はじめに
M4 の Mac mini を使ったローカルLLM をこれまで試していました。
その際、 MLX LM、MLX-VLM を使っていましたが、今回 Ollama を Mac mini で試してみます。
MLX LM・MLX-VLM を使ったお試しの話
過去のお試しについて、少しだけ紹介します。MLX LM・MLX-VLM を試した内容は一部を記事に書いていて、それらは以下の検索に出てくるものです。
●「MLX ローカルLLM user:youtoy」の検索結果 - Qiita
https://qiita.com/search?sort=created&q=MLX+%E3%83%AD%E3%83%BC%E3%82%AB%E3%83%ABLLM+user%3Ayoutoy
それらの記事の中の一部を、以下にピックアップしてみます。
- Mac mini で ローカルLLM: Google の Gemma 3(量子化された MLX版 2種)の画像入力を MLX-VLM で試す - Qiita
- Mac mini で ローカルLLM:「Qwen3-30B-A3B」「Phi-4-reasoning」を MLX LM で試す(量子化された MLX版) - Qiita
- Mac mini で ローカルLLM: Google の Gemma 3(MLX版 27B 3bit)を MLX LM + コマンドライン/Python で試す - Qiita
直近では、試したモデルとして Gemma 3 や Qwen3・Phi-4 がありました。
今回のお試し
MLX LM・MLX-VLM を選んでお試しをいろいろやり始める前、ローカルLLM を試すための方法を検索していた時に Ollama や LM Studio など、メジャーなものの情報は見かけていました。
そして、その後もそれらを見かける機会が何度もあり、いつか試そうと思っていたところでした。
それで今回、Ollama を試してみることにしました。
Ollama を Mac mini にセットアップする
それでは、Ollama を Mac mini にセットアップして試していきます。まずは以下から Ollama をダウンロードしインストールします。
●Download Ollama on macOS
https://ollama.com/download

以下は、インストール後の画面です。

上記の 3つ目の画面で出ているコマンドを実行してみます。
ollama run llama3.2
これを実行すると、モデルがダウンロードされます。

そしてモデルのダウンロードが完了すると、以下のようにやりとりができる状態になります。

モデルの保存先
ここで、上記の手順の途中でダウンロードされたモデルの保存先を確認してみました。
モデルの保存先は以下になるようです。
~/.ollama/models

その中の blobs の中にあるファイル・フォルダ全体のファイルサイズを確認してみました。

上記のサイズは、ほぼ以下と一致しているのが確認できます。

●Ollama Search
https://ollama.com/search
Gemma 3 のお試し1
それでは、Gemma 3 を試していきます。今回試すモデルを、以下から選びます。
●Tags · gemma3
https://ollama.com/library/gemma3/tags
自分の環境だと 16GB までのモデルが試せると想定されるため、大きなサイズのものだと以下を試せそうです。
●gemma3:12b-it-q8_0
https://ollama.com/library/gemma3:12b-it-q8_0

gemma3:12b-it-q8_0 を使ったお試し
gemma3:12b-it-q8_0 をダウンロードして実行してみます。具体的には以下のコマンドです。
ollama run gemma3:12b-it-q8_0
実行後、モデルがダウンロードされます。

ダウンロードが完了した後、「生成AIを8歳に分かるように短い言葉で説明して」というプロンプトを送ってみました。それで得られた回答は以下のとおりです。

ひとまず動作確認ができました。
Ollama のコマンドをいくつか試してみる
ここで、以下を見つつ Ollama のコマンドをいくつか試してみます。
●Ollama で Gemma を実行する | Google AI for Developers
https://ai.google.dev/gemma/docs/integrations/ollama?hl=ja
●ollama/ollama: Get up and running with Llama 3.3, DeepSeek-R1, Phi-4, Gemma 3, Mistral Small 3.1 and other large language models.
https://github.com/ollama/ollama
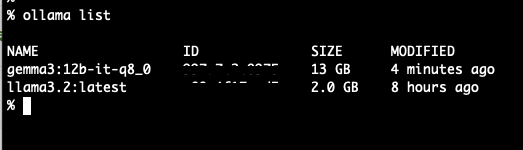
ダウンロード済みのモデルのリスト
以下はダウンロード済みのモデルの一覧の表示です(コマンド ollama list )。
ダウンロード済みのモデルの削除
インストール後にダウンロードしたモデルの削除を試してみます。
以下が、コマンドやコマンドの実行前後の状態です。
ollama rm llama3.2

モデルの情報を見る
ollama show gemma3:12b-it-q8_0

Gemma 3 のお試し2: 画像入力
上で試した gemma3:12b-it-q8_0 は画像の入力にも対応しているため、以下のコマンドを参考に画像を入力に含むものも試してみます。

画像は、過去のローカルLLM でも使った以下を使います。

マルチモーダルの実行結果
以下がコマンドと実行結果で、画像の内容を説明する回答を得ることができました。
※ 「dragon.jpg」は上でも掲載した画像のファイル名です
ollama run gemma3:12b-it-q8_0 "これは何の画像? ./dragon.jpg"

とりあえず、Ollama で Gemma 3 のお試しができました。
【追記】 次に試したこと
次に、以下を試しました。
●Mac mini で ローカルLLM: Ollama で「REST API」とライブラリ「ollama-js」を試す(モデルは Gemma 3) - Qiita
https://qiita.com/youtoy/items/d835920f1bd26dae57fd