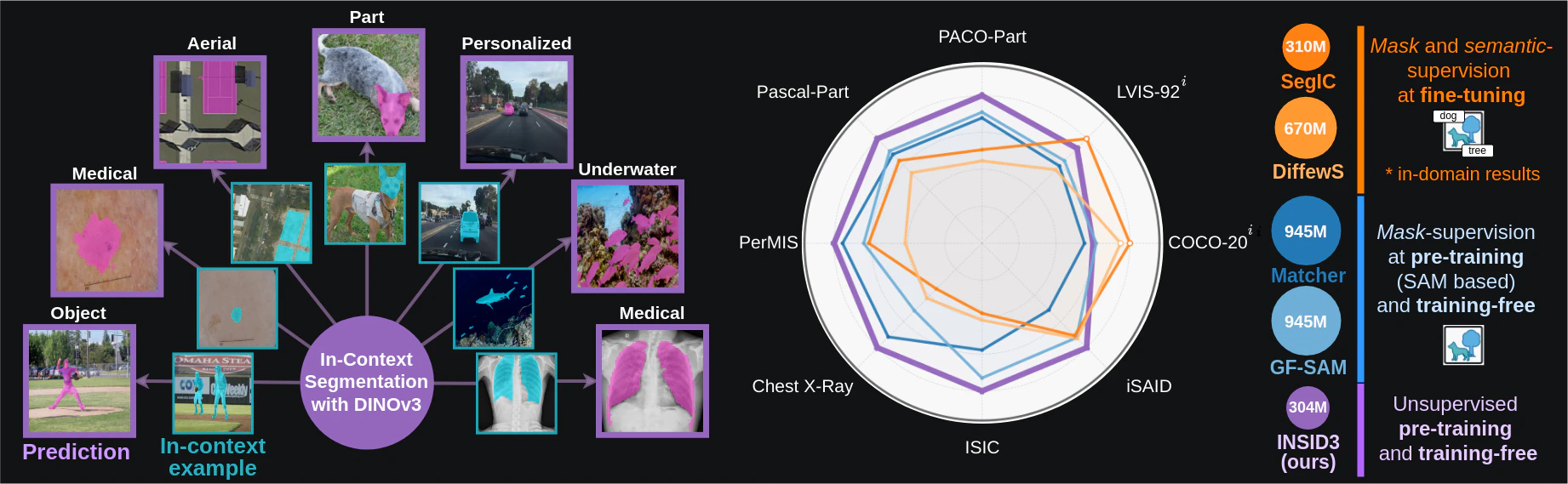
左から:参照画像+マスク → INSID3 → 各種ドメインのターゲット画像に対する予測
INSID3 の特徴
| ポイント | 内容 |
|---|---|
| 学習不要 | fine-tuning・専用セグメンテーション decoder・SAM などの補助モデルは一切不要 |
| 単一 backbone | frozen DINOv3 の dense features だけを使用。複数モデルの協調は不要 |
| 対象の粒度が広い | object-level・part-level・personalized segmentation に対応 |
| ドメイン汎化 | 自然画像・医療・水中・航空写真など幅広いドメインに同一パラメータで適用可能 |
| 位置バイアス補正 | DINOv3 特徴に含まれる絶対位置への反応を低次元部分空間として取り除き、意味的なマッチング精度を向上 |
できること
- 1-shot セグメンテーション:参照画像とそのマスクを1枚渡すだけで動作
- ドメイン不問:自然画像・医療(皮膚病変・胸部X線)・水中・航空写真に同じ設定で対応
- 粒度可変:オブジェクトレベルからパーツレベルまで、ハイパーパラメータの変更不要
- 意味的対応(キーポイントマッチング):参照画像の特定点に対応するターゲット上の点を予測
- 学習・fine-tuning 不要:推論のみで動作し、新しいクラスやドメインへ即時適用可能
問題設定
In-Context Segmentation とは
与えられた「コンテキスト例」(参照画像+マスク)を手がかりに、ターゲット画像内の同種領域を検出・セグメントするタスクです。
入力: ref_image, ref_mask, target_image
出力: target_mask(ターゲット内の同クラス領域)
Few-shot セグメンテーションの一種ですが、タスク定義を文脈として注入する点が特徴で、学習時に見ていないクラスやドメインにも汎化します。
従来手法の課題
| アプローチ | 代表手法 | 強み | 弱み |
|---|---|---|---|
| Fine-tuning ベース | SegIC, DiffewS | ドメイン内で高精度 | 未知ドメインで性能劣化・再学習コスト |
| SAM パイプライン | Matcher, GF-SAM | 汎化性 | 計算コスト大・粒度固定・複数モデル必要 |
| INSID3(提案) | — | 高速・軽量・高精度 | — |
GF-SAM(DINOv2 + SAM)は 945M パラメータ、0.97 FPS。
INSID3 は 304M パラメータ、3.31 FPS でこれを大幅に上回ります。
核心アイデア:Positional Bias の発見と除去
DINOv3 に潜む位置バイアス
INSID3 の最大の貢献は、DINOv3 の特徴量における 未報告の Positional Bias(位置バイアス) の発見です。
Positional Bias とは:参照画像のあるパッチ特徴が、意味的内容に関係なく、ターゲット画像の「同じ位置」に偽の高活性化を示す現象です。
たとえば、参照画像の左上にある犬の鼻に対応する特徴量が、ターゲット画像でも「左上付近」で高い類似度を示してしまいます。その結果、意味的に無関係な領域が誤ってマッチングされます。
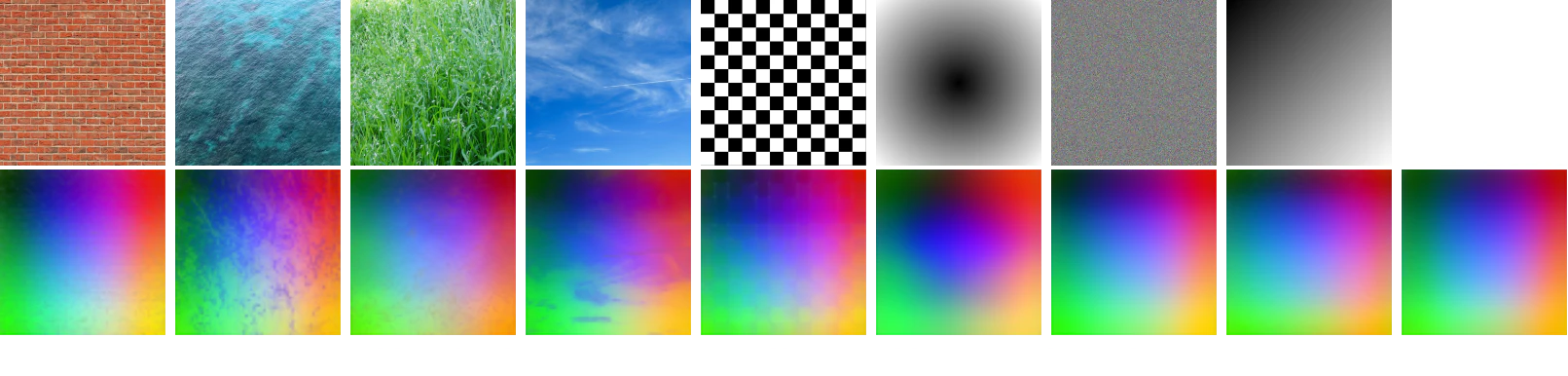
ガウスノイズをエンコーダに入力したときの特徴量(位置バイアスのみが表れる)を PCA で可視化
この現象は DINOv2 にも存在しますが、DINOv3 ではより顕著です。DINOv3 が採用する 強い local-consistency 目標が密な空間構造を生む一方で、位置情報も強く埋め込まれてしまうという副作用によるものです。
SVD ベースの直交補空間射影で解決
位置バイアスを除去するために、以下のシンプルな手順を踏みます。
ステップ 1:位置情報部分空間の推定
ガウスノイズ画像をエンコーダに通すと、出力は位置情報のみを反映します(意味情報はノイズにより消えるため)。
F_noise = Encoder(N(0,1)) ∈ ℝ^{P×D}
ステップ 2:SVD で位置部分空間の基底を抽出
F_noise = U Σ Vᵀ
B = [v₁, v₂, ..., v₅₀₀] ← 上位 500 右特異ベクトル
ステップ 3:直交補空間に射影(debiasing)
F̃ = F · (I_D - BBᵀ)
この1回の行列乗算で、位置成分を除去しつつ意味情報を保全します。投影行列はオフラインで計算・保存できるため、推論時の追加コストはほぼゼロです。

左:Debiasing なし → 位置バイアスによる誤った高活性化。右:Debiasing あり → 意味的に正しい領域のみに活性化が集中
Debiasing の効果
| 条件 | COCO-20i mIoU | SPair-71k PCK@0.20 |
|---|---|---|
| Debiasing なし | 54.5% | 66.4% |
| Debiasing あり | 57.6% | 68.6% |
| 改善幅 | +3.1% | +2.2% |
除去する成分数(rank)の影響も検証されており、s = 500 が最適です(過小だと除去不足、過大だと意味情報まで失われます)。
アーキテクチャ詳細
全体のパイプラインは 4 ステージで構成されます。
参照画像+マスク
↓
┌─────────────────────────────────────────┐
│ 1. 特徴量抽出(DINOv3-Large、凍結) │
│ → F_ref ∈ ℝ^{P×D}, F_tgt ∈ ℝ^{P×D} │
└──────────────┬──────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 2. Debiasing(直交補空間射影) │
│ F̃ = F · (I_D - BBᵀ) │
└──────────────┬──────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 3. 細粒度クラスタリング │
│ 元の特徴量 F_tgt に Agglomerative │
│ Clustering(τ = 0.6)を適用 │
│ → K 個の意味的領域に分割 │
└──────────────┬──────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 4. シード選択 & クラスタ集約 │
│ debiased 空間での後方最近傍マッチング │
│ S_k = s_k^cross · s_k^intra │
│ → 閾値 α = 0.2 で最終マスク生成 │
└─────────────────────────────────────────┘
↓
予測マスク(元解像度に bilinear アップサンプリング)

Agglomerative Clustering によるターゲット画像の意味的領域分割。各色が1クラスタ。
クラスタ集約スコアの設計
各クラスタ k のスコアは2種類の類似度の積で求めます。
S_k = s_k^cross × s_k^intra
- s_k^cross:debiased 特徴量空間でのクロス画像意味類似度(意味的整合性)
- s_k^intra:元の特徴量空間での intra-image 自己類似度(構造的一貫性)
両者を組み合わせることで、意味的にマッチしつつ空間的に自然なクラスタのみを選択できます。
ハイパーパラメータの統一性
9 つのデータセット、3 種類の粒度、複数ドメインで同一パラメータを使用しています。
| パラメータ | 値 | 意味 |
|---|---|---|
tau (τ) |
0.6 | Agglomerative Clustering の結合閾値 |
alpha (α) |
0.2 | 最終マスク生成の閾値 |
svd_components (s) |
500 | Debiasing で除去する SVD 成分数 |
image_size |
1024 | 入力解像度 |
これらは COCO-20i の 3-fold CV のみで決定され、以後一切変更されていません。
実験結果
One-Shot Semantic Segmentation(表1)
9 データセットでの mIoU 比較(1-shot、ハイパーパラメータ固定):
| データセット | INSID3 | GF-SAM | SegIC | 改善(vs GF-SAM) |
|---|---|---|---|---|
| LVIS-92i | 41.8% | 35.2% | — | +6.6% |
| COCO-20i | 57.6% | 51.9% | — | +5.7% |
| ISIC(皮膚病変) | 54.4% | 48.7% | — | +5.7% |
| Chest X-Ray(胸部X線) | 78.8% | 51.0% | — | +27.8% |
| iSAID(航空写真) | 52.1% | 50.3% | — | +1.8% |
| SUIM(水中) | 54.9% | 53.1% | — | +1.8% |
| 平均 | 55.1% | 48.4% | — | +6.7% |
医療画像(Chest X-Ray)での +27.8% は特に顕著な結果です。DINOv3 の強い汎化性能と debiasing の組み合わせが、学習分布外のドメインで特に効果的であることを示しています。
Part Segmentation(パーツレベル)
| データセット | INSID3 | GF-SAM | SegIC |
|---|---|---|---|
| PASCAL-Part | 50.5% | 44.5% | 39.9% |
| PACO-Part | 38.7% | 36.3% | 25.9% |
Personalized Segmentation(パーソナライズド)
| データセット | INSID3 | GF-SAM | DiffewS |
|---|---|---|---|
| PerMIS | 67.0% | 54.1% | 35.2% |
Semantic Correspondence(SPair-71k、キーポイントマッチング)
Debiasing 技術の汎用性を意味対応タスクでも検証しています:
| Metric | Original | Debiased | 改善 |
|---|---|---|---|
| PCK@0.05 | 30.1% | 33.7% | +3.6% |
| PCK@0.10 | 46.8% | 52.6% | +5.8% |
| PCK@0.15 | 55.6% | 62.5% | +6.9% |
| PCK@0.20 | 61.2% | 68.7% | +7.5% |
推論速度比較
| 手法 | FPS | パラメータ数 |
|---|---|---|
| INSID3 | 3.31 | 304M |
| GF-SAM | 0.97 | 945M |
| Matcher | 0.11 | — |
GF-SAM の 3.4倍高速、Matcher の 29.8倍高速を実現しています。
動作サンプル(RTX 4090 / fp16)
実際にこのリポジトリの実装で動作させた結果を紹介します。
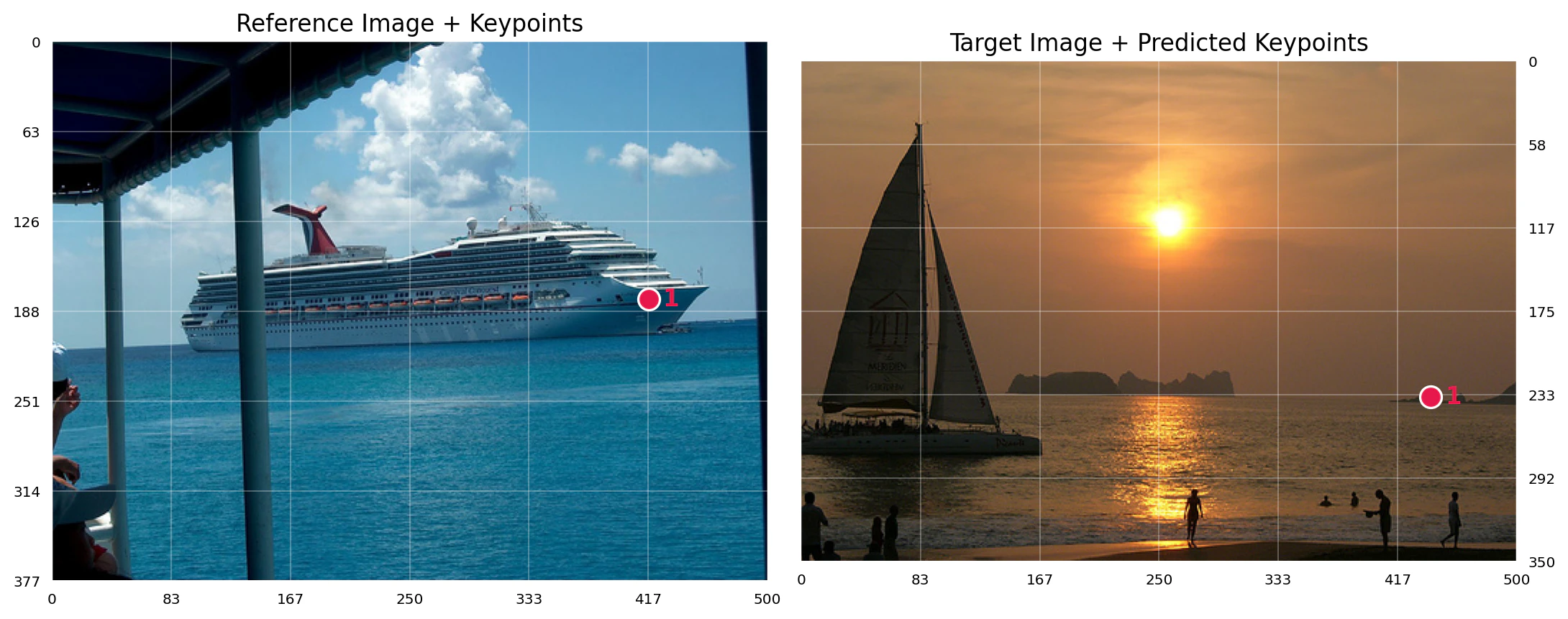
セグメンテーション(猫の例)
公式のサンプルっぽいヤツ①:参照画像にマスクを与え、別の猫画像でセグメンテーションを実行。
実行結果の可視化(左:参照+マスク / 右:ターゲット+予測マスク):

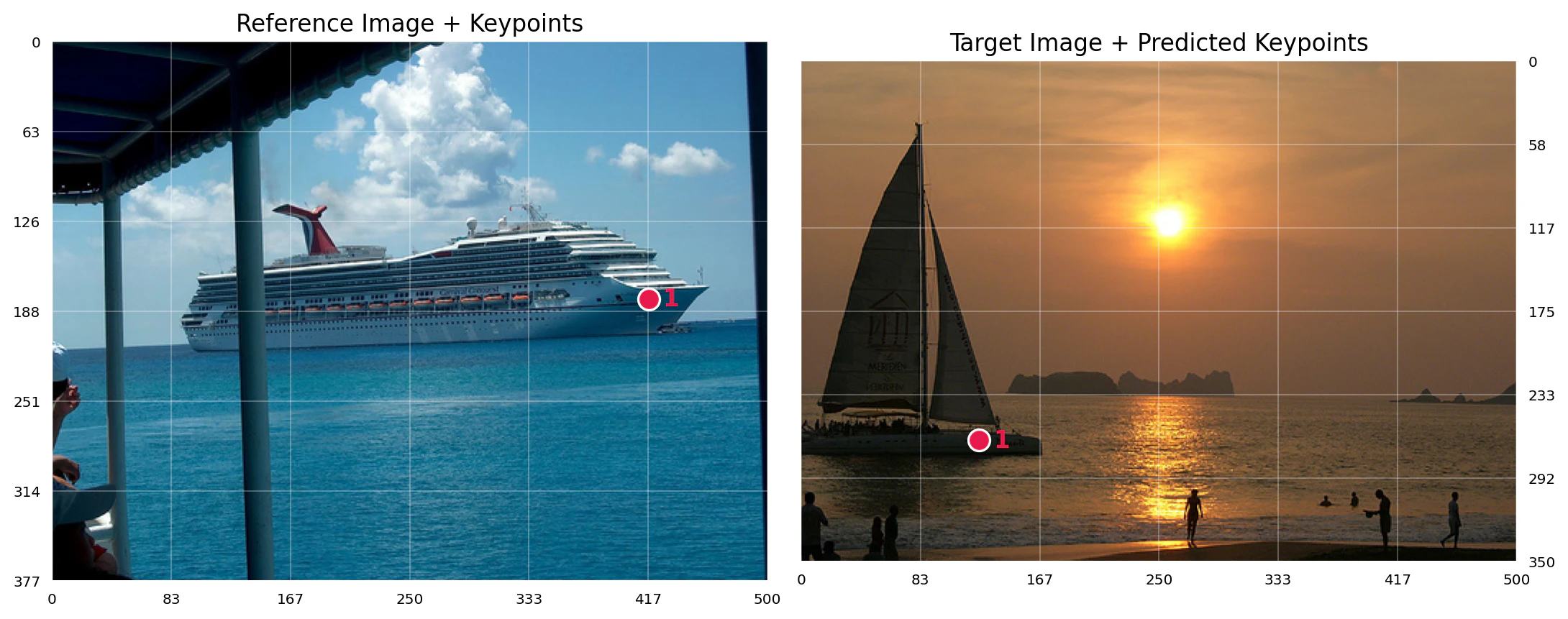
キーポイントマッチング(ボートの例)
公式のサンプルっぽいヤツ②:参照画像上の1点 [417, 180] に対応するターゲット画像上の点を予測します。
可視化(左:参照画像+参照点 / 右:ターゲット画像+予測対応点):

Debiasing の視覚的効果
同じ参照マスクに対して、debiasing の有無でセグメンテーション結果がどう変わるかを比較しています。
| Debiasing なし | Debiasing あり |
|---|---|
 |
 |
Debiasing なし(左)では位置バイアスにより誤った領域が活性化されています。Debiasing あり(右)では意味的に正しい領域のみが検出されています。
追加検証:ペットボトルの複数インスタンス検出
公式のサンプルだけだと面白くないので他でもやってみる。
参照画像として「横たわる青キャップのペットボトル1本」のマスクを与え、異なる2つのターゲット画像でセグメンテーションを検証しました。
参照画像:白背景に横たわるペットボトル(青キャップ)

ケース 1:同種ボトル3本が整列した画像

左:参照画像+マスク / 中:ターゲット画像 / 右:予測結果
3本すべてのボトルが正確にセグメントされています。参照例が1本だけにもかかわらず、同じ概念を持つ複数インスタンスを一度に検出できることが確認できます。
ケース 2:複数本が密集した棚画像

左:参照画像+マスク / 中:ターゲット画像 / 右:予測結果
密集配置・部分的な重なりがある状況でも、ボトル群をまとめてセグメントできています。背景の棚や他の物体との誤検出もなく、ドメイン差(白背景 → 棚環境)への汎化性能が確認できます。
ただ、ラベル部分が検出できていなかったりするので完璧に!とはいかないですね。
ベンチマーク(RTX 4090 実測)
RTX 4090を使用して、手元でテキトーに計測したものです。
| Model | Latency (ms) | VRAM (GB) | Precision | Batch | Input | Device |
|---|---|---|---|---|---|---|
| INSID3 (large) | 306.77 | 1.69 | fp16 | 1 | 1024×1024 | RTX 4090 |
計測条件:Warmup 10 runs → 測定 100 runs 平均。
テンソル事前ロード済みで I/O オーバーヘッドを除外した、純粋な GPU 推論時間です。
torch.cuda.synchronize()+reset_peak_memory_stats()による VRAM 計測。
動作環境
| パッケージ | バージョン |
|---|---|
| torch | 2.7.1+cu126 |
| torchvision | 0.22.1+cu126 |
| einops | 0.8.2 |
| scikit-learn | 1.7.2 |
| Python | 3.10.14 |
| OS | Ubuntu 22.04 |
既存手法との位置づけ
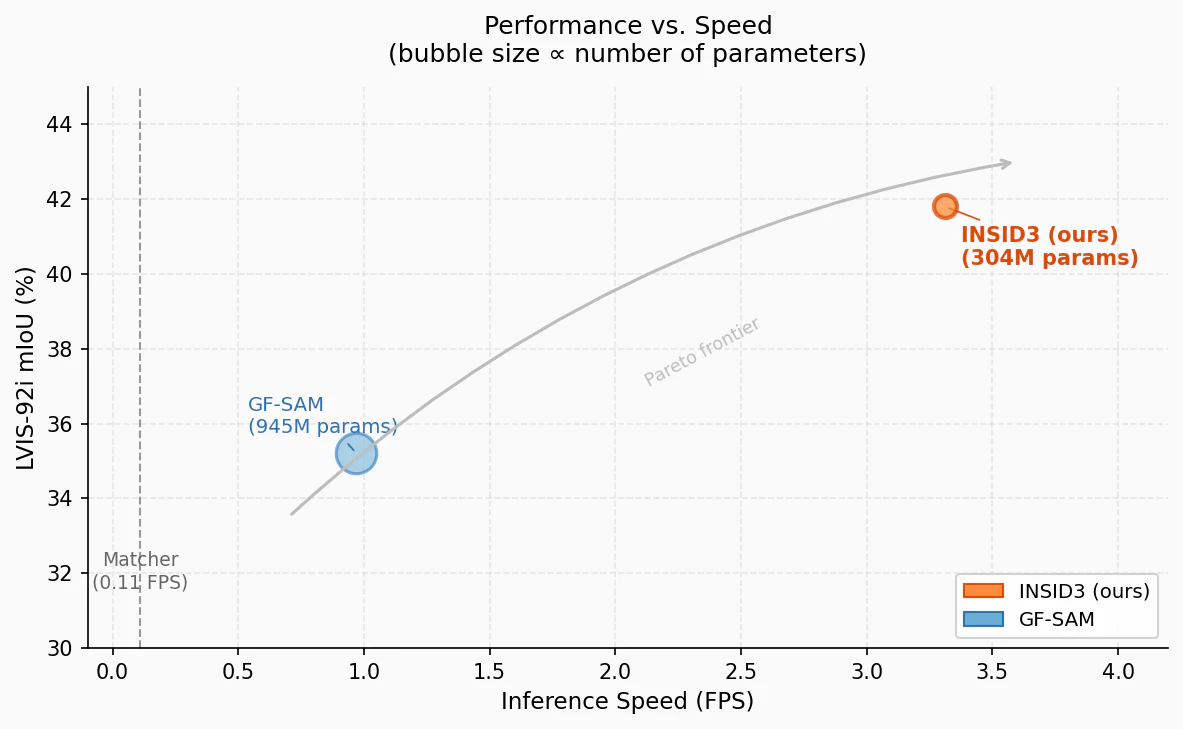
X 軸:推論速度(FPS)、Y 軸:LVIS-92i mIoU(%)、バブルサイズ:パラメータ数に比例。Matcher は mIoU の公表値なし(速度のみ表示)。
INSID3 はパレートフロンティア上に位置し、精度・速度・モデルサイズのすべてにおいて既存手法を上回ります。
INSID3 と SAM 3 の違い
INSID3 をよく知られた SAM 3 と比較です。
一言で表すと、INSID3 は「DINOv3 特徴だけで学習なしに似た概念を切る研究手法」、SAM 3 は「テキスト・点・箱・マスク・画像例示で物体を検出・分割・動画追跡する汎用基盤モデル」 です。
| 観点 | INSID3 | SAM 3 / SAM 3.1 |
|---|---|---|
| 主目的 | 参照例から同じ概念をターゲット画像で切る in-context segmentation | 画像・動画で任意概念を検出、セグメント、追跡する promptable segmentation |
| 入力プロンプト | 参照画像+参照マスクが中心 | テキスト、点、箱、マスク、画像例示など多様な形式に対応 |
| 学習 | 追加学習なし。frozen DINOv3 の特徴をそのまま使う | Meta が大規模データで学習した専用モデル |
| 対象 | 画像中心。object / part / personalized segmentation | 画像と動画。全インスタンス検出、ID 付け、追跡まで対応 |
| 認識能力 | 参照例に似たものを特徴対応で探す | "yellow school bus" のような短い名詞句から open-vocabulary に探せる |
| 構成 | DINOv3 dense features + クラスタリング・特徴処理 | detector + video tracker、共通 backbone、presence head など |
| 強み | 軽量・シンプル・学習不要・研究用途で透明性が高い | 実用寄り・多機能・動画対応・テキスト指定が強い |
| 弱み | 参照マスクが必要になりがち。動画追跡や自然言語指定は主目的でない | モデルが大きく、学習済みシステムへの依存が強い |
どちらを選ぶか
- テキストで「車を全部」「赤いバッグを全部」と指定したい、動画追跡もしたい → SAM 3
- 少数の参照例から同じ物体・部位・個体を学習なしで切り出したい、研究・検証用途 → INSID3
なお、2026年3月には SAM 3.1 も公開されており、複数オブジェクト追跡の効率を上げる "object multiplexing" が追加されています。
考察
なぜ単一バックボーンで十分なのか
DINOv3 は密な自己教師あり学習により、パッチレベルで豊かな意味的・空間的特徴を学習しています。従来は「この特徴量は位置バイアスがあるから使いにくい」と見なされていましたが、INSID3 は逆の発想をとります。「位置バイアスを外科的に除去すれば、残る意味情報は SAM 並みに強力だ」という洞察が核心です。
Debiasing の汎用性
提案の debiasing 手法は INSID3 専用ではありません。任意の Vision Transformer の特徴量に適用できる汎用技術であり、他のドメイン適応タスクや特徴量マッチングタスクへの応用も期待されます。SPair-71k での改善(+7.5% at PCK@0.20)は、セグメンテーション以外でも有効性を示す結果です。
制限事項
- 入力解像度 1024 での Agglomerative Clustering は、超高解像度画像(4K 等)では計算量が課題になります
- 参照マスクが極めて曖昧な場合(複数の解釈が可能な例)では性能が低下することがあります
- 現在は DINOv3-Large の重みのみ対応しています(Base/Small は重みの事前準備が別途必要)
まとめ
INSID3 は「DINOv3 の位置バイアスを SVD で除去する」という一見シンプルなアイデアから出発し、以下を同時に実現しました。
| 観点 | 成果 |
|---|---|
| 精度 | GF-SAM 比 平均 +6.7 mIoU(9 データセット) |
| 速度 | GF-SAM 比 3.4倍高速(3.31 FPS) |
| 軽量性 | GF-SAM 比 704M パラメータ削減(304M) |
| 汎化性 | 医療・航空・水中画像に同一パラメータで対応 |
| 設計の単純さ | DINOv3 のみ・fine-tuning 不要・デコーダ不要 |
「シンプルな仮説の検証が、複雑なエンジニアリングを超える」ことを示した点で、CVPR 2026 Oral 採択は納得の結果と言えます。
参考資料
- 論文: arXiv:2603.28480
- プロジェクトページ: visinf.github.io/INSID3
- 公式コード: github.com/visinf/INSID3
- DINOv3: github.com/facebookresearch/dinov3
- 関連手法 GF-SAM: Gonzalez-Garcia et al., 2024
- 関連手法 SegIC: Wang et al., 2023