はじめに
以前も試して記事を書いたり、また記事には書いてないものでもちょこちょこ試しているローカルLLM の話です。
M4 の Mac mini で、以下の「MLX LM」と MLX版のモデルを組み合わせて試していきます。
●mlx-lm · PyPI
https://pypi.org/project/mlx-lm/
過去の記事
MLX LM と MLX版のモデルの組み合わせを過去に試したもので、記事化したものは以下があります。
●mlx-community の「Llama-3-ELYZA-JP-8B-8bit」「Swallow-13b-instruct-v0.1-8bit」を mlx-lm で試す - Qiita
https://qiita.com/youtoy/items/973910dada605ab7e259
●MLX でローカルLLM:「mlx-community/phi-4-4bit」を試す(M4 Mac mini、mlx-lm を利用) - Qiita
https://qiita.com/youtoy/items/a12ee071dd8290fc0715
今回試すモデル
今回試すモデルは、Googleさんの「Gemma 3(MLX版)」です。
Hugging Face のモデルのメニューで「mlx-community/gemma-3」をキーワードとして検索すると、パラメータ違いのモデルがたくさん出てきます。
●Models - Hugging Face
https://huggingface.co/models?sort=trending&search=mlx-community%2Fgemma-3
この中で、自分の M4 の Mac mini で動かせるモデルを選んでいきます。
モデルを選ぶ
自分のマシンはメモリ 24GB で、設定変更を行わない場合はそのうちの 16GB をローカルLLM用に使えます。
その範囲で扱える、できるだけ大きいモデルを選んでみます。
ざっと見ていくと、以下が良さそうに思えました。
(パラメータ数の大きいものから見ていったところ、27B のモデルは量子化されたものでもサイズが厳しそうだったので、12B の量子化されたものを選んだ形です)
●mlx-community/gemma-3-12b-it-8bit · Hugging Face
https://huggingface.co/mlx-community/gemma-3-12b-it-8bit
●mlx-community/gemma-3-12b-pt-8bit · Hugging Face
https://huggingface.co/mlx-community/gemma-3-12b-pt-8bit

ちなみに、「it」と「pt」という種類があるようでしたが、以下の記事に書かれているような違いがあるようです。
●Google の Gemma 3 を解説して試してみる
https://zenn.dev/schroneko/articles/try-google-gemma-3
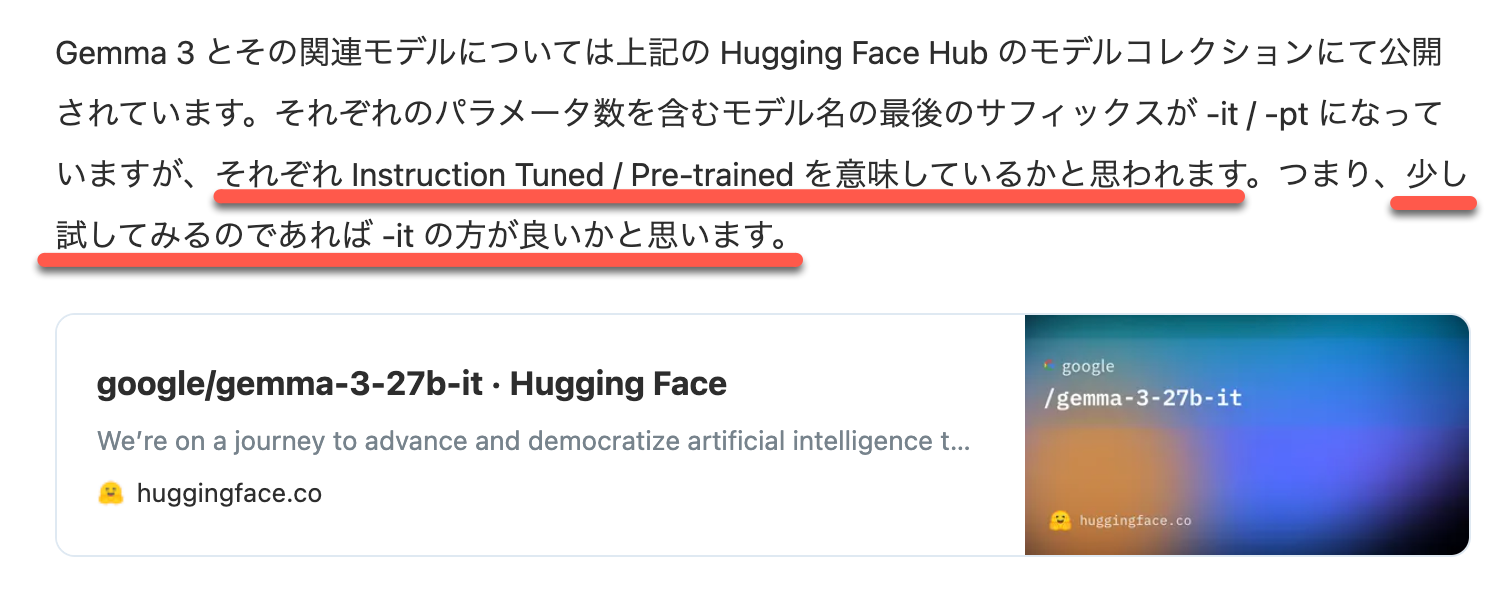
今回は「mlx-community/gemma-3-12b-it-8bit」のほうを使うことにしました。
実際に試す
実際に試していきます。
下準備
過去の記事と同様に、仮想環境を使います。
既に「myenv」という名前で作成していた環境を使います。
まずはアクティベートです。
source myenv/bin/activate
過去に MLX LM を試した環境なので、それが導入済みではあるのですが、最新版にアップデートしておくために以下を実行しました。
pip install -U mlx-lm
コマンドで利用
下準備はできたので、「mlx-community/gemma-3-12b-it-8bit」をコマンドで扱います。
コマンドの内容
具体的には、以下のコマンドで実行すれば OK です。
mlx_lm.generate --model mlx-community/gemma-3-12b-it-8bit --prompt "【プロンプト】"
以下のように「--max-tokens」のオプションを併用すると良いかもしれません(デフォルトの値だと、最大トークン数があまり大きくない感じがします)。
mlx_lm.generate --model mlx-community/gemma-3-12b-it-8bit --prompt "【プロンプト】" --max-tokens 【数字】
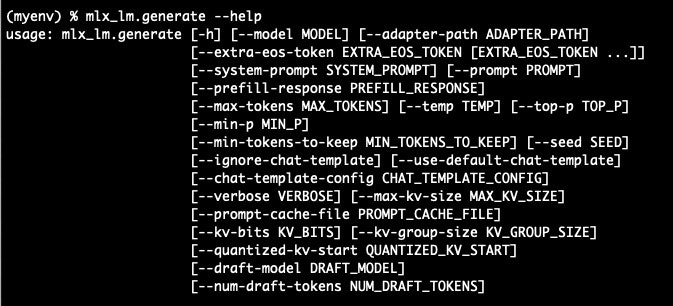
ちなみに利用可能なオプションについては、mlx_lm.generate --help を実行することで確認できます。
以下はその実行例です(この部分の下に、個々のオプションの説明も出てきています)。
実行結果
コマンドを実行して試した例を掲載します。
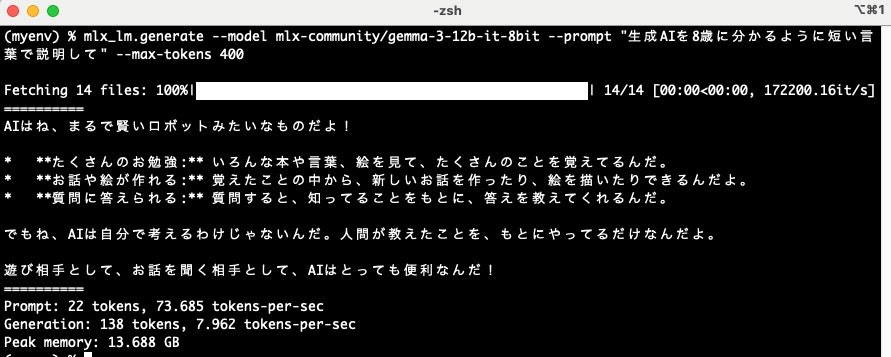
メモリ利用のピークは 13.688 GB で、生成スピードは 7.962 tokens-per-sec となりました。