背景:ラ行は透明感があって新鮮で、プリキュアやラーメン人気の源泉である!?
先日、あるWeb記事を拝見して、衝撃を受けた。
一部関連記事も含めて要約すると、
- 「ラーメン」はそのおいしさだけでなく、「名前」が人気を後押ししている。
- プリキュア60人中34人が「ラ行」を含んでいる
- 「ラ行」には透明感があり、言葉が綺麗に聞こえる
- 古来日本語では「ラ行」は語頭に無かったため、日本人には新鮮&珍しく聞こえる
元記事については、下記リンクをご参照。
ラーメンの話から、日本語の中で「ラ」が1番透明感があり、そのためプリキュアには「ラ」がつく名前が多い
長年アイウエオに触れていながら**「ラ行」の特殊性に全く気づかなかった**。
確かに言われてみると、
「しりとり徹底分析」をした際に作った、各文字ごとの単語数表を見ても、
「ラ行」は全体的に単語数が少ない。
「しりとり徹底分析」については、下記リンクをご参照。
「しりとり」徹底分析!最強キャラ(文字)解説&5つの「驚愕」
そして最も衝撃を受けた理由は、
3歳娘(架空/フィクションです)の名前は「ラ行」で構成されているためだ。
「ラ行」の特殊性については全く無自覚であったが、
私も無意識的に「ラ行」をカワイイと信奉していたのかもしれない。
もちろん3歳娘もプリキュアの信奉者であり、毎日カラーチャージしている。
3歳娘とプリキュアの意外な共通点が今、明らかになった(驚)!
疑問:本当にラ行が多いの? ラ行だけなの?
しかし、パッと考えて様々な疑問が湧いてくる。
プリキュア60人中34人、というのは一見すると多いが、
そもそもプリキュア名は「カタカナ」が必須であるし、
一般のカタカナ語と比べても本当に多いと言えるのだろうか?
**「ラ行」以外に他の「プリキュア感(透明感)のある行」は無いのか?
また逆に「プリキュア感のない行」**もあるのか?
さらに、このルールだと次のプリキュアは
キュア ラーメン
キュア ゴリラ
キュア ラオウ
を許すことになってしまう。
スープと麺のハーモニー!キュアラーメン!
キュアライスとのがったいこうげきはこうかばつぐんだ!
もし、3歳娘がプリキュアになったときに、
このような名前だと泣いてしまうだろう。
素敵な、キュア〇〇〇〇
の名前を考える必要性がある。(※注)
さあ、プログラムを使って、
これらの疑問に対する数値根拠を出し、
プリキュアの秘密を分析してみよう!!
頭に浮かんだこと ぜんぶぜんぶやっちゃおう
想像力からはじまる いま!いま!いま!イマジネーション
「ねぇ、ホントのことを、知りたいの!」
※注:
通常プリキュアは両親には秘密の職業であり、
仮に3歳娘を将来プリキュアにすることに成功したとしても、
両親は全く気づかない可能性がある。
しかし「透明感のある名前」を娘につけてあげれば、
プリキュアになる可能性も上がるのではないか?
変身前の少女の名前も考察対象とする。
結果:プリキュアと一般名詞の「音」を分析してみると面白いことが判明
パパやママに聞いても教えてくれないこれらの疑問に答えるために、
プリキュア60名と、一般名詞68万語を分析した結果、
とても興味深いことが判明した。
先に代表的な結論を書こう。
- 「ラーメン」はプリキュアと同じネーミングセンスだった
-
「ラ行」はプリキュア行であることを確認(後述のグラフ必見)
- さらに、「マ行」がかわいさの秘密だった
キュアミルキー(ララ)が最カワなので知ってた
-
透明感のある名前のつけかたが判明した
- そのつけかたの評価によると、
- 「ラーメン」>>「ゴリラ」>「ラオウ」
- 透明感の無い名前になる文字も判明
さらに、オマケとして(いつもの)Word2Vecも投入すると、
プリキュア名に相応しい単語を続々発掘。
代表的なもので、
ストロベリー、ウィッシュ、スウィート、
シュガー、アイリス、ファイン、
マーマレード、ホーリー、マーブル、パール・・・
などのプリキュア感のある単語を発掘することが出来た。
以下で実際に、どのようなプログラム/データ分析を行ったのか、
考察の内容を記述する。
前提:分析の準備
- Python3(全てGoogle Colaboratory で実行)
- 「しりとり徹底分析」で用意した大量の一般名詞リストを使う
- プリキュアは60人の定義を採用する(2019年9月現在)
- プリキュアの人数は宗教論争になる
最終的に男性含め全人類にプリキュアになれる可能性がある- 映画/オールスター準拠で60人、が妥当線
- 参考:http://prehyou2015.hatenablog.com/entry/nanninpuri
- 技術的に難易度の高いコードは無い。チマチマ頑張って分析する
自然言語処理100本ノックのような感じ
ではさっそく、
プリキュアの名前、変身前の名前、一般名詞、について、
のそれぞれの「音」(アカサタナハマヤラワ)の
統計データを作って考察してみよう!
【1】プリキュア名/変身前名の分析
【1-1】プリキュア名簿の準備
まず、プリキュアの変身前後の名前を定義したCSVファイルを用意し、
以下のようにして読み込む。
苗字は分析してもしょーがないため、
変身前については名前(に相当する箇所)だけに絞っている。
import csv
csv_file = open("drive/My Drive/PURI/プリキュア名称一覧v2.csv", "r", encoding="ms932", errors="", newline="" )
f = csv.reader(csv_file, delimiter=",", doublequote=True, lineterminator="\r\n", quotechar='"', skipinitialspace=True)
PRECURE_NAME_DATA_LIST = []
for row in f:
#rowはList形式
print(row)
PRECURE_NAME_DATA_LIST.append(row)
['1', 'ふたりはプリキュア', 'ブラック', 'ナギサ']
['2', 'ふたりはプリキュア', 'ホワイト', 'ホノカ']
['3', 'ふたりはプリキュアMaxHeart', 'シャイニールミナス', 'ヒカリ']
['4', 'ふたりはプリキュアSplashStar', 'ブルーム', 'サキ']
['5', 'ふたりはプリキュアSplashStar', 'イーグレット', 'マイ']
['6', 'Yes!プリキュア5', 'ドリーム', 'ノゾミ']
['7', 'Yes!プリキュア5', 'ルージュ', 'リン']
['8', 'Yes!プリキュア5', 'レモネード', 'ウララ']
['9', 'Yes!プリキュア5', 'ミント', 'コマチ']
['10', 'Yes!プリキュア5', 'アクア', 'カレン']
['11', 'Yes!プリキュア5GoGo!', 'ローズ', 'クルミ']
['12', 'フレッシュプリキュア!', 'ピーチ', 'ラブ']
['13', 'フレッシュプリキュア!', 'ベリー', 'ミキ']
['14', 'フレッシュプリキュア!', 'パイン', 'イノリ']
['15', 'フレッシュプリキュア!', 'パッション', 'セツナ']
['16', 'ハートキャッチプリキュア!', 'ブロッサム', 'ツボミ']
['17', 'ハートキャッチプリキュア!', 'マリン', 'エリカ']
['18', 'ハートキャッチプリキュア!', 'サンシャイン', 'イツキ']
['19', 'ハートキャッチプリキュア!', 'ムーンライト', 'ユリ']
['20', 'スイートプリキュア♪', 'メロディ', 'ユビキ']
['21', 'スイートプリキュア♪', 'リズム', 'カナデ']
['22', 'スイートプリキュア♪', 'ビート', 'エレン']
['23', 'スイートプリキュア♪', 'ミューズ', 'アコ']
['24', 'スマイルプリキュア!', 'ハッピー', 'ミユキ']
['25', 'スマイルプリキュア!', 'サニー', 'アカネ']
['26', 'スマイルプリキュア!', 'ピース', 'ヤヨイ']
['27', 'スマイルプリキュア!', 'マーチ', 'ナオ']
['28', 'スマイルプリキュア!', 'ビューティ', 'レイカ']
['29', 'ドキドキ!プリキュア', 'ハート', 'マナ']
['30', 'ドキドキ!プリキュア', 'ダイヤモンド', 'リッカ']
['31', 'ドキドキ!プリキュア', 'ロゼッタ', 'アリス']
['32', 'ドキドキ!プリキュア', 'ソード', 'マコト']
['33', 'ハピネスチャージプリキュア!', 'エース', 'アグリ']
['34', 'ハピネスチャージプリキュア!', 'ラブリー', 'メグミ']
['35', 'ハピネスチャージプリキュア!', 'プリンセス', 'ヒメ']
['36', 'ハピネスチャージプリキュア!', 'ハニー', 'ユウコ']
['37', 'ハピネスチャージプリキュア!', 'フォーチュン', 'イオナ']
['38', 'Go!プリンセスプリキュア', 'フローラ', 'ハルカ']
['39', 'Go!プリンセスプリキュア', 'マーメイド', 'ミナミ']
['40', 'Go!プリンセスプリキュア', 'トゥインクル', 'キララ']
['41', 'Go!プリンセスプリキュア', 'スカーレット', 'トワ']
['42', '魔法つかいプリキュア!', 'ミラクル', 'ミライ']
['43', '魔法つかいプリキュア!', 'マジカル', 'リコ']
['44', '魔法つかいプリキュア!', 'フェリーチェ', 'コトハ']
['45', 'キラキラ☆プリキュアアラモード', 'ホイップ', 'イチカ']
['46', 'キラキラ☆プリキュアアラモード', 'カスタード', 'ヒマリ']
['47', 'キラキラ☆プリキュアアラモード', 'ジェラート', 'アオイ']
['48', 'キラキラ☆プリキュアアラモード', 'マカロン', 'ユカリ']
['49', 'キラキラ☆プリキュアアラモード', 'ショコラ', 'アキラ']
['50', 'キラキラ☆プリキュアアラモード', 'パルフェ', 'シエル']
['51', 'HUGっと!プリキュア', 'エール', 'ハナ']
['52', 'HUGっと!プリキュア', 'アンジュ', 'サアヤ']
['53', 'HUGっと!プリキュア', 'エトワール', 'ホマレ']
['54', 'HUGっと!プリキュア', 'マシェリ', 'エミル']
['55', 'HUGっと!プリキュア', 'アムール', 'ルールー']
['56', 'スター☆トゥインクルプリキュア', 'スター', 'ヒカル']
['57', 'スター☆トゥインクルプリキュア', 'ミルキー', 'ララ']
['58', 'スター☆トゥインクルプリキュア', 'ソレイユ', 'エレナ']
['59', 'スター☆トゥインクルプリキュア', 'セレーネ', 'マドカ']
['60', 'スター☆トゥインクルプリキュア', 'コスモ', 'ユニ']
【1-2】プリキュア名のラリルレロ利用率は?
プリキュアの名前で、
どこまでラリルレロが使われているのか、
使用率を確認するコードを書いていく。
# ラ行の文字数を数えるための関数 countMojisuu(input_str, "ラリルレロ")
def countMojisuu(input_str , check_str):
result_val = 0
for check_moji in check_str:
result_val += input_str.count(check_moji)
return result_val
# 単語のリストと、チェック対象文字列(今回はラリルレロなど)が与えられた時に、
# 全単語個数、そのうち何単語にチェック対象文字列が含まれるか、
# 全文字数、そのうち何文字がチェック対象文字か、を返す。
def CheckUsedRate(input_str_list, check_str):
total_kosuu = len(input_str_list)
used_kosuu = 0
total_mojisuu = 0
total_used_mojisuu = 0
for input_str in input_str_list:
used_mojisuu = countMojisuu(input_str , check_str)
if used_mojisuu >0:
used_kosuu += 1
total_mojisuu += len(input_str)
total_used_mojisuu += used_mojisuu
return total_kosuu, used_kosuu, total_mojisuu, total_used_mojisuu
# 上記の関数の結果を出力表示するための関数
def PrintUsedRate(total_kosuu, used_kosuu, total_mojisuu, total_used_mojisuu):
print("単語数: ",used_kosuu, " / ", total_kosuu, " ", round(used_kosuu/total_kosuu*100)," %")
print("文字数: ",total_used_mojisuu, " / ", total_mojisuu, " ", round(total_used_mojisuu/total_mojisuu*100)," %")
# プリキュア名簿から、プリキュアの名前、変身前の名前、のリストを作る
PRECURE_NAME_STR_LIST = [row[2] for row in PRECURE_NAME_DATA_LIST]
print(PRECURE_NAME_STR_LIST)
HENSINMAE_NAME_STR_LIST = [row[3] for row in PRECURE_NAME_DATA_LIST]
print(HENSINMAE_NAME_STR_LIST)
# ラリルレロの利用率を確認する
taisyou_str = "ラリルレロ"
print("プリキュア名の",taisyou_str,"利用率:")
total_kosuu, used_kosuu, total_mojisuu, total_used_mojisuu = CheckUsedRate(PRECURE_NAME_STR_LIST, taisyou_str)
PrintUsedRate(total_kosuu, used_kosuu, total_mojisuu, total_used_mojisuu)
print("")
print("変身前名の",taisyou_str,"利用率:")
total_kosuu, used_kosuu, total_mojisuu, total_used_mojisuu = CheckUsedRate(HENSINMAE_NAME_STR_LIST, taisyou_str)
PrintUsedRate(total_kosuu, used_kosuu, total_mojisuu, total_used_mojisuu)
プリキュア名の ラリルレロ 利用率:
単語数: 34 / 60 57 %
文字数: 37 / 251 15 %
変身前名の ラリルレロ 利用率:
単語数: 28 / 60 47 %
文字数: 32 / 166 19 %
プリキュア60名中34名 = 57%にラ行が入る。
また、文字数で見た場合、ラ行は15%を占めている。
ということが分かる。が、
変身前の時点で、かなり高い割合でラ行を使用している
ということも分かった。
【1-3】アイウエオ、カキクケコの利用率は?
1-2の引数を変えて実行すれば、
すぐに他の行の結果も確認することが出来る。
プリキュア名の アイウエオ 利用率:
単語数: 17 / 60 28 %
文字数: 18 / 251 7 %
変身前名の アイウエオ 利用率:
単語数: 23 / 60 38 %
文字数: 26 / 166 16 %
プリキュア名の カキクケコ 利用率:
単語数: 11 / 60 18 %
文字数: 11 / 251 4 %
変身前名の カキクケコ 利用率:
単語数: 27 / 60 45 %
文字数: 27 / 166 16 %
こちらは変身前後でかなり傾向に違いが出た。
【2】世の中の名詞全体の分析
【2-1】大量名詞データの準備
「しりとり」徹底分析!最強キャラ(文字)解説&5つの「驚愕」
の記事で作成した、しりとり用名詞データを再利用する。
自分でこのデータから作りたい人は上述の記事をご参照。
import pickle
# 保存したpickleファイルは、以下のように復元する
with open('drive/My Drive/PURI/siritori_noun_list.dump', 'rb') as f:
siritori_noun_list = pickle.load(f)
print(len(siritori_noun_list))
import pprint
pprint.pprint(siritori_noun_list[1000:1005])
下記のようなフォーマットで大量のデータ(360万レコード)が入っている。
3655284
[['へとへと', '名詞', '形容動詞語幹', 'ヘトヘト', 4, 'ヘ', 'ト', 'ヘ', 'ト'],
['極大', '名詞', '形容動詞語幹', 'キョクダイ', 5, 'キ', 'イ', 'キ', 'イ'],
['失当', '名詞', '形容動詞語幹', 'シットウ', 4, 'シ', 'ウ', 'シ', 'ウ'],
['冷酷', '名詞', '形容動詞語幹', 'レイコク', 4, 'レ', 'ク', 'レ', 'ク'],
['有数', '名詞', '形容動詞語幹', 'ユウスウ', 4, 'ユ', 'ウ', 'ユ', 'ウ']]
【2-2】「カタカナ単語」だけに絞る
全名詞を対象にするのは望ましくないと考え、
カタカナ語だけに絞った。(⇒ 68万語になった)
ここでのポイントは、カタカナ判定の正規表現。
re.compile(r'[\u30A1-\u30F4]+')
re.compile(r'[ァ-ン]+')
このような書き方をWeb上でよく見かけるが、
「ー(長音)」が入っていなかったり、いろいろ不都合があったため、
re.compile(r'[ァ-ヴー]+')
を採用。(参考:http://syutin.cside.ne.jp/diary/2017/08/755)
import re
re_katakana = re.compile(r'[ァ-ヴー]+')
katakana_noun_list = []
for noun_row in siritori_noun_list:
if re_katakana.fullmatch(noun_row[0]):
katakana_noun_list.append(noun_row[0])
# 重複の削除
katakana_noun_list= list(set(katakana_noun_list))
print(len(katakana_noun_list))
print(katakana_noun_list[4000:4010])
# 出力結果はこんな感じ
# 687432
# > ['ギョジ', 'サモハッカ', 'アランカ', 'ニホンキカクカブシキガイシャ',
# > 'ベイネッテ', 'モエシャ', 'モリーヘイガン', 'ワンナイト',
# > 'エメレク', 'ロクジュウゴテンロクキログラム']
元の辞書の性質上、「ゴヒャクロクジュウロクニンゲツ」のように
カタカナにしただけ&数字表現なども一部含まれるようだが、
全体の「傾向」を分析したい話なので、ここでは無視して先に進む。
【2-3】大量名詞に対する、ラリルレロ利用率の調査
プリキュアに対して実行したコードと、
全く同じコードで確認することが出来る。
taisyou_str = "ラリルレロ"
print("大量のカタカナ名詞中の、",taisyou_str,"利用率:")
total_kosuu, used_kosuu, total_mojisuu, total_used_mojisuu = CheckUsedRate(katakana_noun_list, taisyou_str)
PrintUsedRate(total_kosuu, used_kosuu, total_mojisuu, total_used_mojisuu)
大量のカタカナ名詞中の、 ラリルレロ 利用率:
単語数: 423932 / 687432 62 %
文字数: 641246 / 6845333 9 %
単語の利用率=62%、文字の利用率=9%
あれ!?
プリキュア名は、単語数 ⇒ 57%、文字数 ⇒ 15% だったので、
「ラリルレロ」が含まれる単語の割合は、一般名詞と大差がない。
つまり、
プリキュア60人中34人に「ラ行」が含まれる
という点だけでは実は、名詞全般の平均値と変わらない。
が、
もっと重要なのは、文字数に対する比率である。
文字数で見た時の利用率は9%対15%と、プリキュアの方がかなり上だ。
プリキュアの名前は3文字~6文字であるのに対し、
今回対象とした68万語の中には、もっと長い単語が多数あるため、
「ラリルレロを含む」という条件での比較は公平ではない。
よって、文字数に対しての比率で考えなければいけない、と分かった。
【3】プリキュア名と変身前名と一般名詞の可視化
【3-1】ア行~ラ行、全部の行に統計処理を適用
傾向を一括で可視化するため、
「ア行」「ラ行」など個別に適用していた加工処理を一括適用する。
「ワ」「ン」は「ヤ行」に分類した。
KATAKANA_TARGET_LIST = [
"アイウエオ", "カキクケコ", "サシスセソ",
"タチツテト", "ナニヌネノ", "ハヒフヘホ",
"マミムメモ", "ヤユヨワン", "ラリルレロ",
"ガギグゲゴ", "ザジズゼゾ", "ダヂヅデド",
"バビブベボ", "パピプペポ", "ー", "ッ",
"ャュョァィゥェォ"
]
precure_name_kosuu_rate = []
precure_name_mojisuu_rate = []
for taisyou_str in KATAKANA_TARGET_LIST:
total_kosuu, used_kosuu, total_mojisuu, total_used_mojisuu = CheckUsedRate(PRECURE_NAME_STR_LIST, taisyou_str)
precure_name_kosuu_rate.append(round(used_kosuu*100/total_kosuu))
precure_name_mojisuu_rate.append(round(total_used_mojisuu*100/total_mojisuu))
hensinmae_name_kosuu_rate = []
hensinmae_name_mojisuu_rate = []
for taisyou_str in KATAKANA_TARGET_LIST:
total_kosuu, used_kosuu, total_mojisuu, total_used_mojisuu = CheckUsedRate(HENSINMAE_NAME_STR_LIST, taisyou_str)
hensinmae_name_kosuu_rate.append(round(used_kosuu*100/total_kosuu))
hensinmae_name_mojisuu_rate.append(round(total_used_mojisuu*100/total_mojisuu))
noun_kosuu_rate = []
noun_mojisuu_rate = []
for taisyou_str in KATAKANA_TARGET_LIST:
total_kosuu, used_kosuu, total_mojisuu, total_used_mojisuu = CheckUsedRate(katakana_noun_list, taisyou_str)
noun_kosuu_rate.append(round(used_kosuu*100/total_kosuu))
noun_mojisuu_rate.append(round(total_used_mojisuu*100/total_mojisuu))
【3-2】matplotlibで可視化
作成したデータを可視化する。
本稿のハイライトがこの可視化のグラフ
import matplotlib.pyplot as plt
import numpy as np
import japanize_matplotlib
# 重要:日本語文字化け防止
# !pip install japanize-matplotlib
def DrawBouGraph(listA , listB, listC, labels):
# numpyの横軸設定
left = np.arange(len(listA))
labels = KATAKANA_TARGET_LIST
width = 0.3
plt.figure(figsize=(30, 10), dpi=50)
plt.bar(left, listA, color='r', width=width, align='center', label="プリキュア")
plt.bar(left+width, listB, color='g', width=width, align='center', label="変身前")
plt.bar(left+width+width, listC, color='b', width=width, align='center', label="全名詞")
plt.xticks(left + width/2, labels)
plt.legend()
plt.show()
#plt.savefig('xxxxx.png')
このようなグラフ化関数を使って、データの可視化をしよう!
【3-3】○行が含まれる率の可視化(ご参考)
文字数で見ないと意味が薄いが、せっかくなのでこちらも掲載。
DrawBouGraph(precure_name_kosuu_rate, hensinmae_name_kosuu_rate, noun_kosuu_rate, KATAKANA_TARGET_LIST)
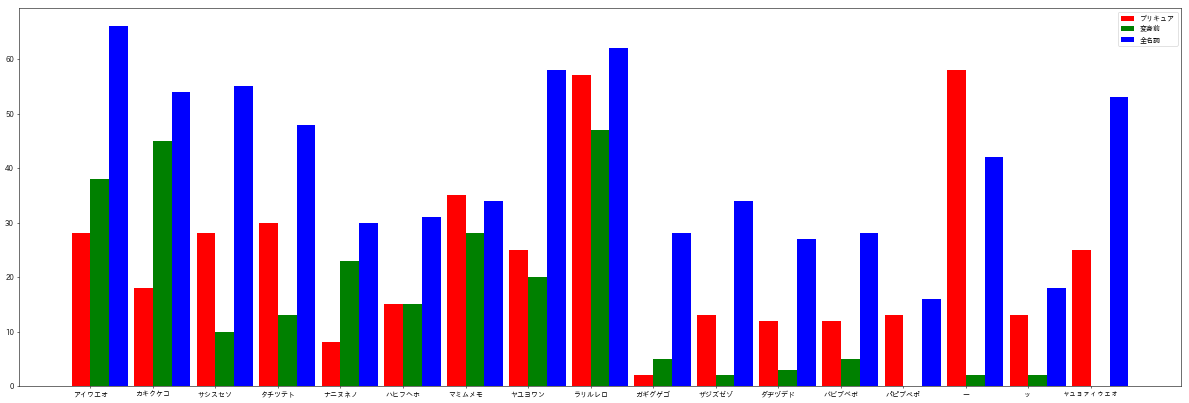
青 = 一般名詞 は(今回採用したデータ内に)文字数が長いものが多いため、
全体的に高い割合になっている。
【3-4】○行の文字数率の可視化(本命グラフ)
こちらが本命、本稿のハイライト
DrawBouGraph(precure_name_mojisuu_rate, hensinmae_name_mojisuu_rate, noun_mojisuu_rate, KATAKANA_TARGET_LIST)
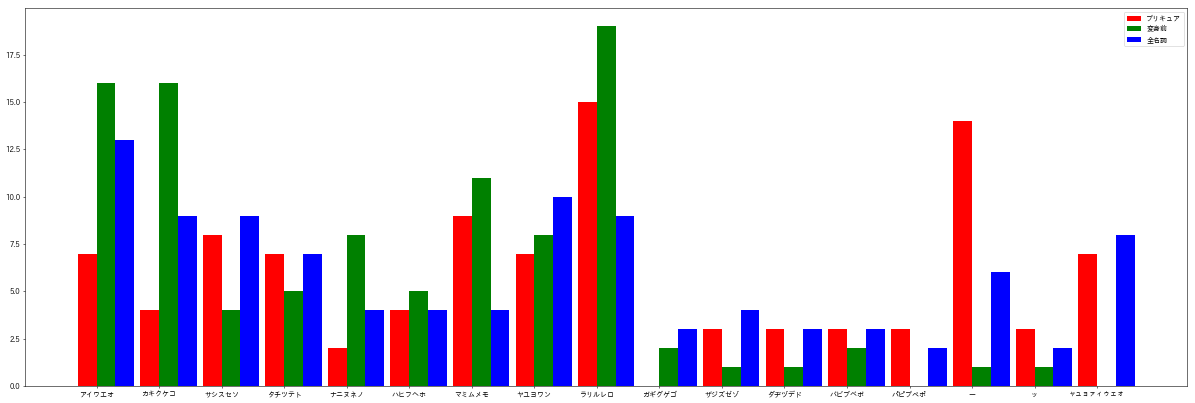
【3-5】可視化した結果の考察
一般名詞=青、では、
「ア行」「カ行」「サ行」「ヤワ行」「ラ行」の使用率が高い。
プリキュア名=赤、では、
「ラ行」「ー(長音)」「マ行」の使用率が高く、
一般でTOPだった「ア行」などは逆にかなり減っている。
変身前名=緑、では
「ラ行」「マ行」はプリキュア名と傾向が近いものの、
「ア行」「カ行」の使用率も高い。
(※今回対象を「カタカナ」にしているため、
変身前名に対する考察は、ご参考程度)
このことから考察すると、
「ラ行」「マ行」が、きらきらしたカワイイ感じとして、
プリキュア名や変身前女子名として採用率が高い、という傾向がある。
逆に、「ア行」「カ行」は、一般的によく使われるために、
プリキュア名として採用すると、ふつーな感じ、になってしまうので、
きらきら感を出すために採用率が低くなっている、という傾向がある。
「ラ行」は普通にプリキュアの名前だけ見ていても高採用率だが、
実は「マ行」の方が、一般名詞との利用比率乖離でみると、
「ラ行」より高い倍率で使われているのだ!!
これには園児もびっくりすること間違いなし。
プリキュア界において特筆すべき新発見である。
【4】プリキュア的きらきら感を判定できる関数で遊ぶ
【4-1】プリキュアきらきら名前チェッカー
さきほどのグラフの「赤」「青」をよーく見比べてみると、
各行は3パターンに分類出来ることに気づく。
① プリキュアの方が2倍くらい多い行
② 利用率がほぼ変わらない行
③ プリキュアの方が半分くらいの行
そこで、プリキュア的にきらきらしている名前かどうか、
判定出来る簡単なロジックを思いついた。
超単純に、①の文字はプラス1点、③の文字はマイナス1点、で数えるだけだ。
名付けて**「プリキュアきらきら名前チェッカー」**
def eval_pricure_do(input_str):
result_point = 0
for itimoji in input_str:
if itimoji in "アイウエオカキクケコナニヌネノガギグゲゴ":
result_point -= 1
continue
if itimoji in "サシスセソタチツテトハヒフヘホヤユヨワンザジズゼゾダヂヅデドバビブベボパピプペポッャュョァィゥェォ":
result_point += 0
continue
if itimoji in "マミムメモラリルレロー":
result_point += 1
continue
#何か異物文字が混入しているということ
result_point -=10
return result_point
# この名前チェッカーを全プリキュアに適用する
import copy
tmp_list = copy.deepcopy(PRECURE_NAME_STR_LIST)
tmp_list = list(map(lambda input_str : (input_str, eval_pricure_do(input_str)), tmp_list))
import pprint
pprint.pprint(tmp_list)
全プリキュアの名前をこの関数により評価した結果を見てみよう。
驚きの結果が明らかになる。
[('ブラック', 0),
('ホワイト', -1),
('シャイニールミナス', 0),
('ブルーム', 3),
('イーグレット', 0),
('ドリーム', 3),
('ルージュ', 2),
('レモネード', 2),
('ミント', 1),
('アクア', -3),
('ローズ', 2),
('ピーチ', 1),
('ベリー', 2),
('パイン', -1),
('パッション', 0),
('ブロッサム', 2),
('マリン', 2),
('サンシャイン', -1),
('ムーンライト', 2),
('メロディ', 2),
('リズム', 2),
('ビート', 1),
('ミューズ', 2),
('ハッピー', 1),
('サニー', 0),
('ピース', 1),
('マーチ', 2),
('ビューティ', 1),
('ハート', 1),
('ダイヤモンド', 0),
('ロゼッタ', 1),
('ソード', 1),
('エース', 0),
('ラブリー', 3),
('プリンセス', 1),
('ハニー', 0),
('フォーチュン', 1),
('フローラ', 3),
('マーメイド', 2),
('トゥインクル', -1),
('スカーレット', 1),
('ミラクル', 2),
('マジカル', 1),
('フェリーチェ', 2),
('ホイップ', -1),
('カスタード', 0),
('ジェラート', 2),
('マカロン', 1),
('ショコラ', 0),
('パルフェ', 1),
('エール', 1),
('アンジュ', -1),
('エトワール', 1),
('マシェリ', 2),
('アムール', 2),
('スター', 1),
('ミルキー', 2),
('ソレイユ', 0),
('セレーネ', 1),
('コスモ', 0)]
なんと60名中59名が、マイナス1以上であった。
コードは省略するが、プリキュアの文字数に合わせて、
3文字~6文字の一般名詞(18万7千語)に対して
同様の確認をした場合、
マイナス1以上になるのは全体の77%
つまり、一般名詞の割合で見ると、
4人に1人くらいはマイナス2以下が居て、
60名中で考えると13人くらい居るのが普通なのに、
1人(キュアアクア)しかマイナス2以下が居なかった。
もちろん数値で見ても各メンバーの値は大きめである。
60人中59人が当てはまる、
**プリキュアの秘密(のネーミングルール)**を見つけてしまった!
【4-2】「ラーメン」の人気の秘密
プリキュアきらきら名前チェッカーを「ラーメン」に適用すると、
ラーメン = 3
(ラ,ー,メ がそれぞれ1ポイント、ン、はゼロ)
プログラムを書くまでもなく、プラスとマイナスの「行」を
覚えておくだけで簡単に暗算判定が出来る。
やはり、
「ラーメン」はプリキュアに通じるところのある、
きらきらカワイイ感があふれるネーミングセンスだった
なお、
ゴリラ = 1
ラオウ = マイナス1
「ラーメン」という名前をつけたことによって、
爆発的にヒットが加速した、と元記事に記載があったが、
あながち間違いではなく、プリキュアとの関連性についても、
より強固な相似要素を見つけることが出来た。
(「ラ」だけでなく「メ」や「ー」も相似要素)
もしあなたが今後カタカナ名を考える場合は、
このプリキュアきらきら名前チェッカーを参考にして
「ラリルレロマミムメモー(長音)」を
出来るだけ取り入れるように考えると人気が出るかもしれない。
【4-3】最もプリキュアにふさわしい名前は何か?(失敗談)
ここまで、個人的には大変興味深い結果であった。
さらに、きらきら感を数値化出来るのであれば、
「最もプリキュアにふさわしい名詞は何か?」
をプログラムで見つけたくなってしまうのが人情というもの。
全名詞の中から、
プリキュアきらきら名前チェッカーが最大値を示す名詞
を探してみた。(コードは単純なので省略する)
すると、なんと**「14」**というものが見つかった!!
それは・・・
シンプルニセンシリーズボリュームザビショウジョシミュレーションアールピージームーンライトテール
!?
「シンプル2000シリーズボリュームTHE美少女シミュレーションRPGムーンライトテール」
こんな単語が(mecabの)辞書の中にカタカナとして入っていたことにも驚きだが
プリキュアの名前として**「ぶっちゃけありえない」**(言うまでもない)
3文字~6文字に限定して実施すると、
「6」が同率で複数見つかった。
マリーロール、メリーメリー、メリメロマル、など。
意味は良くわからない。
プリキュアきらきら名前チェッカーの改善すべき点として、
単純な加減算ではなく、
文字数の長さに応じて平均値を取るなどを考慮すべきかもしれない。
(平均値にしてしまうと、今度は文字が少ない方が有利になるため、悩ましいところ)
プリキュアの中にも「マイナス1」までは複数いるため、
これ以上は最大値を追求せずに、
「マイナス1以上が妥当と分かった」という話にとどめておこう。
【5】オマケ:Word2Vecによる今後のプリキュア名の推定
上述までで、一旦当初目的は達成済みであるが、
意地で、次回作以降のプリキュアの名前をプログラムで算出してみる。
Word2Vecという技術を使う(いつものヤツね)
Word2Vecについては以下ご参考:
【続】AIが三国志を読んだら、孔明が知力100、関羽が武力99、を求められるのか?をガチで考える物語(Word2Vec編)
長くなるので詳細は割愛するが、
ポイントは、以下のような関数を作って、
各単語に対して、歴代プリキュア名との
**「単語としての類似度の平均」**を求めて、
それを高い順にリストアップするというもの。
(但し、3文字~6文字で、
プリキュアきらきら名前チェッカーの結果がマイナス1以上に限定)
from gensim.models.word2vec import Word2Vec
import gensim
# 日本語wikipediaから生成したWord2Vecモデルの読み込み
model_path = 'drive/My Drive/PURI/word2vecmodel_fromWIKI_NEOLOGD01.model'
model = Word2Vec.load(model_path)
def ave_sim_do(input_str, check_str_list):
result_val = 0
for check_str in check_str_list:
try:
sim_do = model.similarity(input_str, check_str)
#print(sim_do)
except:
#そのチェック対象の文字列が無い場合はゼロ扱い
#print("KeyError", check_str)
sim_do = 0
pass
result_val += sim_do
return result_val/len(check_str_list)
ave_sim_do("スター", PRECURE_NAME_STR_LIST)
# > 0.28982034724516176
~~~他の関数は省略~~~
結果に飛ばす。
[('ピーチ', 1, 502.0, 0.4792090936253468, True),
('ストロベリー', 3, 232.0, 0.4721409846097231, False),
('レディー', 2, 287.0, 0.4621714613089959, False),
('マジカル', 1, 301.0, 0.45772725256780783, True),
('ウィッシュ', -1, 154.0, 0.45130613862226404, False),
('スウィート', 0, 476.0, 0.45082837815086046, False),
('ムーン', 2, 1311.0, 0.448010998715957, False),
('レディ', 1, 1399.0, 0.4460138124297373, False),
('シュガー', 0, 459.0, 0.44292359420408806, False),
('アイリス', -1, 506.0, 0.44178551333025096, False),
('ハニー', 0, 367.0, 0.4413684260565788, True),
('ファイン', -1, 221.0, 0.4410709965818872, False),
('ミント', 1, 572.0, 0.4408927426363031, True),
('パッション', 0, 238.0, 0.4392520201082031, True),
('キャット', -1, 288.0, 0.4371894449926913, False),
('ルージュ', 2, 346.0, 0.4366619746511181, True),
('ファイアー', -1, 255.0, 0.43606505828599135, False),
('マーメイド', 2, 216.0, 0.43515188035865626, True),
('バージン', 1, 141.0, 0.43372481496383747, False),
('プリティ', 1, 116.0, 0.4328366027524074, False),
('ミルキー', 2, 115.0, 0.43272389558454355, True),
('バニー', 0, 179.0, 0.43145679887384175, False),
('ワンダー', 1, 382.0, 0.4313376608925561, False),
('ウーマン', 1, 442.0, 0.431137225124985, False),
('クリムゾン', 1, 268.0, 0.43021388749281564, False),
('ブロッサム', 2, 125.0, 0.4290103747198979, True),
('サンシャイン', -1, 638.0, 0.42721113486525913, True),
('ミラクル', 2, 674.0, 0.4264821488410234, True),
('パンプキン', -1, 130.0, 0.425747458015879, False),
('ブルー', 2, 5445.0, 0.42543597308297953, False),
('プリンセス', 1, 1548.0, 0.4242299640551209, True),
('エンジェル', 0, 1468.0, 0.42417359094057855, False),
('ファイヤー', 0, 357.0, 0.4232226965017617, False),
('ダンシング', -1, 209.0, 0.42321491818875073, False),
('プレジャー', 2, 104.0, 0.42315283194184306, False)]
一位は「ピーチ」!
って、既に60名の中にいるじゃん。。。
ということで、右端に既存名の存在判定を付与。
「True」は既に登場している名前。
それを除外して見ていくと、
「ストロベリー」「レディー」「ウィッシュ」
「スウィート」「ムーン」「シュガー」・・・・。
プリキュアに居ても違和感の無い名前が出ているのではないか?
これは単純にWord2Vecの評価結果だけで順に並べているが、
プリキュアきらきら名前チェッカーの値との足し算や、
文字数等のルールをいろいろ決めて試すと面白い。
ざっと上位300位あたりまで眺めて、いくつかピックアップすると、
「ホーリー」「パール」「プラネット」「ラビット」
「ブリリアント」「ノワール」「ラッキー」「マーブル」
「ジャスミン」「メイプル」「ビーナス」などなどが出ていた。
このWord2Vecによる評価ならば、
「ラーメン」はプリキュア名としてイマイチ、
という評価をすることが出来る。
(※それでも0.13くらいで、下位のプリキュアより高いくらいであったが)
【6】結論まとめ
プリキュアのかわいさと、ラーメンの人気の秘密は、
「ラ行」「マ行」「ー(長音)」であり、
「ア行」「カ行」のようなふつーの音は使用を控えることが望ましい。
(プリキュア60名中59名がこのルールに準じていると言える)
また、以下の2点の評価を用いることで、「プリキュアっぽい名前」を
プログラムで探索することが出来た。(主観に基づく結論です)
① プリキュアにふさわしい音 = プリキュアきらきら名前チェッカー
② プリキュアにふさわしい意味 = Word2Vecの評価平均
備考:変身前の名前で見ても、「ラ行」「マ行」の人気は高く、
全体的に「ラ行」「マ行」は女子力が高いのかもしれない。
女子の名前づけに使えるノウハウを得ることが出来た。
終わりに
日本語は、母音×子音でなんとなく50音は平等というイメージがあった。
一方で、きらきら感によって音で受ける印象が違う、という点は興味深い。
「プリキュアきらきら名前チェッカー」は、
暗算でも出来る内容であるため、ぜひみなさまも
いろいろなものの名前への適用をすると面白いかもしれない。
プリキュアの美しき言葉で、
邪悪な心を打ち砕きましょう!!
以上。
後日追記:ブルボンはプリキュア以上にきらきら!
ラ行ゴリ押しの企業といえばブルボン
商品のほとんどにラ行が付いてます。
fujikenbotebote さんにコメントでお教えいただき、
気になったのでざっくり試してみたら、
さらなる衝撃の結果が生まれた。
[('アルフォート', 1),
('エブリバーガー', 1),
('エリーゼ', 1),
('ガトーレーズン', 2),
('ショコラセーヌ', 0),
('シルベーヌ', 1),
('シルベーヌ', 1),
('スローバー', 3),
('セブーレ', 2),
('チョコチップ', -1),
('チョコバーム', 1),
('チョコブラウニー', -1),
('チョコラングドシャ', -1),
('チョコリエール', 1),
('バームロール', 5),
('パキーラ', 1),
('フェットチーネ', 0),
('プチ', 0),
('ブランチュール', 3),
('ホワイトショコラ', -1),
('ホワイトロリータ', 2),
('マロンブラン', 3),
('ミルファス', 2),
('ラシュクーレ', 2),
('リッチミルク', 2),
('ルーベラ', 3),
('ルマンド', 2),
('レーズンサンド', 2),
('レーズンラッシュ', 3),
('ロアンヌ', -1)]
これはすごいっっっ!!!
てきとうに挙げた30項目中「-2」以下は一個も無し!
ブルボンのきらきら度平均値=「1.3」の超高水準をマーク!!
※プリキュア平均= 0.65
※全単語平均 =-0.64
ブルボンはプリキュアを超えるきらきら感があった
「なお 受け取っていない………!
ブルボンからは 1円も……!」
by ハンチョウ ~ブルボンドラフト会議~
ほかにもいろいろ試してみたくなる。。。