はじめに
今回の内容は、以下の記事に書いていた「Gemma 3(MLX版)」を使ったローカルLLMの話です。
●Mac mini で ローカルLLM: Google の Gemma 3(MLX版 12B 8bit)を MLX LM で試す - Qiita
https://qiita.com/youtoy/items/43e0c2a5c966963edcc5
上記の記事では、M4 の Mac mini で MLX LM を使って、コマンドラインでローカルLLM を試していました。そして、用いたモデルは 12B で、なおかつ自分の環境で使えるモデルサイズの量子化されたもの(利用するメモリが 16GB以内のもの)の 1つでした。
具体的には「gemma-3-12b-it-8bit」を使っていました。
今回の内容
今回は「27B で量子化が 3bit の MLX版」である「gemma-3-27b-it-qat-3bit」を使ってみます。当時はおそらくまだ出ていなかったと思われるものです(当時の 27B でモデルサイズが最小のものは、量子化が 4bit のものだった気がします)。
以下のとおり 16GB のメモリ割り当てができれば、余裕で実行できる感じのサイズ感のものです。
●mlx-community/gemma-3-27b-it-qat-3bit at main
https://huggingface.co/mlx-community/gemma-3-27b-it-qat-3bit/tree/main

実際に試す
試す環境
今回、過去にも使った以下の環境を利用しています。
- PC
- M4 の Mac mini(メモリ 24GB、うち 16GB をローカルLLM用で利用可能)
- モデル
- gemma-3-27b-it-qat-3bit
- 実行環境
- Python の仮想環境で MLX LM を利用、Python のコードで処理を実行
コマンドラインで処理を実行する
コマンドラインで実行するコマンド
仮想環境で、以下のコマンドを実行して試してみます。
mlx_lm.generate --model mlx-community/gemma-3-27b-it-qat-3bit --prompt "東京について日本語で説明して" --max-tokens 1024
出力
上記を実行した結果は、以下の通りです。

日本語での説明を得ることができました(出力されたトークン数 ⇒「Generation: 560 tokens」)。また「Peak memory: 12.900 GB」となっており、ピーク時でも 13GB未満のメモリ使用量におさまっていたようでした。
Python のコードで処理を実行する
あとは、Python のコードでのローカルLLM も試してみます。
Python のコード
今回、以下の過去記事でも使った、公式サンプルを元にした Python のコードを使いました。
●Mac mini で ローカルLLM: Qwen3(MLX版)を MLX LM + Python で試した時のメモ - Qiita
https://qiita.com/youtoy/items/fcf775e3a1547979cc63
具体的なコードは、以下のとおりです。
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/gemma-3-27b-it-qat-3bit")
prompt = "東京について3段落くらいで、日本語で説明して"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
response = generate(model, tokenizer, prompt=prompt, max_tokens=1024, verbose=True)
実行結果
上記の Python のコードを実行して、その結果として日本語の説明を得られました。
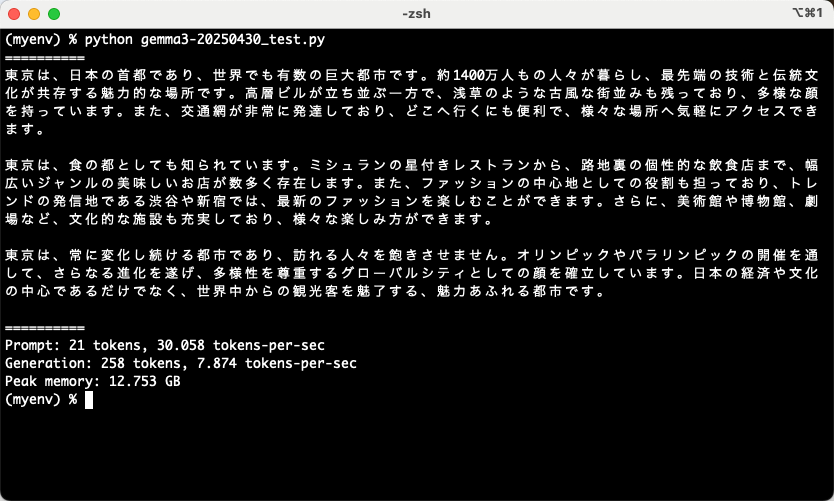
また、出力中の様子を動画でキャプチャしたものも掲載しておきます。
コマンドラインでのコマンドによる処理でも Python を使った処理でも、無事に結果を得られました。
自分の環境での ローカルLLM で扱えるモデルのバリエーションが増えるのは、嬉しい限りです。