1.はじめに
AgentCoreにはエージェントをホストする方法として CLIと SDK の2種類でしたが、
2026年5月現在、Amazon Bedrock AgentCore Harness(Preview)が新たに利用可能になっています。
本記事では「AWSの最新アップデートをRSSから取得してカテゴリ別棒グラフを生成する」というユースケースを題材に、AgentCore Harnessを活用した結果をまとめます。
2.AgentCore Harnessとは
AgentCore Harnessは、コードを書かずにコンソールの設定だけでエージェントを動かせるマネージドサービスです。
これまではAIエージェントを構築するのに、何十行何百行のコードを書く必要がありましたが、それが自然言語だけで完結するようになりました。
アーキテクチャ
クライアント
└─ InvokeHarness API
└─ AgentCore Harness
└─ Strands Agents(エージェントループ)
├─ Amazon Bedrock / OpenAI / Gemini(モデル)
├─ AgentCore Gateway / MCP(ツール)
└─ 組み込みメモリ・セッション管理
エージェントのオーケストレーション(モデル呼び出し・ツール実行・メモリ管理・セッション管理)はすべてHarnessが自動で行います。開発者はシステムプロンプトとツール設定を書くだけです。内部では AWS が公開しているオープンソースのエージェントフレームワーク Strands Agents が動いています。
実際にどれくらい便利になったのか、通常のRuntimeと比較してHarnessの機能・中身を見ていきましょう!
3.デモ検証概要
成果物
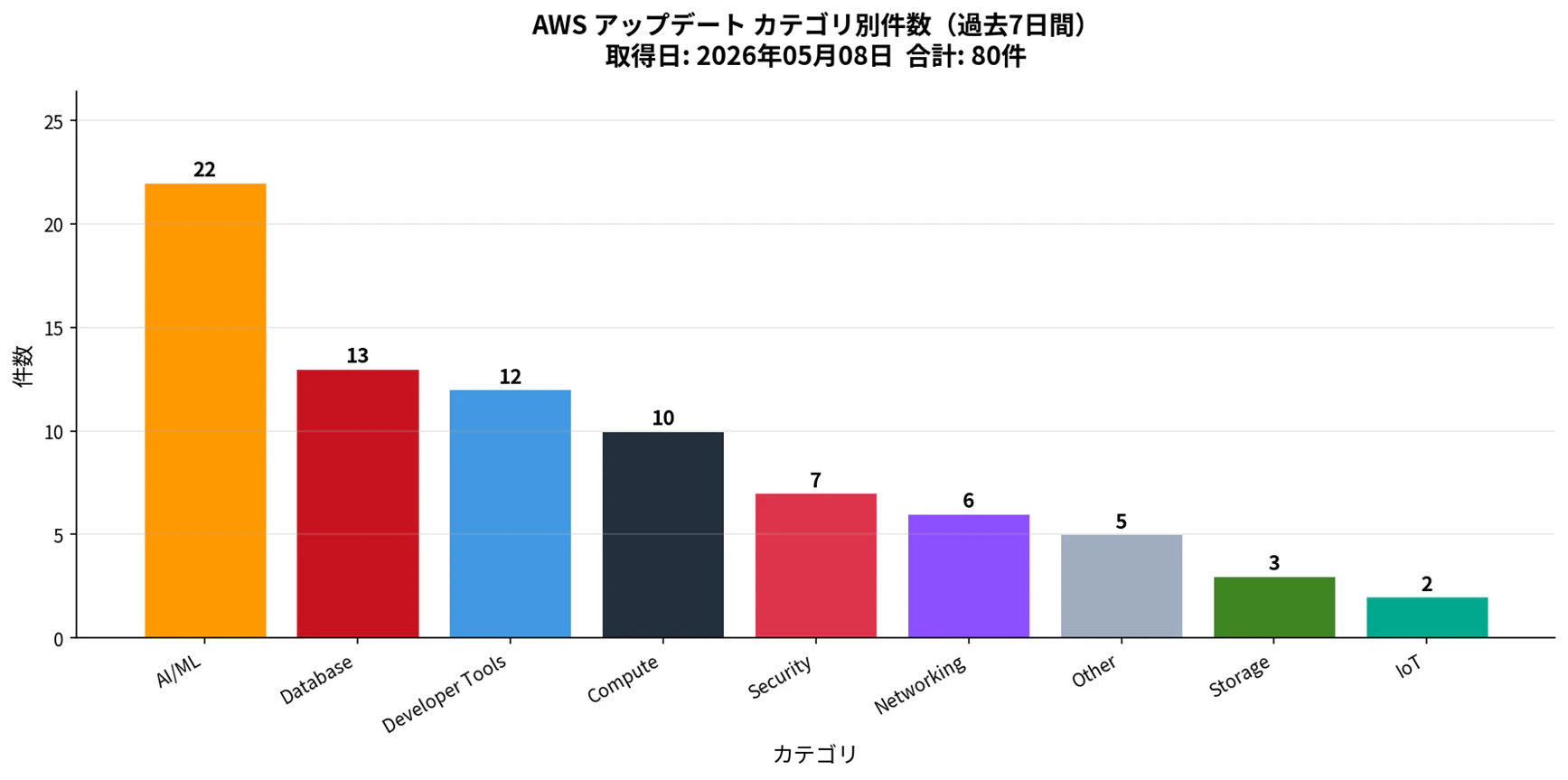
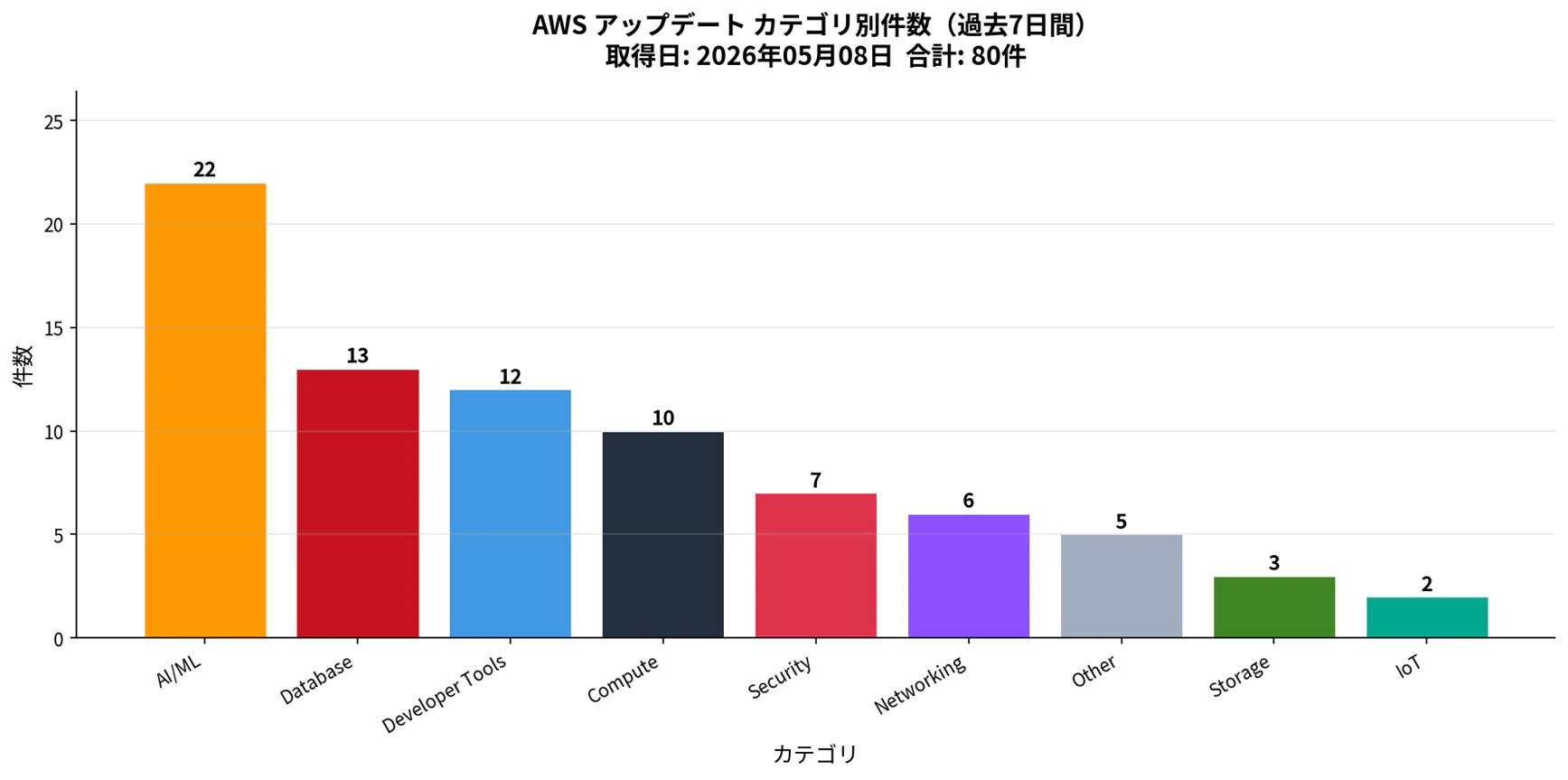
過去7日間のAWSアップデート68件をカテゴリ別に分類し、棒グラフとして出力するAIエージェントを開発します。
棒グラフ完成イメージはこちらです。
使用するAWSサービス
| サービス | 用途 |
|---|---|
| Amazon ECR | Runtimeのコンテナイメージ保管 |
| AgentCore Runtime | FastAPIエージェントのホスティング |
| AgentCore Harness | マネージドエージェント実行環境 |
| Amazon Bedrock | カテゴリ分類(Claude Haiku 4.5) |
4.Runtimeでの実装
Runtimeとは
AgentCore Runtimeは、自分で書いたコードをコンテナとしてホストし、エージェントとして公開するサービスです。エージェントのロジックはすべて自分で実装します。フレームワークの制約がなく自由度が高い反面、インフラ周りの設定もすべて自前で行う必要があります。
AgentCore Runtimeとして動作させるには、以下の要件を満たす必要があります。
| 要件 | 内容 |
|---|---|
| エンドポイント① |
POST /invocations(エージェント処理) |
| エンドポイント② |
GET /ping(ヘルスチェック) |
| ポート | 8080 でリッスン |
| アーキテクチャ |
ARM64 必須(--platform linux/arm64) |
| 初期化時間 | 30秒以内 に完了すること |
| ホスト方式 | ECR(S3 ZIPは初期化タイムアウトが発生しやすい) |
実装方針
AIコーディングツール Kiro を使って実装しました。
Harnessを使わずとも、Kiroを使うことで同じ効果を得られるではと予想して作業を進めました。
Runtime構築手順
Step 1: ローカルにコードを準備
main.py(FastAPIエージェント)、requirements.txt、Dockerfile を作成します。
ファイル構成
C:\Users\******\AgentCoreHarness\
├── main.py # FastAPIエージェント本体
├── requirements.txt # 依存パッケージ
└── Dockerfile # コンテナ定義
requirements.txt
fastapi
uvicorn
boto3
feedparser
matplotlib
requests
pydantic
Dockerfile
fonts-noto-cjk は日本語フォントの描画に必要です。
fc-cache -fv でフォントキャッシュを更新しておきます。
FROM --platform=linux/arm64 python:3.13-slim
WORKDIR /app
RUN apt-get update && apt-get install -y --no-install-recommends \
fonts-noto-cjk \
libfreetype6 \
fontconfig \
&& fc-cache -fv \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY main.py .
EXPOSE 8080
CMD ["python", "main.py"]
main.py(抜粋)
AgentCore Runtimeが送るリクエストボディの形式は固定されていないため、
PydanticモデルではなくFastAPIの Request オブジェクトで生のJSONを受け取ります。
※ハンズオン教材提供が目的ではないので、コード提供は割愛させていただきます。
@app.get('/ping')
async def ping():
return {'status': 'healthy'}
@app.post('/invocations')
async def invoke(request: Request):
try:
body = await request.json()
except Exception:
body = {}
# days の取得:input.days → days → promptから数字抽出 → デフォルト7
days = 7
if isinstance(body.get('input'), dict):
days = int(body['input'].get('days', 7))
elif 'days' in body:
days = int(body['days'])
elif 'prompt' in body:
m = re.search(r'(\d+)', str(body['prompt']))
if m:
days = int(m.group(1))
result = run_agent(days)
return JSONResponse(content={'output': result})
Step 2: ECRリポジトリを作成
AWSコンソール → ECR → リポジトリを作成
| 項目 | 設定値 |
|---|---|
| リポジトリ名 | agentcore-runtime-hands |
| イメージタグの可変性 | Mutable |
| 暗号化 | AES-256 |
Step 3: Dockerイメージをビルドしてプッシュ
--platform linux/arm64 は必須です。忘れるとRuntime起動エラーになるので要注意です!
# ARM64でビルド(必須)
docker build --platform linux/arm64 -t agentcore-runtime-hands .
# ECRにログイン
aws ecr get-login-password --region us-west-2 | \
docker login --username AWS --password-stdin \
123456789012.dkr.ecr.us-west-2.amazonaws.com
# タグ付け
docker tag agentcore-runtime-hands:latest \
123456789012.dkr.ecr.us-west-2.amazonaws.com/agentcore-runtime-hands:v11
# プッシュ
docker push \
123456789012.dkr.ecr.us-west-2.amazonaws.com/agentcore-runtime-hands:v11
Step 4: AgentCore Runtimeを作成
AWSコンソール画面から、Amazon Bedrock AgentCore → Runtimes → ホストエージェント/ツールで進みます。
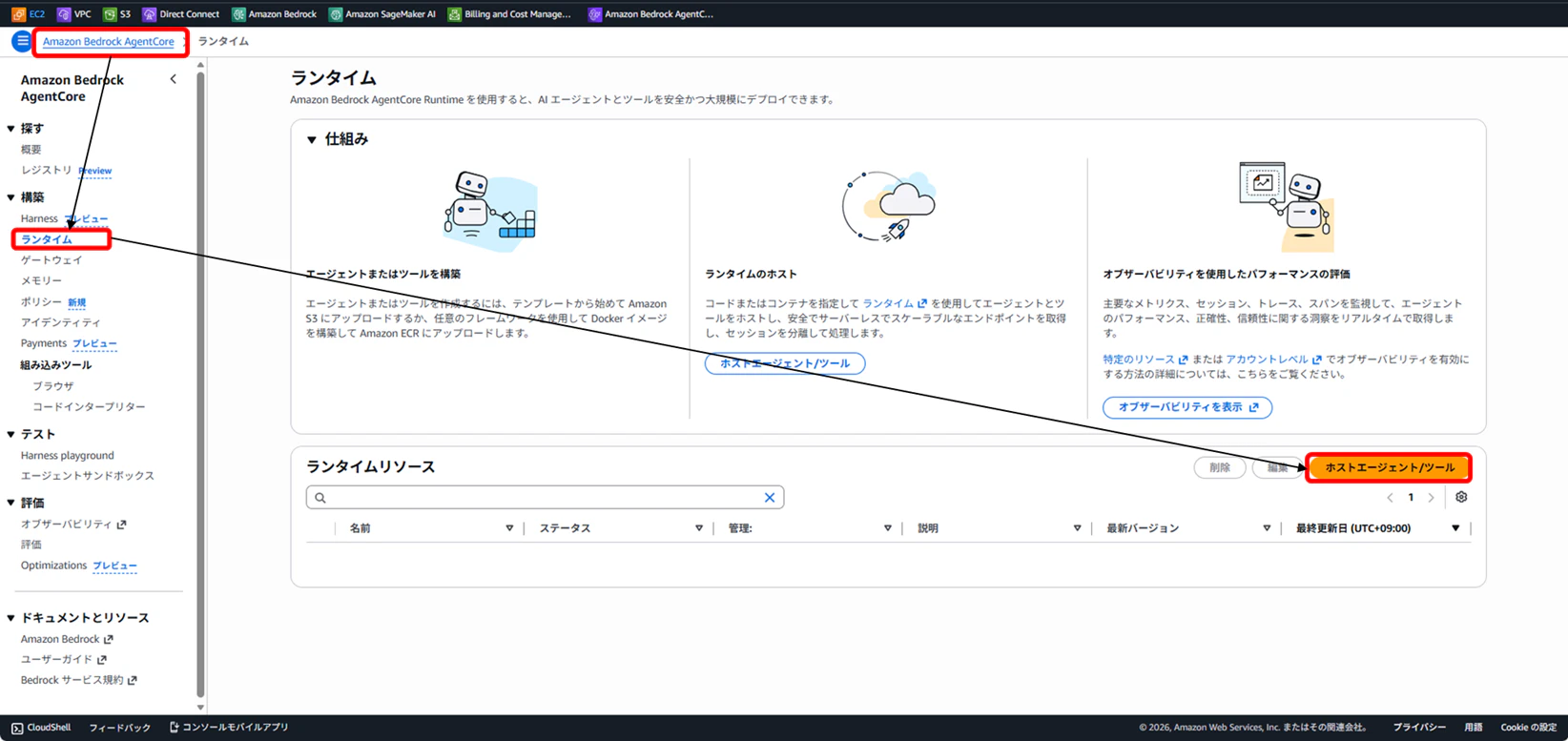
先ほどプッシュしたECRイメージを参照し、以下の設定値で実装しました。
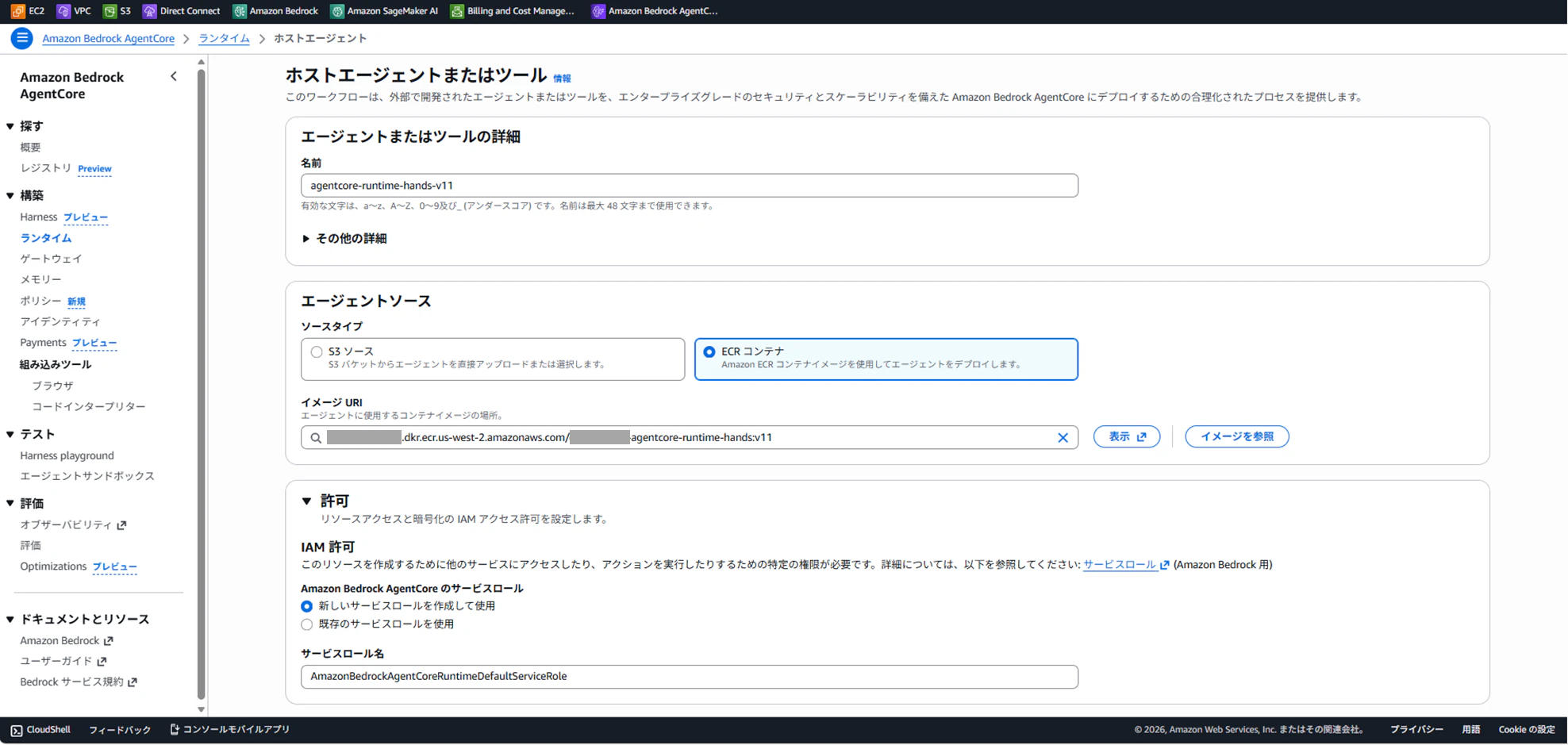
| 項目 | 設定値 |
|---|---|
| Runtime name | agentcore-runtime-hands-v11 |
| Container image URI | 123456789012.dkr.ecr.us-west-2.amazonaws.com/agentcore-runtime-hands:v11 |
| Execution role | 新規作成(ECRプル・Bedrock呼び出し権限を付与) |
Status が READY になるまで数分待ちます。
Step 5: デフォルトエンドポイントを選択してテスト
- 作成したRuntimeを選択
- Endpoints タブ → default エンドポイントを選択
- Test endpoint でリクエストを送信
{"days": 7}
これによって、棒グラフのBase64データと集計結果が返ってきました。
v1〜v11 試行錯誤の記録
構築手順は上記の通りですが、実際にはここに至るまで11回の手直しが必要でした。
AIコーディングツールKiroによって、一瞬で開発できると思っていましたが、
想像以上に時間がかかり計5時間・約200 creditsも消費してしまいました...
| バージョン | 想定原因 | 対処内容 | 結果 |
|---|---|---|---|
| v1 | S3 ZIPデプロイでRuntime初期化が30秒以内に完了しない | S3にagent.zipをアップロードしてデプロイ | ❌ Runtime initialization time exceeded.
|
| v2 | ZIPのパッケージサイズ大・Harness管理RuntimeへのDirect invoke | agent2.zipを再作成。Harness管理Runtimeへの直接invoke問題を認識 | ❌ The agent runtime is managed by a harness and cannot be invoked directly.
|
| v3 | ECRホスト方式に切り替え。Dockerfileなし・ビルドコンテキストのパス不正 | Dockerfileを新規作成。docker build --platform linux/arm64 でビルド |
❌ COPY main.py: not found(パス指定ミス) |
| v4 | ビルドコンテキストのパス修正後、ECRプッシュ・Runtime新規作成 | 絶対パスに修正。ECRへタグ付け・プッシュ後にRuntime作成 | ❌ An error occurred when starting the runtime.
|
| v5 | FastAPIサーバーが正常起動しない。依存パッケージ失敗またはポート設定ミスの疑い | requirements.txtとDockerfileの依存関係を見直し。ポート8080のEXPOSE確認 | ❌ Received error (422) from runtime.
|
| v6 | AgentCore Runtimeが送るリクエストボディとPydanticモデルが不一致 |
InvocationRequestにextra='allow'追加。Requestオブジェクトで生JSON受け取りに変更 |
❌ 同じ422エラー継続 |
| v7 |
/invocationsのリクエスト受け取り方が不完全 |
async def invoke(request: Request)で生JSON受け取りに統一。daysパラメータの多段フォールバック実装 |
❌ カテゴリ分類が全件Otherになる問題が発覚 |
| v8 |
Bedrock raw response:ログが出ていない。カテゴリ名の不一致疑い |
CloudWatch Logsを調査。デバッグログ追加(classify_articles called、Bedrock raw response:) |
❌ Bedrockは呼ばれているが返答が日本語や別表記 |
| v9 | プロンプトが日本語のためモデルが日本語で返答。モデルがLegacy扱い | プロンプトを英語カテゴリ名のみ返すよう修正。モデルをus.anthropic.claude-haiku-4-5-20251001-v1:0に変更 |
❌ モデルアクセスエラー(Legacy扱い) |
| v10 | us-west-2でLegacyラベルのないモデルを選定する必要がある | モデルIDをus.anthropic.claude-haiku-4-5-20251001-v1:0に確定。完全一致+部分一致フォールバックのマッチングロジック追加 |
❌ Otherが多い状態 |
| v11 | カテゴリマッチングロジックの精度不足。大文字小文字・前後スペースの不一致 |
.strip()・.lower()による正規化を徹底。部分一致ロジックを改善。日本語フォント(Noto CJK)フォールバック追加 |
✅ 成功 |
主なハマりポイント3選
1. S3 ZIPは使えない → ECR一択
最初はS3にZIPをアップロードする方式を試みましたが、依存パッケージ(matplotlib、feedparser等)を含めるとサイズが大きくなり、30秒の初期化タイムアウトに引っかかります。
→ ECRにDockerイメージをプッシュする方式が安定
2. 422エラーはリクエスト形式の不一致
AgentCore Runtimeが送るリクエストボディの形式は固定されていません。PydanticモデルでBodyを受け取ると型不一致で422エラーになります。
# ❌ これだと422になる
@app.post('/invocations')
async def invoke(body: InvocationRequest):
...
# ✅ これが正解
@app.post('/invocations')
async def invoke(request: Request):
body = await request.json()
...
3. モデルのLegacy問題(us-west-2)
us-west-2では一部のAnthropicモデルがLegacy扱いになっており、呼び出しがブロックされます。
us.プレフィックス付きのクロスリージョン推論モデルを使うことで解決しました。
# ❌ Legacy扱いでアクセス不可になる場合がある
modelId='anthropic.claude-3-haiku-20240307-v1:0'
# ✅ Legacyラベルなし
modelId='us.anthropic.claude-haiku-4-5-20251001-v1:0'
5.Harnessでの実装
「Harnessとは」で説明した通り、コンソールの設定だけでエージェントが動きます。
実際の手順を見ていきます。
Harness構築手順
Step 1: Harnessを作成
AWSコンソール画面から、Amazon Bedrock AgentCore → Harnesses → ハーネスをクイック作成 で進みます。
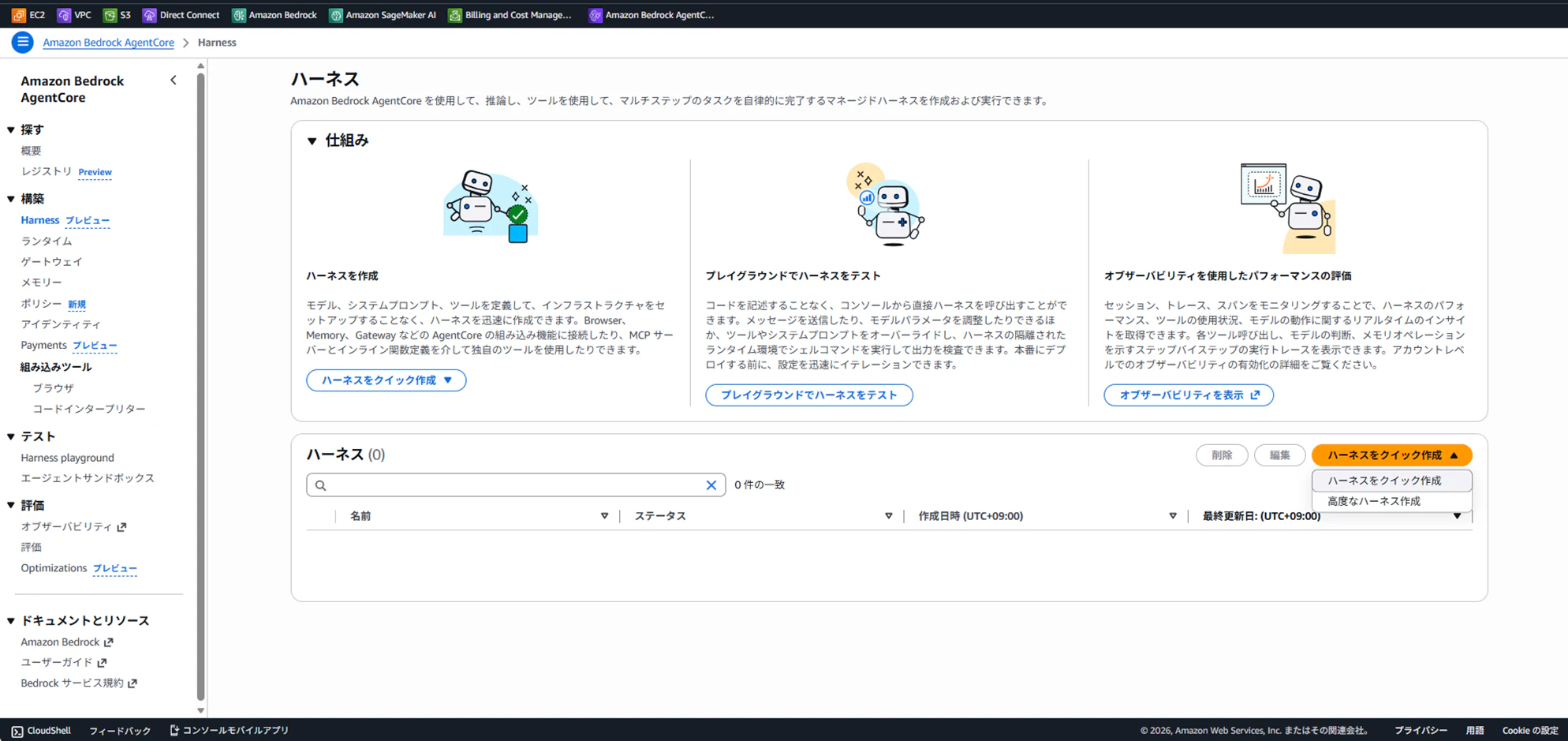
なんとなんと、この1画面だけで設定が完結します。
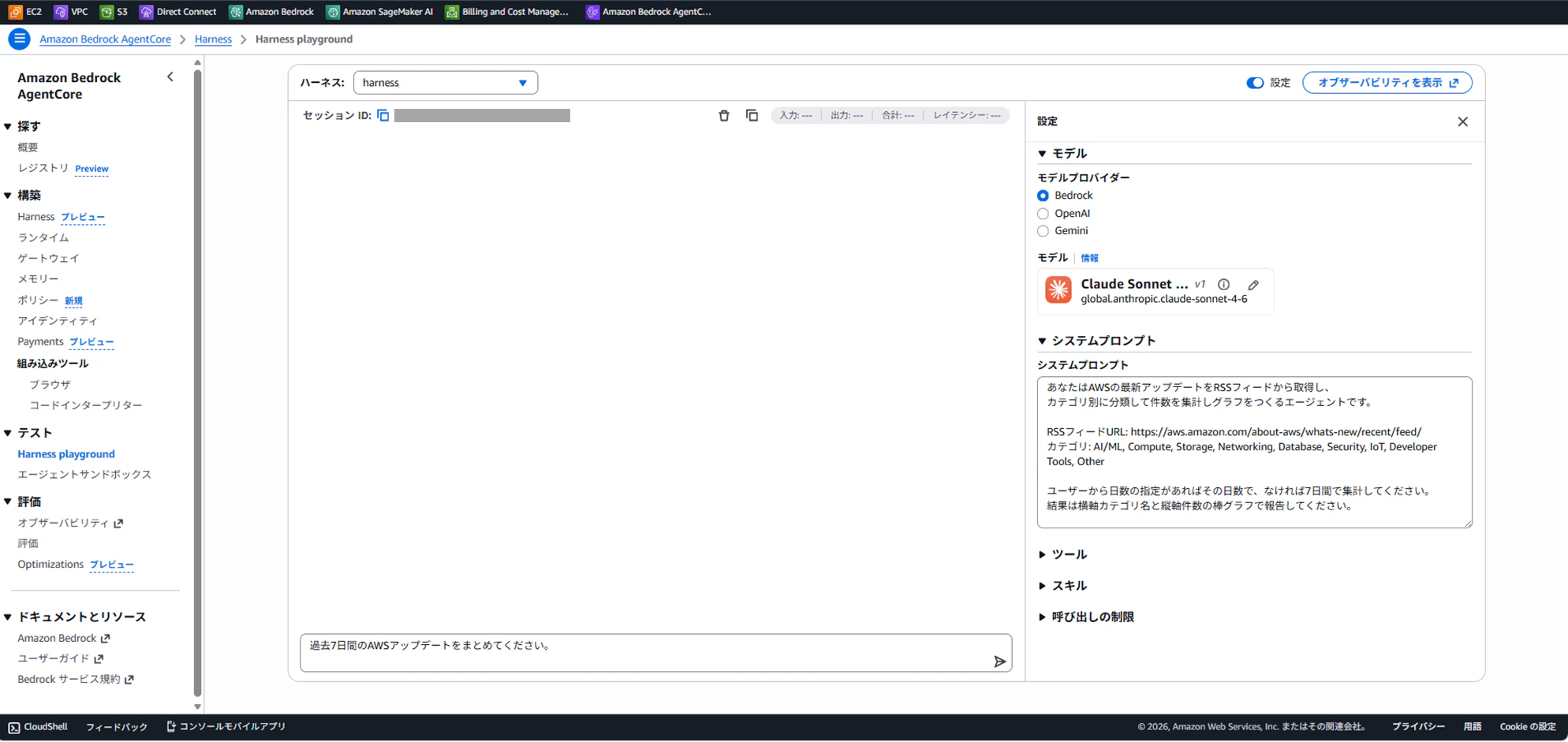
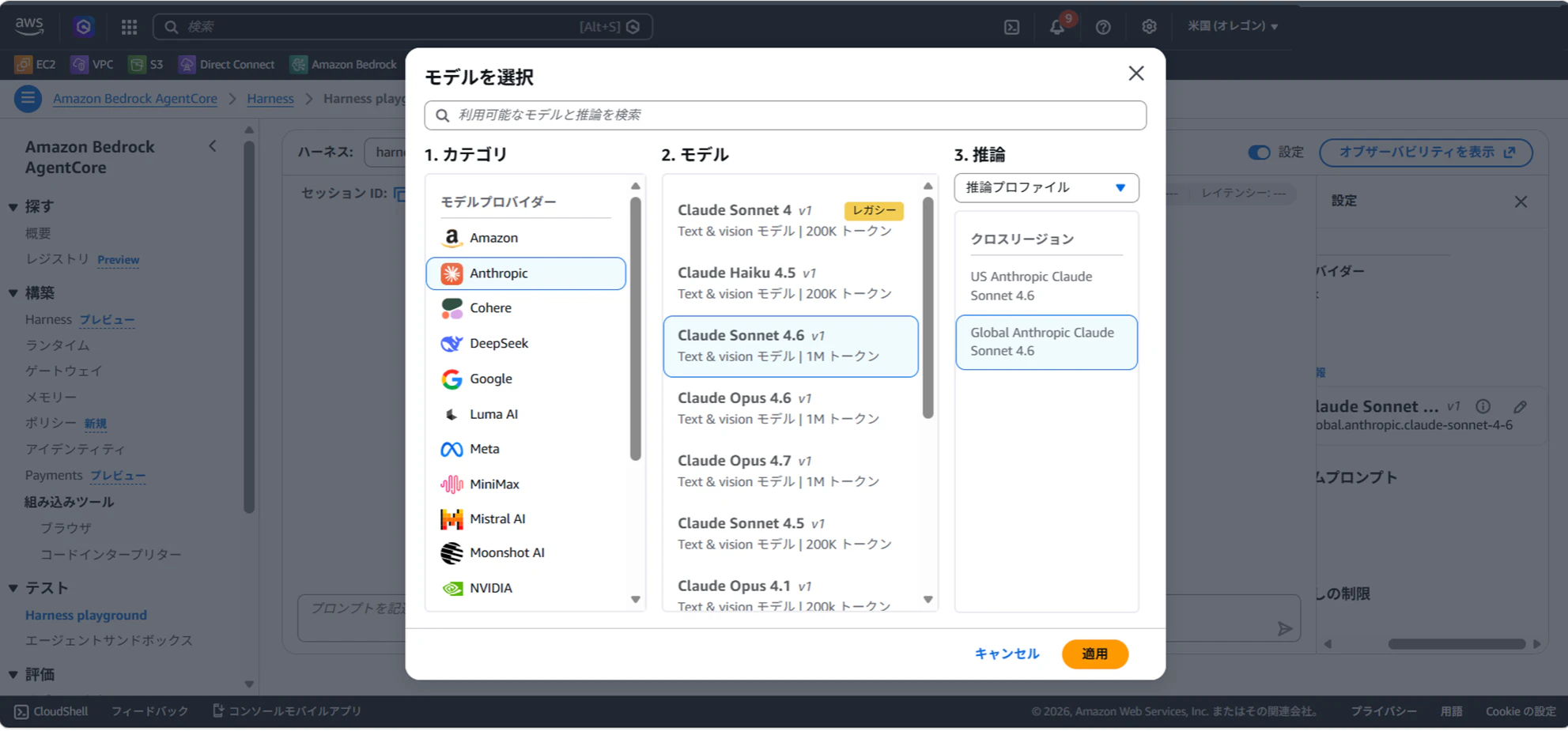
Step 2: モデルを選択
右側のモデルから利用するAIモデルを選択します。
| 項目 | 設定値 |
|---|---|
| モデルプロバイダー | Amazon Bedrock |
| モデル | Claude Sonnet 4.6(デフォルト) |
注意:
global.anthropic.claude-sonnet-4-6等はAWS Marketplace経由のモデルのため、IAMロールにaws-marketplace:ViewSubscriptions権限が必要です。権限エラーが出た場合はモデルを変更するか、IAMロールにポリシーを追加してください。
Step 3: システムプロンプトを設定
右側の設定パネルの「システムプロンプト」欄に入力します。
あなたはAWSの最新アップデートをRSSフィードから取得し、
カテゴリ別に分類して件数を集計するエージェントです。
RSSフィードURL: https://aws.amazon.com/about-aws/whats-new/recent/feed/
カテゴリ: AI/ML, Compute, Storage, Networking, Database, Security, IoT, Developer Tools, Other
ユーザーから日数の指定があればその日数で、なければ7日間で集計してください。
結果は横軸カテゴリ名と縦軸件数の棒グラフで報告してください。
Step 4: チャットでテストする
左側のチャット欄に送信するだけです。
過去7日間のAWSアップデートをカテゴリ別に集計してください
そうすると、以下の表を出力してくれました。
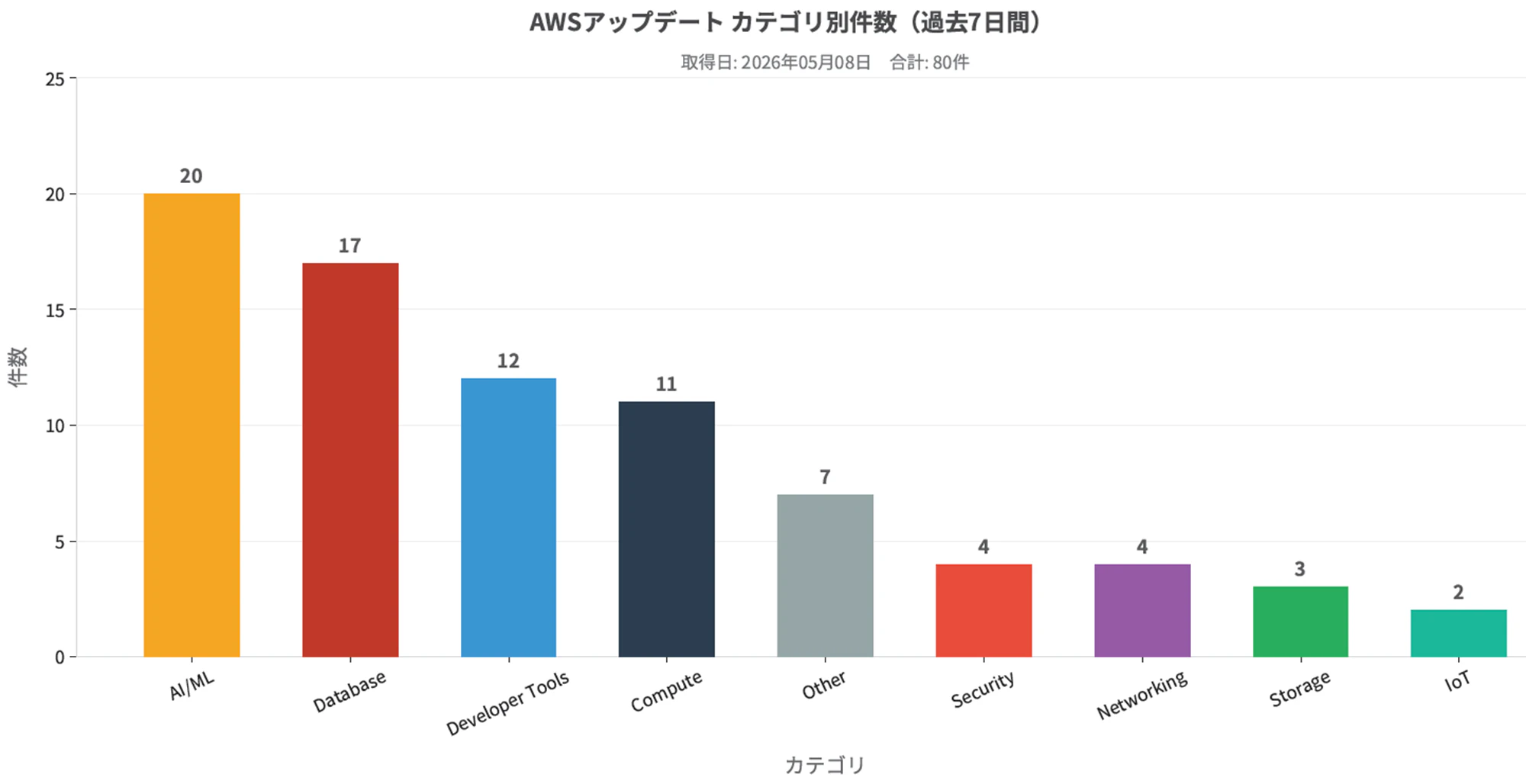
コードもDockerもECRも不要で、わずか30分以内でアウトプット出力まで完結しました。
6.機能比較
同じユースケースをRuntime・Harnessの両方で実装した結果を、観点ごとに比較します。
実装コスト
Runtime
Dockerfile作成 → ECRリポジトリ作成 → ARM64でビルド → ECRプッシュ → Runtime作成 → エンドポイントテスト、という手順が必要です。
私の技術不足もあるかもしれませんが、Kiroを使ってもかなりの時間が必要です。
Harness
コンソールのCreate harness画面を開き、システムプロンプトを入力してチャットするだけです。コードもDockerも不要で、数分で動作確認まで完了しました。
デプロイ方法
Runtime
コードを変更するたびに更新サイクル(コード修正 → docker build → docker push → Runtime更新または新規作成)が必要です。
バージョン管理はECRのイメージタグで行います(v1, v2, ... v11)。
Harness
コンソールの設定画面を変更するだけです。再ビルドもプッシュも不要です。
モデル切り替え
Runtime
コード内のモデルIDを変更し、再ビルド・再デプロイが必要です。
# コードを直接変更する
modelId='us.anthropic.claude-haiku-4-5-20251001-v1:0'
Harness
コンソールの設定パネルでモデルをドロップダウンから選択するだけです。Bedrock・OpenAI・Geminiをその場で切り替えられます。
複数モデル対応
Runtime
複数モデルを使い分けたい場合は、自前でロジックを実装する必要があります。
これも先ほどと同じく、コード内のモデルIDを変更し、再ビルド・再デプロイが必要です。
Harness
セッション中にモデルを切り替えることが可能です。設定変更のみで対応できます。
ツール連携
Runtime
外部ツールとの連携はすべて自前実装です。今回はRSSフィード取得・Bedrock呼び出し・matplotlib描画をすべてコードで実装しました。
Harness
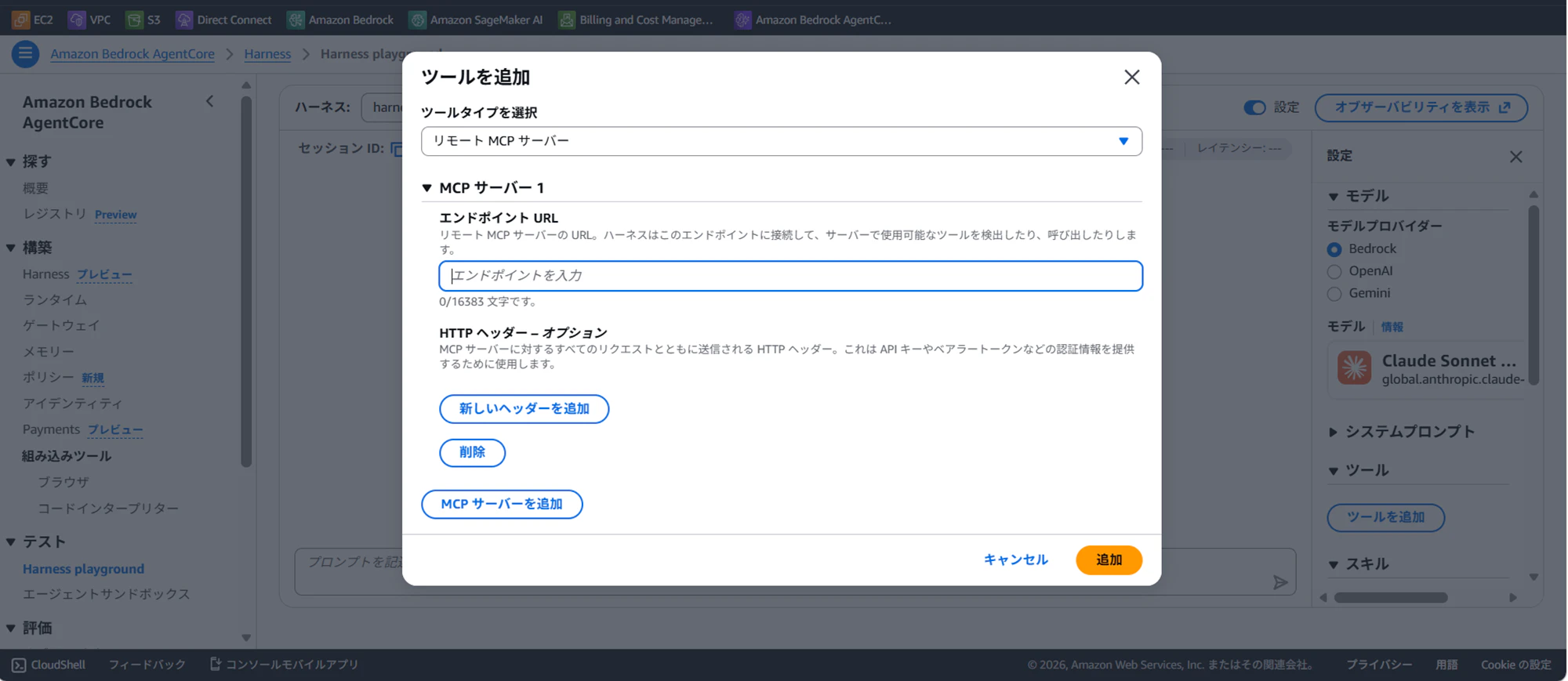
AgentCore Gateway・MCP(Model Context Protocol)サーバーとの連携が組み込みで対応しています。コンソールの「ツールを追加」から設定できます。
下記画像は、MCPサーバを設定するときの画面です。
カスタマイズ性
Runtime
処理ロジックをすべて自分でコントロールできます。今回のように「RSSを取得してBedrockで分類してmatplotlibで棒グラフを生成してBase64で返す」という複雑な処理も自由に実装できます。
Harness
システムプロンプトとツール設定でエージェントの動作を制御します。
今回の検証では大丈夫でしたが、複雑な処理ロジックの実装には限界があるかもしれません。
アーキテクチャ制約
Runtime
コンテナは ARM64 アーキテクチャでビルドする必要があります。
--platform linux/arm64 を忘れると起動エラーになります。
# 必須
docker build --platform linux/arm64 -t my-agent .
Harness
アーキテクチャの制約はありません。コンテナを自前で用意する必要がないためです。
初期化制約
Runtime
コンテナの起動(FastAPIサーバーの立ち上がり)は 30秒以内 に完了する必要があります。依存パッケージが多い場合は注意が必要です。
Harness
初期化時間の制約はありません。
オブザーバービリティ
Runtime:CloudWatch Logs
Runtimeのログは以下のロググループに出力されます。
/aws/bedrock-agentcore/runtimes/{runtime-name}-{suffix}-DEFAULT
今回の検証でも、カテゴリ分類が全件 Other になる問題はCloudWatch Logsで Bedrock raw response: を確認することで原因を特定できました。
# デバッグログの例
logger.info(f'classify_articles called: {len(articles)} articles')
logger.info(f'Bedrock raw response: [{raw}]')
ログを見るには CloudWatch コンソールを開く必要があり、視覚的なトレースはありません。
Harness:AgentCore Observability
Harnessにはコンソール右上の 「オブザーバービリティを表示」 から専用の画面が開きます。
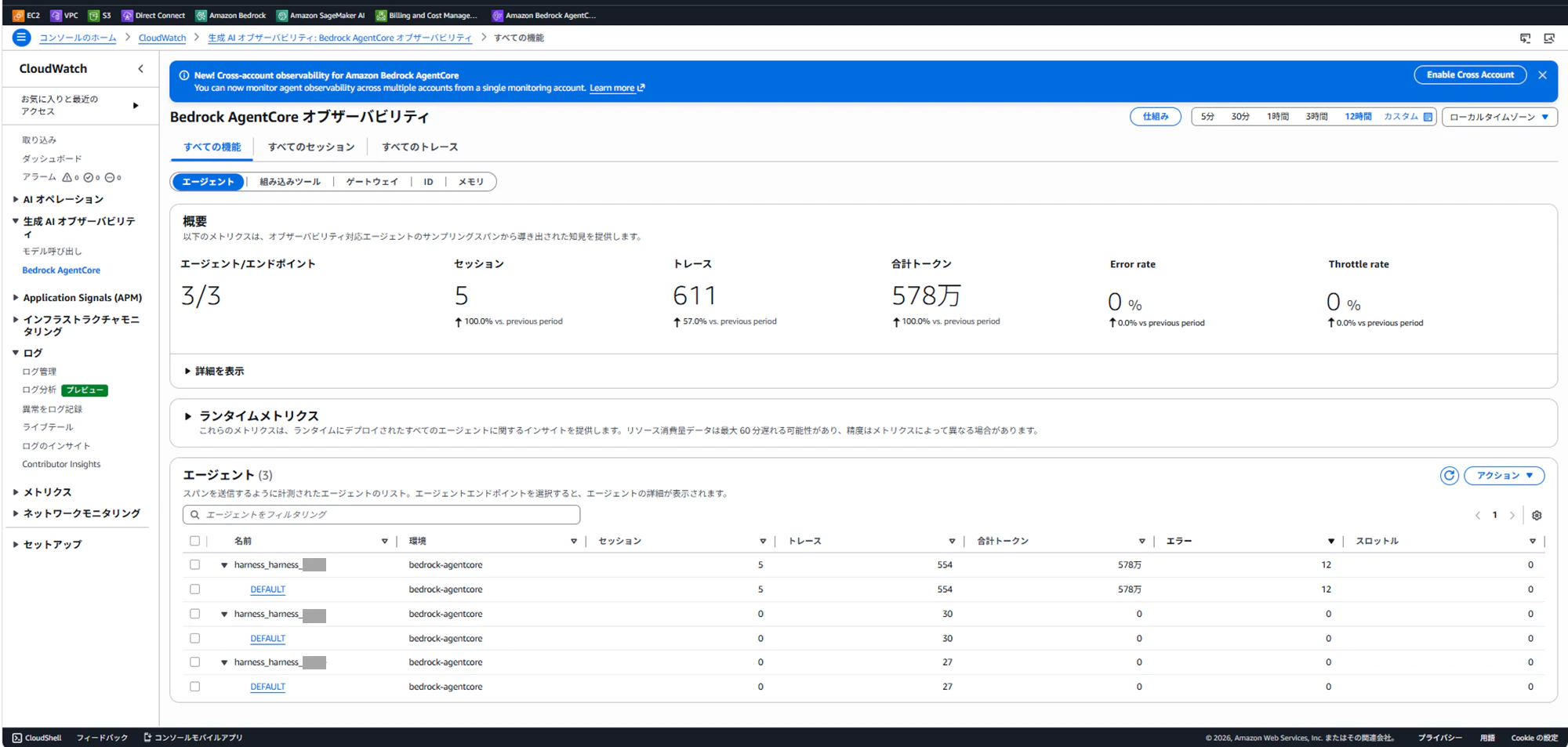
- エージェントの思考ステップのトレース(どのツールをいつ呼んだか)
- トークン使用量・コスト
- レイテンシー
- ツール呼び出し履歴
CloudWatch Logsを直接見る必要がなく、視覚的に確認できます。
比較まとめ表
これまでの比較をまとめるとこのようになります。
こうしてみると、Harnessの便利さがわかりますね!
| 観点 | Runtime | Harness |
|---|---|---|
| 実装コスト | 高(コード・Docker・ECR・11回の手直し) | 低(コンソール設定のみ・数分) |
| デプロイ方法 | コード修正→ビルド→プッシュ→Runtime更新 | コンソール設定変更のみ |
| モデル切り替え | コード変更→再ビルド→再デプロイ | ドロップダウンで即時切り替え |
| 複数モデル対応 | 自前実装 | セッション中に切り替え可能 |
| ツール連携 | 自前実装 | AgentCore Gateway / MCP対応(組み込み) |
| カスタマイズ性 | 高(処理ロジックを完全制御) | 中(システムプロンプトとツールで制御) |
| アーキテクチャ制約 | ARM64必須 | なし |
| 初期化制約 | 30秒以内 | なし |
| オブザーバビリティ | CloudWatchlogsから確認 | 専用画面で視覚的に理解可能 |
コストについても、Harness自体の追加料金がなく、使用するAgentCore機能(Runtime・Memory等)の料金に対してのみ課金されるのでそれもありがたい要素です。
7.感想
Runtimeは「インフラエンジニア向け」
Runtimeは自由度が高い分、インフラ周りの知識が必要です。
- Dockerfileの書き方
- ARM64ビルドの注意点
- ECRへのプッシュ手順
- FastAPIのエンドポイント設計
- CloudWatch Logsでのデバッグ
Kiroというコーディングツールを使って実装しましたが、それでも 11回の手直しが必要でした。エラーの原因がインフラ側にあることが多く、コードを直しても解決しないケースが続きました。
Harnessは「ビジネス寄りの人向け」
Harnessはコンソールの設定画面だけで動きます。システムプロンプトを書ける人なら誰でも使えます。
コードもDockerもECRも不要。モデルの切り替えも設定変更だけ。セッション管理やメモリも組み込み済み。
プロトタイプを素早く作りたい場合は、まずHarnessから始めるのが正解だと感じました。
8.まとめ
| Runtime | Harness | |
|---|---|---|
| 一言で言うと | 自由だが大変 | 楽だが制約あり |
| 始めるまでの時間 | 数時間〜数日 | 数分 |
| 必要なスキル | Python・Docker・AWS全般 | プロンプトエンジニアリング |
| おすすめシーン | 本番運用・既存コードの移植・複雑な処理 | プロトタイプ・検証・シンプルな処理 |
使い分けの指針:
まずHarnessで試してみて、要件を満たせる場合はHarnessのまま本番環境構築へ、
カスタマイズが必要という場合はRuntimeに移行するのが良いのではないでしょうか。
AgentCore(Preview)はまだ発展途上ですが、Harnessの手軽さは証明できました笑
エージェント開発の入り口として、ぜひ試してみてください!
9.参考リンク
- Amazon Bedrock AgentCore ドキュメント
- AgentCore Harness ドキュメント
- AgentCore Runtime ドキュメント
- Strands Agents(Harnessの内部フレームワーク)
10.免責事項
本記事では、生成AIを活用した内容が含まれています。掲載している技術情報・手順・コードは執筆者が実際に検証した内容をベースにしていますが、AIによる誤情報が含まれる可能性があります。実際の構築・運用の際は必ず公式ドキュメントを確認し、必ずご自身で判断のうえ行ってください。