CVPR 2024 Day4 AMで気になったpaperを羅列。
後から忘れないようにするためのメモ的立ち位置。
詳しく知りたいものは後日paperを読む予定。
3D
3DFIRES: Few Image 3D REconstruction for Scenes with Hidden Surfaces
https://cvpr.thecvf.com/virtual/2024/poster/29885

CityDreamer: Compositional Generative Model of Unbounded 3D Cities
https://cvpr.thecvf.com/virtual/2024/poster/29266

Template Free Reconstruction of Human-object Interaction with Procedural Interaction Generation
https://cvpr.thecvf.com/virtual/2024/poster/29444

MonoCD: Monocular 3D Object Detection with Complementary Depths
https://cvpr.thecvf.com/virtual/2024/poster/30921

Know Your Neighbors: Improving Single-View Reconstruction via Spatial Vision-Language Reasoning
https://cvpr.thecvf.com/virtual/2024/poster/29964

Compressed 3D Gaussian Splatting for Accelerated Novel View Synthesis
https://cvpr.thecvf.com/virtual/2024/poster/31680

MonoDiff: Monocular 3D Object Detection and Pose Estimation with Diffusion Models
https://cvpr.thecvf.com/virtual/2024/poster/30683

LaneCPP: Continuous 3D Lane Detection using Physical Priors
https://cvpr.thecvf.com/virtual/2024/poster/30930

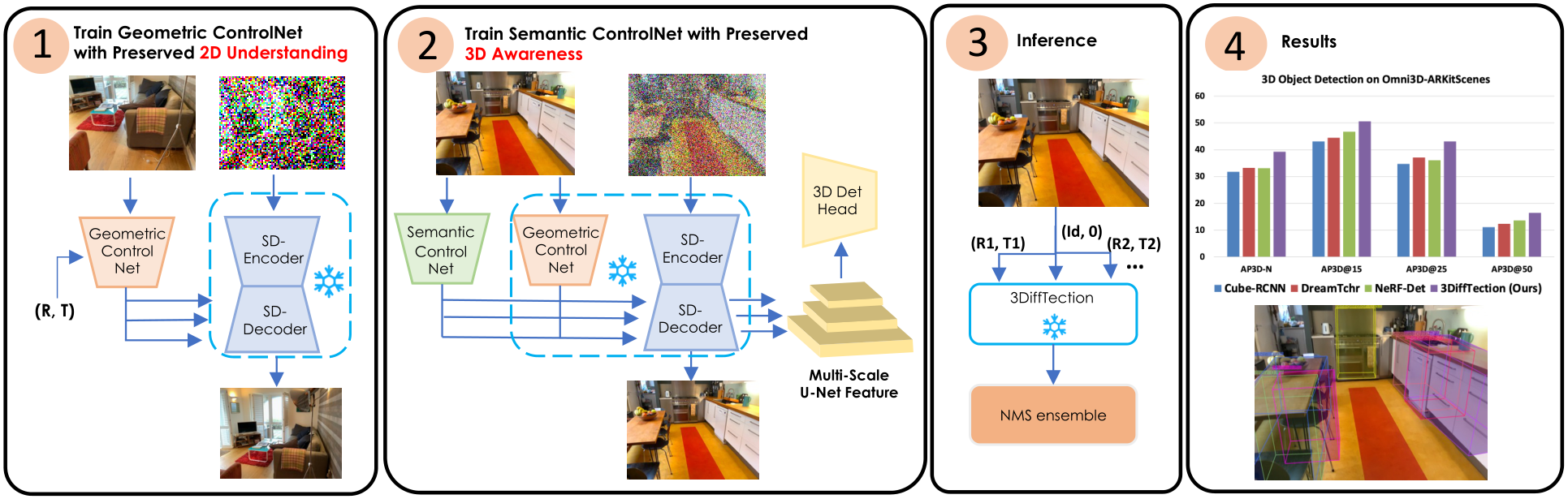
3DiffTection: 3D Object Detection with Geometry-Aware Diffusion Features
https://cvpr.thecvf.com/virtual/2024/poster/30607
Gated Fields: Learning Scene Reconstruction from Gated Videos
https://cvpr.thecvf.com/virtual/2024/poster/29275

depth
Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
https://cvpr.thecvf.com/virtual/2024/poster/31264

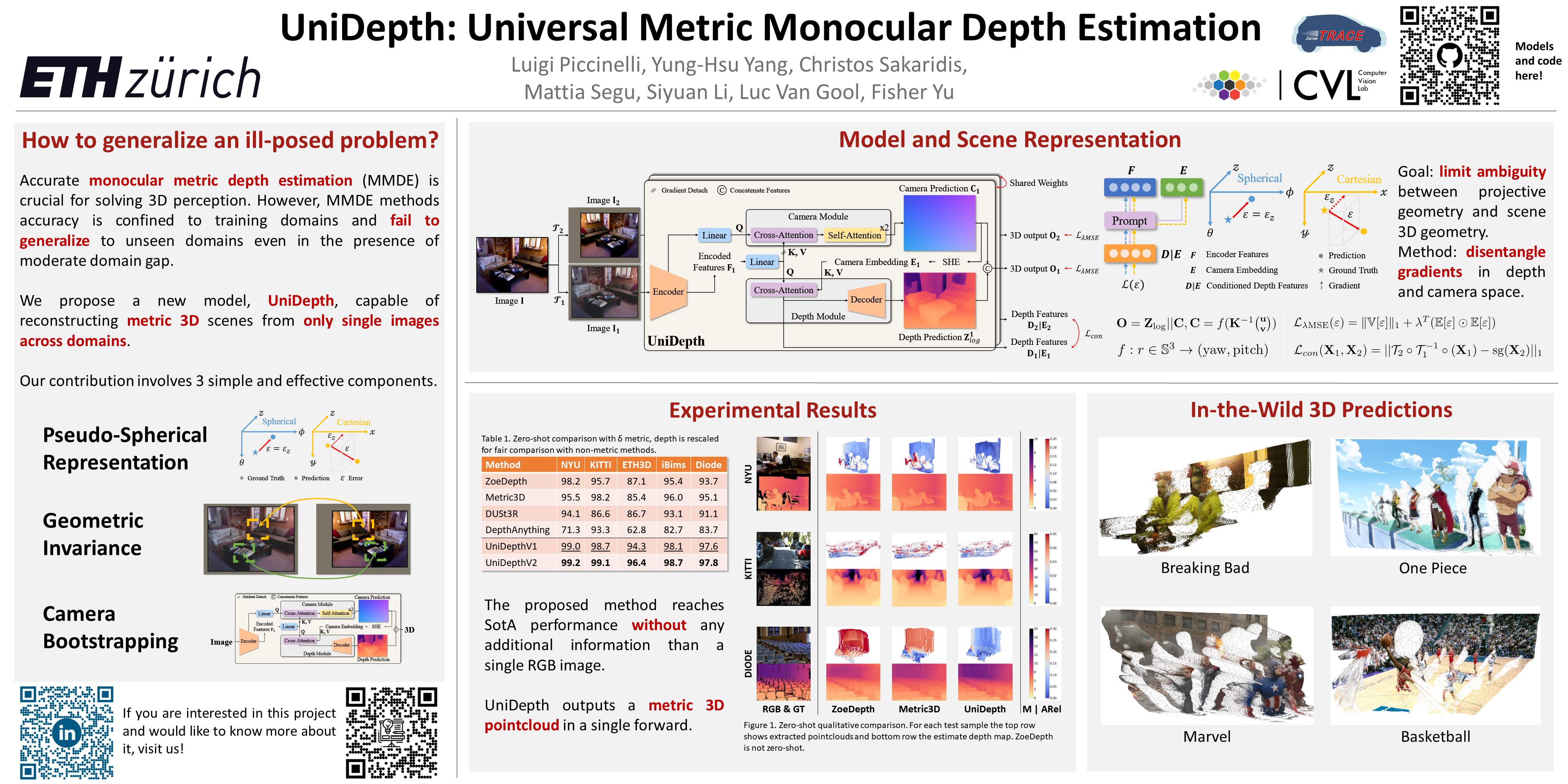
UniDepth: Universal Monocular Metric Depth Estimation
https://cvpr.thecvf.com/virtual/2024/poster/31417
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
https://cvpr.thecvf.com/virtual/2024/poster/30176

Atlantis: Enabling Underwater Depth Estimation with Stable Diffusion
https://cvpr.thecvf.com/virtual/2024/poster/29435

multimodal
Adapting Visual-Language Models for Generalizable Anomaly Detection in Medical Images
https://cvpr.thecvf.com/virtual/2024/poster/29250

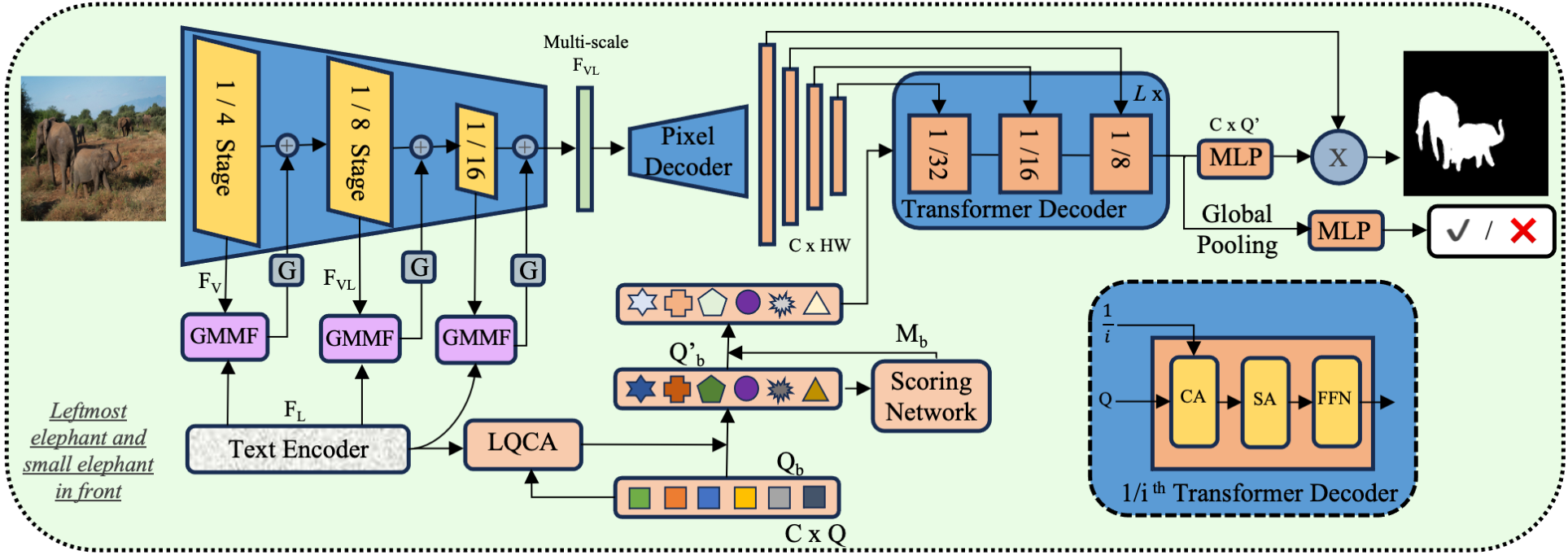
LQMFormer: Language-aware Query Mask Transformer for Referring Image Segmentation
https://cvpr.thecvf.com/virtual/2024/poster/31268
ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
https://cvpr.thecvf.com/virtual/2024/poster/29580

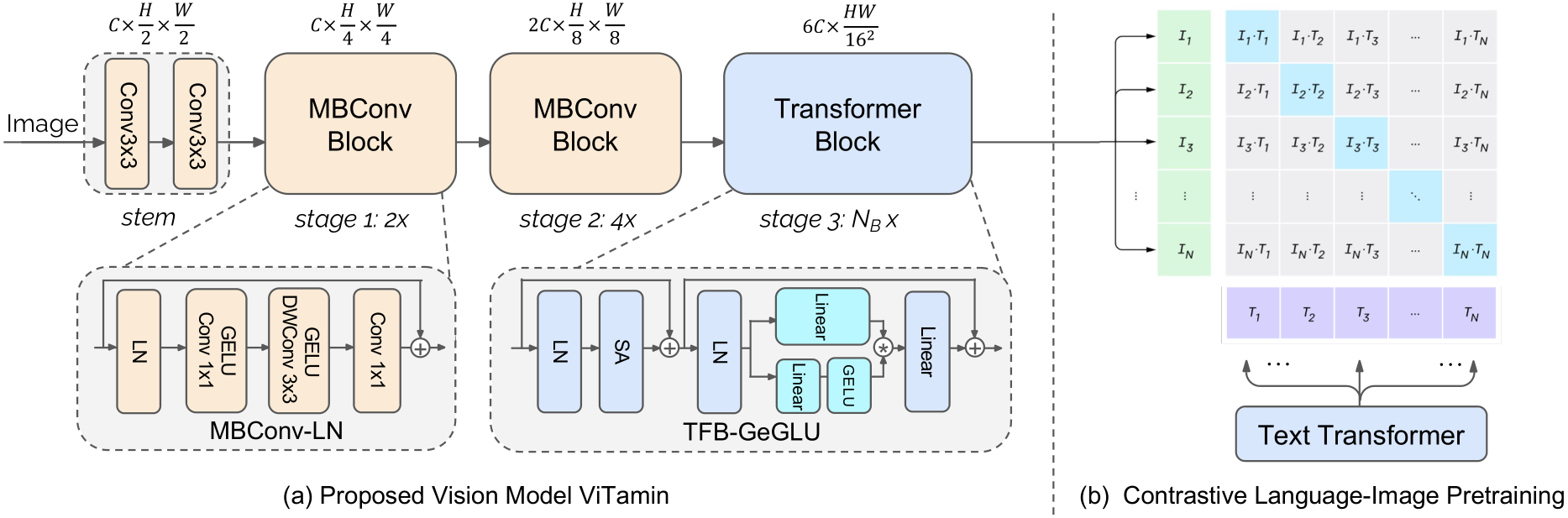
ViTamin: Designing Scalable Vision Models in the Vision-Language Era
https://cvpr.thecvf.com/virtual/2024/poster/31575
Learning to Localize Objects Improves Spatial Reasoning in Visual-LLMs
https://cvpr.thecvf.com/virtual/2024/poster/31877

GLaMM: Pixel Grounding Large Multimodal Model
https://cvpr.thecvf.com/virtual/2024/poster/31094
Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
https://cvpr.thecvf.com/virtual/2024/poster/31492

Pixel-Aligned Language Model
https://cvpr.thecvf.com/virtual/2024/poster/31639
VISTA-LLAMA: Reducing Hallucination in Video Language Models via Equal Distance to Visual Tokens
https://cvpr.thecvf.com/virtual/2024/poster/29676
CLIP as RNN: Segment Countless Visual Concepts without Training Endeavor
https://cvpr.thecvf.com/virtual/2024/poster/31270

See Say and Segment: Teaching LMMs to Overcome False Premises
https://cvpr.thecvf.com/virtual/2024/poster/31231
Segment and Caption Anything
https://cvpr.thecvf.com/virtual/2024/poster/29271

RegionGPT: Towards Region Understanding Vision Language Model
https://cvpr.thecvf.com/virtual/2024/poster/31126

LISA: Reasoning Segmentation via Large Language Model
https://cvpr.thecvf.com/virtual/2024/poster/30109

Taming Self-Training for Open-Vocabulary Object Detection
https://cvpr.thecvf.com/virtual/2024/poster/29999

その他
Teeth-SEG: An Efficient Instance Segmentation Framework for Orthodontic Treatment based on Multi-Scale Aggregation and Anthropic Prior Knowledge
https://cvpr.thecvf.com/virtual/2024/poster/30824

Long-Tailed Anomaly Detection with Learnable Class Names
https://cvpr.thecvf.com/virtual/2024/poster/31789

