背景
しりとりで最強のキャラ(文字)は?
**「ル」**が圧倒的に有名である。
しかし、実際に「ル」以外はダメなのだろうか?
濁音、半濁音がありの状態では、
「ル」以外にどの文字が強いのか?
「しりとり」を知らぬものは居ないが、
「しりとり」の深淵はまだ誰も知らない。
「しりとり」の深淵をのぞく時、「しりとり」もまたこちらをのぞいているのだ。
~ Char Fuitter (1847~1912 オランダ) ~
しりとりを徹底分析すると、驚きの新事実が見えてきた。
というのが今回のテーマ。
決して、よく他サイトの「しりとり必勝法」でありがちな
「ル」で始まる単語一覧を作った、とかではない。
しりとり道を究めんとする修験者たちの集い、に挑戦
QuizKnockというYouTuber集団をご存知だろうか?
伊沢拓司さんという、テレビでも有名な東大生クイズ王が発起人となったチームで、
日本超トップクラスの頭脳を無駄な方向に活用する様子を垂れ流している
とても知的で興味深い教養溢れる記事/番組を多数作成している。
そして、妙に「しりとり」に関する動画が多い。
彼らの中でも、自身をそう認識しており、
「しりとり道を究めんとする修験者たちの集い」
とまで言っている。
皆さん、QuizKnockといえば、どんなイメージをお持ちですか?
知的?楽しい?ためになる?いいヒマつぶし?
筆者(編集部N)のイメージは違います。
筆者のイメージは「しりとり道を究めんとする修験者たちの集い」です。
by http://quizknock.com/grandwords/
実際、その例は多数見つかる。
驚くべき高度・高レベルな単語のやり取りがされているのでヒマな時に必見である。
◆記事:勝手に第1.5回東大王開催! 「限界しりとり」で水上・鶴崎と対決!
◆Youtube動画:【超えろパオパオチャンネル】東大生が「増殖しりとり」したら超すごい記録が出るのか?
「しりとり」なんて子供の遊びでしょ?と思ったあなた、
「しりとり」には多数のアレンジルールを絡めることが出来る。
上記の「増殖しりとり」をはじめ、「限界しりとり」「アポロしりとり」など
大人の遊びとして、QuizKnock内でも多数のやりとりが紹介されている。
東大生も熱中する遊びとして、今まさにしりとり道が熱い!
今回のテーマは、そういったアレンジしりとりにおいても、
必ず役立つレベルの基礎データを提供できると思う。
全キャラ(文字)の詳細ステータスを解説する。
「文字」だけにまさに「キャラ」characterの解説、という高度で知的なギャグ
そして、日本人として一読するべき興味深い結果が出たと思う。
**5つの「驚愕」**として後述する。
ぜひ、今回の結果を活用して、しりとり好きなお子様を完膚なきまでに叩きのめして欲しい
さらに、おまけとして**「増殖しりとり」は何文字までいけるのか研究したい**。
(※「か」⇒「かさ」⇒「さかな」⇒「なぞなぞ」のように1文字ずつ増加するしりとり)
本投稿の内容
- 本気でしりとりをPythonで解析する。
- 結論/成果① = 全キャラ(文字)のステータスを解析
- 結論/成果② = 分析した結果の5つの「驚愕」
- 結論/成果③ = 最長の増殖しりとりを生成する試み
- 上記3点に達するまでは、様々な試行錯誤があったため、その苦労を解説。
- コードの実行環境は全て、Windows10 + Python3 +JupyterNotebook を前提。
将来的に、本投稿の内容を応用して、さまざまなアレンジしりとり用のAIも出来るかも。
東大生とAIの対戦なども実現できるかもしれない。
しりとり、のルールとは?(定義)
しりとりのローカルルールは数しれず。
分析を始める前に、定義をしないと話がかみ合わない。
下手なルール設定だと、「ハナヂ(鼻血)」と言った瞬間、
「ジ」に変えてはいけない場合、
「ヂ」で始まるものが思いつけずに負け、とか、
「ヲ」攻めとか(「りんな」に対する攻略手段)、
あまり面白くない攻略方法が可能になってしまう。
良く使われていると思われるルールで、
特殊すぎる攻撃が出来ないような形で、
Wikipediaなどを参考に以下のルールを設定した。
挙げる単語は「名詞」に限る
- 一般的な常識としてよく知られた固有名詞、はOKとする。
- 国名、地名、大都市の名前、トヨタなどの企業名、長嶋茂雄などの有名人等
- 禁止とするルールもあるが「ホッチキス」「セロテープ」など一般化した商品名もあり煩雑
- 数詞は使用禁止
- 「10001」「10232」や、「3個」などの単位との組み合わせなど。無限にあるので禁止
最後の長音は無視して前の音を採用する
- 例:「ミキサー」→「サ」から続ける
- 上記の場合、文字数としては「4文字」で、「ミキササ」的な扱いになるということ。
- 他に、母音にするルール(「ア」)、長音を含んで答えるルール(「サー」)などもある。
- 分析後、最強は「サー」攻撃でした、など分かっても一般的に使いにくいので無視ルールにする
最後の文字が拗音・促音の場合、清音に戻す(小さい文字は巨大化)
- 例:「キシャ(汽車)」→「ヤ」から続ける
- 他に、「シャ」のまま続けるルールもあるが、使いにくいために巨大化ルールにする
- 実際は、「ッャュョァィゥェォヮ」を巨大化するということ
濁音・半濁音は、清音に戻さずそのまま使う
- 例:「ショウガ(生姜)」→「ガ」から続ける。「カ」に変えられない。
- これは結構ルールが分かれるかもしれない。分析の面白さ/有用性的にそのままルールにする
旧仮名遣い(や特殊な仮名)は、現代仮名遣いと可変扱いとする
具体的には、以下のパターン:
- ジヂは同一とみなす(ヂ⇒ジ)
- ヅズは同一とみなす(ヅ⇒ズ)
- ブヴは同一とみなす(ヴ⇒ブ)
- ヰイは同一とみなす(ヰ⇒イ)
- ヱエは同一とみなす(ヱ⇒エ)
- ヲオは同一とみなす(ヲ⇒オ)
ハナヂ(鼻血)や、コウヅ(国府津)などで瞬殺を防ぐため。
どちらも互換性のある文字として使って良いということ。
余談
しりとりは、先に有限な全単語が与えられている場合は、
「零和有限確定完全情報ゲーム」であり、
グラフ理論で解こうとする研究もある。
しかし、個人的にはしりとりの本質は、「単語の発見」側であると考えるため、
ここではグラフ理論側のテーマには触れない。
分析実施:名詞の抽出とデータ加工と集計
ルールが定義出来たので分析を開始する。
まず、取得元の辞書をどうするのか?が一番重要になる。
単語数が多くなることを重視して、
mecabのデフォルトの辞書に追加して、
mecab-ipadic-neologdの新語辞典も用いることにした。
それぞれ、ソースコードから、CSVデータもダウンロードできる。
CSVデータの中から、noun(名詞)を主として、数詞ではないデータを、
特定のファイルの中にまとめて配置し、それをPythonで読み込むことにする。
CSVデータのロード
import csv
import codecs
import glob
# 特定のCSVファイルをロードして、dfを生成する。
def read_csv_noun_files(path_for_all_csv):
# 複数のCSVの全てのファイルパスを取得する。
files = glob.glob(path_for_all_csv)
csv_read_list = []
print(len(files))
for filepath in files:
with codecs.open(filepath, 'r', 'utf-8') as f:
reader = csv.reader(f)
#header = next(reader) # ヘッダーを読み飛ばしたい時
for row in reader:
#rowはList
genkei=row[0]
hinsi=row[4]
s_hinsi=row[5]
yomi=row[11]
nagasa=len(yomi)
sentou=yomi[0]
matubi=yomi[-1]
if hinsi.startswith("名詞"):
tango_info=[genkei,hinsi,s_hinsi,yomi,nagasa,sentou,matubi]
csv_read_list.append(tango_info)
return csv_read_list
csv_read_list = read_csv_noun_files(r'noun_for_siritori/*/*.csv')
print(len(csv_read_list))
print(csv_read_list[:5])
14
3655310
[['きらびやか', '名詞', '形容動詞語幹', 'キラビヤカ', 5, 'キ', 'カ'], ['史的', '名詞', '形容動詞語幹', 'シテキ', 3, 'シ', 'キ'], ['プラトニック', '名詞', '形容動詞語幹', 'プラトニック', 6, 'プ', 'ク'], ['てらてら', '名詞', '形容動詞語幹', 'テラテラ', 4, 'テ', 'ラ'], ['静謐', '名詞', '形容動詞語幹', 'セイヒツ', 4, 'セ', 'ツ']]
合計14ファイルを読み込み、
3,655,310語の名詞を取得したことになる。
処理中、先頭と末尾の文字も取得しているが、
実際しりとりに使うのは特殊ルールを付与した状態であるため、
直接は、上記で取得した文字は使わない。
実は、しりとりのルールについては、データ解析結果を見ながら何度か見直している。
最初に、加工処理をしない上記の状態で集計してみて、
例えば、「ヴ」の存在を完全に忘れていたなー、なんて眺めていたのだ。
加工処理を作ってから集計すると、個数が合わなくても、
加工処理のプログラムが悪かったかも、と原因が分からなくなるため、
どんなデータが入っているのか不明な場合は、原型で少し眺めてから加工した方がよい。
なお、詳細な品詞のパターンとしては、以下の7種類であった。
['形容動詞語幹', '副詞可能', '一般', '代名詞', 'ナイ形容詞語幹', '固有名詞', 'サ変接続']
見慣れないものだけ例を挙げておく。
- 形容動詞語幹:きらびやか、プラトニック
- 副詞可能:十中八九、一層、直接
- ナイ形容詞語幹:味け、素っ気、申しわけ
- サ変接続:気乗り、静止、察知
しりとりルールの実装
しりとりルールでは、文字列的に単純に末尾の文字を使うのではなく、
長音に対する対応や、小さい文字の巨大化、旧字体の変換などが必要。
その変換処理や、辞書の内容チェックを行うために、以下の関数を実装する
# 語句として、あり得る全ての発音
gojyuu_on_list =u"アイウエオカキクケコサシスセソタチツテトナニヌネノ"
gojyuu_on_list+=u"ハヒフヘホマミムメモヤユヨラリルレロワヲン"
gojyuu_on_list+=u"ガギグゲゴザジズゼゾダヂヅデドバビブベボパピプペポ"
gojyuu_on_list+=u"ッャュョー"
gojyuu_on_list+=u"ヰヱ"
gojyuu_on_list+=u"ァィゥェォ"
gojyuu_on_list+=u"ヴヮ"
# しりとりとして、許可する先頭&最後の文字
gojyuu_on_ok_list =u"アイウエオカキクケコサシスセソタチツテトナニヌネノ"
gojyuu_on_ok_list+=u"ハヒフヘホマミムメモヤユヨラリルレロワン"
gojyuu_on_ok_list+=u"ガギグゲゴザジズゼゾダデドバビブベボパピプペポ"
def get_siritori_sentou(input_yomi):
first=input_yomi[0]
if first==u'ヂ':
return u'ジ'
if first==u'ヅ':
return u'ズ'
if first==u'ヴ':
return u'ブ'
if first==u'ヰ':
return u'イ'
if first==u'ヱ':
return u'エ'
if first==u'ヲ':
return u'オ'
if first==u'ッ':
return u'ツ'
if first==u'ャ':
return u'ヤ'
if first==u'ュ':
return u'ユ'
if first==u'ョ':
return u'ヨ'
if first==u'ァ':
return u'ア'
if first==u'ィ':
return u'イ'
if first==u'ゥ':
return u'ウ'
if first==u'ェ':
return u'エ'
if first==u'ォ':
return u'オ'
if first==u'ヮ':
return u'ワ'
if first not in gojyuu_on_ok_list:
print("Err")
print(input_yomi)
return first
def get_siritori_matubi(input_yomi):
last=input_yomi[-1]
if last==u'ー':
last = input_yomi[-2]
#冒頭の文字変換と同様の枠に入れる
result = get_siritori_sentou(last)
#「イルヴァーモーー」だけ長音が二文字続いてエラーになった。
if result ==u'ー':
print(input_yomi)
return result
※shiracamusさんのコメントのとおり、本来は辞書を使うとif部分を短く書ける
良い子はマネしてはいけない。
最初は4個しかなかったのに、後で追加して段々長くなってしまった。
早速、この関数を使って、生成した名詞のリストに対して、
しりとりとしての先頭の文字、
しりとりとしての末尾の文字、
のデータを付与する。
# tango_info=[genkei,hinsi,s_hinsi,yomi,nagasa,sentou,matubi]
siritori_noun_list=[]
for tango_info in csv_read_list:
genkei=tango_info[0]
hinsi=tango_info[1]
s_hinsi=tango_info[2]
yomi=tango_info[3]
nagasa=tango_info[4]
sentou=tango_info[5]
matubi=tango_info[6]
#辞書中に誤登録されているデータがあり、末尾が二重長音になっているため修正
if yomi == u'イルヴァーモーー':
yomi=u'イルヴァーモーニー'
nagasa=len(yomi)
if yomi == u'イルヴァーモーーマホウマジュツガッコウ':
yomi=u'イルヴァーモーニーマホウマジュツガッコウ'
nagasa=len(yomi)
#よほど変なモノ(英語や記号など入りのミス登録的なデータ)は入れない(26個あった)
#本来ヨミガナの部分がアルファベットだったり、など。
if(sentou not in gojyuu_on_list or matubi not in gojyuu_on_list):
#print(tango_info)
pass
else:
siri_sentou=get_siritori_sentou(yomi)
siri_matubi=get_siritori_matubi(yomi)
siritori_info=[genkei,hinsi,s_hinsi,yomi,nagasa,sentou,matubi,siri_sentou,siri_matubi]
siritori_noun_list.append(siritori_info)
print(len(siritori_noun_list))
# > 3655284
結果は、3,655,284単語になった。
今回使っている辞書データ中には、
長音が二連続していた「イルヴァーモーー」のような異常データ2件と、
ヨミガナの部分に英字、記号、ひらがななどが入っていて
除外しなければいけないデータ26件があった。
また、後で発覚したのだが、
「目」「芽」などの異なる意味の同音データや、
英語表記とカタカナ表記などの、表記が違う同音データが含まれており、
実際に使用して良い単語は、上記数値よりも、もう少し減る。
また、しりとりで使用したら喧嘩になるレベルの変な語句も多いため、
まじめに「しりとり」の対戦AIなどを作る場合は、
もう少し正確性の高い辞書をベースにしたほうが良いかもしれない。
以前以下の記事で作った、Wikipediaで使用されている語句+その使用頻度
(記事: メロンとメロンパンを、キカイが探す物語 )
のデータなどは、今後使いやすそうである。
しかし、今回は、主目的は「分析」である。
「ル」で始まる単語の数と、「ウ」で始まる単語の数の傾向を見よう、
という話がやりたいことであるため、
面倒なのでそのあたりまでの単語のお洗濯はしなくて良いだろう。
集計作業
さて、上記までで、使える名詞の一覧と、
その各単語がしりとりルール上、何で始まって、何で終わるか、を得ることが出来た。
いよいよ結果を集計する。
「X」から始まって、「Y」で終わる単語、という、
合計で、68×68の内容を集計する。
# siritori_info=[genkei,hinsi,s_hinsi,yomi,nagasa,sentou,matubi,siri_sentou,siri_matubi]
siritori_syuukei_ok_dict={}
# 以下の形で、先頭から最後までの値をカウントする
# { ('sentou','matubi') : 'count' }
for siritori_info in siritori_noun_list:
key = (siritori_info[7],siritori_info[8])
#へんなモノ(入っていない予定)は入れない。
if(siritori_info[7] not in gojyuu_on_list or siritori_info[8] not in gojyuu_on_ok_list):
print(siritori_info)
else:
siritori_syuukei_ok_dict.setdefault(key, 0)
siritori_syuukei_ok_dict[key]+=1
print(len(siritori_syuukei_ok_dict))
print(siritori_syuukei_ok_dict[("ア","ア")])
print(siritori_syuukei_ok_dict)
# dict形式では流用しにくいため、以下のようにして行ごと表示
siritori_syuukei_ok_hyou=[]
for sentou in gojyuu_on_ok_list:
txt=""+sentou
for matubi in gojyuu_on_ok_list:
#keyが無かった場合もエラーにならないようにする
val=siritori_syuukei_dict.get((sentou,matubi),0)
txt+="\t"+str(val)
print(txt)
上記によって得られた、68×68の表を、
エクセルに張り付けて、いろいろ分析出来る状態を作った。
かなり凶悪な表であるため、ここでは、紙面と分かりやすさの都合上、
その縦横の合計値をまとめたサマリ結果を、以降でご報告したい。
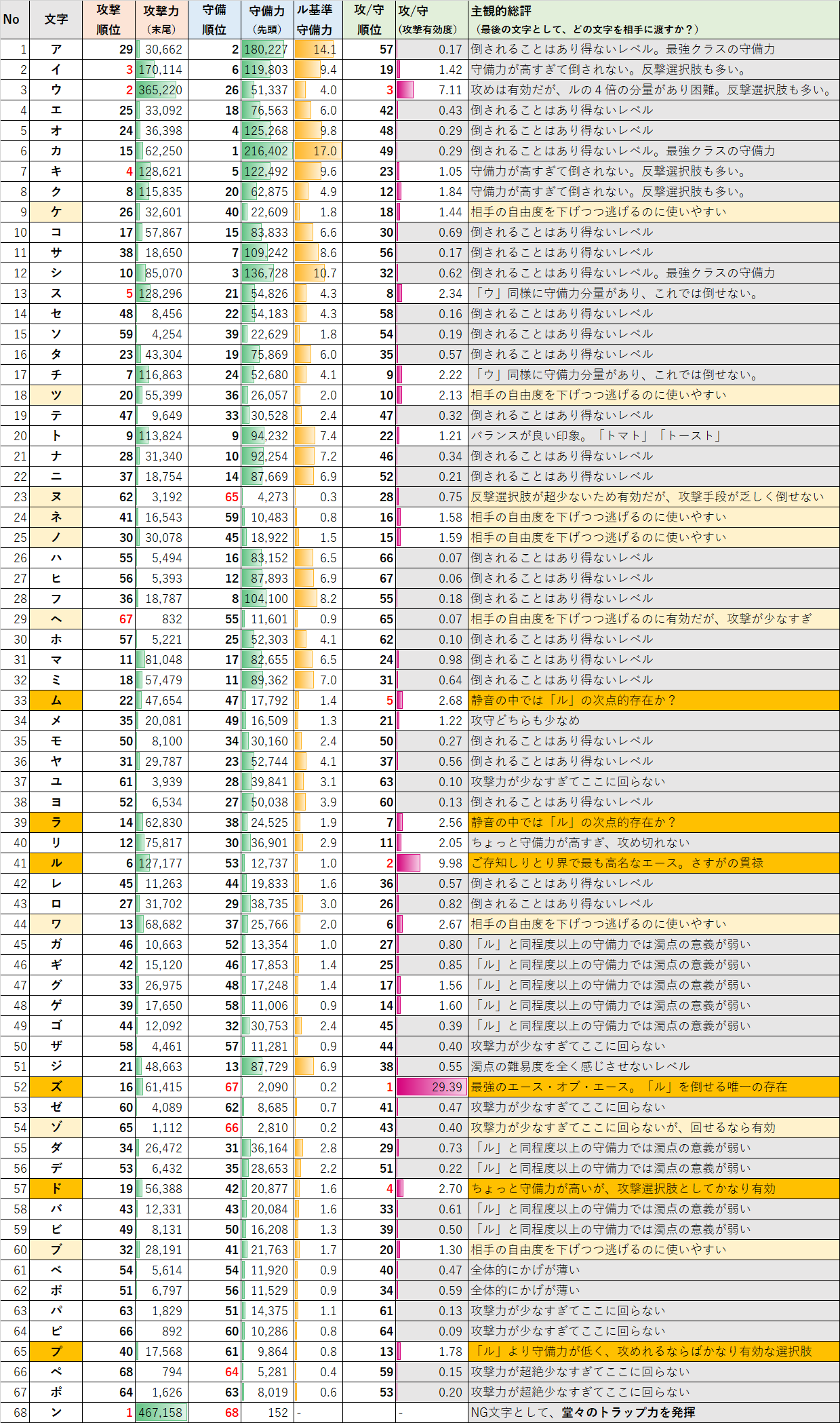
★結果①★ 全キャラ(文字)の詳細ステータス解説
永久保存版とも言える全キャラ一覧表を作った。
ちょっと見かたにコツがいるので先に説明をする。
キャラ(文字)「X」で終わる単語数を、
「攻撃力」とした。(その文字で攻撃出来る回数が多い)
キャラ(文字)「X」から始まる単語数を、
「守備力」とした。(その文字で攻撃されても、回避出来る回数が多い)
守備力が低いのに、攻撃力が高い、といった形で、
割合にゆがみがある場合、その文字での攻撃が有効ということになる。
「攻撃力」÷「守備力」の割合を表示することにした。
しかし、実際は、「守備力」の絶対的な個数が多いと、
勝負が終わらないことになってしまうため、
「守備力」の絶対値も重要である。
イメージしやすいように「ル」との比率を表現した。
さあ、多くの日本人が待ち望む(?)結果がここにある。
存分に楽しんで欲しい・・・。
★結果②★ しりとりにおける、5つの「驚愕」
かなり細かい表になるので、結局何が面白かったんだよ!?
というめんどくさがり屋なお忙しいあなたへ。
私がかなり驚き感動した5つの「驚愕」をご紹介する。
直近1年のQiita記事分析で分かった7つの「驚愕」
の7つの「驚愕」より、むしろこっちの方が驚いた。。。
①「ル」と「ズ」の圧倒的存在感
もはや説明不要なレベルに有名な「ル」と、
一部のしりとりマニアの間で有名な「ズ」が、
確かにしりとり戦術上有効な作戦であることが、
データによって説明された、と言える。
「ズ」で終わる単語は「ル」に比べ約半分だが、
「ズ」で始まる単語は「ル」の5分の1であるため、
あらかじめ「~~ズ」リストを用意すれば、
「ル」の5倍の速度で圧勝出来る。
良い子はこれを見て「ズ」で始まるリスト&終わるリストを調べてはいけない。
②「ル」よりも「ヌ」「ネ」「ヘ」で始まる単語数が少ない
しりとりの印象が強すぎて、少なくとも濁音半濁音をのぞけば、
「ル」で始まる言葉が一番少ないと、心から信じていた。
一方で実際は、清音の中にも、「ル」より、
その文字で始まる単語数が少ない文字が**「ヌ」「ネ」「ヘ」と三つも居た**。
しかし、攻撃する手段が少ないために、
しりとりで「ヌ」攻めをすることはかなり難しい。
「ル」がしりとりで猛威を振るう理由は、
「ル」で終わる単語が多い(6位)、に対して
「ル」で始まる単語が少ない(53位)、という、比率的な理由である。
日本人の90%くらい誤解していそうな内容ではないだろうか!?
「ル」が一番少ないに、スーパーヒトシ君人形をかけてしまうと、
残念ながらボッシュート、になってしまうので注意が必要だ。
もしあなたがクイズ番組に出る際には、とても役に立つ知識である。
③「ン」は「トラップ」として最高の性能
なんと、「ン」で終わる言葉が一番多いという結果に。
「あ、ンがついた~~」を誘発するためには、
やはり単語の母数が必要になる。
1文字ジョーカーを入れろと言われたら、
「ン」で始まる単語がほぼ無い、という理由以外でも、
やはり「ン」をNG文字として設定することが相応しいと言える。
最も終わる言葉が多く、始まる言葉が皆無という意味で、
しりとりのルール上とてもよくできた設定だ。
フフフ、幼稚園児の1%もこの事実に気づいていまい・・・
④清音で「ル」に次ぐ文字は「ム」「ラ」
割合だけで言えば、「ウ」が高いものの、
「守備力」が高すぎて、切らすことがかなり難しい
(反撃も受けやすいということ)
そのため、実戦的には、「ム」「ラ」が使いやすい。
「ウはっ…私の守備力、高すぎ…?」
「ル」の印象が強すぎて見落とされがちだが、
「ム」「ラ」などの強文字は覚えておいて損はない。
そもそも、しりとりを極めようとする行為自体が、
人生の何かを損しているような気はする
⑤濁音半濁音は、「ル」に比べて大したことはない
「ズ」以外では、「ド」「プ」はそれなりに有効ではある。
しかし、他の文字は、集中してX攻めをすることは、
攻撃時の選択肢が少なく、「ル」に比べてあまり有効ではない。
(相手の選択肢を狭めるという意味では有効)
濁音/半濁音があるしりとりでも、
意外と、濁音/半濁音攻めは容易ではないということが分かった。
なお、濁音/半濁音は付け替え自由、というぬるいルールにするならば、
それぞれ清音の側に数値を足してあげれば良い。
その場合、「ラ」「ム」は濁音/半濁音化出来ないため、
「ル」の次点としての地位が高まることになる。
増殖しりとり、東大生への挑戦
ここまでが、「第一部:分析編」。
まともに読む価値が高いのは上までなので、
一旦ここまででいいねをおしてから閉じてもらっても構わない。
ここから、謎の第二部が始まる。
様々なアレンジしりとりに挑戦してみたいが、まず「増殖しりとり」に目をつけた。
(増殖しりとり以外は、ちょっと名詞リストの作り直しもしたいので、別記事かな~~)
増殖しりとりとは?
「か」⇒「かさ」⇒「さかな」⇒「なぞなぞ」のように1文字ずつ増加するしりとりである。
前述の東大生(QuizKnock)は、「18文字」まで達成していた。
(詳細は前述の動画を参照)
今回こちらは、語彙力は乏しいが、機械が味方についている。
18文字を圧倒的に超える記録を打ち立てられるハズ。
文字数の分布調査
まず、ざっくりと文字数の分布を調べる。
既に文字数もリストに入れており、プログラムは簡単すぎるために省略。
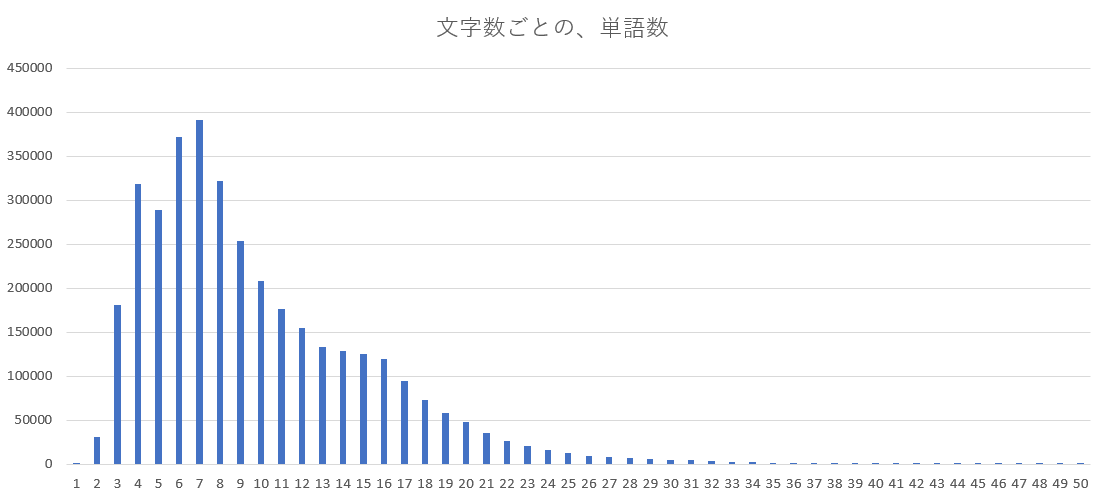
グラフより右側の80文字くらいまでは、チラホラと単語が存在する。
だが、今回の単語リストでは、
「68文字」の単語が一個も存在しなかったため、
どんなにがんばっても67文字までしか作れないということが分かった。
増殖しりとり攻略プログラムの検討
まず、まじめに、1文字目から順番にしりとりを作っていくと、
バリエーションが多すぎて、計算量が膨大になる。
(1手ごとに単語数分掛け算はしないにしても、
次の文字の選び方で、68通りのN乗という形になってくる)
そのために、逆に67文字の単語側から、
「あたまとり形式」で生成していくことが望ましい。
また、逆側から行っても、途中まで進むと同様に計算量が膨大になるため、
1. 何文字の増殖しりとりなら出来るのか?を先に見極め、
2.次に、その頭の文字がどう推移するのかのリストを作り、
3.最後に実際の単語を探す、
という3ステップを踏むことにする。
準備として、任意の長さの単語リスト
特定の長さの単語群が必要になるため、以下のようにして取得できるようにする。
# siritori_info=[genkei,hinsi,s_hinsi,yomi,nagasa,sentou,matubi,siri_sentou,siri_matubi]
nagasa_goto_siritori_noun_list_dict={}
# 以下の形で、長さごとに、siritori_infoの情報をまとめる。
# { nagasa : list[siritori_info,siritori_info,siritori_info] }
for siritori_info in siritori_noun_list:
key_nagasa =siritori_info[4]
nagasa_goto_siritori_noun_list_dict.setdefault(key_nagasa, [])
nagasa_goto_siritori_noun_list_dict[key_nagasa].append(siritori_info)
「67文字」から逆向きに、接続可能か確認していく
ちょっと複雑なので、もっと良いやり方があるかもしれない。
67文字側から順番に、繋がる頭の文字を列挙した文字列を生成させる。
# 次に検索対象とする文字数と、それまでにつなげられたリストを入力する
# tunagari_list=["〇〇さか","〇あいう","ぞなさま"]などのデータ
# たとえば、その文字数内に、「あか」「いか」などがあれば分岐。「〇ま」が無ければ消える。
# tunagari_list=["〇〇さかあ","〇〇さかい",〇あいうえ","〇〇〇〇く",〇〇〇〇〇"]などの形で返す。
def getRenzokuSiritori(next_mojisuu, tunagari_list):
#該当の文字数の全単語リストを取得する
mojisuu_goto_list = nagasa_goto_siritori_noun_list_dict[next_mojisuu]
#print(mojisuu_goto_list)
next_tunagari_list=[]
for tunagari in tunagari_list:
#この文字で終わる単語を探す
target_matubi = tunagari[-1]
#その単語リストの中で、しりとり用の文字を取得する。
for siritori_info in mojisuu_goto_list:
siri_sentou = siritori_info[7]
siri_matubi = siritori_info[8]
#末尾の文字が一致したのが見つかれば、先頭を追加:重複は気にしない。
#"〇"はワイルドカード
if target_matubi == siri_matubi or target_matubi==u"〇" :
next_tunagari = tunagari+siri_sentou
next_tunagari_list.append(next_tunagari)
#重複を削除する
next_tunagari_list_uniq = list(set(next_tunagari_list))
#元々のtunagariの文字数に+1した分の長さの〇の連続値を、ワイルドカードとして追加
# ※ある程度先に進むと、このワイルドカードは入れないように変えた方がよい。
wild_str = ''.join([u"〇" for i in range(len(tunagari)+1)])
next_tunagari_list_uniq.append(wild_str)
# ある程度先に進むと、return時に[:5]などで、結果を切って一部を渡しても、単語が多いので問題が生じない
return next_tunagari_list_uniq
上記で準備した関数を、1文字ずつ減らす形でループして回す
result=[u"〇"]
for val in range(20):
result=getRenzokuSiritori(67-val, result)
print(result)
# 上を最初に、数値を変えて、いろいろ試す
result=[u"〇"]
for val in range(5):
result=getRenzokuSiritori(44-val, result)
print(result)
['〇チクイコニ', '〇チクイコゼ', '〇マホニドチ', '〇イクイダア', '〇イクイダゲ', '〇チクトニビ', '〇チクカコニ', '〇イクカコニ', '〇イクイトオ', '〇チクカコア', '〇イクイキセ', '〇イクイトト', '〇イクイコゼ', '〇チクイダゲ', '〇リフトニビ', '〇オミゲニビ', '〇チクイトト', '〇イクトニビ', '〇チクイキセ', '〇イクイニビ', '〇チクイトオ', '〇チクイニビ', '〇チクカコゼ', '〇イクイコア', '〇イクルチヒ', '〇チクイエシ', '〇チクルチヒ', '〇イクイコニ', '〇チクイコア', '〇マホニドグ', '〇イクイエシ', '〇イクカコゼ', '〇チクルチシ', '〇イクルチシ', '〇チクイダア', '〇イクカコア']
例えば上の結果の一個目では、以下のような組があることを示唆している。
- ニ~~コ(40文字)
- コ~~イ(41文字)
- イ~~ク(42文字)
- ク~~チ(43文字)
- チ~(任意)(44文字)
既に長すぎるし分かりにくいので、一部を省略して、
結論としては、
1文字~44文字までの増殖しりとりは、(最後の部分も)何パターンもあるが、
45文字の増殖しりとりは作れない、ことが分かった。
頭の文字がどう推移するのかのリストの作成
上記の関数を、計算量に注意して、44文字分(最後の1文字まで)繋げるようにする。
結果を3例だけ記載してみる。
(文字数が多い領域=下記でいうと左側の部分も、実は多数のパターンがあった。
以下の冒頭の「イクイコニ」が上の44文字から調べた結果と対応している)
'〇イクイコニイイイキトイヒイグミコテクチギコクブドコサオキクメシムタフロワメソプソエウママ'
'〇イクイコニイイイキトイヒイグミコテクチギコクブドコサオキクメシムタフロワメソプソベゴママ'
'〇イクイコニイイイキトイヒイグミコテクチギコクブドコサオキクメシムタフロワメソプソエウムム'
実際の単語を探す
さあ、冒頭の文字をつなげた文字列が出来たので、
実際に当てはまる単語を探そう。
まず、汎用的に使える関数として、
任意の文字数、先頭、末尾の文字の単語の候補を出せる関数を実装する。
# 先頭と末尾と文字数を入れると、合致する単語を検索する関数:最大N個検索する
def kensaku_word_Hukusuu(sentou,matubi,mojisuu, kensaku_kosuu):
#結果リスト
result_list=[]
#該当の文字数の全単語リストを取得する
mojisuu_goto_list = nagasa_goto_siritori_noun_list_dict[mojisuu]
#その単語リストの中で、しりとり用の文字を取得する。
for siritori_info in mojisuu_goto_list:
siri_sentou = siritori_info[7]
siri_matubi = siritori_info[8]
#条件に合致するものを探す
if ((siri_sentou == sentou or sentou == u"〇") and (siri_matubi == matubi or matubi == u"〇")) :
#結果リストにどんどん追加していく。
result_list.append(siritori_info)
#十分な検索結果が集まっていたら処理を戻す
if len(result_list) > kensaku_kosuu-1:
return result_list
return result_list
上記の関数では、例えば、
「ト」で始まって「ト」で終わる4文字の単語を5個挙げることが出来る。
結構汎用的で使いやすい。
ト⇒トのカウンター攻撃がこんな一瞬で5個繰り出せるのは強力だ。
もちろん引数を9にすれば飛天御剣流/九頭龍閃が出せる。
「QuizKnock/限界しりとり」ならこのツールを持ち込めば圧勝できそうだ。
ぜひこのツールでクイズ王たちを倒したい(違
kensaku_word_Hukusuu(u"ト",u"ト",4, 5)
[['供人', '名詞', '一般', 'トモビト', 4, 'ト', 'ト', 'ト', 'ト'],
['トロット', '名詞', '一般', 'トロット', 4, 'ト', 'ト', 'ト', 'ト'],
['トラスト', '名詞', '一般', 'トラスト', 4, 'ト', 'ト', 'ト', 'ト'],
['トースト', '名詞', '一般', 'トースト', 4, 'ト', 'ト', 'ト', 'ト'],
['TOTO', '名詞', '固有名詞', 'トートー', 4, 'ト', 'ー', 'ト', 'ト']]
この関数を活用して、
冒頭の文字をつなげた文字列、から実際のしりとり単語を探す。
(44文字目側から並んでいるために、ひっくり返して1文字目から探す)
# 最初の〇を消す[1:] & 文字列の反転[::-1]
zousyoku_str=last_result[1][1:][::-1]
print("増殖のキー文字列: "+zousyoku_str)
print(len(zousyoku_str))
# 最初の文字(一文字)は任意でも良い(1文字の場合実質終わる文字と一緒
sentou_moji=zousyoku_str[0]
for val in range(len(zousyoku_str)-1):
matubi_moji = zousyoku_str[val+1]
mojisuu_nagasa = val+1
print(kensaku_word_Hukusuu(sentou_moji,matubi_moji,mojisuu_nagasa,5))
#次の単語の先頭は、前の単語の末尾
sentou_moji = matubi_moji
# 最後は任意の文字で終わって良い
print(kensaku_word_Hukusuu(sentou_moji,u"〇",len(zousyoku_str),5))
結果発表
上の5つの候補単語のなかから、適当に選んで以下のようなしりとりとした。
正直、何のことか良くわからない単語がほとんどである。
(項目を分けて「表」にすると、ピラミッド型でかえって見にくいため、1列の表にした)
| 増殖しりとりの単語データ |
|---|
| '間', '名詞', '一般', 'マ', 1, 'マ', 'マ', 'マ', 'マ' |
| '孫', '名詞', '一般', 'マゴ', 2, 'マ', 'ゴ', 'マ', 'ゴ' |
| 'ゴンベ', '名詞', '固有名詞', 'ゴンベ', 3, 'ゴ', 'ベ', 'ゴ', 'ベ' |
| 'ベタ基礎', '名詞', '固有名詞', 'ベタキソ', 4, 'ベ', 'ソ', 'ベ', 'ソ' |
| 'ソフマップ', '名詞', '固有名詞', 'ソフマップ', 5, 'ソ', 'プ', 'ソ', 'プ' |
| 'プログレッソ', '名詞', '固有名詞', 'プログレッソ', 6, 'プ', 'ソ', 'プ', 'ソ' |
| '染宮すずめ', '名詞', '固有名詞', 'ソメミヤスズメ', 7, 'ソ', 'メ', 'ソ', 'メ' |
| '名電長沢', '名詞', '固有名詞', 'メイデンナガサワ', 8, 'メ', 'ワ', 'メ', 'ワ' |
| '別部穢麻呂', '名詞', '固有名詞', 'ワケベノキタナマロ', 9, 'ワ', 'ロ', 'ワ', 'ロ' |
| 'ロシア連邦政府', '名詞', '固有名詞', 'ロシアレンポウセイフ', 10, 'ロ', 'フ', 'ロ', 'フ' |
| 'フラットベッドプロッタ', '名詞', '一般', 'フラットベッドプロッタ', 11, 'フ', 'タ', 'フ', 'タ' |
| 'タイパハウスミュージアム', '名詞', '固有名詞', 'タイパハウスミュージアム', 12, 'タ', 'ム', 'タ', 'ム' |
| 'ムツゲゴマムクゲキノコムシ', '名詞', '固有名詞', 'ムツゲゴマムクゲキノコムシ', 13, 'ム', 'シ', 'ム', 'シ' |
| '灼熱の卓球娘', '名詞', '固有名詞', 'シャクネツノタッキュウムスメ', 14, 'シ', 'メ', 'シ', 'メ' |
| 'MEDICAL SYSTEM NETWORK', '名詞', '固有名詞', 'メディカルシステムネットワーク', 15, 'メ', 'ク', 'メ', 'ク' |
| 'caシウダーデロルキ', '名詞', '固有名詞', 'クルブアトレチコシウダーデロルキ', 16, 'ク', 'キ', 'ク', 'キ' |
| 'きよし黒田の今日もへぇーほぉー', '名詞', '固有名詞', 'キヨシクロダノキョウモヘェーホォー', 17, 'キ', 'ー', 'キ', 'オ' |
| '大阪版健康栄養調査', '名詞', '固有名詞', 'オオサカバンケンコウエイヨウチョウサ', 18, 'オ', 'サ', 'オ', 'サ' |
| 'サンタンジェロ・ディ・ピオーヴェ・ディ・サッコ', '名詞', '固有名詞', 'サンタンジェロディピオーヴェディサッコ', 19, 'サ', 'コ', 'サ', 'コ' |
| '国際原子力事象評価尺度', '名詞', '固有名詞', 'コクサイゲンシリョクジコヒョウカシャクド', 20, 'コ', 'ド', 'コ', 'ド' |
| 'ドンカスター・ローヴァーズFC', '名詞', '固有名詞', 'ドンカスターローヴァーズフットボールクラブ', 21, 'ド', 'ブ', 'ド', 'ブ' |
| 'VISUAL JAPAN SUMMIT 2016', '名詞', '固有名詞', 'ヴィジュアルジャパンサミットニセンジュウロク', 22, 'ヴ', 'ク', 'ブ', 'ク' |
| '熊本県熊本市北区植木町荻迫', '名詞', '固有名詞', 'クマモトケンクマモトシキタクウエキマチオギサコ', 23, 'ク', 'コ', 'ク', 'コ' |
| '国民体育大会軟式野球競技', '名詞', '固有名詞', 'コクミンタイイクタイカイナンシキヤキュウキョウギ', 24, 'コ', 'ギ', 'コ', 'ギ' |
| '岐阜県岐阜市西改田東改田入会地', '名詞', '固有名詞', 'ギフケンギフシニシカイデンヒガシカイデンイリアイチ', 25, 'ギ', 'チ', 'ギ', 'チ' |
| '中国人民解放軍第三軍医大学', '名詞', '固有名詞', 'チュウゴクジンミンカイホウグンダイサングンイダイガク', 26, 'チ', 'ク', 'チ', 'ク' |
| 'CHRISTMAS TIME IN BLUE-聖なる夜に口笛吹いて-', '名詞', '固有名詞', 'クリスマスタイムインブルーセイナルヨルニクチブエフイテ', 27, 'ク', 'テ', 'ク', 'テ' |
| 'TAM航空402便離陸失敗事故', '名詞', '固有名詞', 'ティーエーエムコウクウヨンヒャクニビンリリクシッパイジコ', 28, 'テ', 'コ', 'テ', 'コ' |
| '小林麻耶の意外と!?シングルガール-マヤヤゴルフアカデミー-', '名詞', '固有名詞', 'コバヤシマヤノイガイトシングルガールマヤヤゴルフアカデミー', 29, 'コ', 'ー', 'コ', 'ミ' |
| '見る力を実践で鍛える DS眼力トレーニング', '名詞', '固有名詞', 'ミルチカラヲジッセンデキタエルディーエスメヂカラトレーニング', 30, 'ミ', 'グ', 'ミ', 'グ' |
| 'グラディウススリージーアールエーディーアイユーエスアイアイアイ', '名詞', '固有名詞', 'グラディウススリージーアールエーディーアイユーエスアイアイアイ', 31, 'グ', 'イ', 'グ', 'イ' |
| 'International Institute for Strategic Studies', '名詞', '固有名詞', 'インターナショナルインスティテュートフォーストラテジックスタデヒ', 32, 'イ', 'ヒ', 'イ', 'ヒ' |
| '広島県不当な街宣行為等の規制に関する条例', '名詞', '固有名詞', 'ヒロシマケンフトウナガイセンコウイトウノキセイニカンスルジョウレイ', 33, 'ヒ', 'イ', 'ヒ', 'イ' |
| '一般社団法人マインドフルリーダーシップインスティテュート', '名詞', '固有名詞', 'イッパンシャダンホウジンマインドフルリーダーシップインスティテュート', 34, 'イ', 'ト', 'イ', 'ト' |
| '特定非営利活動法人 農業10次化プロジェクトいわき', '名詞', '固有名詞', 'トクテイヒエイリカツドウホウジンノウギョウジュウシカプロジェクトイワキ', 35, 'ト', 'キ', 'ト', 'キ' |
| 'きれいな水といのちを守る合成洗剤追放全国連絡会', '名詞', '固有名詞', 'キレイナミズトイノチヲマモルゴウセイセンザイツイホウゼンコクレンラクカイ', 36, 'キ', 'イ', 'キ', 'イ' |
| '一般社団法人全国高等学校PTA連合会', '名詞', '固有名詞', 'イッパンシャダンホウジンゼンコクコウトウガッコウピーティーエーレンゴウカイ', 37, 'イ', 'イ', 'イ', 'イ' |
| '一般社団法人東京都小学校PTA協議会', '名詞', '固有名詞', 'イッパンシャダンホウジントウキョウトショウガッコウピーティーエーキョウギカイ', 38, 'イ', 'イ', 'イ', 'イ' |
| '出光リテール販売株式会社 ファインオイル東日本カンパニー', '名詞', '固有名詞', 'イデミツリテールハンバイカブシキガイシャファインオイルヒガシニッポンカンパニー', 39, 'イ', 'ー', 'イ', 'ニ' |
| '2012年南アフリカ空軍c-47tp墜落事故', '名詞', '固有名詞', 'ニセンジュウニネンミナミアフリカクウグンシーヨンジュウナナティーピーツイラクジコ', 40, 'ニ', 'コ', 'ニ', 'コ' |
| '公益社団法人 日本消費生活アドバイザーコンサルタント協会', '名詞', '固有名詞', 'コウエキシャダンホウジンニホンショウヒセイカツアドバイザーコンサルタントキョウカイ', 41, 'コ', 'イ', 'コ', 'イ' |
| 'イラク人道復興支援特措法に基づく対応措置に関する基本計画', '名詞', '固有名詞', 'イラクジンドウフッコウシエントクソホウニモトヅクタイオウソチニカンスルキホンケイカク', 42, 'イ', 'ク', 'イ', 'ク' |
| '黒鷲旗第34回全日本バレーボール男子・女子選手権大会', '名詞', '固有名詞', 'クロワシキダイサンジュウヨンカイゼンニホンバレーボールダンシジョシセンシュケンタイカイ', 43, 'ク', 'イ', 'ク', 'イ' |
| "INFINITY16 welcomez若旦那from湘南乃風&JAY'ED", '名詞', '固有名詞', 'インフィニティシックスティーンウェルカムズワカダンナフロムショウナンノカゼアンドジェイド', 44, 'イ', 'ド', 'イ', 'ド' |
「国際原子力事象評価尺度」(20文字)
「見る力を実践で鍛える DS眼力トレーニング」(30文字)
「一般社団法人東京都小学校PTA協議会」(38文字)
とか、通常のしりとりでは一生使わないレベルの単語ばかりだが、
1文字~44文字までの増殖しりとりを達成した。(ように見える)
実際に友達とのしりとりで使ったら、友達を無くすレベル
用いられている単語に文句があるならば、
mecabやNEologdなど、形態素解析向けの辞書の性質である。
(正直に全単語使ってはいけなかったのかもしれない?)
また、44文字の増殖しりとりは何パターンもあるようなので、
別のパターンで、別な単語を生成すれば、
そのうちもっとまともな解が見つかるかもしれない。
とりあえず、機械の助けと、りんなルール(注)によって、
18vs44で、
東大生チームに対して圧勝した、と宣言しておこう。
多分、増殖しりとりにおける日本新記録である。
注:
りんなの”負ける気がしない”しりとり
をする場合、りんなからのルール説明のなかに、
「そしてりんながルール」
という最強の暴言掟が存在している。
機械女子高生とのしりとりは、機械女子高生が認識している単語で勝負、が大前提。
さらなる発展を目指して
今回は、分析と増殖しりとりについて記載した。
なんとなくズルイ単語もリスト中にまだ多いため、
実際に友達を無くさないレベルの回答にするためには、
もう少し名詞リストを見直した方が良いかもしれない。
辞書中にも登録ミスらしき単語もいくつかあり、
個数が多いデータのクリーニングは難しい。
綺麗な単語リストを作るor入手することは今後の課題である。
一方、成果として、
しりとり≒日本語の単語、のデータ分析結果として、
なかなか興味深い結果が得られた。
また、アレンジしりとりへの応用例も示せた。
日本一の結果を出した。
お子様への「接待しりとり」のためにこの結果を逆用してもいいかも?
さらに、他の技術との組み合わせも有望である。
上記の記事の「裏のあとがき」に記載したように、
word2vec(赤の他人の対義語)、
char2vec(平成の次の元号)、
doc2vec(AIが見つけた良記事)、
のそれぞれの2vec技術を活用すれば、
「山手線しりとり」「連想しりとり」なども実現できるかもしれない。
しりとり以外でも「クイズミラクル9」(クイズTV番組)の
漢字一文字×クロスワードのゲームなどにも適用出来そうだ。
本投稿が、しりとり道に燃える大勢の人への、道しるべとなれば幸いである。
だが「しりとり」の深淵をのぞく時は注意をしてほしい。
テーマとして深すぎて既に私は怖くなってきている。
「しりとり」を知らぬものは居ないが、
「しりとり」の深淵はまだ誰も知らない。
「しりとり」の深淵をのぞく時、「しりとり」もまたこちらをのぞいているのだ。
~ Char Fuitter (1847~1912 オランダ) ~
この物語はフィクションです。
登場する人物・団体・名称等は架空であり、
実在のものとは関係ありません。
文中に不適切/失礼な用語があった場合は、見なかったことにしてください。
Char Fuitter (チャー・フイター)は架空の人物です。