はじめに
以下でポストした、自宅にある Mac mini(M4)での Qwen3 を使ったお試し時のメモです。MLX LM を使ったローカルLLM の話になります。
動作中の様子
先に、動作中の様子の動画を掲載してみます。
以下は出力中の様子の動画で、出力中の様子の一部(合計30秒ほど)をカットしています。(※ 途中をカットしていない、約1分弱のフルバージョンはこちら)
直近のローカルLLM のお試し
過去、複数の種類のモデルを MLX LM で試しているのですが、それに関して直近だと Gemma 3 を試していました。
●Mac mini で ローカルLLM: Google の Gemma 3(MLX版 12B)を MLX LM で試す - Qiita
https://qiita.com/youtoy/items/43e0c2a5c966963edcc5
実際に試してみる
試す環境
Qwen3 を試す際の環境について、少し補足します。PC や利用するモデルについては、以下のとおりです。
- PC
- M4 の Mac mini(メモリ 24GB、うち 16GB をローカルLLM用で利用可能)
- モデル
- MLX版の Qwen3 で量子化されているもの
- 実行環境
- Python の仮想環境で MLX LM を利用、コマンドラインから処理を実行
コマンド関連
Python の仮想環境は myenv という名前で過去に作成済みです。
そのため、まずは作成済みの仮想環境をアクティベートします。
source myenv/bin/activate
また、念のため MLX LM を最新版にアップデートしておきます(過去に MLX LM を仮想環境内にセットアップ済みで、それを利用)。
pip install -U mlx-lm
あとは、適当なプロンプトやオプションをつけた内容で試します。
MLX LM を使って動作確認1
とりあえず、以下のプロンプト・オプションで動作確認をしてみます。
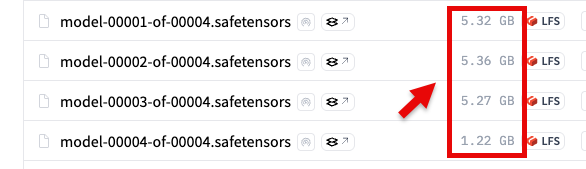
mlx_lm.generate --model mlx-community/Qwen3-14B-8bit --prompt "東京について日本語で説明して" --max-tokens 400
初回実行時は、モデルがダウンロードされていないので、モデルのダウンロードが行われてからローカルLLM の処理が実行されます。
上記のパラメータだと、回答が出力される前段の「。。。」の部分が途中まで出て終了となりました。

あと、ローカルLLM の処理を実行できてはいますが、以下のワーニングは出ています(上記の画像のとおり「Peak memory: 15.790 GB」なので、自分の環境の 16GB でぎりぎりという感じです)。

回答が出るところまで出力されるよう、オプションの値を少し変えて実行してみます。
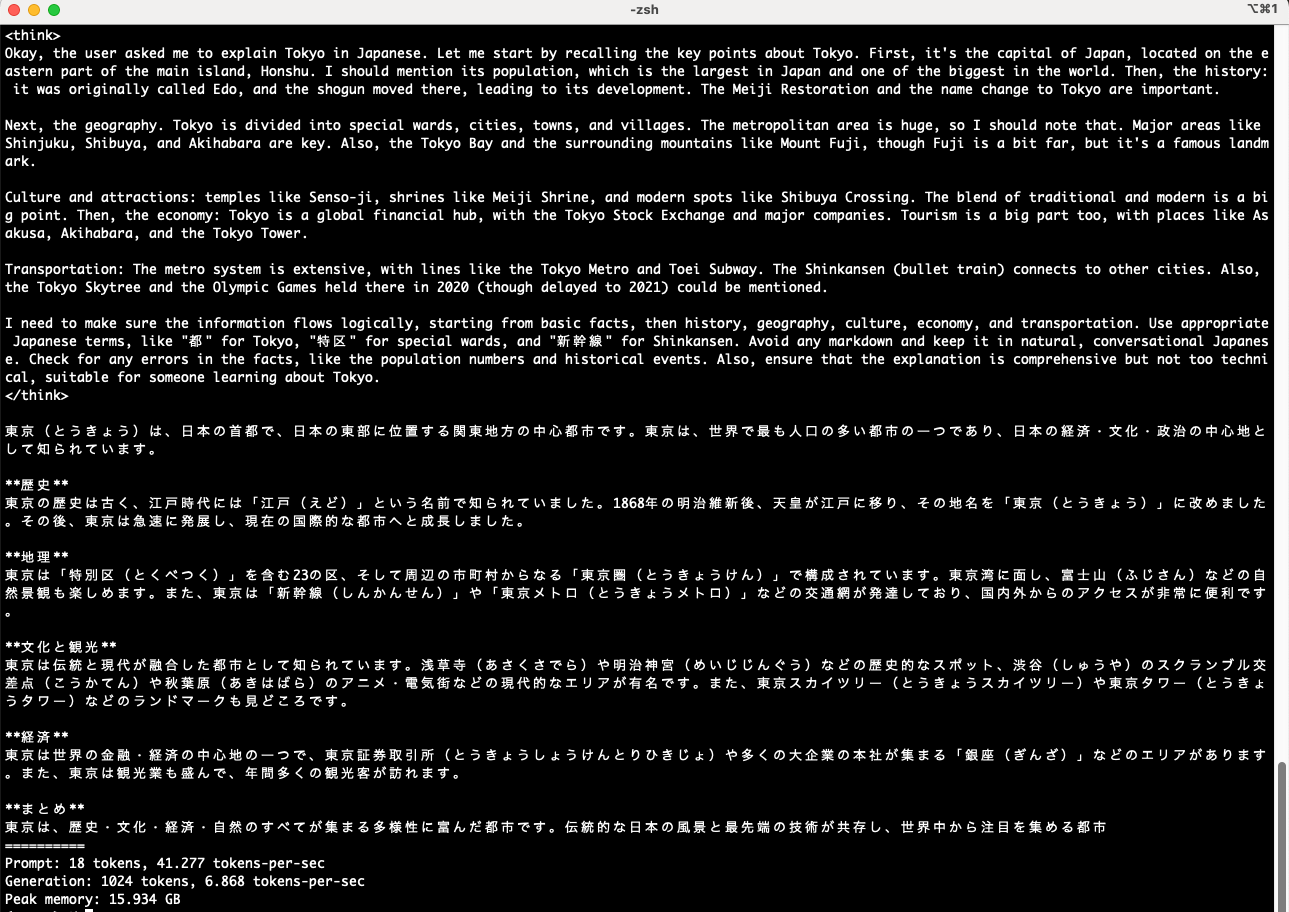
mlx_lm.generate --model mlx-community/Qwen3-14B-8bit --prompt "東京について日本語で説明して" --max-tokens 1024
今度も回答が途中で途切れてはいますが、日本語による回答の出力はできていました。
MLX LM を使って動作確認2
先ほどの内容でオプションを変えたものにしても良いですが、別のプロンプトでも試してみます。
mlx_lm.generate --model mlx-community/Qwen3-14B-8bit --prompt "生成AIを8歳に分かるように短い言葉で日本語で説明して" --max-tokens 1024
出力は以下のとおりです。
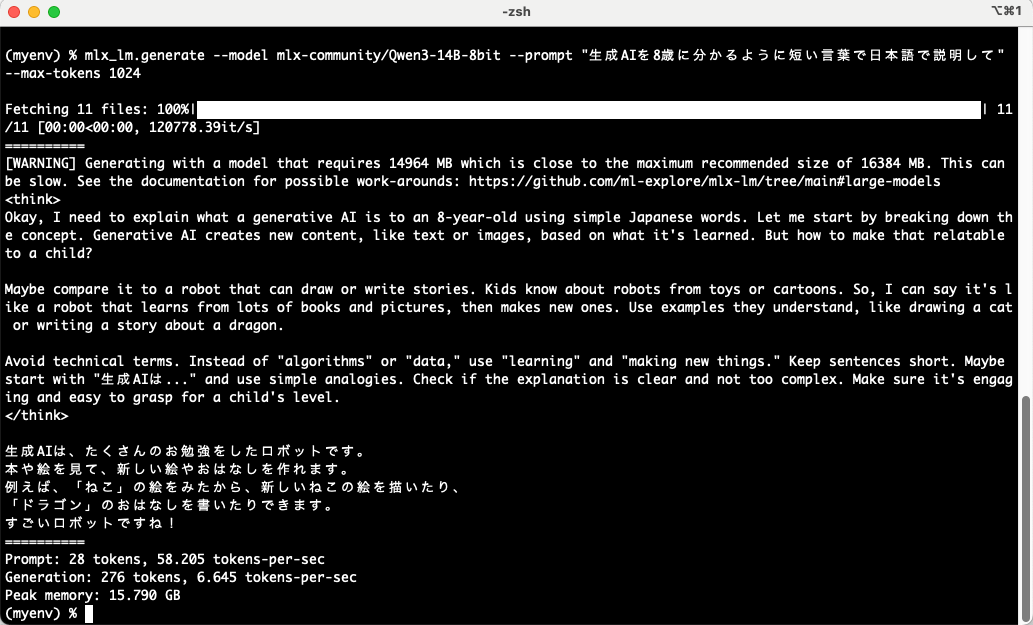
上記の画像のとおり、以下の内容が得られました。
<think>
Okay, I need to explain what a generative AI is to an 8-year-old using simple Japanese words. Let me start by breaking down the concept. Generative AI creates new content, like text or images, based on what it's learned. But how to make that relatable to a child?
Maybe compare it to a robot that can draw or write stories. Kids know about robots from toys or cartoons. So, I can say it's like a robot that learns from lots of books and pictures, then makes new ones. Use examples they understand, like drawing a cat or writing a story about a dragon.
Avoid technical terms. Instead of "algorithms" or "data," use "learning" and "making new things." Keep sentences short. Maybe start with "生成AIは..." and use simple analogies. Check if the explanation is clear and not too complex. Make sure it's engaging and easy to grasp for a child's level.
</think>
生成AIは、たくさんのお勉強をしたロボットです。
本や絵を見て、新しい絵やおはなしを作れます。
例えば、「ねこ」の絵をみたから、新しいねこの絵を描いたり、
「ドラゴン」のおはなしを書いたりできます。
すごいロボットですね!
==========
Prompt: 28 tokens, 58.205 tokens-per-sec
Generation: 276 tokens, 6.645 tokens-per-sec
Peak memory: 15.790 GB
その他
【余談】気になった内容
余談になりますが、今回の内容を進める中で気になったもののメモです。
詳細を後で調べてみようと思い、とりあえずメモしてみます。
lmstudio-community の MLX版
今回利用するモデルを探していて、lmstudio-community の MLX版モデルを見かけました。
●lmstudio-community/Qwen3-14B-MLX-8bit · Hugging Face
https://huggingface.co/lmstudio-community/Qwen3-14B-MLX-8bit
「LM Studio用かな」とも思ったのですが、冒頭部分を見ると MLX LM を使った手順が書かれていました。
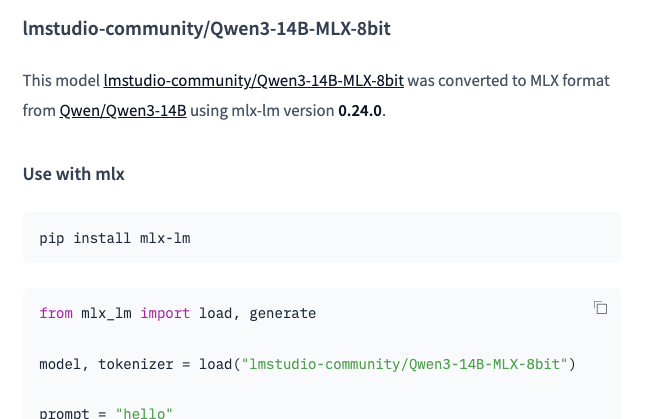
今回自分が使った(また以前からよく使っている)「mlx-community」のものと、何か違いなどがあるかが気になりました。
●mlx-community/Qwen3-14B-8bit · Hugging Face
https://huggingface.co/mlx-community/Qwen3-14B-8bit
MLX版 30B-A4B
以下の記事内に書かれた「MLX版 30B-A4B」というのも気になりました。
●Qwen3はローカルLLMの世界を変えたかも - きしだのHatena
https://nowokay.hatenablog.com/entry/2025/04/30/024927

Hugging Face で「Qwen3-30B-A3B mlx」で検索してみたところ、一番モデルサイズが小さそうなもので「量子化された MLX版で 4bit」がありました。

しかしモデルのサイズ合計が 16GB は超えており、自分の M4 Mac mini だと少しメモリが足りずに動かなそうなサイズ感でした...